- The paper introduces DistriVoting and SelfStepConf, new methods that formally model LLM confidence distributions to enhance answer selection.
- Empirical results demonstrate up to 8-10% performance gains and improved AUROC by dynamically filtering and reflecting low-confidence steps.
- The work provides a theoretical framework linking distribution separation to voting accuracy, promoting calibrated inference in LLMs.
Distribution-Guided Confidence Calibration in Test-Time Scaling
Introduction
"Believe Your Model: Distribution-Guided Confidence Calibration" (2603.03872) introduces a set of methods—DistriVoting and SelfStepConf (SSC)—for improving answer selection in LLMs through explicit modeling and dynamic manipulation of the confidence distribution generated at inference time. The central observation is that the distributional characteristics of model-internal confidence signals, typically calculated as a function of per-token log-probabilities, are only partially exploited in extant test-time scaling (TTS) protocols. The paper demonstrates that by formally modeling these signals and intervening at both post hoc voting and during stepwise generation, both the efficacy and reliability of test-time scaling are increased.
Distributional Modeling for Confidence-Based Voting
Existing test-time scaling and answer selection techniques aggregate multiple sampled trajectories, using approaches such as Self-Consistency, Best-of-N, or reward-model-based ranking, with several recent works leveraging intrinsic signals like perplexity or average log-probability as proxies for answer quality. However, these methods typically operate in an empirical or heuristic regime and do not formally decompose the sampled confidence distribution into underlying latent structure.
This paper identifies that, upon repeated answer generation, the distribution of trajectory-level confidences is bimodal, corresponding approximately to 'correct' and 'incorrect' solution populations. Under this hypothesis, DistriVoting uses a Gaussian Mixture Model (GMM) to fit the distribution of confidences.
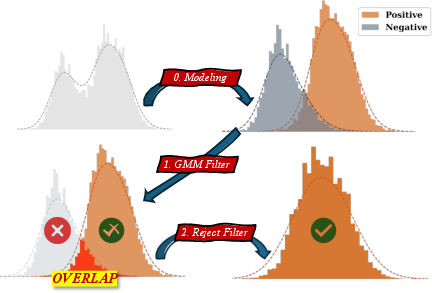
Figure 1: Overview of DistriVoting, illustrating GMM modeling, negative sample filtering, and rejection of false positives.
The GMM then segregates trajectories into positive (higher mean, presumed correct) and negative (lower mean, presumed incorrect) pools. A two-stage filtering process is applied: a GMM-based filter selects for the positive component, and a reject filter further eliminates false positives by leveraging information from highly negative-confidence samples. The final selection employs hierarchical weighted majority voting stratified by confidence intervals.
Stepwise Confidence Monitoring and Dynamic Reflection
Beyond downstream voting, the SelfStepConf module introduces dynamic test-time intervention. During autoregressive sequence generation, step-level confidences are computed by aggregating per-token top-k log-probabilities over semantic blocks, which are dynamically identified (e.g., via paragraph boundaries or high-entropy token positions).
SSC performs online monitoring: when step confidence drops below an exponentially-moving average threshold, a reflection operation is triggered, injecting a fixed reflection token (e.g., "wait") for a small number of steps by manipulating the token logit distribution. The rationale is to induce local divergence and model-driven reevaluation, promoting separation between correct and incorrect trajectory distributions and mitigating premature convergence on low-quality completions.
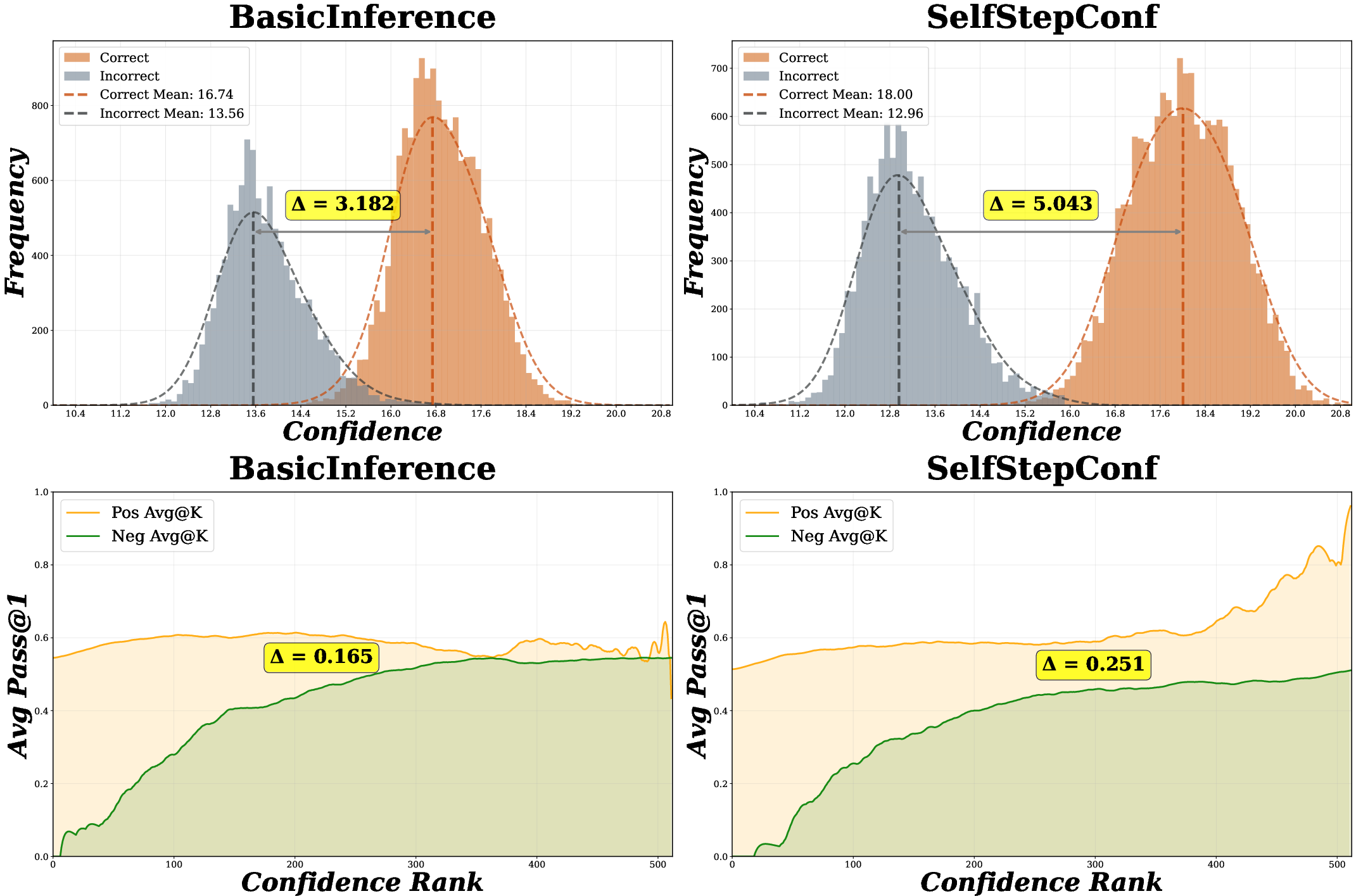
Figure 2: Histogram of confidence distribution and interval-based accuracy after SSC, large separation of two confidence modes.
Theoretical Analysis
The work provides theoretical justification for the key design: maximizing the mean separation δ=μpos−μneg in the bimodal confidence distribution provably increases post-filter voting accuracy. Specifically, for f(x) and g(x) as the density functions of the positive and negative Gaussians, the paper establishes that the right-tail ratio (with respect to the mid-point threshold) is strictly monotonic in δ. This is non-trivial: it establishes that improvements in distributional separation—whether by confidence engineering at the trajectory or step level—are guaranteed to lift answer selection performance, independent of the particular majority voting aggregation scheme.
Empirical Results and Quantitative Analysis
The proposed DistriVoting and SSC components are evaluated on 16 models—including DeepSeek-R1-8B, Qwen3-32B (in both thinking and non-thinking modes), and more—and across five challenging mathematical reasoning benchmarks (e.g., HMMT2025, GPQA-D, BRUMO2025). Budgets up to 128 trajectories and 64 sampling repeats are used per query.
Major empirical findings include:
- DistriVoting provides consistent and substantial performance gains over classical methods (Self-Consistency, BoN, WSC), with average improvements of up to 2-3% across strong baselines and up to 8-10% in individual benchmarks for selected models.
- Adaptive distribution-based filtering with GMM outperforms fixed-top-k percentile filtering, with optimal thresholds varying by model/benchmark (see Figure 3).
- Table-level results exhibit that mean accuracy (Acc) for the final positive pool increases from 69.27% (pre-filtering) to 80.41% after both GMM and reject filtering.
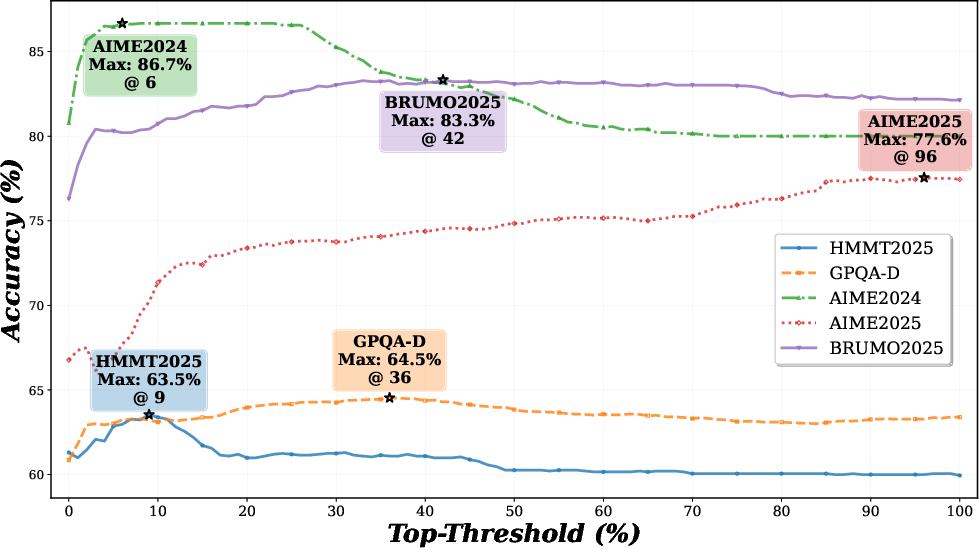
Figure 3: Optimal top-threshold traversal. Fixed percentile filters cannot adapt distributional shifts; GMM-based filters are consistently superior.
- The inclusion of SSC further increases the separation between positive/negative confidence distributions, boosting the density of correct answers in high-confidence pools and achieving up to 0.09 improvements in AUROC for some model/benchmark combinations (see Figure 2).
- Figure 4 and Figure 5 demonstrate that SSC raises pass@K (especially pass@1) for medium-range models, and that its effect converges as K increases—i.e., it increases sampling efficiency rather than expanding the fundamental solution set.
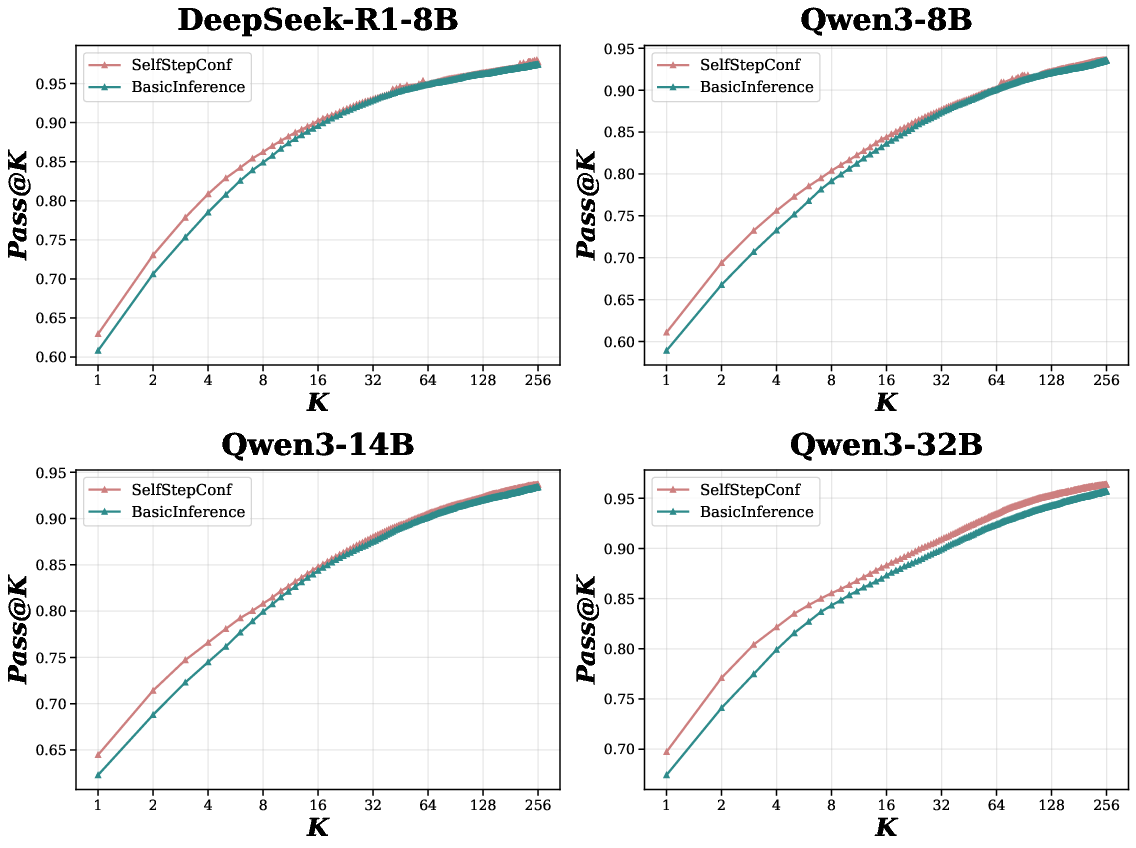
Figure 4: Pass@K (increasing K) for SSC vs BasicInference, showing superior sample efficiency for SSC.
- SSC does not necessarily increase the average token count per response—reflection-induced interventions improve answer quality without the cost of longer generations (see Figure 6).
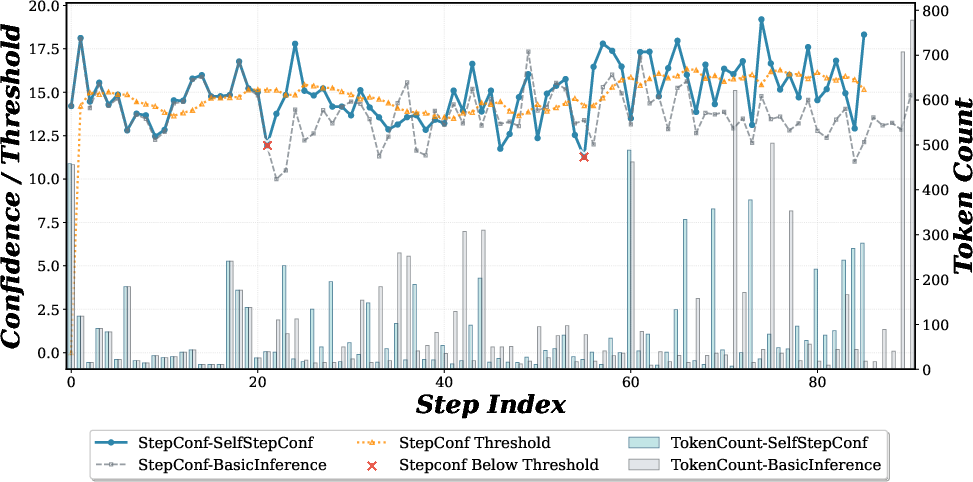
Figure 6: SSC trajectories exhibit higher confidence with only a modest increase in computational overhead per token.
- Extensive ablation studies confirm the superiority of GMM versus simpler clustering or fixed-threshold strategies and show that improvements are robust over a range of hyperparameter selections.
Practical and Theoretical Implications
Distribution-guided calibration shifts TTS answer selection from empirical, model-agnostic heuristics to methods that explicitly leverage the statistical structure of model-internal signals. This enables more sample-efficient answer aggregation and improved reliability without introducing auxiliary verifier or reward models, preserving test-time efficiency and maintaining training-independence.
Theoretically, the direct link between distributional separation and voting accuracy provides a framework for analyzing and predicting the benefit of architectural interventions, training protocols, or generation strategies, as long as their effect can be cast in terms of modulating the separation of the intrinsic confidence distribution.
Practically, these findings invite future work in jointly optimizing for confidence calibration and correct/incorrect separation during both model pretraining and fine-tuning. The stepwise, real-time dynamic adjustment approach of SSC can inspire adaptive sampling and reflection policies beyond chain-of-thought mathematics, including code generation, sequential decision making, and other areas where answer reliability varies over semantic blocks.
Conclusion
The paper establishes DistriVoting and SelfStepConf as effective, theoretically grounded improvements to test-time scaling in LLMs. By explicit modeling and manipulation of the confidence signal, these methods reliably increase post-hoc answer selection accuracy with the same sampling budget and negligible computational overhead. The work lays a technical foundation for further integration of distributional calibration in inference pipelines and motivates systematic study of the interplay between training objectives, model scaling, intrinsic signal structure, and sample-efficient test-time performance.

