The Art of Scaling Reinforcement Learning Compute for LLMs
Abstract: Reinforcement learning (RL) has become central to training LLMs, yet the field lacks predictive scaling methodologies comparable to those established for pre-training. Despite rapidly rising compute budgets, there is no principled understanding of how to evaluate algorithmic improvements for scaling RL compute. We present the first large-scale systematic study, amounting to more than 400,000 GPU-hours, that defines a principled framework for analyzing and predicting RL scaling in LLMs. We fit sigmoidal compute-performance curves for RL training and ablate a wide range of common design choices to analyze their effects on asymptotic performance and compute efficiency. We observe: (1) Not all recipes yield similar asymptotic performance, (2) Details such as loss aggregation, normalization, curriculum, and off-policy algorithm primarily modulate compute efficiency without materially shifting the asymptote, and (3) Stable, scalable recipes follow predictable scaling trajectories, enabling extrapolation from smaller-scale runs. Combining these insights, we propose a best-practice recipe, ScaleRL, and demonstrate its effectiveness by successfully scaling and predicting validation performance on a single RL run scaled up to 100,000 GPU-hours. Our work provides both a scientific framework for analyzing scaling in RL and a practical recipe that brings RL training closer to the predictability long achieved in pre-training.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What This Paper Is About
This paper is about making the “second stage” of training LLMs—called reinforcement learning (RL)—more predictable and efficient. Pre-training already follows clear “scaling laws” (more compute → steady, predictable gains). But for RL, people often rely on trial-and-error. The authors build a simple, scientific way to predict how much better an LLM will get as you spend more compute on RL, and they share a practical training recipe (called ScaleRL) that follows those predictable patterns even at very large scales (up to 100,000 GPU-hours).
Think of it like this: they want RL for LLMs to be less of an art project and more of a science experiment you can plan and forecast.
What Questions Did They Ask?
- Can we predict how well an LLM will do after RL, just from small early runs, instead of guessing and spending huge amounts of compute?
- Which training choices raise the “ceiling” (the best possible performance you can reach), and which ones only make you reach that ceiling faster?
- Is there a reliable recipe for RL (ScaleRL) that is stable and predictable at big scales?
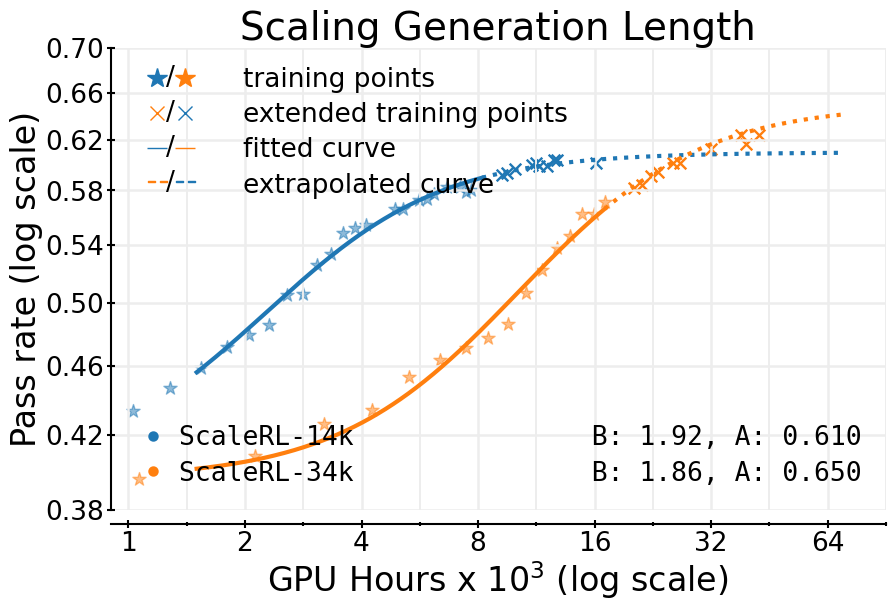
- Do these predictions still hold when we change things like model size, batch size, or how long the model is allowed to “think” (the number of tokens)?
How They Did It (In Simple Terms)
The team ran a very large set of RL experiments (over 400,000 GPU-hours). A GPU-hour is like paying for one powerful graphics card to work for one hour—so this is a lot of compute.
They trained LLMs (mostly on math problems, and also some code) using RL, where:
- The model generates several possible answers to a prompt.
- Each answer gets a simple score (reward): correct or not.
- The model is nudged to generate better answers over time based on these rewards.
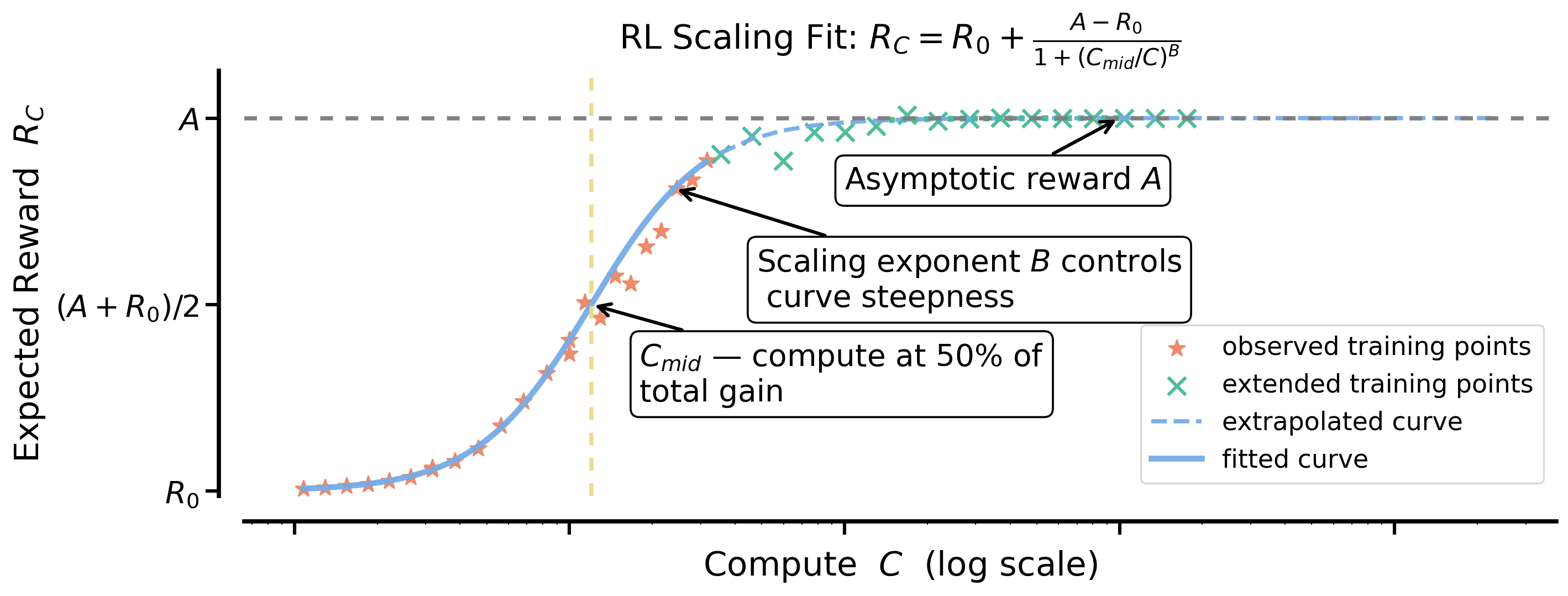
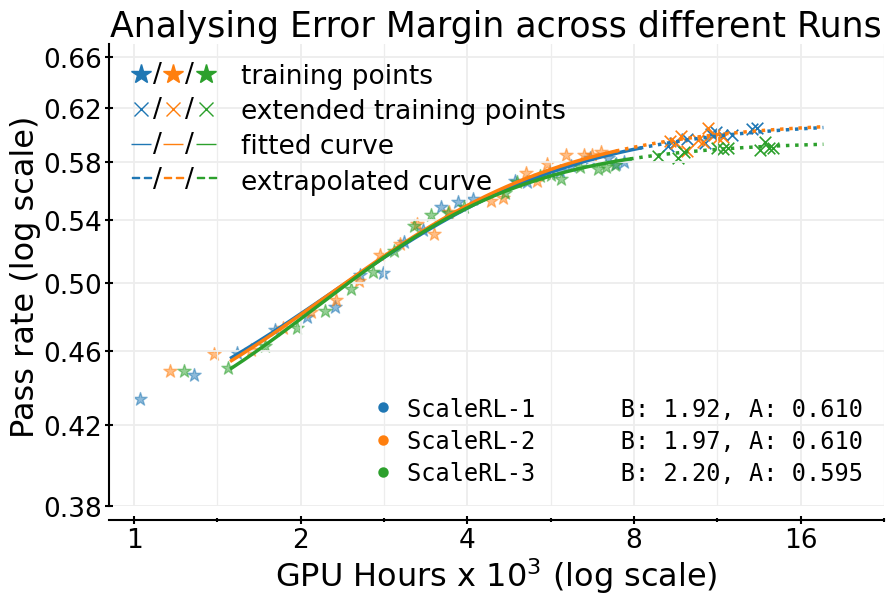
To make predictions, they fit an S-shaped curve (a “sigmoid”) that relates compute (how much training you do) to performance (how often the model answers correctly on a held-out validation set). Why an S-curve?
- At the start, progress is slow (the model is just warming up).
- Then progress speeds up as learning clicks.
- Finally, it levels off near a ceiling (you can’t improve forever).
They describe this curve with three easy ideas:
- A (the “asymptote”): the ceiling—the best you can hope to reach if you train long enough.
- B (efficiency): how quickly you climb toward that ceiling.
- C_mid (midpoint): the compute level where you’ve achieved about half of your total possible improvement.
They also:
- Compared many RL design choices (like loss functions, precision settings, batching, and how to handle very long answers).
- Used an “asynchronous” training setup (called PipelineRL) that keeps GPUs busy so training is faster and steadier.
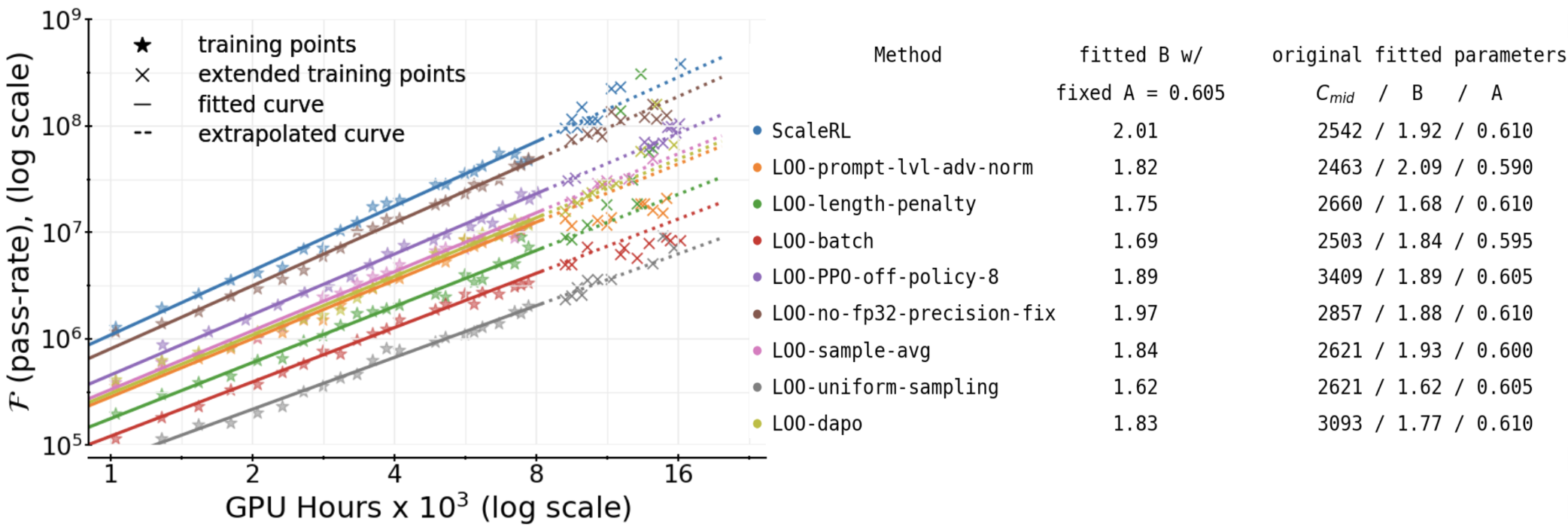
- Did “leave-one-out” tests: build the best recipe, then remove one piece at a time to see what really matters.
- Checked that early-run fits of the S-curve can predict later performance—even when they doubled the compute.
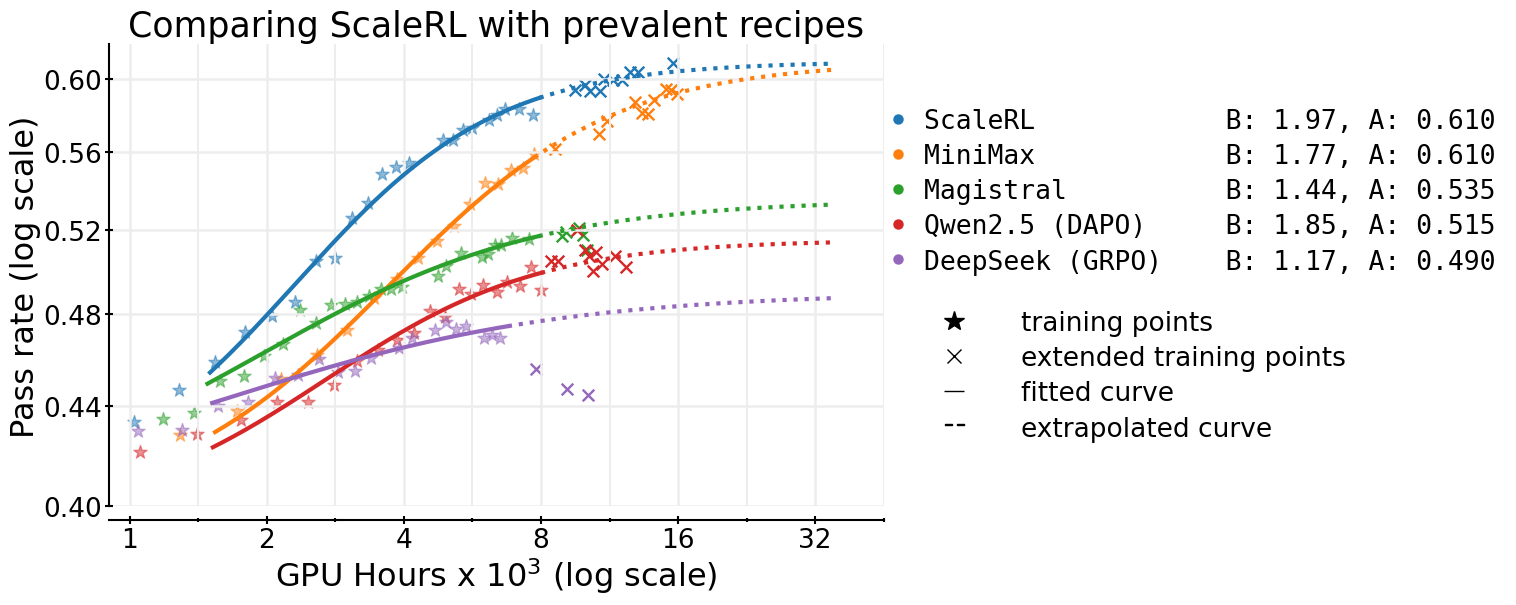
What They Found (Key Results)
Here are the main takeaways, explained with simple ideas first and details after:
- Not all RL recipes end up at the same ceiling.
- Many common tricks don’t raise the ceiling—but they do help you reach it faster.
- If your recipe is stable, its progress follows a predictable S-curve. That means you can forecast big-run results from smaller runs.
- The authors’ ScaleRL recipe scales smoothly and matches its predicted curve up to 100,000 GPU-hours.
Some highlights:
- Predictable scaling: Fitting the S-curve early (after a small chunk of compute) lets you reliably predict final performance later. Their forecasts matched actual results at large compute.
- Ceiling vs. efficiency:
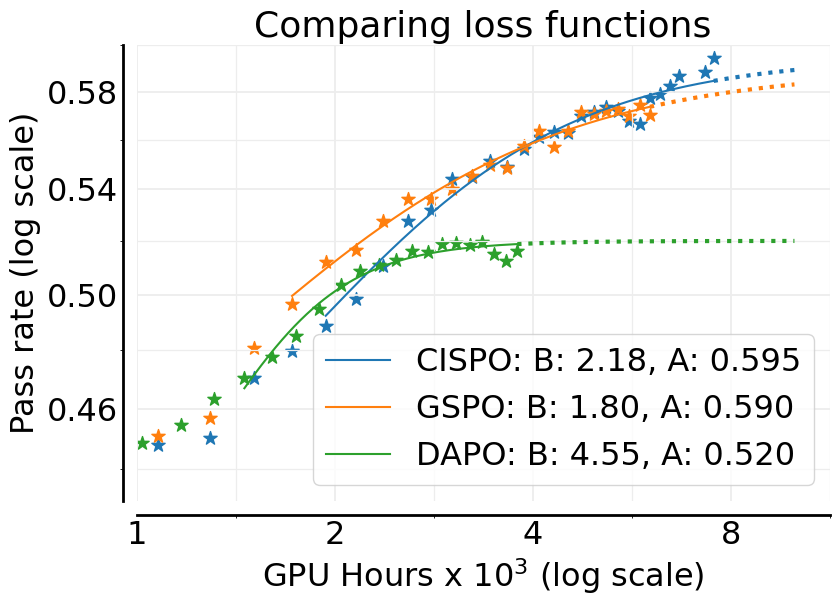
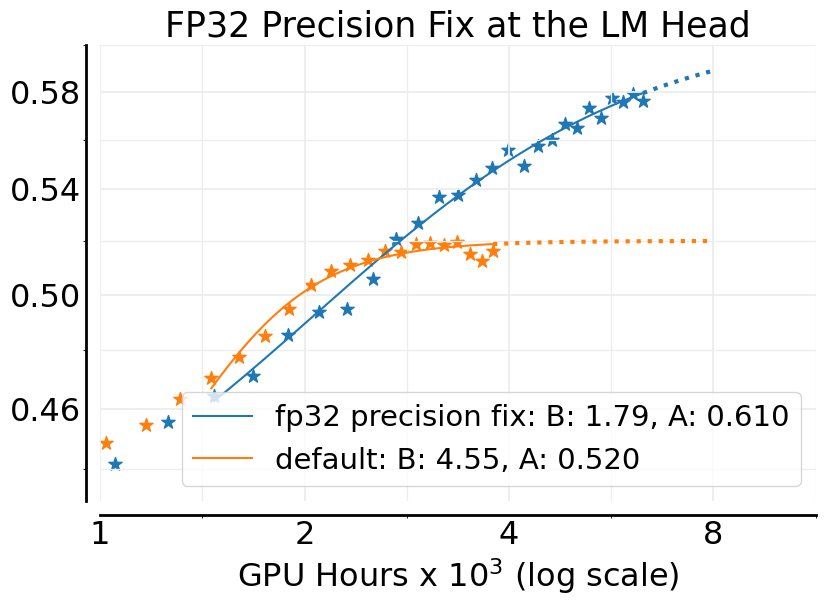
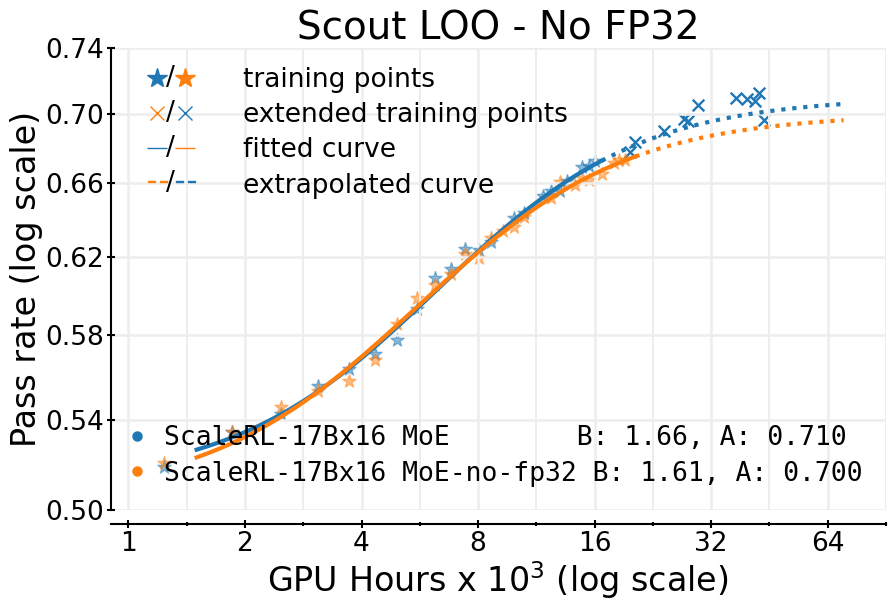
- Choices like the loss function (they favor CISPO), and a precision fix (using FP32 at the model’s final layer) improved the ceiling (A).
- Choices like how to combine losses, normalize rewards, and curriculum (dropping prompts that are already easy) mostly improved efficiency (B)—you get to the ceiling faster but don’t change the ceiling much.
- Better infrastructure: PipelineRL (an asynchronous setup) made training more efficient than a common alternative, so you waste less time and get more learning per unit of compute.
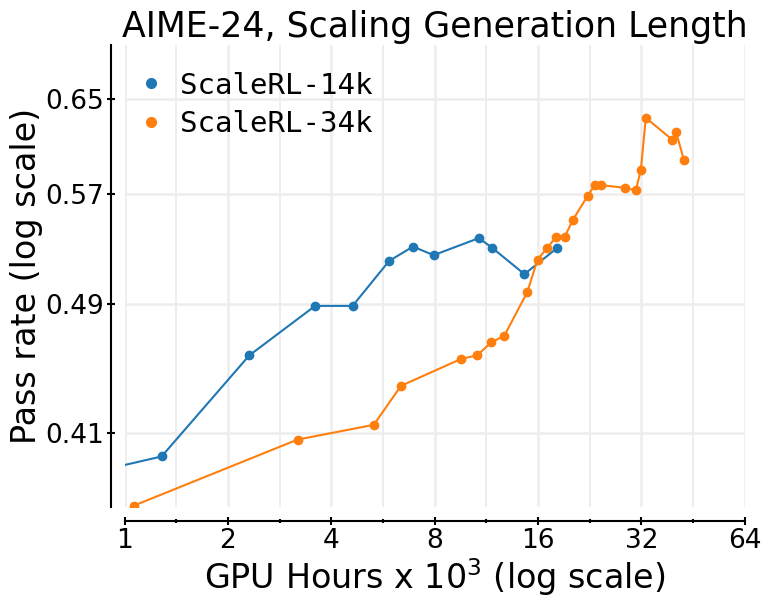
- Longer thinking helps: Allowing longer “reasoning” (more tokens for the model to think) starts slower but raises the ceiling—given enough compute, it wins.
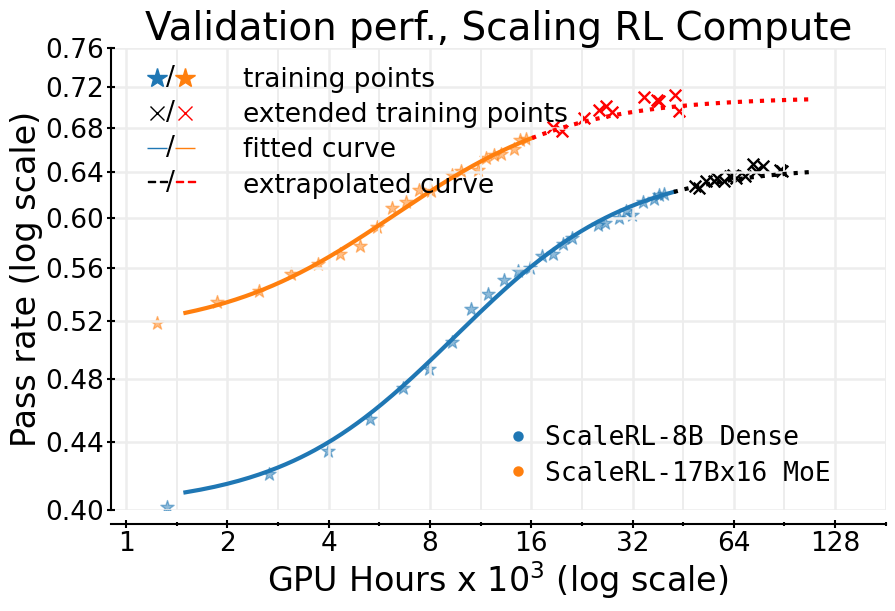
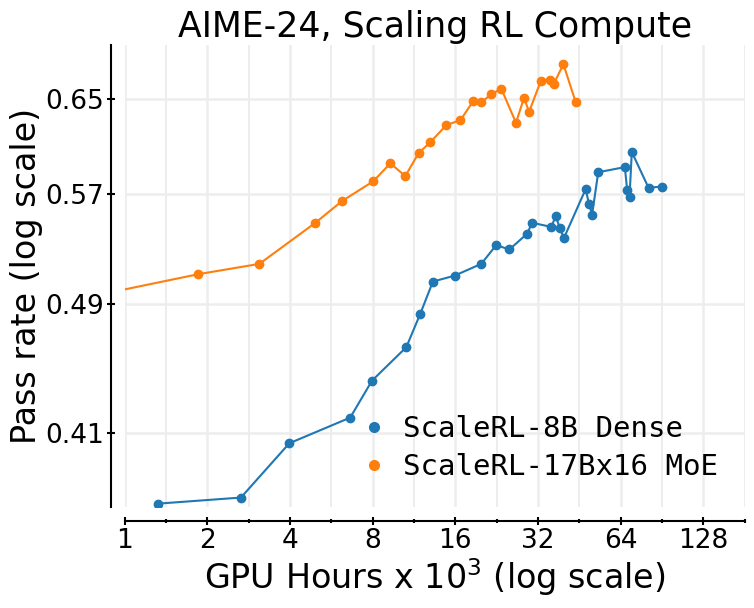
- Bigger models help: A larger “mixture-of-experts” model (a team of mini-models working together) reached a higher ceiling with less RL compute.
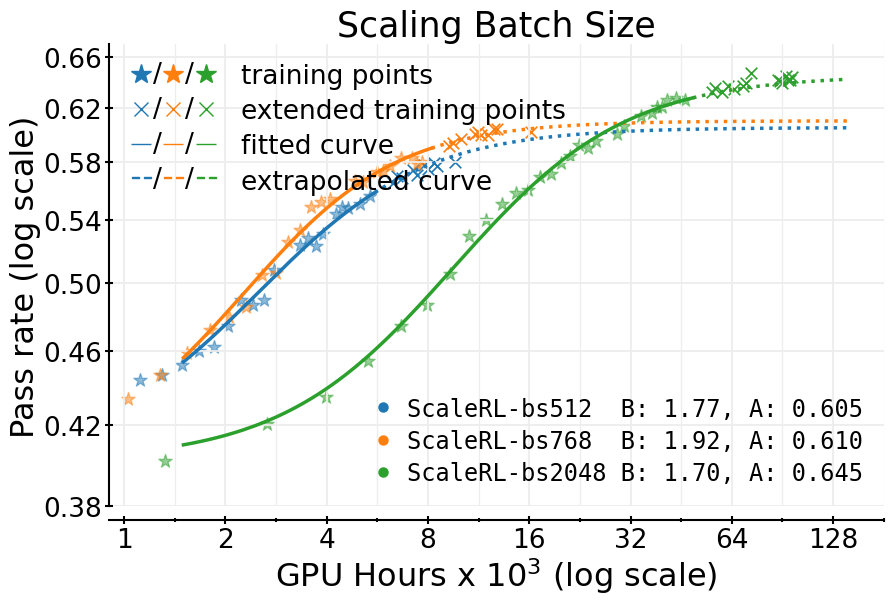
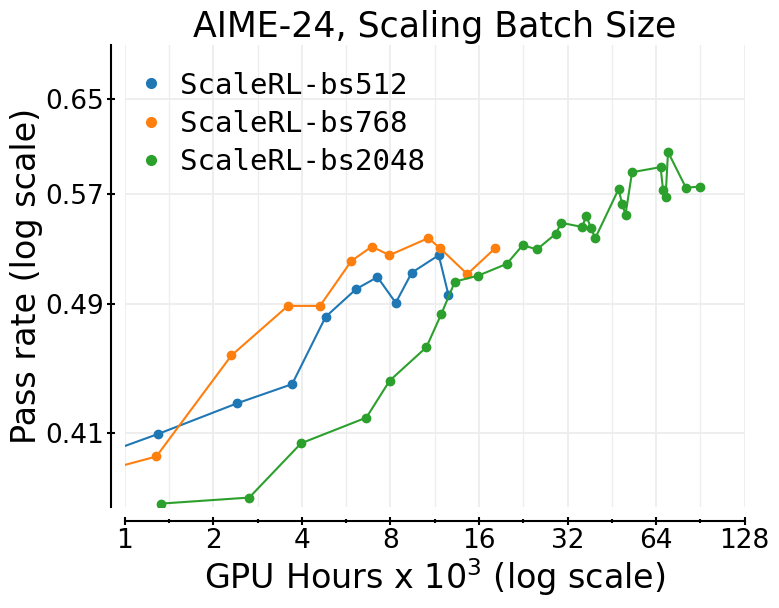
- Batch size matters: Larger batches sometimes look worse early on but end up reaching a higher ceiling as training continues.
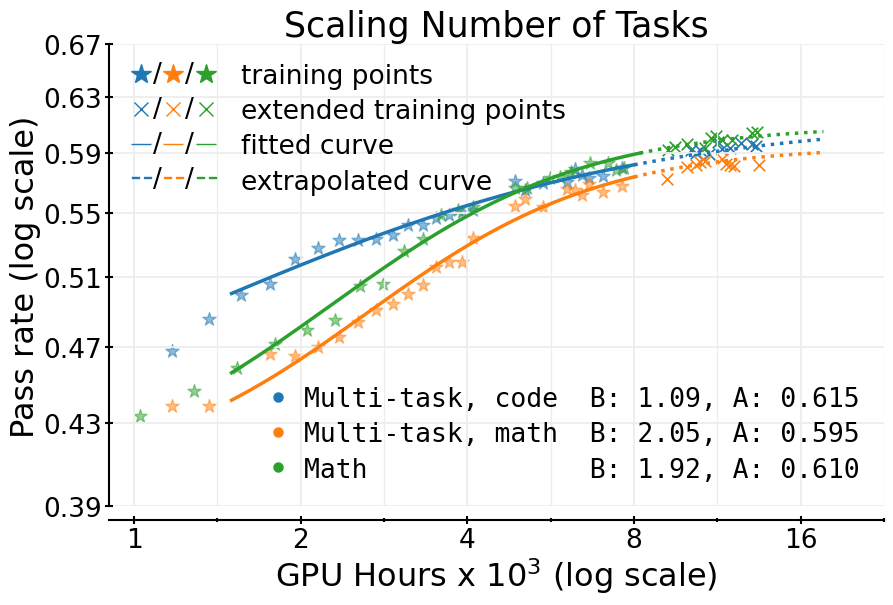
- Stable across tasks: The S-curve predictions held for math-only and math+code training, and improvements showed up on outside tests too.
Why This Is Important
- Planning and fairness: Researchers (including those with smaller budgets) can use early, cheaper runs to predict whether a method is worth scaling up. That helps everyone compete and innovate without gambling massive compute.
- Faster progress: Instead of guessing, you can compare methods by their predicted ceiling and efficiency. That speeds up research and reduces wasted compute.
- A reliable recipe: ScaleRL is a tested, stable starting point—like a good “house style” for RL training that others can build on.
A Bit More Detail on Practical Choices (Plain Language)
- Loss function: CISPO worked best overall. Think of it as a clean way to use the model’s old and new probabilities to update safely and steadily.
- Precision fix (FP32 at the head): Using higher precision for the final step where the model picks the next token reduced tiny math mismatches and led to better top-end performance.
- Length control: The model can sometimes ramble. They use a forced “end of thinking” message to cap how long it thinks. This keeps training stable and efficient.
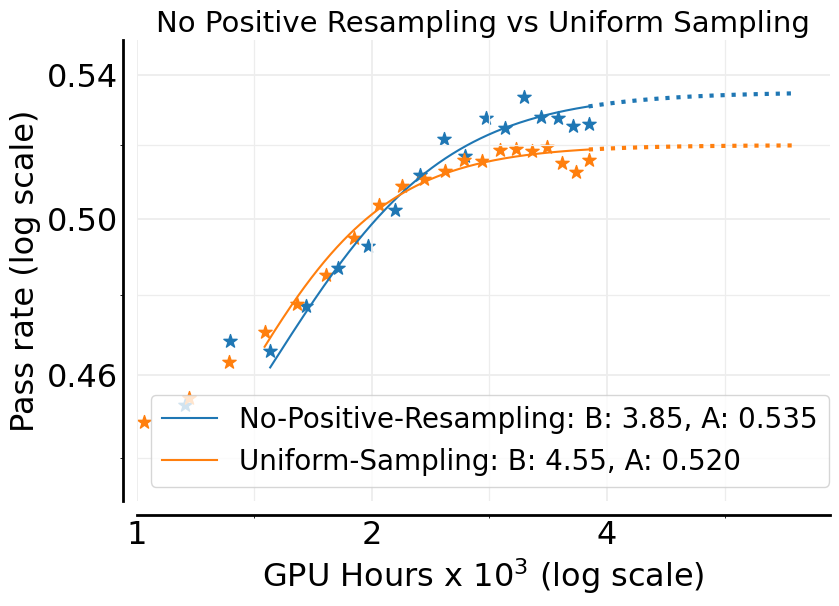
- Curriculum (No-Positive-Resampling): If a prompt is already too easy (the model almost always gets it right), don’t keep using it—it no longer teaches the model anything.
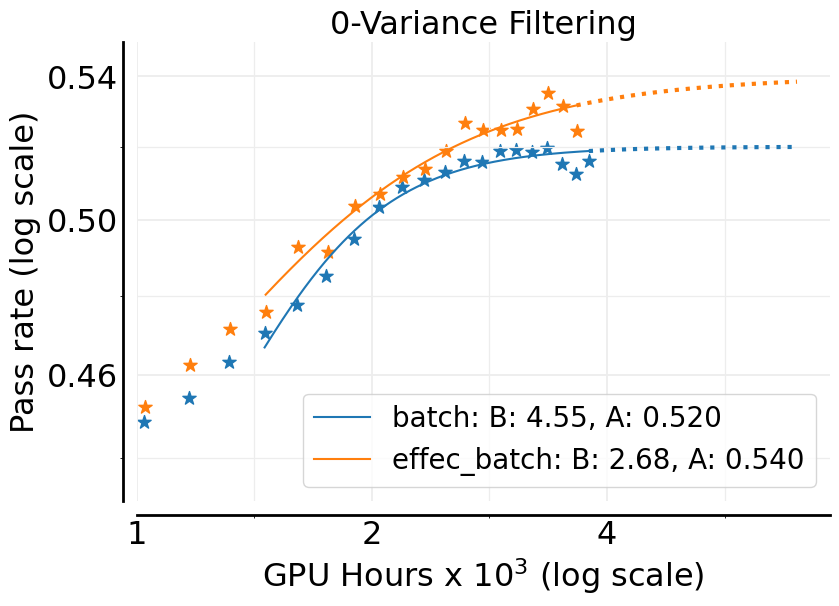
- Zero-variance filtering: If all attempts for a prompt get the same reward, that prompt won’t help learning that step—skip it so useful examples get more attention.
What This Means Going Forward
- Predictable RL scaling: Just like pre-training, RL for LLMs can be guided by simple curves and clear parameters. That makes large-scale experiments more scientific and less risky.
- Smarter compute use: You can pick what to scale (model size, batch size, context length) based on whether you want a higher ceiling or faster climb.
- Broader impact: The same framework could help study other advanced training setups (like multi-turn conversations or agents that interact with tools) by measuring predictability and scaling behavior there too.
Final Thoughts
The authors turn RL for LLMs from guesswork into a planned journey. With a simple S-curve, they show how to predict where you’ll end up (the ceiling) and how quickly you’ll get there (the efficiency). Their ScaleRL recipe follows this predictable path all the way to 100,000 GPU-hours. For researchers and engineers, this means fewer surprises, better budgeting, and faster progress toward smarter, more reliable AI systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper establishes a practical framework and recipe for scaling RL compute for LLMs, but several aspects remain uncertain or unexplored. Future researchers could address the following gaps:
- Lack of theoretical justification for the sigmoidal compute–performance curve: why
R_C = A - (A - R_0) / (1 + (C/C_mid)^B)(or its equivalent form) should emerge from RL dynamics, and under what assumptions it outperforms power laws. - Parameter identifiability and fitting reliability: rigorous quantification of uncertainty for
A,B, andC_midbeyond ±0.02 onA(only 3 seeds), including confidence intervals, sensitivity to fit windows, and automatic detection of the “stable” regime after excluding early training (<1.5k GPU-hours). - Standardized compute accounting: comparisons mix algorithmic effects with infrastructure utilization (e.g., PipelineRL reduces “idle time”). Normalize by model FLOPs or tokens processed to separate engineering throughput from algorithmic efficiency.
- Generalization beyond in-distribution validation: systematic study of how in-distribution pass-rate improvements translate to out-of-distribution and downstream tasks, including robust correlation analyses, calibration, and failure cases (the paper reports AIME-24 but does not fully characterize generalization).
- Risk of overfitting from multi-epoch RL on a fixed prompt set: quantify overfitting and catastrophic forgetting (especially with No-Positive-Resampling), and develop regularizers or curricula that preserve generalization while improving efficiency.
- Reward design and verifier dependence: results rely on verifiable math/code rewards with pass-rate metrics; scalability to tasks without deterministic verifiers (open-ended reasoning, dialog, safety alignment) and to structured/dense rewards is untested.
- Robustness of the recipe to KL regularization and entropy controls: the main recipe omits KL; explore whether scaling predictability persists when adding KL/entropy terms commonly used for stability and alignment, and how these change
A/B. - Off-policy bias and convergence guarantees: PipelineRL with stale KV caches and truncated importance sampling (CISPO) is effective empirically, but the bias/variance trade-offs, convergence properties, and failure modes are not analyzed theoretically.
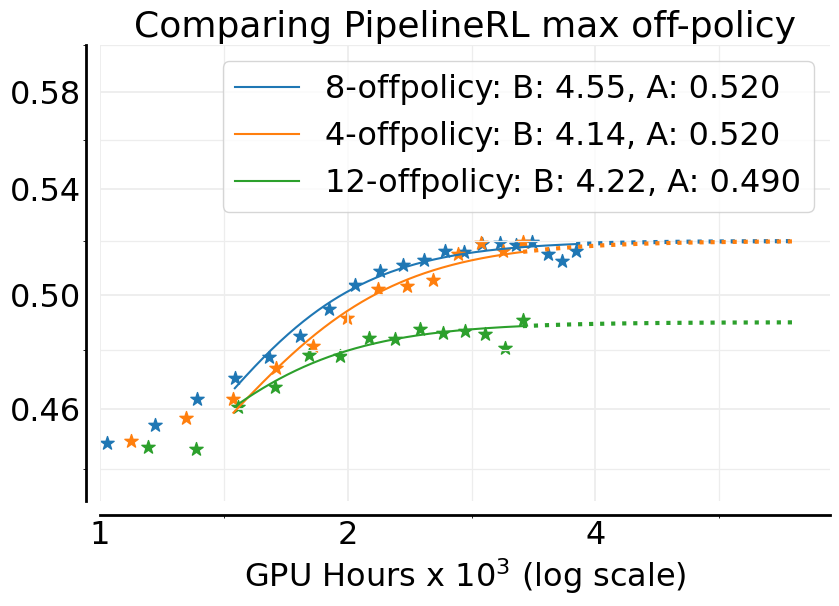
- Choice of maximum off-policyness
k=8: provide principled guidance or analysis explaining whyk=8is optimal and how to choosekunder varying generator/trainer speeds, hardware, and batch schedules. - CISPO vs. GSPO vs. DAPO beyond math/code: assess whether the observed asymptotic gains of CISPO generalize across domains (dialog, tool use, multi-turn tasks), and characterize hyperparameter robustness (e.g., IS clipping
ε_max, learning rates) at scale. - Length control via forced interruptions: quantify trade-offs relative to length penalties on reasoning quality, truncation rates, exploration, and downstream transfer, especially at 32k+ contexts and multi-turn settings.
- Allocation of compute across axes: derive compute-optimal policies for batch size, context length, generations per prompt, and model size that jointly optimize
AandB, rather than axis-by-axis sweeps. - Joint scaling laws across pre-training compute, RL compute, model size, and data size: provide a unified framework to predict returns when co-scaling these factors and to decide the optimal RL budget relative to pre-training.
- Multi-task RL mixtures: beyond math+code, study mixture weighting, curriculum schedules, and cross-task interference; develop predictive scaling fits for each task under joint training and methods to detect/improve negative transfer.
- Generations-per-prompt allocation at very large batches: the paper notes second-order effects at moderate batches; systematically test at 2k+ total generations to confirm or refute invariance of scaling curves.
- Reward distribution and advantage normalization: analyze how reward noise, skew, and multi-modality affect gradient variance and scaling parameters; evaluate alternative normalization schemes and their impact on
B. - Zero-variance prompt filtering: quantify statistical bias introduced by dropping zero-variance prompts, its effect on gradient estimation, and whether adaptive resampling (vs. dropping) yields better scaling.
- Data curation and contamination: assess training/eval leakage risks in Polaris-53K/AIME-24, and the robustness of scaling curves under different datasets, difficulty distributions, and contamination controls.
- Architecture generality: results focus on Llama-4 8B dense and 17B×16 MoE; validate predictability across diverse architectures (e.g., different tokenizer, attention variants, decoder-only vs. encoder–decoder) and vendor stacks.
- Safety and alignment: examine whether compute-scaling recipes that optimize pass-rate metrics degrade safety, calibration, or controllability, and how to integrate safety rewards/constraints without breaking predictability.
- Stability at extreme scales: beyond 100k GPU-hours, identify instability modes (e.g., entropy collapse, reward hacking, drift) and develop early-warning diagnostics tied to curve-fit residuals or training signals.
- Evaluation protocol standardization: define a common validation protocol (generations per prompt, sampling temperature, pass-rate definition, sequence length) to ensure fair cross-recipe comparisons and reproducibility.
- Hardware and kernel nondeterminism: FP32 logits at the LM head help, but residual mismatches between generator/trainer kernels remain unquantified; measure their impact on IS ratios and scaling fits across toolchains.
- Early-extrapolation reliability: formalize how much early data (compute window size) is needed for reliable extrapolation, including criteria to reject unstable fits and quantify expected forecast error.
- Public reproducibility: the paper releases curve-fitting code but not training pipelines, datasets, or checkpoints; full reproducibility artifacts (configs, logs, seeds, eval scripts) are needed to validate scaling claims across labs.
Practical Applications
Immediate Applications
Below are practical, real-world uses you can deploy now based on the paper’s findings and the ScaleRL recipe, organized by audience and sector.
- Compute-to-performance forecasting for RL training
- Sectors: software/AI, finance (cost optimization), energy (compute planning)
- Tools/Workflows: sigmoidal curve fitting for pass rate vs. compute; integration into ML Ops dashboards for budget planning and early-stop decisions
- Assumptions/Dependencies: access to an IID held-out validation set with verifiable rewards; exclude the very early training regime (~first 1.5k GPU-hours) for stable fits; consistent hardware stack between runs
- Adopt ScaleRL to stabilize and scale LLM RL training
- Sectors: software/AI platforms, cloud providers
- Tools/Workflows: PipelineRL-8 (asynchronous generator–trainer split), CISPO loss, prompt-level loss aggregation, batch-level advantage normalization, FP32 logits, zero-variance filtering, No-Positive-Resampling, interruption-based length control
- Assumptions/Dependencies: distributed training infrastructure (generator/trainer split), reward functions that can produce verifiable pass rates, support for FP32 at LM head in both inference and training kernels
- Early-stop and dynamic budget allocation across experiments
- Sectors: finance (R&D portfolio management), energy (cluster scheduling), software/AI
- Tools/Workflows: use fitted curves to detect diminishing returns, reallocate compute from low-slope runs to promising ones; automated pipelines to pause/extend runs based on predicted asymptote and efficiency (A, B)
- Assumptions/Dependencies: reliable pass-rate telemetry; common evaluation protocol across runs
- Numerical precision audits to reduce generator–trainer mismatch
- Sectors: software/AI infrastructure, hardware/software co-design
- Tools/Workflows: enforce FP32 computation at LM head in both inference and training; regression tests on IS ratios and loss consistency
- Assumptions/Dependencies: kernels and hardware that can expose FP32 logits without prohibitive throughput loss; especially beneficial for IS-based losses
- Switch to PipelineRL with bounded off-policyness (k≈8)
- Sectors: distributed systems, software/AI
- Tools/Workflows: streaming generation with immediate parameter pushes; trainer-side backpressure when k steps ahead; monitoring off-policyness to balance efficiency vs. stability
- Assumptions/Dependencies: well-engineered async dataflow; KV-cache reuse handling; metrics on truncations and instability
- Reward-efficient batching via zero-variance filtering
- Sectors: data engineering, training efficiency
- Tools/Workflows: drop prompts whose generations have identical rewards (no gradient contribution) from effective batch; align batch accounting with gradient-yielding samples
- Assumptions/Dependencies: scalar rewards with prompt-level variance; reward computation available before loss aggregation
- Data curriculum with No-Positive-Resampling
- Sectors: data ops, software/AI training
- Tools/Workflows: maintain per-prompt pass-rate history; permanently exclude prompts once pass rate ≥0.9; reduce wasted compute on already-mastered items
- Assumptions/Dependencies: reliable pass-rate tracking; stability of “easy” prompts over epochs; careful control to avoid distribution shift that harms generalization
- Context-length and batch-size tuning guided by fitted curves
- Sectors: product LLMs (reasoning assistants), education (math tutors), developer tools (code generation)
- Tools/Workflows: use early fits to decide when to adopt longer generation budgets (e.g., 32k tokens) or larger batch sizes to raise asymptotes and downstream performance
- Assumptions/Dependencies: sufficient compute; interruption-based length control; downstream tasks that benefit from longer reasoning traces
- Multi-task RL scaling (math + code) with parallel monitoring
- Sectors: software/AI products, education
- Tools/Workflows: joint training schedules while tracking separate validation curves per domain; apply the same curve-fitting methodology per task
- Assumptions/Dependencies: domain-appropriate reward functions; balanced data mixture; separate IID validation sets for each domain
- Academic benchmarking and method triage at small budgets
- Sectors: academia, open-source research
- Tools/Workflows: use the released curve-fitting code to estimate A and B from small runs; rank methods by predicted asymptote and efficiency before scaling
- Assumptions/Dependencies: shared datasets (e.g., Polaris-53k), reproducible training seeds, standardized telemetry
- ESG and compute planning dashboards
- Sectors: policy, sustainability, enterprise governance
- Tools/Workflows: map predicted compute requirements to carbon intensity and cost; justify training extensions with expected accuracy gains
- Assumptions/Dependencies: carbon accounting per GPU-hour; stable mapping from compute to performance; organization-level reporting frameworks
- Procurement and capacity planning based on efficiency (B)
- Sectors: finance/ops, cloud cost management
- Tools/Workflows: treat B and C_mid as input to cost models; choose hardware and instance types that maximize predicted gains per dollar
- Assumptions/Dependencies: comparable kernels across vendors; consistent throughput and numerical behavior
Long-Term Applications
The following applications require further research, scaling, or ecosystem development before broad deployment.
- Automated RLops controllers that adjust training knobs in real time
- Sectors: software/AI platforms, cloud ML services
- Tools/Workflows: closed-loop systems that tune batch size, context length, off-policyness k, and loss clipping to follow target scaling trajectories
- Assumptions/Dependencies: robust online curve fitting; reliable variance estimates; guardrails against instability
- Organization-level portfolio optimization across model families
- Sectors: industry R&D, finance
- Tools/Workflows: meta-optimizers that distribute compute between dense and MoE models, varying batch/context lengths, guided by predicted asymptotes and downstream needs
- Assumptions/Dependencies: consistent evaluation suites; cross-model comparability; policy constraints (budget, ESG)
- Standards for RL scaling reporting and governance
- Sectors: policy/regulation, industry consortia
- Tools/Workflows: shared protocols to publish scaling parameters (A, B, C_mid), validation datasets, and exclusion windows; auditable training logs
- Assumptions/Dependencies: broad buy-in; harmonized benchmarks and metrics; legal/privacy considerations for datasets
- Sector-specific RL fine-tuning with predictable returns
- Sectors: healthcare (clinical reasoning support), law (contract analysis), finance (risk modeling), education (personalized tutoring)
- Tools/Workflows: domain reward design; verified task suites; curve-fitting to plan compute for specialized models
- Assumptions/Dependencies: trustworthy reward signals (e.g., programmatic verifiers or expert-labeled outcomes); regulatory compliance; domain-specific generalization studies
- Energy-aware training schedulers for carbon minimization
- Sectors: energy, sustainability, cloud providers
- Tools/Workflows: use performance forecasts to shift training windows to lower-carbon grid periods while meeting target curves
- Assumptions/Dependencies: accurate real-time grid data; flexible job orchestration; acceptable training latency
- Marketplace of packaged RL components and recipes
- Sectors: software tooling, open-source ecosystems
- Tools/Workflows: modular implementations of PipelineRL, CISPO, FP32 logits, zero-variance filtering, and curricula; plug-and-play with standard telemetry
- Assumptions/Dependencies: interoperability across frameworks (PyTorch, JAX); reproducibility guarantees
- Robust scaling laws across axes (pre-training compute, model size, RL data)
- Sectors: academia, industry research
- Tools/Workflows: multi-axis meta-analyses to quantify optimal compute allocation between pre-training and RL for targeted capabilities
- Assumptions/Dependencies: large-scale shared experiments; cross-institution collaboration; careful treatment of generalization vs. in-distribution fits
- Safer agentic RL scaling with verifiable rewards
- Sectors: robotics, autonomous systems, AI safety
- Tools/Workflows: extend the framework to multi-turn, interactive, or long-form agent tasks; combine generative verifiers with structured rewards
- Assumptions/Dependencies: robust and safe reward mechanisms; monitoring for entropy collapse or unsafe modes; higher compute budgets
- Long-context reasoning products that exploit ceiling gains
- Sectors: productivity assistants, education, scientific discovery
- Tools/Workflows: product lines that rely on 32k+ token reasoning; specialized interruption strategies; curriculum pipelines to unlock higher asymptotes
- Assumptions/Dependencies: UI/UX that supports long chain-of-thought; memory and latency constraints; verified benefit on downstream tasks
- Regulatory compliance and compute-cap audits using predictive curves
- Sectors: public policy, compliance
- Tools/Workflows: certify expected compute footprints and accuracy gains before training; track realized vs. predicted performance for accountability
- Assumptions/Dependencies: formal regulatory frameworks; standardized auditing practices; secure logging
- Early risk management to avoid sunk-cost experiments
- Sectors: enterprise ML governance, finance
- Tools/Workflows: kill-switches triggered by poor predicted asymptotes or efficiency; automated “pivot plans” to alternative recipes or models
- Assumptions/Dependencies: reliable predictive intervals; variance-aware decision thresholds
- Enhanced developer tools from multi-task RL scaling
- Sectors: software engineering
- Tools/Workflows: code copilots trained with predictable multi-task scaling; domain-mixed curricula to balance math, code, and reasoning
- Assumptions/Dependencies: generalization beyond in-distribution validation; robust code evaluation and reward design
Notes on General Feasibility
- The methodology is most reliable on tasks with verifiable rewards (e.g., math/code pass rates). Open-ended tasks will need stronger reward modeling (e.g., generative verifiers).
- Early-stage fits should exclude the very low-compute regime to improve stability; variance estimates are necessary to judge meaningful differences across recipes.
- Hardware/kernel determinism matters: FP32 at LM head reduces numerical mismatch that destabilizes IS-based losses.
- Some choices primarily improve efficiency (B, C_mid) rather than ceilings (A). Planning should separate “how fast” from “how high” when allocating compute.
- In-distribution validation correlates with downstream performance in the reported experiments, but domain-level generalization still requires dedicated evaluation.
Glossary
- Advantage normalization: A technique to scale advantages (reward-centered signals) by a variance measure to stabilize gradients, applied at prompt or batch level. "batch-level advantage normalization"
- Asymptotic pass rate: The upper-limit (ceiling) of validation accuracy reached as compute grows, denoted by A. "where represents the asymptotic pass rate"
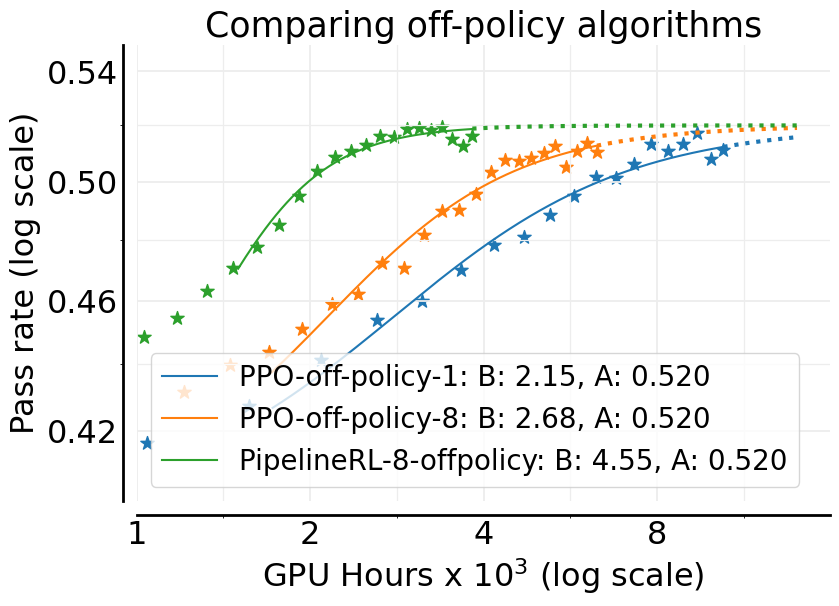
- Asymptotic performance: The performance level approached at very large compute budgets, often measured by pass rate A. "PipelineRL and PPO-off-policy achieve similar asymptotic performance "
- CISPO: A loss that combines truncated importance sampling with REINFORCE to improve stability and scalability in off-policy RL. "CISPO exhibits a prolonged near-linear reward increase"
- Compute efficiency: How quickly performance improves per unit of compute, often associated with the scaling exponent B. "achieves the highest compute efficiency."
- DAPO: An asymmetrically clipped off-policy policy optimization loss designed to prevent collapse while maintaining diversity. "We compare the asymmetric DAPO loss"
- Entropy collapse: A failure mode where the policy’s output diversity sharply decreases during training. "avoid entropy collapse and maintain output diversity"
- FSDP: Fully Sharded Data Parallel; a training backend that shards model states across GPUs to enable large-scale training. "training backend (FSDP)"
- FP32 precision: Using 32-bit floating point arithmetic (e.g., at the LM head/logits) to reduce numerical mismatches and improve stability. "Using FP32 precision in the final layer (LM head) gives a considerable boost in the asymptotic reward."
- GRPO: Group Relative Policy Optimization; a token-level importance sampling policy gradient variant used for RL fine-tuning. "resembles GRPO~\citep{shao2024deepseekmath} without any KL regularization term"
- GSPO: A sequence-level importance sampling policy optimization method that contrasts with token-level IS approaches. "GSPO applies importance sampling at the sequence level"
- Held-out validation: Evaluation on a reserved subset of in-distribution data used to fit and extrapolate scaling curves. "Scaling curve on held-out validation"
- Importance sampling (IS) ratios: Ratios of new to old policy probabilities used to weight policy gradients in off-policy training. "token-level importance sampling (IS) ratios"
- Interruptions: A truncation mechanism that forcibly ends overly long generations to stabilize and speed up training. "forcibly stop overly long generations"
- KL regularization: A penalty term encouraging the current policy to stay close to a reference/old policy to stabilize updates. "without any KL regularization term"
- KV cache: The cached key-value tensors for attention that enable efficient continuation of generation; may be stale in asynchronous setups. "a stale KV cache from the old policy"
- LM head: The final output projection layer that produces token logits in a LLM. "final layer (LM head)"
- Mixture-of-Experts (MoE): An architecture that routes inputs through multiple expert sub-networks to improve capacity and efficiency. "17Bx16 MoE (Scout)"
- No-Positive-Resampling: A curriculum strategy that permanently removes prompts once they become too easy (high pass rate). "No-Positive-Resampling"
- Off-policy: Training the policy using data generated by older versions of the policy rather than the current one. "asynchronous off-policy RL setup"
- Off-policyness: A measure of how many training steps the trainers are ahead of the generators in asynchronous pipelines. "maximum off-policyness"
- PipelineRL: An asynchronous streaming RL training regimen where generators continuously produce traces and trainers update policies. "PipelineRL- is a recent approach"
- PPO-off-policy: An asynchronous variant of Proximal Policy Optimization that performs multiple updates per generated batch with stale data. "PPO-off-policy- is the default approach for asynchronous RL"
- REINFORCE: A classic Monte Carlo policy gradient estimator used to optimize policies via sampled returns. "truncated importance-sampling REINFORCE loss (CISPO)"
- Scaling exponent B: The parameter controlling the steepness/efficiency of the scaling curve; larger B implies faster gains per compute. "B > 0 is a scaling exponent that determines the compute efficiency"
- Sigmoidal compute-performance curve: A saturating sigmoid-shaped fit relating compute to performance used for prediction and extrapolation. "We fit sigmoidal compute-performance curves for RL training"
- Stop-gradient: An operation that prevents gradients from flowing through a value during backpropagation. "where is the stop-gradient function"
- Surrogate objective: A clipped or modified objective function optimized during policy updates to improve stability. "The surrogate objective is given by:"
- Truncated importance sampling: Clipping IS ratios to reduce variance and stabilize off-policy gradient estimates. "truncated importance sampling RL loss (CISPO)"
- Zero-variance filtering: Dropping prompts whose generations all have identical rewards, as they contribute no useful gradient. "``Zero'' variance filtering"
Collections
Sign up for free to add this paper to one or more collections.

