- The paper introduces a reinforcement learning framework that uses a rigorously curated, difficulty-aware dataset to enhance code generation models.
- It employs a four-stage pipeline with multi-dimensional difficulty scoring to systematically filter and standardize competitive programming problems.
- Results show significant performance gains, including up to 17.2% relative improvements on medium and hard problems across diverse benchmarks.
Scaling Data Difficulty for Code Generation Models via Reinforcement Learning
Motivation and Problem Statement
Current code generation datasets are impeded by severe imbalances in difficulty distribution, lack of recency, format inconsistencies, and pervasive data quality issues. Existing corpora are predominantly populated by simple or outdated problems, thus failing to sufficiently challenge modern LLMs and hindering improvements in generalization to the hardest distributions encountered in practical competitive programming or recent online judge contests. Furthermore, noise—including incomplete descriptions, unstandardized formats, and poor-quality or inadequate test case suites—further reduces the effectiveness of RL-based fine-tuning on code tasks. This paper addresses these deficiencies through a principled dataset curation pipeline, difficulty-aware selection, and a systematic measurement of impact on downstream RL training and evaluation.
Data Processing Framework
The proposed framework implements a four-stage data pipeline: collection, processing, filtering, and verification. Collection aggregates real competitive programming problems from both open-source platforms (TACO, KodCode, DeepCoder) and privately-maintained archives (AIZU, AtCoder, Kattis, CodeChef). Processing entails comprehensive standardization—translating foreign language tasks to English, strict removal of noise and irrelevant content, unification of instruction and prompt formats, and LLM-based generation and selection of comprehensive reference test cases to maximize solution validation reliability.
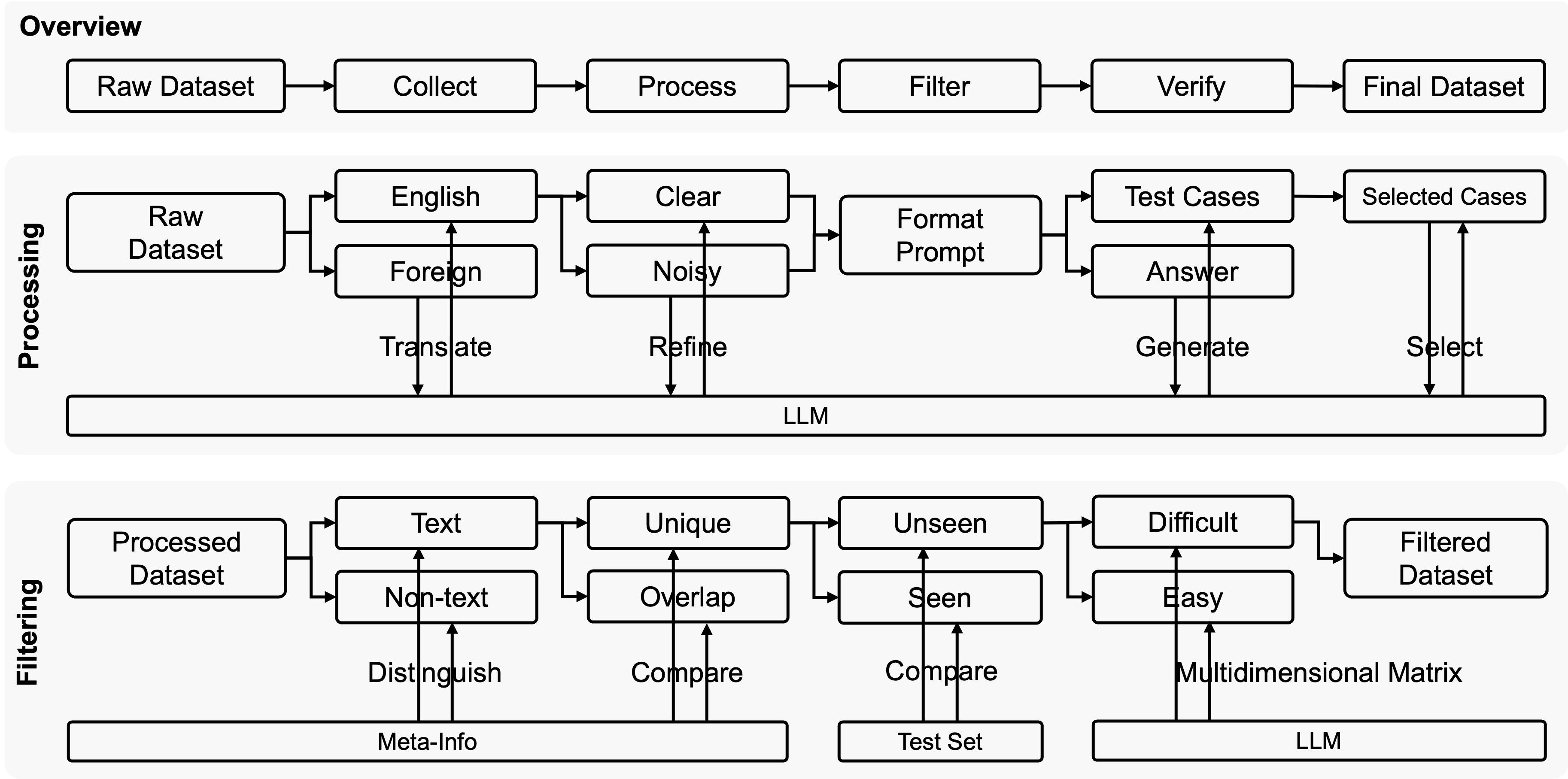
Figure 1: End-to-end data processing pipeline: collection, standardization, filtering using difficulty-aware and hard requirements, and human verification ensuring corpus quality.
Filtering combines both hard requirements (text-only, uniqueness, train-test separation via 16-gram similarity thresholding) and adaptive measures using LLM-driven, multidimensional problem difficulty assessment. Verification solidifies quality with conservative human validation, ensuring abstract and test case completeness. The resultant MicroCoder dataset is comprised of 13,300 rigorously curated problems exhibiting high diversity and recency, with substantial removal of simplistic or noisy problems.
Multi-dimensional Difficulty Metrics and Automatic Filtering
Central to the pipeline is the automated, LLM-based difficulty scoring framework. Problem complexity is modeled along five dimensions: Algorithmic Thinking Complexity (ATC), Implementation Difficulty (ID), Output Diversity (OD), Problem Comprehension Difficulty (PCD), and Knowledge Breadth Requirements (KBR). High weights are placed on ATC and ID, minimal weights on PCD and KBR, and all are rated 1–5 by independently-queried LLM assessments. The combination yields a composite, calibrated difficulty ranking for selection.

Figure 2: Multi-dimensional difficulty assessment: examples of dimension scores, weighting, LLM-based reproducibility, and calibration to percentile ranks within the dataset.
The predict-calibrate-select filtering procedure calibrates LLM-predicted scores against empirical pass rates under controlled code model attempts, thereby aligning selection thresholds with actual model difficulty. This approach enables automated and robust elimination of excess easy problems while retaining those critical for training high-capacity models to generalize to competitive levels.
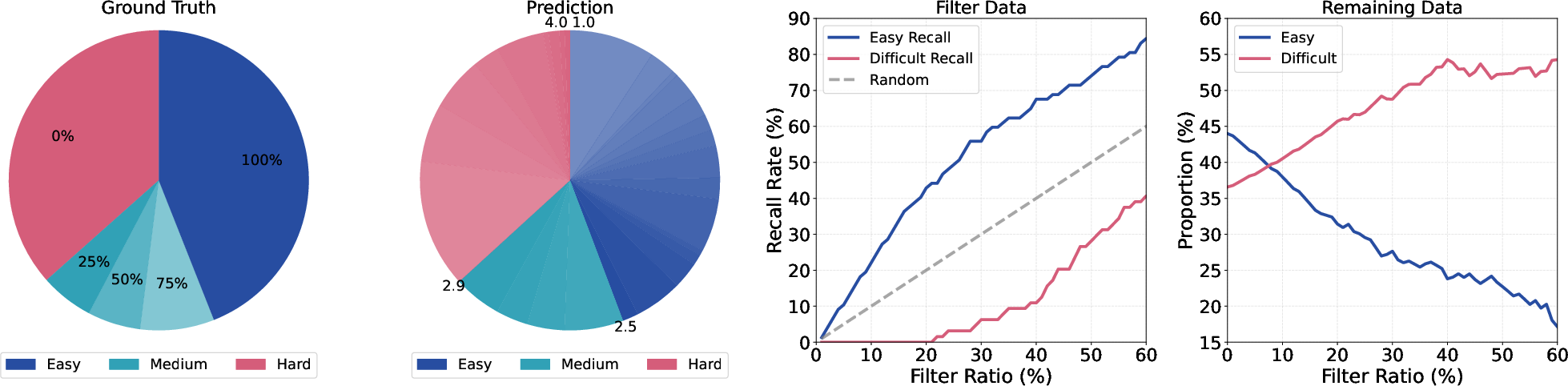
Figure 3: Case study validating that LLM-based difficulty filtering closely matches empirical model success curves: selective pruning of low-difficulty problems produces a dataset where medium/hard tasks dominate.
Statistical Analysis of MicroCoder
Statistical surveys demonstrate that MicroCoder’s problems are both longer and more complex on average than those in open datasets, especially those contributed from private collections. Test case selection is standardized to maintain efficiency and avoid overfitting or training slowdowns—at most 15 cases per problem, with preference for the most challenging instances. t-SNE visualizations confirm little overlap and strong complementarity across platforms, and cosine similarity analysis confirms a train-test separation with minimal detectable information leakage.
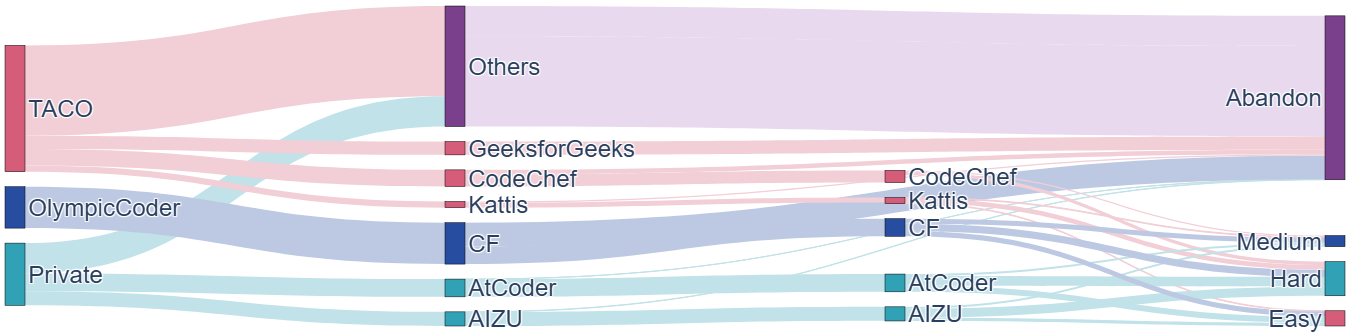
Figure 4: Sankey diagram of data sourcing and filtering: privatized archives contribute most difficult/recent tasks, open-source sets are aggressively filtered toward higher difficulty.
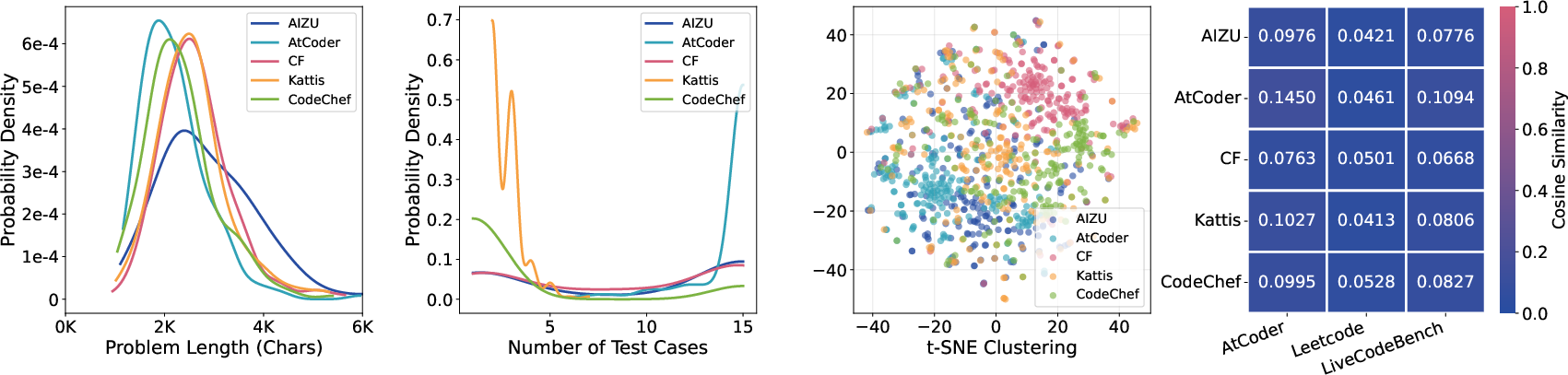
Figure 5: Problem length, test case, t-SNE distribution and cosine similarity statistics confirm diversity and non-redundancy of curated datasets.
Experimental Design
Benchmarks consist of AtCoder, LeetCode, and LiveCodeBench v6—all containing strictly held-out, post-training-release problems, preventing contamination. The Qwen3-4B-Instruct-2507 model is trained using both GRPO and DAPO RL variants, with DAPO encouraging high solution diversity and removing KL constraints with a high clipping threshold—emphasizing capabilities on more difficult distributions. Mainline evaluations report average pass rates per test set, stratified by problem difficulty, with multiple independent attempts per problem.
Results and Key Findings
MicroCoder outperforms the widely used DeepCoder and other leading datasets by a substantial margin, with especially pronounced gains on medium and hard problems. Under identical model and training settings, MicroCoder yields +2–4 absolute percentage points (and up to +17.2% relative improvements) on all-primary benchmarks, with the largest deltas observed on LeetCode and LiveCodeBench at the medium and hard echelons. DAPO outperforms GRPO across the board, indicating the synergy of challenging data and diversity-seeking RL objectives.
Experiments spanning model sizes (1.7B–14B parameters) show that gains scale with capacity, with the most powerful models reaping maximal benefit from recency- and difficulty-aware curation. Ablation and filtering studies further indicate that advantages are due not only to filtering existing problems, but to the introduction of recent and out-of-pretraining-distribution challenges.
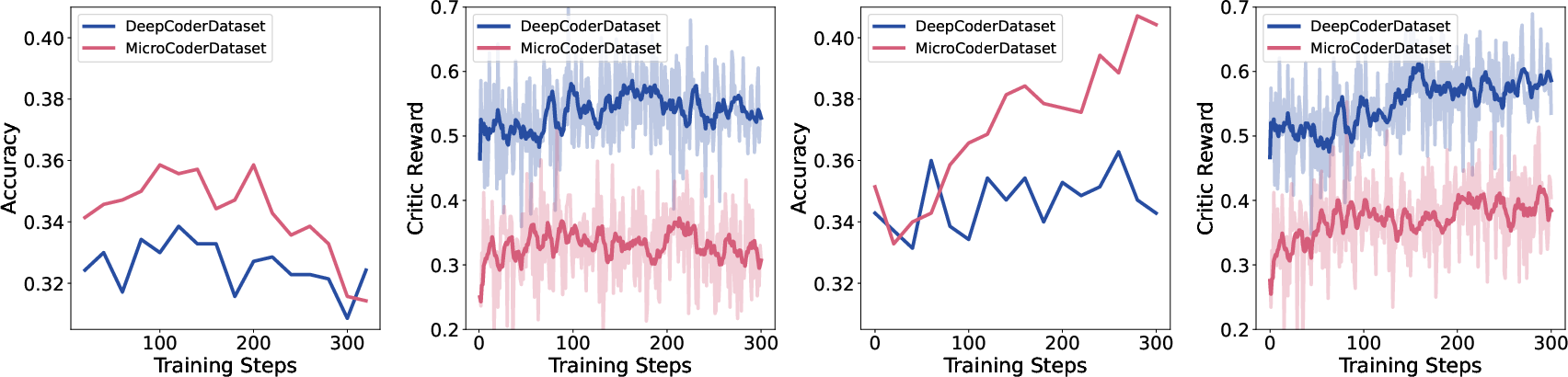
Figure 6: Training dynamics: MicroCoder drives higher generalization accuracy but lower on-policy training rewards, confirming the role of difficult data in improving real-world performance.
Theoretical and Practical Implications
These findings empirically validate the hypothesis that curated, high-difficulty, and recent competitive programming problems drive larger and more robust improvements in RL-based code generation models. The contribution lies not merely in scaling data volume, but in scaling data difficulty and minimizing redundancy and contamination. The five-dimensional difficulty framework operationalizes a reproducible and model-aligned filtering process, potentially informing broader dataset construction for both code and general LLM tasks, especially as model capability increases.
The systematic addressing of quality, format, recency, and difficulty positions MicroCoder as an improved training standard for next-generation coders. The data/algorithm synergy observed with DAPO over standard policy gradients suggests new RL methods that are better matched to challenging program synthesis tasks.
Future Directions
Further extensions include adaptation of this pipeline for multilingual, multi-paradigm code tasks, dynamic in-training difficulty assessments that adapt to model progress, and explorations into difficulty-scaled curation for orthogonal reasoning and code robustness tasks. There’s also scope for integrating these metrics into active dataset acquisition and lifelong learning scenarios for code generation LLMs.
Conclusion
This work demonstrates that difficulty-aware and recency-sensitive dataset curation provides persistent, model-scale-robust improvements in competitive code generation, particularly when paired with diversity-driven RL algorithms. The MicroCoder dataset and its methodology establish a new direction for systematic dataset engineering, moving beyond scale to informed, calibration-backed selection for maximal effect in challenging domains.
Reference: Zongqian Li, et al., "Scaling Data Difficulty: Improving Coding Models via Reinforcement Learning on Fresh and Challenging Problems" (2603.07779)