- The paper demonstrates that massive, procedurally generated simulation data enables robust zero-shot sim-to-real transfer, achieving up to 79.2% success on pick-and-place tasks.
- It introduces the MolmoBot-Engine, which creates 1.8 million expert episodes across diverse environments by randomizing object, lighting, and camera configurations with CLIP-based annotations.
- The study shows that scaling simulation data and object diversity can bridge the sim-to-real gap, challenging the need for real-world demonstrations or extensive domain adaptation.
Large-Scale Sim-to-Real Manipulation with MolmoBot
Introduction and Motivation
The widespread belief in robot learning holds that simulation data alone is insufficient for robust sim-to-real transfer in manipulation. Prevailing practice relies on some degree of real-world demonstration or domain adaptation to bridge the sim-to-real gap, especially for manipulation tasks involving complex interactions and environmental variation. The MolmoBot study challenges this assumption by scaling procedural simulation pipelines to generate massive, diverse demonstrations across both static and mobile manipulation tasks, and empirically demonstrating strong zero-shot sim-to-real performance—achieving up to 79.2% real-world pick-and-place success with no real-world fine-tuning, exceeding state-of-the-art real-data-trained baselines.

Figure 1: MolmoBot leverages diverse simulation data to achieve zero-shot sim-to-real transfer on multiple robotic tasks such as pick-and-place and door opening. This unlocks the ability to dramatically scale up the training data for generalist robotic foundation models.
MolmoBot-Engine and Dataset Construction
The foundation of this approach is MolmoBot-Engine, an open-source pipeline for high-throughput procedural data generation built on MolmoSpaces—an ecosystem of 232k environments with over 48k manipulable objects distributed across diverse room and object types.
MolmoBot-Engine programmatically instantiates randomized manipulation scenes by varying object and agent configurations, lighting, textures, poses, and camera viewpoints, employing domain and pose randomization at episode and asset levels. It automatically generates expert demonstration rollouts for articulated (e.g., doors, drawers) and rigid object manipulation via motion planners with stochastic grasp and action noise injection.
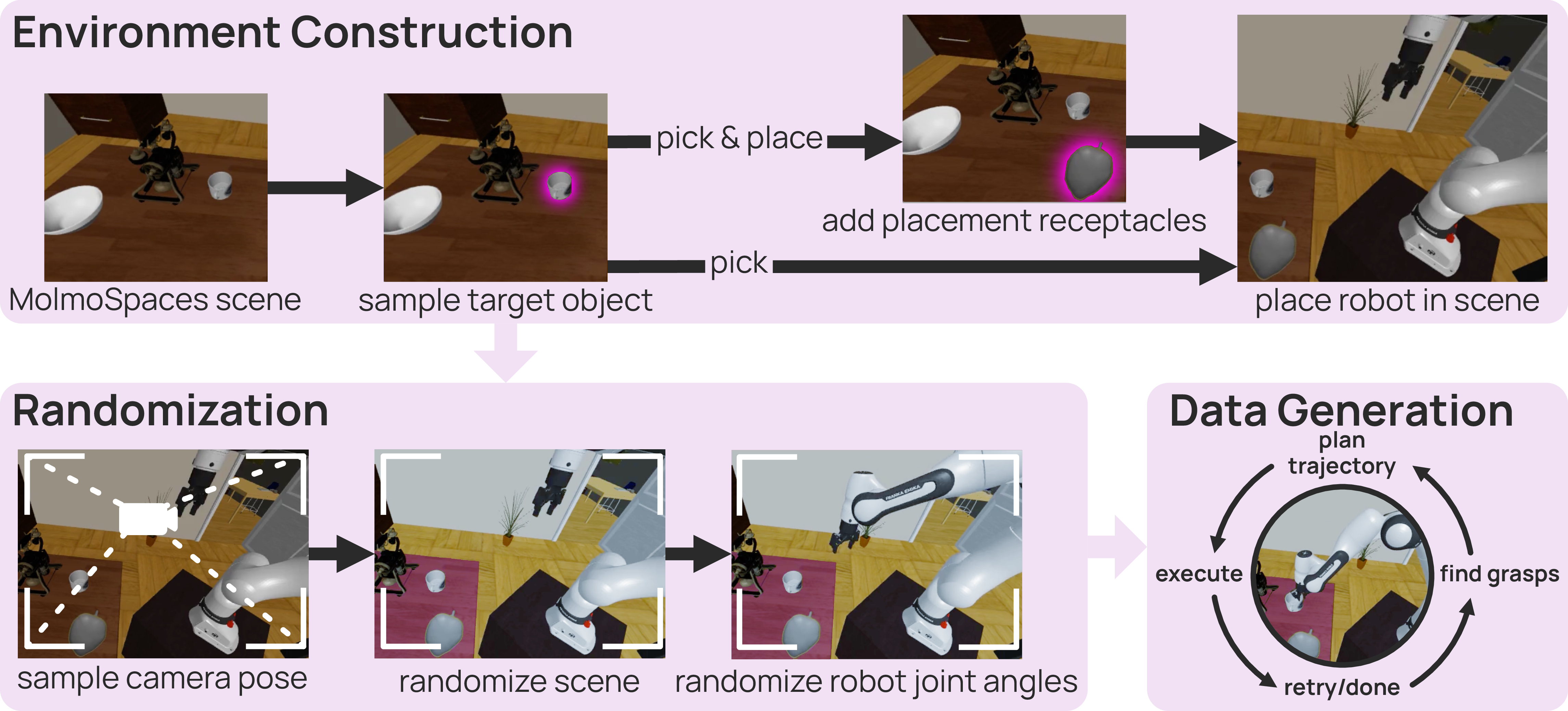
Figure 2: MolmoBot-Engine. Starting from a pre-built MolmoSpaces environment, objects and physical parameters are randomized and expert trajectories are generated until a successful solution is found.
The resulting MolmoBot-Data comprises 1.8 million expert episodes (approx. 300 million frames) encompassing 94k scene instances, with over 11k unique target assets and 9k receptacle objects.
Expert demonstrations cover both static (Franka FR3) and mobile manipulation (RB-Y1) platforms, with fine-grained, phase-based task decomposition (pick, pick-and-place, open, pick-and-place-next-to, etc.), and each episode annotated with diverse, unambiguous CLIP-based language instructions for robust vision-language grounding.

Figure 3: Expert demonstrations across multiple robots and manipulation tasks, visualizing language-conditioned rollouts on Franka tabletop (top) and RB-Y1 mobile manipulation (bottom).
Policy Architecture and Training
Three classes of manipulation policies are trained exclusively on MolmoBot-Data, with no real demonstrations:
- MolmoBot: Built atop a Molmo2-based VLM backbone, incorporating SigLIP2 vision encoding, a DiT-based flow-matching action head, and multi-frame temporal context. Actions are predicted as either absolute or delta joint positions with chunked execution.
- MolmoBot-Pi0: Replicates the π0 architecture [black2024pi_0], using an identical Paligemma VLM and flow-matching action head, retrained from scratch on MolmoBot-Data. This allows for direct isolation of data versus architectural impact.
- MolmoBot-SPOC: A lightweight, edge-deployable transformer policy inspired by SPOC [ehsani2024spoc], utilizing quantile-binned action tokenization, parallel decoding, and SigLIP text-vision encoders.
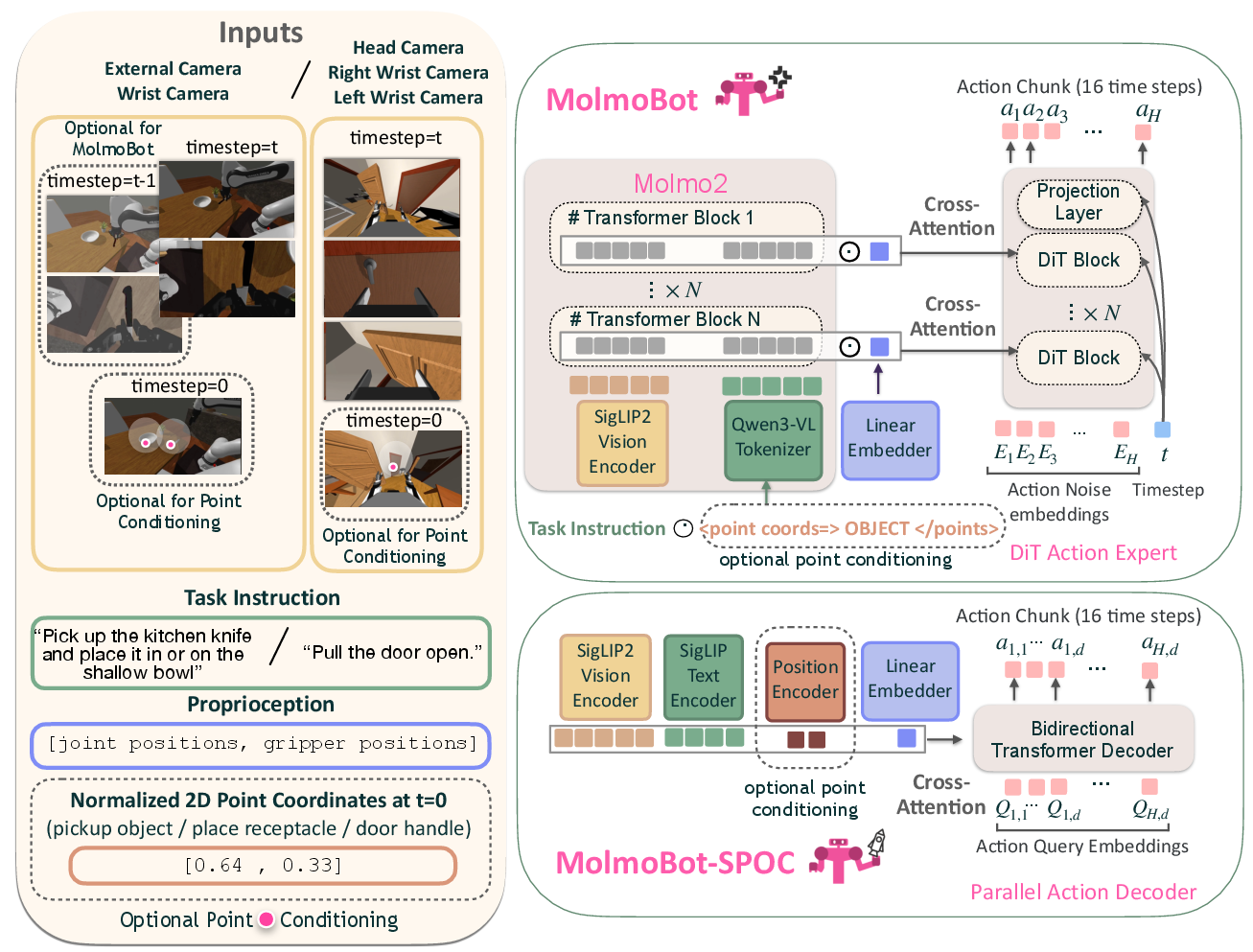
Figure 4: Policy architectures. MolmoBot leverages a VLM backbone and flow-matching head (top right), while MolmoBot-SPOC employs a parallel transformer action decoder (bottom right). All process language, multi-view RGB, proprioceptive, and optional spatial cues (left).
All policies are trained with large-batch behavior cloning, heavy image augmentation, prompt and referral expression randomization, and, for multi-frame variants, temporally compositional input for enhanced visuomotor temporal grounding.
Sim-to-Real and Benchmark Evaluation
Static Manipulation: DROID Environments
Real-world evaluation is performed on three DROID (Franka FR3) platforms across four distinct environments (kitchen, workroom, bedroom, office) at two institutions, with 120 pick-and-place tasks per policy. Task prompts are diverse and context-specific. Baselines include SOTA real-data-trained π0.5 and π0 models.




Figure 5: Real-world environments for DROID evaluations: kitchen, workroom, bedroom, and office, selected for diverse geometry and visual appearance.
Key result: MolmoBot (multi-frame, F=2) achieves 79.2% average real-world success, compared to π0.5 at 39.2% and MolmoBot-Pi0 at 46.7%, all with zero real-world fine-tuning.
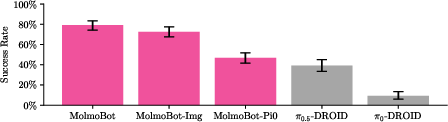
Figure 6: MolmoBot policies demonstrate strong zero-shot sim2real transfer, substantially outperforming π0.5 and π0 baselines in real-world DROID tasks.
This contradicts the assumption that sim2real manipulation at this level requires real-world adaptation or photorealistic simulation, provided scale and diversity are sufficient.
Mobile Manipulation: RB-Y1 Results
MolmoBot policies are also evaluated for articulated and mobile manipulation tasks on the RB-Y1 platform (pick-and-place, door opening, drawer/cabinet interaction). While performance is lower than in static setups, zero-shot deployment with no prior real-world data is shown feasible for entire task categories previously lacking generalist solutions.




Figure 7: Real-world setups for RB-Y1 articulated and rigid object mobile manipulation evaluations.
Systematic Ablation Results
Policy performance as a function of simulation dataset scale, object and environment diversity, and data normalization is systematically evaluated both in real and held-out simulation environments.
- Scaling demonstrations: Both simulation and real performance improve monotonically with trajectory count (10k → 50k), illustrating the primacy of scale.
- Scaling object diversity: Simulation benchmarks benefit from greater object variety; real-world improvements plateau, attributed to evaluation object homogeneity.
- Scaling environment diversity: No significant effect on the pick task, indicating that isolating the manipulated object dominates generalization, not broader scene variety.
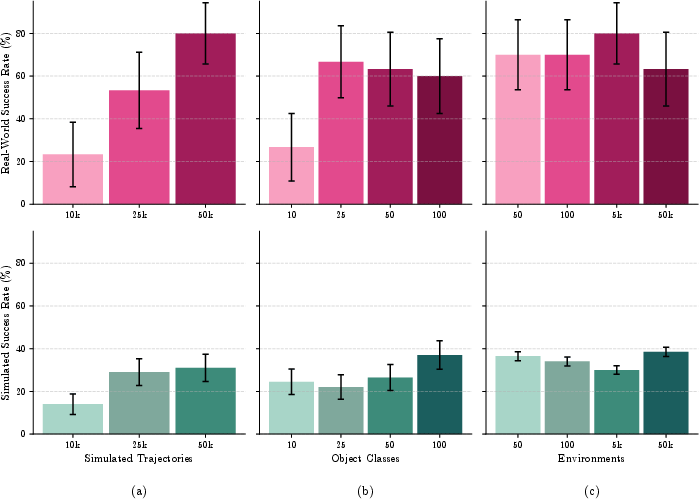
Figure 8: Scaling ablations reveal that data quantity and object diversity drive most of the gains; environment diversity has marginal impact on the tested task.
- Action parameterization and training regime: Absolute joint position actions outperform delta representations in real settings. Training with denoising on multiple timesteps per example increases simulation performance and stabilizes real transfer.
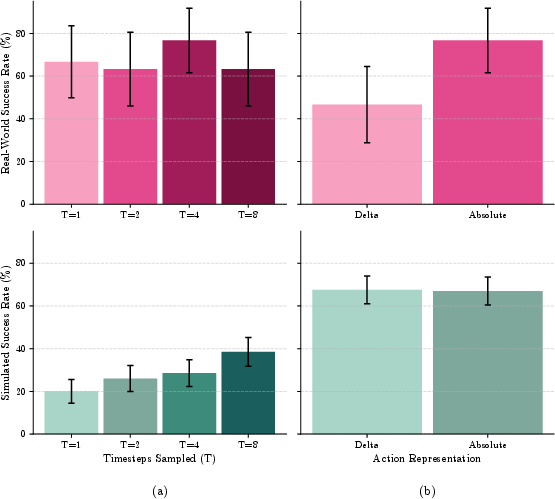
Figure 9: Training regime and action representation ablations: higher denoising steps T improve convergence; absolute actions yield higher real-world transfer.
Implications and Future Directions
Theoretical and Practical Impact
This work provides compelling evidence that the perceived irreducible sim-to-real gap in robot manipulation can be substantially overcome through massive, diverse, and procedurally generated simulation data—with no recourse to photorealistic rendering, privileged sensing, or architectural domain adaptation. This suggests that access to high-quality procedural simulators, scalable data pipelines, and foundation model pretraining may be more critical than real-world data curation for generalist policy creation.
Open-sourcing the full simulation pipeline and dataset enables democratization of large-scale robot learning research, reducing the current dependence on proprietary large-scale real-world datasets.
Limitations and Forward-Looking Research
Current limitations include restriction to manipulation domains accurately supported by contemporary physics simulators (rigid and articulated objects). Transferability to contact-rich, deformable, or fluid-based task categories remains open, primarily dependent on advances in high-fidelity world simulation. Opportunities also exist for combining large-scale simulation pretraining with modest real-world or on-policy RL fine-tuning to address residual gaps and to expand deployment in unmodeled or long-horizon task categories.
Conclusion
MolmoBot demonstrates that, through extensive proceduralization and large-scale simulation, robust and generalizable robotic manipulation can be achieved zero-shot in real-world settings, challenging entrenched assumptions regarding the necessity of real demonstrations for high-performance deployment. The release of the MolmoBot-Engine and dataset establishes a new paradigm for research reproducibility and scalability in embodied AI, and paves the way for further community efforts toward sim-driven generalist robot policy development.
(2603.16861)