- The paper presents an explicit digital twin construction method to enable zero-shot manipulation in open-world environments without prior demonstrations.
- It leverages advanced vision-language models and segmentation techniques to generate semantic and geometrically accurate 3D models from 2D observations.
- Experimental results show high task success rates (≥75%) while highlighting sim-to-real transfer challenges in complex semantic scenarios.
Explicit World Modeling for Zero-Shot Open-World Object Manipulation
Introduction and Motivation
Open-world robotic manipulation introduces considerable challenges in perception, affordance inference, and task generalization due to the necessity for semantic and physical reasoning under novel, unstructured environments. Typical Vision-Language-Action (VLA) frameworks rely heavily on extensive robot demonstrations and struggle with generalization to out-of-distribution tasks or objects. This work proposes a framework for zero-shot open-world manipulation built upon explicit world modeling: the system reconstructs a physically-consistent digital twin of the real environment from 2D onboard observations and natural language command, and subsequently explores candidate manipulation strategies in simulation to enable robust policy selection and transfer.
System Architecture
The framework consists of sequential modules: (A) open-set perception for task-relevant segmentation and grasping, (B) digital twin mesh construction and alignment, and (C) manipulation strategy generation and evaluation. The explicit world model is leveraged to perform closed-loop reasoning about actions without utilizing any task-specific training or demonstrations.
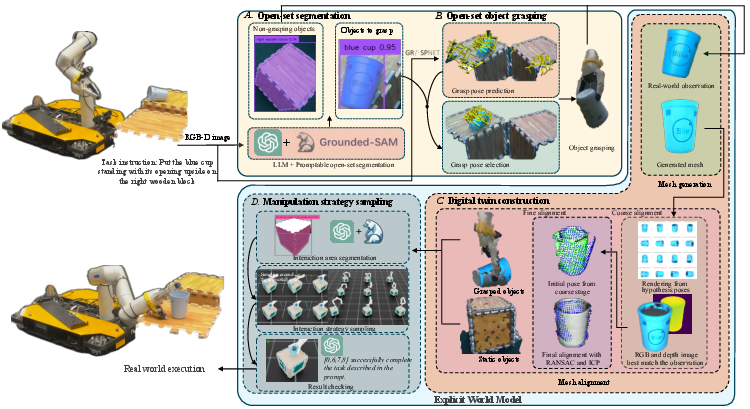
Figure 1: The overall pipeline combines perception, digital twin construction, and simulated sampling to select and execute manipulation strategies for open-set tasks.
Open-Set Segmentation and Grasping
Utilizing large VLMs (GPT-4o) and advanced segmentation backbones (Grounded-SAM), the system parses the semantic instruction to identify and generate segmentation masks for manipulated and interacted entities, permitting open-vocabulary recognition beyond pre-defined categories. AnyGrasp then proposes grasp poses. Grasp candidates are filtered based on proximity to segmented object point clouds, ensuring accurate, instance-level manipulation.
Digital Twin Construction
A core contribution is the robust digital twin reconstruction. Masked RGB regions are synthesized into textured 3D meshes via Hunyuan3D 2.0, but since generated meshes are in canonical pose and unit scale, a two-stage alignment pipeline is introduced. First, coarse pose hypotheses are rendered and ranked against the observed view using DINOv2 feature similarity. The best candidate undergoes fine 6-DoF registration against the observed point cloud using RANSAC and ICP, further adjusted for scale according to bounding boxes.
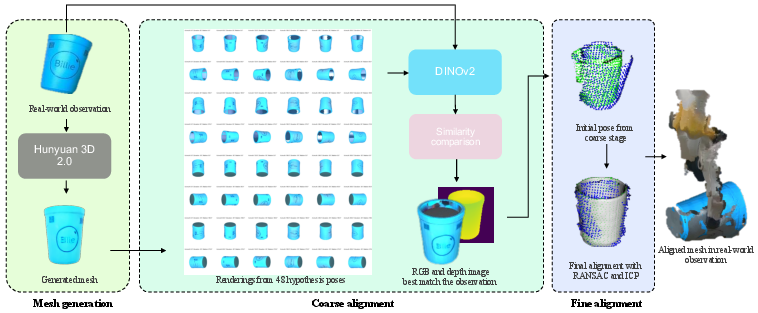
Figure 2: The digital twin module leverages generative models and feature-based view correspondence for mesh synthesis and precise pose-scale alignment.
Qualitative alignment results confirm high scene fidelity post-alignment, facilitating downstream simulation.

Figure 3: Aligned mesh overlays demonstrate strong geometric and pose consistency against real-world observed data.
Manipulation Strategy Sampling
Candidate strategies are sampled by constraining end-effector pose generation to the predicted interaction regions derived from VLM and segmentation, followed by sampling across reachable orientation subspaces. The digital twin is instantiated in a physics-based simulator (Isaac Sim) for rollouts.
Rendered post-manipulation views are presented to the VLM to assess semantic goal satisfaction per sample, providing weak binary success labels. A GP classifier in SE(3) then smooths and calibrates the success landscape, ranking and selecting the optimal candidate for transfer to real-robot execution.
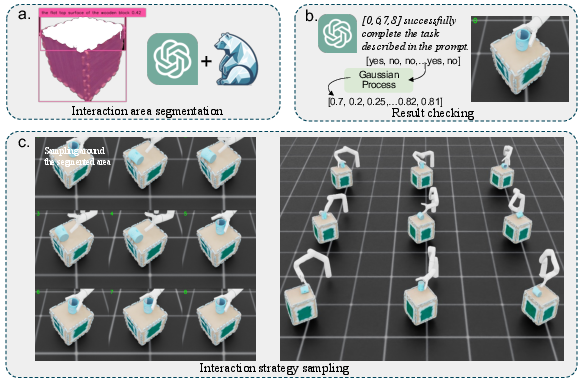
Figure 4: Strategy generation leverages VLM-driven segmentation for search space reduction, simulator rollouts, and LLM-based outcome validation, with a GP providing calibrated sample ranking.
Experimental Evaluation
The two-stage mesh alignment pipeline significantly outperforms direct alignment baselines without reliance on ground-truth demonstration, both in free and grasped scenarios, yielding higher alignment success rates with comparable RMSE. This validates the efficacy of the feature-based coarse-to-fine pipeline for robust open-set object registration.
Real-World Task Execution
Nine open-world manipulation tasks, including semantic and spatial reasoning, were deployed over 96 real robot attempts. The system achieves high success rates (≥75%) on two-thirds of the tasks, without any task-specific retraining or demonstration data. Lower performance on "cup upside on box" tasks is attributed to inherent semantic ambiguities unresolved by VLM-based visual checking.

Figure 5: Sampled manipulation tasks span insertion, stacking, and spatial arrangement, with top and bottom frames indicating pre- and post-execution scenes respectively.
Stage-wise analysis via a Sankey diagram reveals primary failure points in the result checking (VLM ambiguity) and sim-to-real transfer (mismatch in dynamics or geometry).
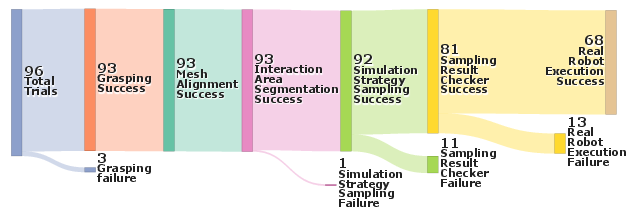
Figure 6: Sankey visualization quantifies module-wise trials and losses, pinpointing bottlenecks across the framework.
A breakdown of failure distributions indicates that misclassification by the VLM-based strategy checker is predominant for tasks with visually ambiguous results.
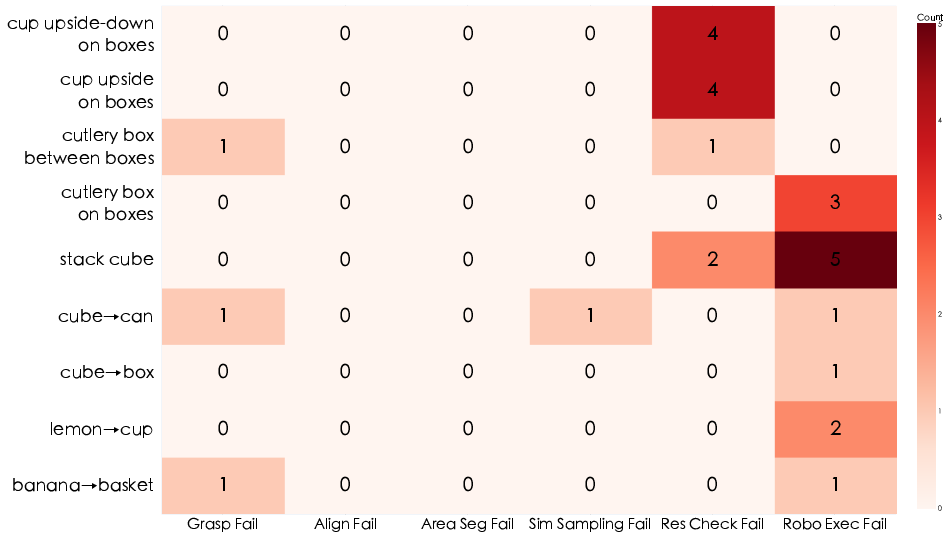
Figure 7: Most checker failures (by task and error type) occur on semantically challenging scenarios with subtle visual distinctions.
Implications and Future Work
This approach establishes the viability of explicit mesh-based world models, reinforced by VLMs, for open-world zero-shot generalization in manipulation. Its reliance on simulation, rather than demonstrations, decouples task specification from policy instantiation. This modularity enables immediate transfer to arbitrary rigid-body tasks and new objects. Limitations center on sim-to-real gaps (especially for deformable, articulated, or visually ambiguous objects), model calibration, and computational demands of sampling.
Practical implications include enhanced autonomy in industrial and service robotics where semantic diversity and open-ended tasks preclude full demonstration-based coverage. Theoretical extensions will focus on integrating deformable/jointed articulations, depth/contact multi-modality in the outcome checker, and real-time acceleration of the simulation-evaluation-sampling loop.
Conclusion
By constructing a geometrically explicit, physically parameterized digital twin from open-world observations, and coupling it with LLM-driven perception and outcome evaluation, this work achieves robust zero-shot object manipulation across a variety of tasks and unseen objects (2603.13825). The empirical results support the theoretical claim that explicit world models, combined with scalable foundation models, are powerful enablers for open-world robotics. Future efforts will target efficiency, sim-to-real transfer, and multimodal outcome validation to further broaden application scope.