- The paper introduces BLAZER, a fully automated framework leveraging zero-shot LLM planning to generate and verify high-quality manipulation demonstrations without manual data collection.
- The approach uses simulation for verification, enabling a finetuned LLaMA-8B to outperform larger models and achieve an 83.2% success rate in RLBench tasks.
- The framework integrates a vision pipeline for object state estimation, ensuring robust performance and effective transfer to real-world and out-of-distribution tasks.
BLAZER: Bootstrapping LLM-based Manipulation Agents with Zero-Shot Data Generation
Introduction and Motivation
The BLAZER framework addresses a central challenge in robotics: the scarcity of large-scale, diverse, and high-quality manipulation demonstrations required for training generalizable robotic policies. Unlike computer vision and NLP, robotics lacks internet-scale datasets, making manual data collection prohibitively expensive and slow. BLAZER leverages the zero-shot planning capabilities of LLMs to automatically generate and verify manipulation demonstrations in simulation, thereby bootstrapping the training of smaller, more efficient LLM-based manipulation agents without human supervision.
Methodology
BLAZER formalizes robotic manipulation as a sequence of control primitives executed by a gripper in an environment E, with tasks τ defined by language instructions and object states. The framework consists of three main components:
- Zero-Shot Data Generation: A large LLM (e.g., LLaMA-70B) is prompted to generate executable manipulation plans for a set of tasks T, using privileged simulator state information.
- Automatic Verification: Generated plans are executed in simulation, and only successful executions are retained, forming a curated dataset DBLAZER of positive demonstrations.
- Supervised Finetuning: A smaller LLM (e.g., LLaMA-8B) is finetuned on DBLAZER, specializing it for manipulation policy generation.
This pipeline is fully automatic and does not require manual annotation or demonstration at any stage. The approach is illustrated in the following figure:
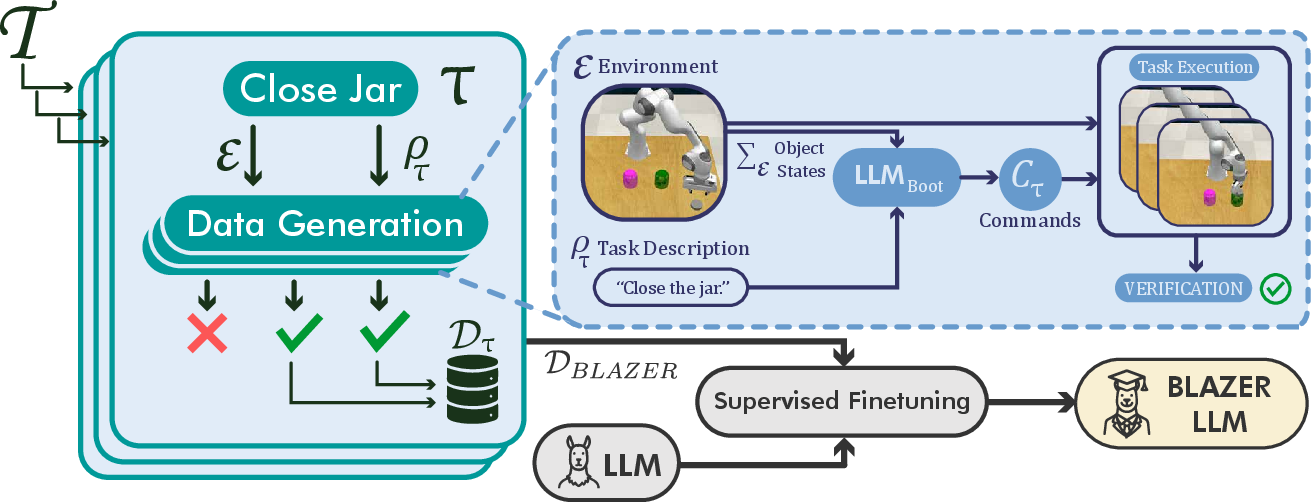
Figure 1: Overview of BLAZER. Given a set of manipulation tasks τ∈T, LLM-generated commands are verified in simulation and successful solutions are aggregated for finetuning.
Vision-Based Deployment
To enable real-world deployment, BLAZER introduces a vision pipeline that estimates object states from multi-view RGB-D data using foundation models (Molmo, Segment Anything, M2T2). This pipeline reconstructs the environment state Σ~E, which is then used as input for the finetuned LLM agent, allowing transfer from simulation to real-world tasks without additional training.
Experimental Evaluation
Simulation Tasks
BLAZER is evaluated on nine RLBench pick-and-place tasks, covering a range of manipulation scenarios:

















Figure 2: Tasks in simulation. Nine RLBench tasks are shown with start and end states.
The LLaMA-8B model finetuned with BLAZER achieves an average success rate of 83.2%, outperforming all baselines, including the larger LLaMA-70B (77.0%) and multi-agent MALMM (80.9%). Notably, LLaMA-8B with BLAZER surpasses its teacher model (LLaMA-70B) despite having significantly fewer parameters, demonstrating the effectiveness of the bootstrapping approach.
Visual Observations
When ground truth object states are replaced with vision-based estimates, BLAZER maintains superior performance and robustness to perception noise:
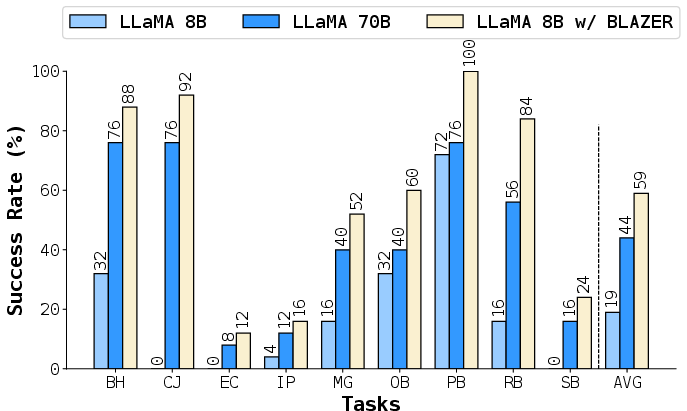
Figure 3: Tasks in simulation using visual observations. BLAZER-trained LLaMA-8B outperforms LLaMA-70B and base LLaMA-8B with vision pipeline input.
Real-World Transfer and Generalization
BLAZER is deployed on a Franka Emika Panda robot for 12 real-world tasks, including both in-distribution and out-of-distribution scenarios. The finetuned LLaMA-8B agent achieves a 47.8% average success rate, outperforming LLaMA-70B (33.3%). The agent demonstrates strong generalization to novel tasks not seen during training.


















Figure 4: Real world tasks visualization. Start and end states for in-distribution and out-of-distribution tasks.
Ablation Studies
BLAZER's performance scales with the number of generated training samples per task, but exhibits diminishing returns beyond 2000 samples. Additionally, the framework is compatible with smaller LLMs (e.g., LLaMA-3.2 3B), which achieve competitive success rates (84.9%) and enable deployment on resource-constrained platforms.
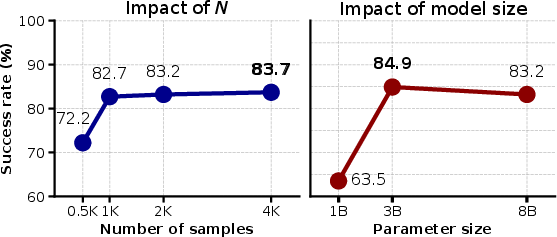
Figure 5: Ablation studies. Left: Success rate vs. number of samples. Right: Model size impact, showing strong performance for smaller models.
Implementation Considerations
- Computational Requirements: Data generation and verification in simulation are parallelizable and can be scaled arbitrarily. Finetuning with LoRA enables efficient adaptation of smaller LLMs.
- Deployment: The vision pipeline is modular and leverages off-the-shelf foundation models, facilitating integration with diverse sensor setups.
- Limitations: Current training uses only positive demonstrations; incorporating negative samples via preference-based methods (e.g., DPO) could further improve policy accuracy.
Implications and Future Directions
BLAZER demonstrates that automatic bootstrapping of manipulation data via LLMs can yield specialized agents that outperform their teacher models and generalize to novel tasks. This approach reduces reliance on manual data collection and enables scalable training of robotic policies. Future work may explore preference-based finetuning, integration with multimodal LLMs, and extension to more complex manipulation domains.
Conclusion
BLAZER provides a scalable, fully automatic framework for training LLM-based manipulation agents using zero-shot data generation and simulation-based verification. The method achieves strong empirical results in both simulation and real-world settings, with robust generalization and efficient model scaling. BLAZER represents a significant step toward practical, data-efficient training of robotic manipulation policies using foundation models.