Opening the Sim-to-Real Door for Humanoid Pixel-to-Action Policy Transfer
Abstract: Recent progress in GPU-accelerated, photorealistic simulation has opened a scalable data-generation path for robot learning, where massive physics and visual randomization allow policies to generalize beyond curated environments. Building on these advances, we develop a teacher-student-bootstrap learning framework for vision-based humanoid loco-manipulation, using articulated-object interaction as a representative high-difficulty benchmark. Our approach introduces a staged-reset exploration strategy that stabilizes long-horizon privileged-policy training, and a GRPO-based fine-tuning procedure that mitigates partial observability and improves closed-loop consistency in sim-to-real RL. Trained entirely on simulation data, the resulting policy achieves robust zero-shot performance across diverse door types and outperforms human teleoperators by up to 31.7% in task completion time under the same whole-body control stack. This represents the first humanoid sim-to-real policy capable of diverse articulated loco-manipulation using pure RGB perception.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows how a human‑shaped robot (a humanoid) can learn to find, grab, and open many kinds of real doors using only regular color cameras (RGB) and then walk through them—all without extra sensors or hand‑crafted instructions. The twist: the robot learns everything in a realistic video game–like simulator and then works in the real world “zero‑shot” (no extra training on the real robot). The system is called DoorMan.
What questions did the researchers ask?
- Can a humanoid robot learn the full “walk up + use hands + stay balanced + open door + go through” sequence using only camera images?
- If we train only in simulation, will the robot still work in messy, never‑seen real places (different doors, materials, lighting)?
- Can a learned policy (the robot’s decision‑maker) actually beat humans who control the robot by remote (teleoperation) using the same underlying body controller?
How did they do it?
Think of teaching the robot like teaching a kid to drive:
- First, a coach sits beside them with special tools (extra mirrors, speed data) and shows exactly what to do.
- Later, the student drives using only normal car mirrors and eyesight.
- Finally, the student practices tougher roads and gets better than simple copying.
The researchers split training into three main parts and built a huge, varied simulation playground to practice in.
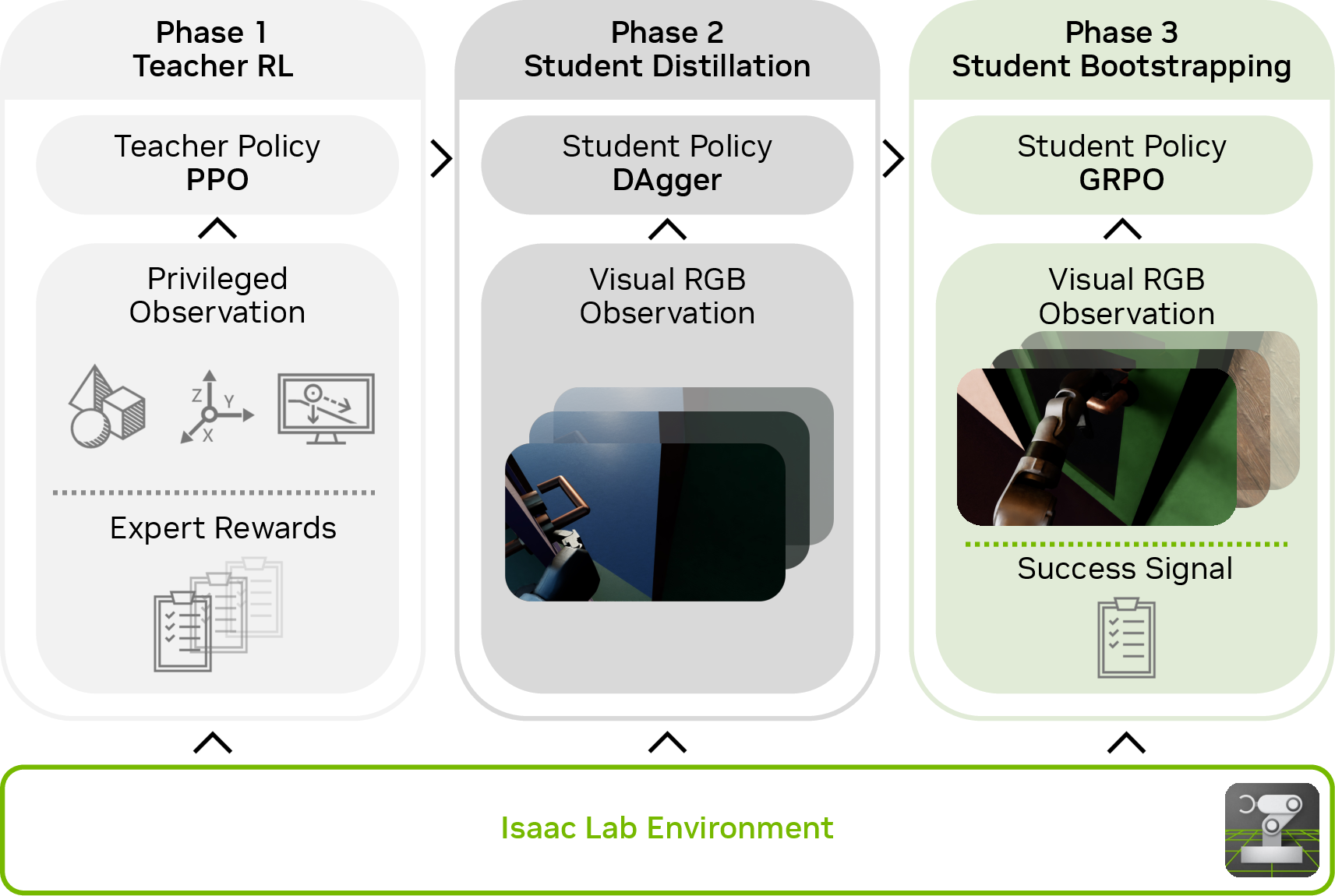
1) A “teacher” policy learns with extra info
In the simulator, a powerful “teacher” policy has privileged information that a real robot wouldn’t normally have, like the exact position of the door and handle. Using reinforcement learning (trial and error with rewards), the teacher learns the full door‑opening routine, including how to:
- Approach the door,
- Find and rotate the handle,
- Push or pull the door while staying balanced,
- Walk through.
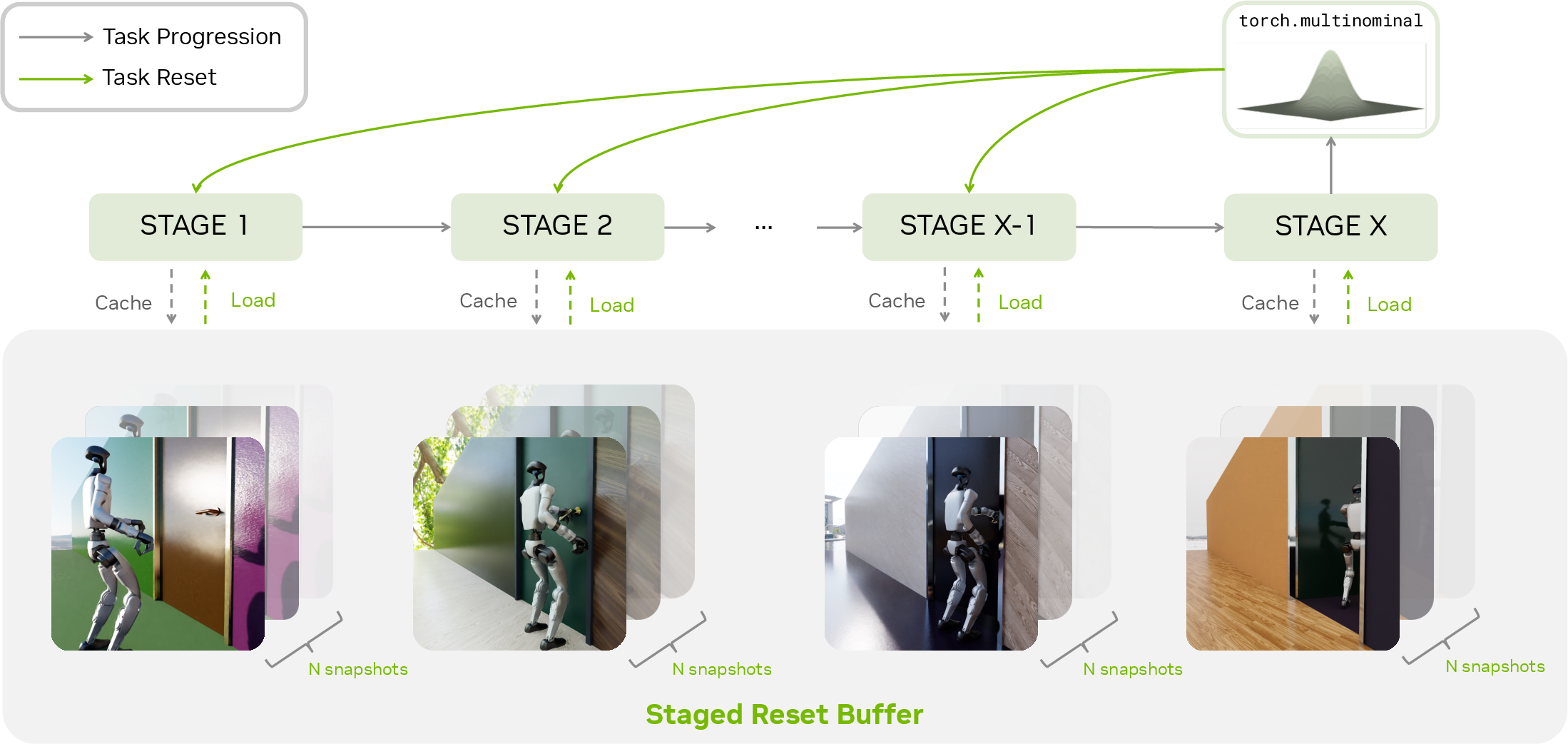
To make this long, tricky task easier to learn, they use “staged resets”: imagine a video game with checkpoints. When the teacher reaches a new stage (for example, “handle grabbed”), the simulator saves a snapshot. On future practice rounds, it sometimes restarts from these checkpoints, so the robot gets more practice on the hard later parts, not just the first few seconds.
2) A “student” learns from camera images
Next, a “student” policy learns to imitate the teacher but only sees what a real robot would: the RGB camera and its own body info (joint angles, etc.). It does not get the teacher’s extra door measurements.
They use a method called DAgger (short for Dataset Aggregation): as the student drives, the teacher tells it what it should have done, so the student learns from its own situations, not just from the teacher’s ideal ones. This helps the student handle mistakes and unusual viewpoints.
Inside the student:
- A vision encoder turns the camera image into useful features (like “there’s a handle here”).
- A memory unit (LSTM) helps it remember what just happened (important when something is briefly off‑camera).
- A small neural network outputs where to move its joints next.
3) Fine‑tuning with GRPO to handle what the camera misses
Using only cameras means sometimes important things are off‑screen or hidden (called “partial observability”). To help, they fine‑tune the student with an RL method called GRPO. Simple idea: run many trials, score them (did the robot open the door and get through?), then nudge the policy toward actions from the better‑scoring trials. No complex value models, just group‑based comparisons.
This step helps the student learn “camera‑smart” habits, like keeping the handle in view or adjusting where it stands so its eyes (camera) see what matters.
4) A huge variety of simulated doors and looks
To make sure the robot can handle the real world, they use “domain randomization,” which means the simulation keeps changing:
- Physics: door size, hinge stiffness, latch behavior (that “click” when a door opens), handle type, and where it’s placed.
- Visuals: textures, materials, wall colors, lighting and time of day, and slight camera variations.
This is like practicing in hundreds of different gyms with different doors so the robot doesn’t get fooled by a new paint color or a stronger spring.
5) Whole‑body control underneath
The policy sits on top of a strong whole‑body controller (a lower‑level skill set that keeps the robot balanced and tracks joint targets). That way, the learned policy can focus on where to move and how to interact with the door, while the body controller handles smooth motion and balance.
What did they find, and why is it important?
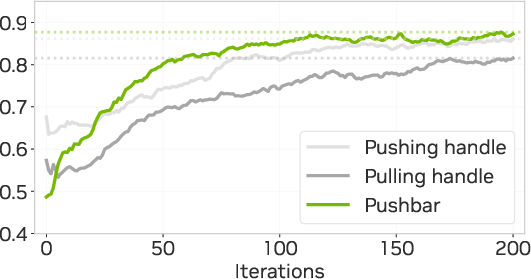
- It works zero‑shot in the real world. The policy trained only in simulation successfully opened many different real doors (push, pull, lever handles, and push bars) and walked through them.
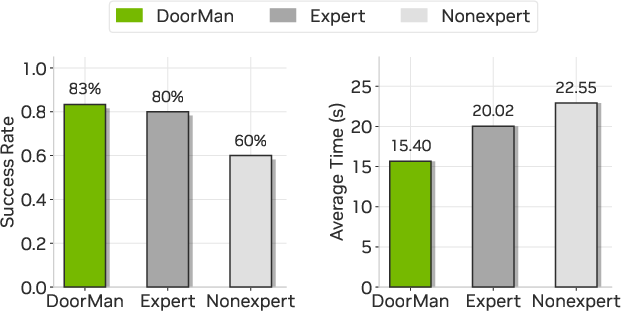
- It beat human teleoperators on speed and was slightly better or on par on success:
- Success rate: about 83% for the robot vs. 80% for expert human teleoperators (and 60% for non‑experts).
- Completion time: the robot was about 23%–32% faster than humans using the same body controller.
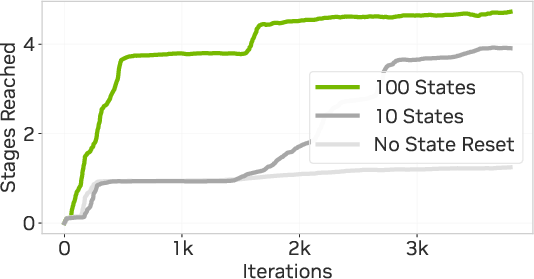
- The staged‑reset “checkpoint” trick sped up learning the hard parts. Without it, the teacher kept failing to reach later stages. With larger reset buffers (more checkpoint snapshots), the teacher reached the final stages much faster.
- The GRPO fine‑tuning closed the gap caused by partial observability. The student started notably worse than the teacher (since it only had a camera), then improved to nearly match the teacher’s success after fine‑tuning.
- Photorealistic variety mattered a lot. Training with rich textures and varied lighting led to much higher real‑world success. With no visual randomization, success dropped to around 5%–20%; with full textures and lighting variety, it jumped to roughly 80%–86%, depending on the door type.
Why this matters: Opening doors sounds simple but is hard for robots because it mixes seeing, touching, pushing, pulling, and staying balanced—all at once, over many seconds. Showing that an RGB‑only, simulation‑trained policy can do this robustly is a big step toward robots handling everyday tasks in human spaces.
What could this change in the future?
- Safer, cheaper training: Robots can master tricky tasks in simulation instead of risking real hardware.
- Less hand‑coding: Instead of writing brittle scripts for each door or room, we can train general skills that adapt on their own.
- Broader everyday skills: The same pipeline—teacher with extra info, student with camera‑only, staged resets, and GRPO fine‑tuning—could extend beyond doors to drawers, cabinets, gates, or other household interactions.
- Better autonomy than teleop for long, delicate tasks: As shown, learned policies can be faster and more consistent than human remote control for contact‑rich, whole‑body tasks.
In short, this work opens the “sim‑to‑real door” for humanoids: learning complex, camera‑based, whole‑body manipulation in simulation and transferring it directly to the messy real world—quickly, robustly, and often faster than a human at the controls.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, to guide future research.
- Real-world coverage of articulated object types is narrow: evaluate on door knobs, sliding doors, double doors, glass/transparent doors, louvered/accordion doors, heavy self-closers, warped frames, misaligned latches, and locked doors requiring more complex interactions.
- Robustness to visual edge cases is unquantified: glare/specular highlights, transparency, strong reflections (glass/metal), occlusions by the robot hand/body, cluttered backgrounds, thin/low-contrast handles, and texture-less surfaces.
- Illumination and camera artifact modeling is limited: extend randomization and tests to low light/night scenes, flicker, HDR extremes, motion blur, rolling shutter, lens distortion/vignetting, sensor noise, dirty/wet lenses, and harsh backlighting.
- Camera viewpoint sensitivity is under-explored: quantify performance under large extrinsic/intrinsic shifts, head/chest mounting changes, camera vibrations during footsteps, and moving camera height/tilt.
- Initial condition diversity is limited: move beyond starting 1 m facing the door to random initial positions, orientations, obstacles, narrow corridors, furniture occlusions, and partial visibility of the door.
- No explicit navigation-to-door capability: integrate and evaluate active search, exploration, and path planning toward doors under partial observability.
- Limited robot and hardware diversity: assess transfer to different humanoids (morphology, mass distribution), other grippers/hands, varied joint controllers (e.g., torque vs position), and different camera hardware.
- End-effector variability is not studied: robustness to hand geometry differences, glove thickness/compliance, finger pad materials, wet/slippery handles, and variable contact friction.
- On-robot compute and real-time performance are unspecified: report inference latency, on-board CPU/GPU requirements, jitter, and any control degradations at 50 Hz or higher.
- Safety and compliance are unaddressed: quantify contact forces, property damage risk, fall rates, recovery behaviors, torque/force limits, fail-safes, and compliance strategies during door opening.
- Failure modes lack analysis: systematically categorize failures (e.g., mis-grasp, wrong opening direction, loss of visibility, balance loss), frequency, root causes, and mitigation strategies.
- Physics gap measurement is missing: compare simulated hinge torques, latch dynamics, damping, and handle stiffness to real distributions; calibrate or bound sim-to-real mismatch.
- No online estimation of door properties without privileged signals: develop and evaluate student policies that infer opening direction, hinge stiffness, and latch state online from RGB + proprioception, with uncertainty modeling.
- Staged-reset relies on manual stage design and reward shaping: reduce task-specific engineering via automatic stage discovery, learned progress estimators, or curriculum methods that generalize across tasks.
- GRPO fine-tuning occurs only in simulation: assess safe real-world RL fine-tuning, sample efficiency, safety constraints, and whether sim-only GRPO suffices under larger reality gaps.
- Limited algorithmic comparison: rigorously ablate GRPO vs PPO/A2C/IMPALA; study the effect of group sizing, normalization, and baselines on stability and performance for long-horizon loco-manipulation.
- Policy architecture ablations are absent: compare ResNet vs ViT, CNN-LSTM vs Transformers, attention mechanisms, temporal context length, and memory strategies for occlusion-heavy tasks.
- Exclusively RGB perception is not benchmarked against minimal additional sensing: evaluate trade-offs with monocular depth/estimators, tactile/contact sensing, force/torque, audio cues, or wrist IMUs under the same training pipeline.
- Domain randomization coverage is incomplete: add transparent/translucent materials, microgeometry (scratches/dirt), decals, aging, material anisotropy, realistic indoor clutter, and dynamic lighting sources beyond dome lights.
- Generalization beyond door opening is untested: validate on drawers, cabinets, knobs, latches, switches, and multi-contact articulated mechanisms to support the “representative task” claim.
- Robustness to extreme mechanics is unknown: evaluate very stiff closers, high-friction seals, spring/damper nonlinearities, latch misalignment, and abrupt stick-slip during opening.
- Active perception behaviors lack metrics: quantify handle centering, gaze stabilization, view maintenance under motion, and their causal impact on success; design rewards or constraints for view-keeping explicitly.
- Staged-reset theory and generality need study: formalize its effect on occupancy measures and credit assignment, estimate “bridge” crossing probabilities, and test portability to off-policy/model-based RL and other tasks.
- Reproducibility details are thin: report training wall-time, compute budget, number of parallel environments, curriculum schedule, and release the procedural assets with parameter ranges.
- Human teleoperation baseline fairness is unclear: evaluate diverse teleop interfaces (e.g., haptic, higher DoF control), include scripted/traditional baselines, and replicate across multiple sites/operators to reduce interface bias.
- Ethical and operational deployment questions are open: policies for opening doors in public/private spaces, privacy, access control compliance, and human-aware safety in shared environments.
- Energy and wear considerations are missing: quantify energy consumption, thermal profiles, actuator wear, and maintenance implications during repeated contact-rich tasks.
- Binary success reward may limit fine-grained behavior: explore preference learning, continuous task fluency metrics, and dense-but-generalizable shaping that reduces hand-tuned stage rewards.
- Extreme weather and environment robustness is untested: rain, dust, mud, snow on shoes, puddles near doors, wind forces on panels, and outdoor lighting variability.
- Inter-task transfer and pretraining are unexplored: measure how DoorMan pretraining accelerates learning on new loco-manipulation tasks and analyze representation reuse in vision and control.
- Long-horizon multi-step sequences are not evaluated: opening, traversing, closing, and subsequent navigation; measure retention, reversibility, and cumulative error across chained behaviors.
- Policy interpretability and verification are absent: develop tools to inspect attention/latent states during contact, detect out-of-distribution observations, and certify safety under uncertainty.
Practical Applications
Practical Applications Derived from “Opening the Sim-to-Real Door for Humanoid Pixel-to-Action Policy Transfer”
Below are actionable, real-world applications that follow from the paper’s findings, methods, and innovations (DoorMan policy, teacher–student–bootstrap pipeline, staged-reset exploration, GRPO fine-tuning, and the IsaacLab-based randomized simulation). Each item notes likely sectors, candidate tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
The following can be piloted or deployed with current humanoid platforms and photorealistic simulation infrastructure.
- Autonomous door opening and traversal for building navigation
- Sectors: robotics, facilities management, logistics, hospitality, security
- What: Integrate the learned RGB-only policy to let humanoids open diverse push/pull doors and push bars while maintaining balance and fluency.
- Tools/Products/Workflows: “DoorMan” skill module integrated into existing whole-body control (WBC) stacks; deployment on Unitree G1-class humanoids; workflow for validation in IsaacLab with held-out textures/lighting; operator HMI to trigger “door autopilot.”
- Assumptions/Dependencies: Non-locked, standard-sized doors; sufficient onboard compute for 50 Hz inference; reliable WBC; camera placement/quality adequate under variable lighting; site safety policies for contact-rich autonomy.
- Teleoperation assist: “Door autopilot” for operator relief
- Sectors: robotics, security, telepresence, inspection
- What: Single-button autonomy for the specific subtask of door use during teleop missions, reducing operator workload and time, with instant fallback to manual control.
- Tools/Products/Workflows: Shared-autonomy mode in teleop consoles; safety interlocks and “hold position” behaviors; operator training playbooks.
- Assumptions/Dependencies: Human-in-the-loop oversight; robust failure detection and recovery; predictable human/traffic near doors.
- Last-10-meter indoor delivery and service routing
- Sectors: logistics, hospitality, office services
- What: Enable delivery and service robots to traverse non-automated doors between rooms to complete internal routing tasks.
- Tools/Products/Workflows: Mission planner integration that inserts “door skill” at known waypoints; building maps annotated with likely door types; IsaacLab simulation of route variants for pre-deployment testing.
- Assumptions/Dependencies: Door locations/types known or detected; human-aware navigation stack; building approval for autonomous door traversal.
- Facilities and custodial robotics
- Sectors: facilities management, janitorial services
- What: Routine room-to-room transitions for cleaning, inspection, and restocking tasks without retrofitting automatic door openers.
- Tools/Products/Workflows: Skill library for routine door variations (push bar, lever, pull); scheduling and logging for task auditability; maintenance interface to flag “non-openable” doors.
- Assumptions/Dependencies: Compliance with building and fire codes; predictable door mechanics (e.g., working springs, hinges).
- Security patrol and night operations
- Sectors: security, corporate campuses, warehousing
- What: After-hours patrols that require opening interior doors to complete assigned routes with repeatable timing.
- Tools/Products/Workflows: Patrol scheduler; “access control aware” routing (skip locked doors); event logging; geofenced autonomy zones.
- Assumptions/Dependencies: Doors are unlocked or access granted; quiet operation requirements; robust low-light performance or auxiliary lighting.
- Academic benchmarking and reproducible research on articulated loco-manipulation
- Sectors: academia, R&D labs
- What: Use the IsaacLab procedural door generator and the teacher–student–GRPO pipeline as a standardized benchmark for whole-body RGB loco-manipulation research.
- Tools/Products/Workflows: IsaacLab door asset packs; reference PPO+DAgger+GRPO scripts; ablation harnesses for visual/physics randomization coverage.
- Assumptions/Dependencies: GPU-accelerated simulation availability; reproducible rendering and physics settings; versioned benchmarks and seeds.
- Simulation asset pipelines for product teams
- Sectors: software, robotics R&D
- What: Adopt the photorealistic, physics-accurate, procedurally randomized door suite to generate scalable training/evaluation data for in-house robots.
- Tools/Products/Workflows: “Simulation asset packs” for doors and lighting domes; CI for regression on success rates; internal data catalogs of randomization coverage.
- Assumptions/Dependencies: Teams able to manage GPU clusters; careful parameter ranges to avoid unrealistic physics; QA for domain shift checks.
- RL training techniques for long-horizon tasks
- Sectors: robotics, software/ML tooling
- What: Apply staged-reset exploration to other tasks with narrow “transition bridges” (e.g., plugging, latching, multi-part assembly).
- Tools/Products/Workflows: Staged-reset plugin for PPO-based libraries; snapshot buffer management; state-distribution reweighting dashboards.
- Assumptions/Dependencies: Fully recoverable simulators; sensible stage definitions and reward decompositions.
- GRPO fine-tuning for partial observability in vision policies
- Sectors: robotics, software/ML tooling
- What: Drop-in actor-only PPO variant to refine imitation-learned policies where privileged perception is absent, improving closed-loop stability.
- Tools/Products/Workflows: GRPO training recipe using binary success + regularizers; curriculum schedules; minimal success-signal integration into existing pipelines.
- Assumptions/Dependencies: Non-zero initial success; sufficient sim diversity; careful clipping/tuning for stability.
- Cost-optimized sensor suites for mobile manipulators
- Sectors: hardware/robotics productization
- What: Replace or complement depth sensors with monocular RGB for door interaction, reducing BOM and calibration complexity.
- Tools/Products/Workflows: Camera selection and calibration guidelines; robust exposure/auto-white-balance configs; performance tests under illumination extremes.
- Assumptions/Dependencies: Acceptable performance degradation in low-light/high-glare; camera mounting that preserves field-of-view during gait.
- Safety and human-factors evaluation frameworks
- Sectors: policy, compliance, insurance
- What: Use quantifiable improvements over teleop (e.g., ~23–32% faster completion) to motivate safety cases and standardized tests for contact-rich humanoid interactions.
- Tools/Products/Workflows: Test protocols for door types; success/fluency metrics; near-miss and force-limit logging.
- Assumptions/Dependencies: Agreement on acceptable contact forces and fail-safe behaviors; third-party certification pathways.
Long-Term Applications
These require broader task coverage, additional sensing/controls, scaling, or regulatory readiness.
- General articulated-object interaction beyond doors
- Sectors: robotics, smart buildings, retail, manufacturing
- What: Extend the pipeline to drawers, cabinets, gates, latches, and appliances (knobs, switches), creating a comprehensive “articulated skill” library.
- Tools/Products/Workflows: Expanded procedural asset generators; multi-task teacher–student distillation; task-agnostic reward strategies.
- Assumptions/Dependencies: Accurate contact models for varied mechanisms; grasp diversity; advanced compliance control.
- Home assistance and eldercare
- Sectors: healthcare, consumer robotics
- What: Personal robots that navigate homes, open doors safely near humans, and assist mobility-impaired users.
- Tools/Products/Workflows: Human-aware planning; safety-certified behaviors; voice/gesture-triggered “door assist.”
- Assumptions/Dependencies: Rigorous safety and hygiene standards; compact, quiet hardware; affordable platforms.
- Hospital and clinical operations
- Sectors: healthcare
- What: Support logistics and routine tasks (e.g., moving supplies between wards) across door-heavy layouts while respecting sterile zones.
- Tools/Products/Workflows: Sterility-compliant hardware covers; corridor etiquette policies; EMR/logistics integration.
- Assumptions/Dependencies: Infection control approval; restricted-area access coordination; predictable pedestrian flow.
- Disaster response and public safety
- Sectors: public safety, defense, utilities
- What: Door and gate manipulation under debris, poor visibility, deformation, or unknown mechanics.
- Tools/Products/Workflows: Tactile and force sensing augmentation; thermal/low-light perception; “exploration-first” staged resets for uncertain mechanisms.
- Assumptions/Dependencies: Robust hardware to higher forces; fault-tolerant control; specialized training domains.
- Industrial and construction sites
- Sectors: construction, energy, heavy industry
- What: Opening heavy, non-standard, or safety-critical doors (blast doors, equipment enclosures) during inspection or maintenance routes.
- Tools/Products/Workflows: High-force capable end-effectors; torque-limited compliance; site-specific simulation packs with realistic hinge dynamics.
- Assumptions/Dependencies: Stronger actuation; PPE and site safety policies; operator authorization for safety interlocks.
- Foundation policies for whole-body loco-manipulation
- Sectors: robotics, AI research
- What: Scale the teacher–student–GRPO framework across many tasks to create generalist pixel-to-action humanoid policies.
- Tools/Products/Workflows: Multi-task curricula; large-scale randomized assets; unified success-shaping strategies; offboard training clusters.
- Assumptions/Dependencies: Compute scale; robust generalization across tasks; comprehensive eval suites.
- Building design and policy for robot accessibility
- Sectors: policy, architecture, real estate
- What: Update building codes and design standards (handle types, clearances, push bars) to ease robot traversal without retrofitting automation.
- Tools/Products/Workflows: Robot-accessibility guidelines; door-hardware procurement specs; simulation-based pre-occupancy audits.
- Assumptions/Dependencies: Stakeholder consensus; demonstrated safety/economic benefits; transitional retrofits in legacy buildings.
- Edge optimization and model compression for onboard deployment
- Sectors: hardware/software co-design
- What: Compress and optimize the vision + LSTM policy for low-power compute, enabling longer missions and smaller payloads.
- Tools/Products/Workflows: Quantization/distillation pipelines; runtime profiling; perception-control co-design to maintain 50 Hz.
- Assumptions/Dependencies: Acceptable accuracy drop; thermal constraints; improved scheduling on heterogeneous SoCs.
- Compliance and certification frameworks for contact-rich autonomy
- Sectors: standards bodies, insurers, regulators
- What: Define certification processes for contact forces, failure handling, and human proximity during articulated manipulation.
- Tools/Products/Workflows: Standard test doors and metrics; traceable logs; third-party audits.
- Assumptions/Dependencies: Industry-wide risk models; insurance acceptance; incident reporting infrastructure.
- Mixed-modality extensions for robustness
- Sectors: robotics
- What: Fuse RGB with low-cost depth, tactile, or event cameras to improve robustness in low light, specularities, or occlusions while keeping costs low.
- Tools/Products/Workflows: Sensor fusion encoders; partial-observability curricula; fallback policies.
- Assumptions/Dependencies: Minimal added complexity; integration with existing form factors; retraining at scale.
Notes on feasibility across applications:
- Hardware readiness: Success depends on stable humanoid WBC, sufficient payload for cameras and compute, and battery life compatible with patrol/service loops.
- Environment variability: While broad domain randomization helps, extreme or rare door mechanics may still require fine-tuning or demonstrations.
- Safety and compliance: Contact-rich behaviors near people require conservative force limits, fail-safes, and human-aware navigation.
- Simulation coverage: Transfer quality hinges on the breadth and realism of physics/appearance randomization and the alignment of onboard cameras with simulated setups.
Glossary
- Articulated-object interaction: Interaction with objects composed of multiple connected parts that move via joints (e.g., doors, drawers). "using articulated-object interaction as a representative high-difficulty benchmark."
- Camera intrinsics/extrinsics: Intrinsics are internal camera parameters (e.g., focal length), extrinsics describe the camera’s pose relative to the world. "Visually, we randomize materials, lighting, and camera intrinsics/extrinsics."
- Clipped PPO surrogate: The objective function in PPO that clips policy updates to stabilize training. "update πS using the clipped PPO surrogate:"
- Closed-loop consistency: Stability and coherence of behavior when actions depend on continuous feedback from observations. "improves closed-loop consistency in sim-to-real RL."
- Contact wrenches: Combined force and torque vectors at contact points describing interaction forces. "net contact wrenches on the 18 hand bodies"
- DAgger: Dataset Aggregation; an imitation learning method that iteratively collects data under the learner’s policy. "The student is interactively distilled using DAgger"
- Discount factor: Scalar in RL that weights future rewards relative to immediate rewards. "γ∈[0,1) the discount factor"
- Discounted occupancy measure: Distribution over states visited by a policy, weighted by the discount factor across time. "with an updated discounted occupancy measure"
- Domain randomization: Technique that randomizes visual and physical properties in simulation to improve real-world transfer. "we build a large-scale domain randomization pipeline in IsaacLab"
- Dome-light textures: Environment lighting maps (HDRI) used to simulate diverse illumination conditions. "5233 dome-light textures are applied"
- Egocentric camera: A camera viewpoint attached to the agent/robot, reflecting its perspective. "from a moving egocentric camera"
- End-effector poses: Positions and orientations of a robot’s manipulators (hands/arms) relative to the task. "adjusting end-effector poses to maintain visibility."
- Group Relative Policy Optimization (GRPO): An actor-only PPO variant that uses group-normalized returns as baselines. "we fine-tune the student policy with a Group Relative Policy Optimization (GRPO) algorithm"
- Hinge damping: Resistance in a hinge joint that dissipates motion and affects door dynamics. "door-hinge damping"
- Initial state distribution: Distribution over starting states in an RL environment. "ρ0 the initial state distribution"
- IsaacLab: NVIDIA’s GPU-accelerated simulation framework for robot learning and domain randomization. "We then describe a large-scale synthetic generation pipeline in IsaacLab"
- Inverse kinematics: Computing joint configurations that achieve a desired end-effector pose. "via inverse kinematics"
- Latching mechanism: Mechanical system that keeps a door closed until actuated to release. "realistic latching mechanism"
- Loco-manipulation: Coordinated whole-body locomotion and manipulation tasks performed simultaneously. "vision-based humanoid loco-manipulation"
- LSTM: Long Short-Term Memory; a recurrent neural network unit for sequence modeling. "a two-layer LSTM (512 units each)"
- MLP: Multilayer Perceptron; a feedforward neural network with multiple fully connected layers. "A three-layer MLP (512, 256, 128) then maps the recurrent features to target joint angles."
- On-policy RL: Reinforcement learning where data is collected using the current policy being optimized. "see its effect in on-policy RL"
- PD control law: Proportional-Derivative control used to track joint targets with feedback. "tracked by low-level motors using a PD control law."
- Photorealistic simulation: High-fidelity rendering and physics that closely resemble real-world appearance and behavior. "Recent progress in GPU-accelerated, photorealistic simulation"
- Physically Based Rendering (PBR): Rendering approach using physically accurate material and lighting models. "IsaacLab's Physically Based Rendering (PBR) materials"
- POMDP: Partially Observable Markov Decision Process; formal model where the agent has limited observability. "Consider a partially observable Markov decision process (POMDP)"
- Privileged observations: Simulator-only information (e.g., exact poses, forces) unavailable to the real robot at deployment. "a teacher policy with privileged observations."
- Proprioception: Internal sensing of the robot’s state (e.g., joint angles, velocities). "fusing a vision encoder with proprioception under aggressive visual randomization."
- Proximal Policy Optimization (PPO): A stable policy-gradient RL algorithm with clipped updates. "We train the teacher policy using standard proximal policy optimization (PPO)"
- Reset distribution: The distribution from which environments are initialized at different stages. "each stage's reset distribution ρy"
- Rolling buffer: A fixed-size cache storing recent simulator snapshots for staged resets. "a rolling buffer keeps the recent 100 snapshots of the robot and environment"
- Reward shaping: Adding auxiliary reward terms to guide learning toward desired behaviors. "with the exact reward shaping recipe available in Appendix"
- RTX Real-Time renderer: NVIDIA’s real-time ray-traced renderer used for efficient photorealistic simulation. "we use the RTX Real-Time renderer in performance mode"
- Sim-to-real: Transferring policies learned in simulation to real-world deployment. "improves closed-loop consistency in sim-to-real RL."
- Stage-based reward system: Task decomposition into phases, each with tailored rewards. "we design a stage-based reward system to decompose the task into atomic stages"
- Stage-conditioned rewards: Reward terms conditioned on the current task stage to guide progression. "trained via reinforcement learning (RL) with stage-conditioned rewards."
- Staged-reset exploration: Resetting environments to later-stage snapshots to increase exploration of rare transitions. "a staged-reset exploration strategy that stabilizes long-horizon privileged-policy training"
- Teacher-student-bootstrap: Pipeline where a privileged teacher is distilled into a vision-only student and then refined. "we develop a teacher-student-bootstrap learning framework"
- Teleoperation: Human control of a robot remotely, often via VR devices and joysticks. "teleoperation-centered pipelines"
- Transition kernel: Probability model of next states given current state and action in an MDP/POMDP. "T(s'|s,a) the transition kernel"
- Vision encoder: Neural network module that extracts features from images for control. "The image is processed by a vision encoder"
- Whole-body control (WBC): Coordinated control of all robot joints (arms, legs, torso) for balance and manipulation. "coordinate vision and whole-body control (WBC)"
- Zero-shot: Achieving performance on unseen real-world tasks without additional real-world training. "achieves robust zero-shot performance across diverse door types"
Collections
Sign up for free to add this paper to one or more collections.