MotionTrans: Human VR Data Enable Motion-Level Learning for Robotic Manipulation Policies
Abstract: Scaling real robot data is a key bottleneck in imitation learning, leading to the use of auxiliary data for policy training. While other aspects of robotic manipulation such as image or language understanding may be learned from internet-based datasets, acquiring motion knowledge remains challenging. Human data, with its rich diversity of manipulation behaviors, offers a valuable resource for this purpose. While previous works show that using human data can bring benefits, such as improving robustness and training efficiency, it remains unclear whether it can realize its greatest advantage: enabling robot policies to directly learn new motions for task completion. In this paper, we systematically explore this potential through multi-task human-robot cotraining. We introduce MotionTrans, a framework that includes a data collection system, a human data transformation pipeline, and a weighted cotraining strategy. By cotraining 30 human-robot tasks simultaneously, we direcly transfer motions of 13 tasks from human data to deployable end-to-end robot policies. Notably, 9 tasks achieve non-trivial success rates in zero-shot manner. MotionTrans also significantly enhances pretraining-finetuning performance (+40% success rate). Through ablation study, we also identify key factors for successful motion learning: cotraining with robot data and broad task-related motion coverage. These findings unlock the potential of motion-level learning from human data, offering insights into its effective use for training robotic manipulation policies. All data, code, and model weights are open-sourced https://motiontrans.github.io/.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
What is this paper about?
This paper shows a new way to teach robots how to move their arms and hands by learning directly from human demonstrations recorded in virtual reality (VR). The system, called MotionTrans, turns human VR recordings into a form robots can understand, then trains robot controllers on both human and robot examples so the robot can copy human motions—even for tasks it has never practiced on the robot.
Why is this hard?
Collecting lots of real-robot demonstrations is slow and expensive. While robots can learn to see and understand language from internet data, learning the actual “how to move” part is tricky. Human motion data is plentiful and diverse—but humans and robots have different bodies and speeds, so simply copying doesn’t work. MotionTrans tackles this gap.
Key Questions the Paper Tries to Answer
- Can a robot learn brand‑new motions directly from human VR data, without any robot examples for those tasks (“zero‑shot”)?
- If it can’t fully complete a task, will it at least move in the right direction (show meaningful progress)?
- What training strategies and data matter most for motion transfer?
- How do different robot models (types of controllers) compare?
How MotionTrans Works
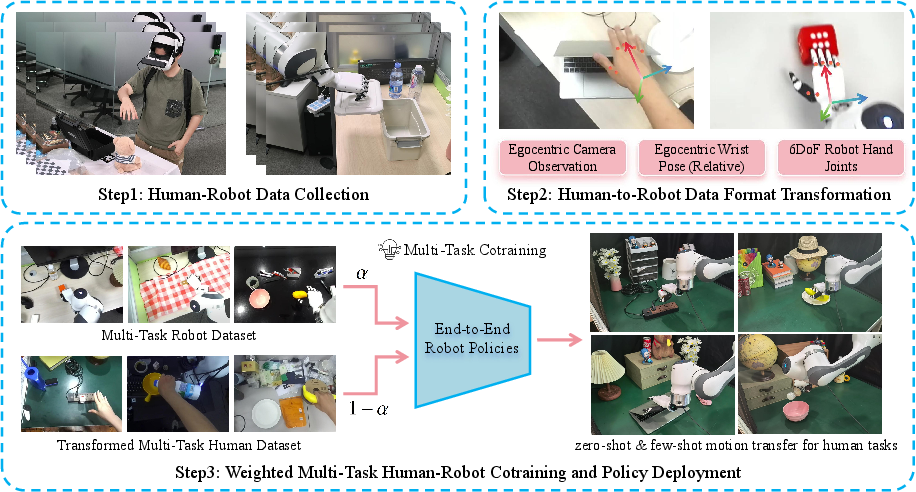
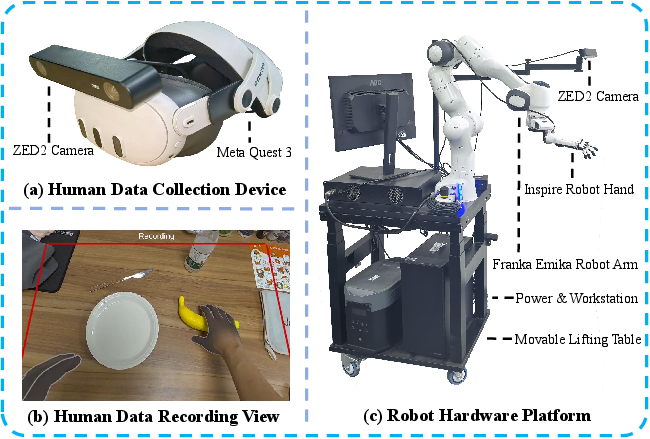
Step 1: Collect two kinds of data
- Human VR data: People wear a VR headset and perform everyday tasks (like picking up an orange and putting it in a bucket). The system records:
- First‑person camera images (what you see)
- Hand keypoints and wrist positions (where your fingers and wrist are)
- Robot data: A human controls a real robot arm and hand (teleoperation), and the system records:
- Robot’s first‑person camera images
- Robot’s wrist and hand joint positions (how the robot is moving)
Think of this like building a bilingual dictionary: one side is “human movement,” the other is “robot movement.”
Step 2: Translate human data into “robot format”
To help the robot learn from human examples, MotionTrans converts human recordings into the same kind of inputs and outputs robots use:
- Egocentric images: Both human and robot use first‑person views so scenes look similarly laid out.
- Wrist poses in the same camera coordinate system: Positions are measured relative to the camera, so “move forward 10 cm” means the same for both.
- Hand retargeting: Human finger positions are mapped to robot finger joints using an optimizer, like fitting a glove designed for a robot hand.
Helpful tweaks:
- Slow down human motions (by 2.25×). Humans move faster; slowing down makes motions safer and smoother for robots.
- Use relative movements (move forward/rotate right) instead of absolute positions to reduce mismatch in comfortable workspaces.
- Vary camera viewpoints during recording to make the robot robust to different angles.
Step 3: Train one policy on both sources (“weighted cotraining”)
MotionTrans trains a single controller (“policy”) using a balanced mix of human and robot data. This is like learning from both a textbook (robot data) and real-life videos (human data), giving the robot richer experience but keeping it grounded in what its body can actually do.
Two popular policy types are tested:
- Diffusion Policy (DP): Think of it as starting with a rough plan and repeatedly refining it into a precise motion sequence.
- Vision‑Language‑Action (‑VLA): A model that can read task instructions and see images, then output actions. It’s good at following instructions like “pour the bottle.”
Technical term translations:
- Proprioception: The robot’s “sense of self”—knowing where its wrist and fingers are.
- Egocentric view: A first‑person camera, like a GoPro mounted on your head.
- Zero‑shot: Doing a task without any robot practice on that task.
- Few‑shot finetuning: Giving the robot a small number of demos to polish its skills after pretraining.
- Weighted cotraining: Balancing losses so human and robot data contribute fairly during training.
Main Findings
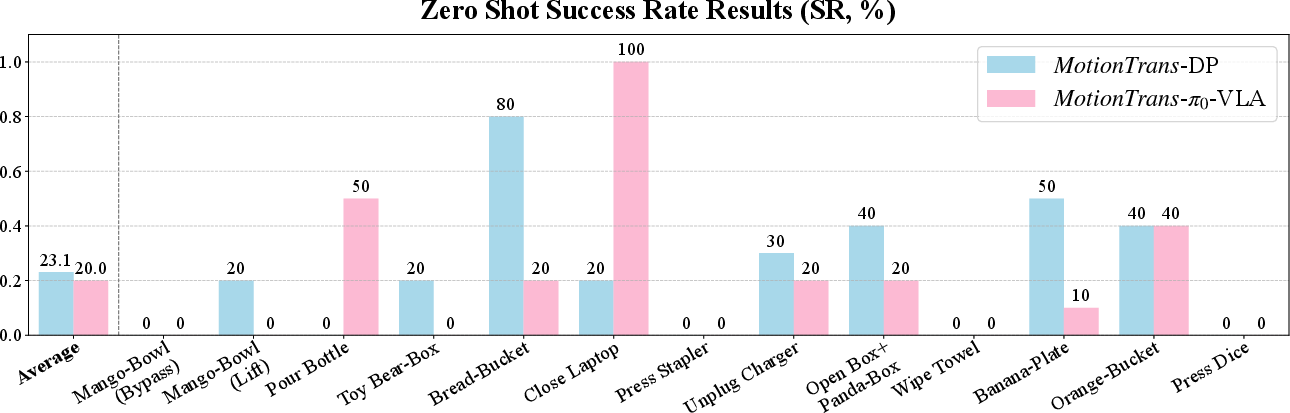
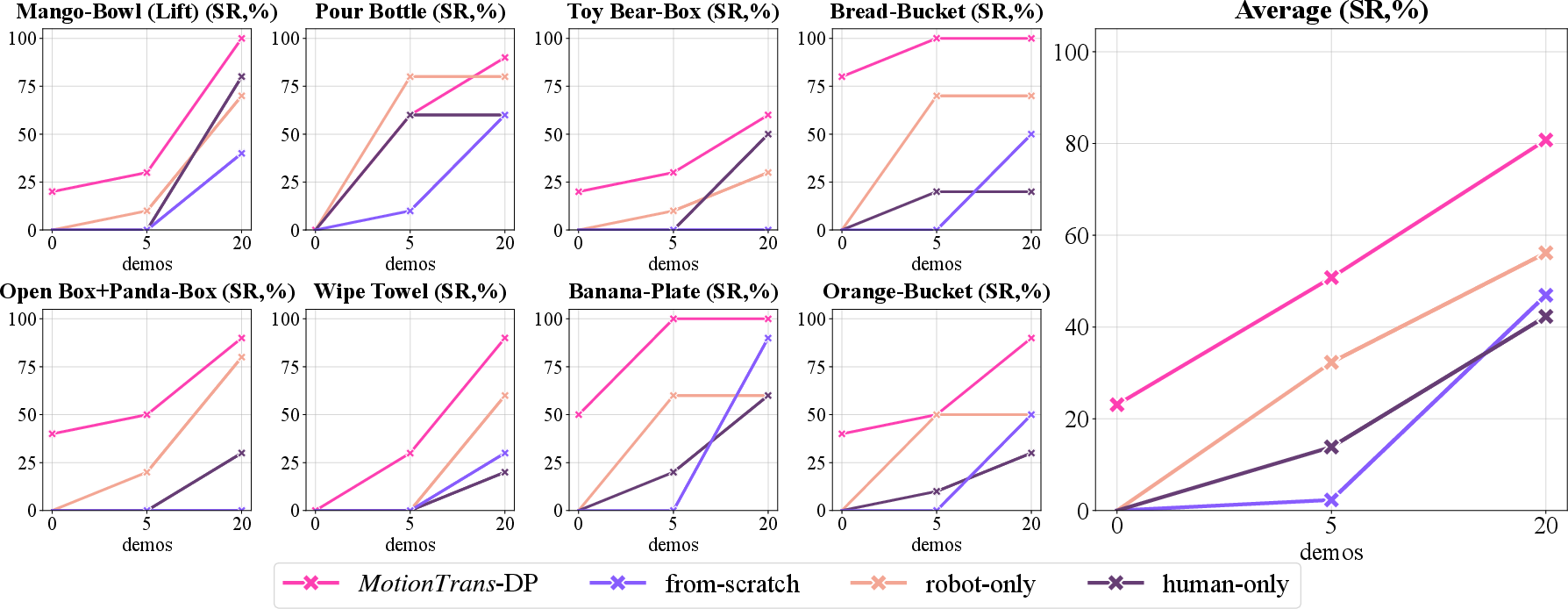
1) Zero‑shot motion transfer works
- The robot successfully completed 9 out of 13 human‑only tasks without any robot demos for those tasks.
- Average success across these tasks was about 20%.
- Pick‑and‑place tasks worked best (e.g., “Orange to Bucket”), likely because they’re common, simpler, and share similar motion patterns.
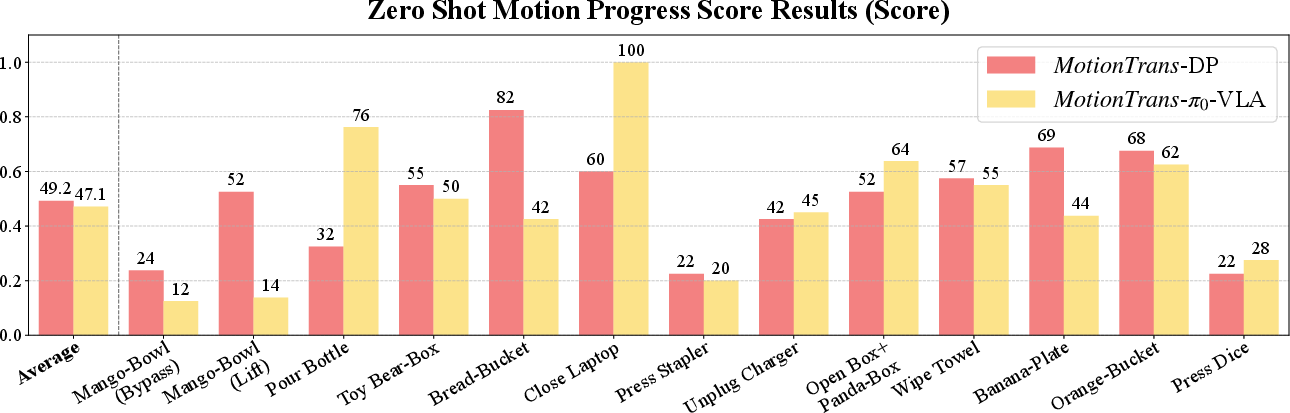
Even when the robot didn’t fully complete a task, it often made meaningful progress—like reaching the right object or starting the correct motion (measured with a “Motion Progress Score” around 0.5 on average).
2) Training with robot data is essential
- If the policy is trained only on human data (no robot data), zero‑shot success drops to 0%. It moves randomly when deployed on the robot.
- Cotraining with robot examples helps the robot adapt human motions to its own body.
3) Different models shine in different ways
- Diffusion Policy (DP) was better at precise hand movements (like grasping). Across pick‑and‑place tasks, DP grasped successfully about 65% of the time vs. 20% for ‑VLA.
- ‑VLA was better at following task instructions for complex motions (like fully rotating a bottle to pour).
4) Pretraining boosts few‑shot finetuning
When you later give the robot a few actual demonstrations for these tasks:
- Pretraining on MotionTrans (human + robot) increases success rate by roughly 40% compared to training from scratch.
- Robot‑only pretraining helps more than human‑only (same embodiment matters), but the combination (human + robot) is best.
- Pretraining helps most when you have very few finetuning demos (like 5). With more demos (like 20), the advantage shrinks but is still helpful.
5) Practical design tips
- Use unified normalization for actions across human and robot data (keeps training and testing consistent).
- Adding a rendered robot into human videos didn’t help much in this setup.
- Slowing human motions and using relative poses make transfer smoother and safer.
Why It Matters
Big picture impact
- Faster learning: MotionTrans lets robots learn new motions directly from rich, easy‑to‑collect human VR data, cutting down on expensive robot demonstration collection.
- Broader skills: With diverse human tasks, robots pick up motion patterns that generalize—reaching, grasping, pouring, unplugging, pressing, lifting, opening/closing, and wiping.
- Practical guidance: The paper identifies key ingredients for success—cotraining with robot data and wide coverage of related motions—giving a recipe for building better robot training datasets and systems.
What this could lead to
- Home and workplace robots that learn from people more naturally.
- Safer deployment by slowing and translating human motions into robot‑friendly formats.
- Open research progress: The authors released their data, code, and models so others can build on this.
In short, MotionTrans shows that robots can learn the “how to move” part directly from human VR recordings when trained smartly—making motion learning more scalable, practical, and effective.
Knowledge Gaps
Below is a concise, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions to guide future research.
- Embodiment generality: Validate motion transfer across diverse robot embodiments (e.g., multi-finger hands with different kinematics, simple parallel grippers, left vs. right hands, mobile manipulators) and quantify degradation or failure modes when retargeting across morphologies.
- Bimanual and long-horizon tasks: Extend from single-arm, single-step motions to bimanual coordination, tool-use, and multi-stage, long-horizon activities with explicit subgoal sequencing.
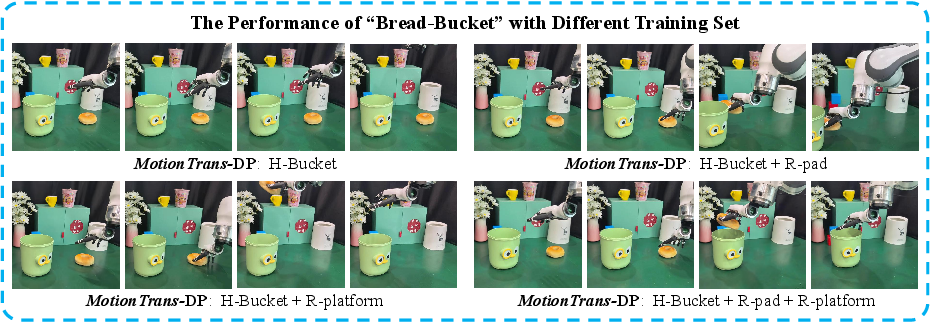
- Data requirements for motion transfer: Systematically quantify how the amount, type, and task similarity of robot cotraining data influence zero-shot transfer (e.g., learning curves over number of robot tasks, overlap in motion primitives, and coverage of contact events).
- Motion coverage metrics: Define and measure “task-related motion coverage” (referenced as key) with concrete metrics (e.g., trajectory diversity, contact event variety, pose-space coverage) and correlate these with transfer success.
- Weighted cotraining strategy: Explore alternative sampling/weighting schemes beyond size-balanced weights (e.g., curriculum learning, uncertainty-based sampling, per-task/domain importance weights) and report sensitivity analyses/hyperparameter sweeps.
- Domain adaptation stability: Revisit and benchmark modern, stable cross-domain alignment techniques (e.g., feature-level adapters, distribution matching with regularization, domain-specific normalization layers) to understand when and why they help or hurt motion transfer.
- Action representation design: Compare absolute vs relative SE(3) actions, joint vs Cartesian spaces, velocity vs position control, and action-horizon lengths; quantify their effect on transfer, especially for precise contact phases (grasp, unplug, press).
- Force/tactile information: Evaluate whether adding force/torque, tactile, or impedance control signals improves contact-rich skills (e.g., unplugging, pressing, wiping) that currently show low zero-shot success.
- Retargeting fidelity: Quantify errors introduced by dex-retargeting (IK) from human keypoints to robot joints (e.g., pose error, self-collision frequency) and study their impact on policy learning; compare optimization-based vs learning-based retargeters.
- Temporal resampling: Replace the fixed 2.25× slowdown with adaptive temporal resampling/downsampling and analyze safety, stability, and performance trade-offs across tasks with different motion speeds.
- Calibration and synchronization: Provide quantitative calibration error and time-sync measurements between VR, camera, and action streams; study how misalignment affects policy performance and develop online auto-calibration/sync correction.
- Viewpoint robustness: Move beyond “minimize head motion” by training/evaluating with natural head movements, multi-view egocentric inputs, or exocentric–egocentric fusion; quantify the effect on transfer.
- Visual domain gap handling: Despite limited gains from simple rendering, test stronger visual bridging methods (e.g., 3D reconstruction + relighting, neural rendering, photorealistic inpainting, style augmentation) and measure their effect on zero-shot transfer.
- Normalization schemes: Systematically compare unified vs domain-specific vs task-specific normalization (per-feature, per-dimension, per-joint) and investigate adaptive normalization at inference to mitigate distribution shift.
- Architecture breadth: Evaluate additional sequence models (e.g., Transformer-based behavior cloning, diffusion-transformers, recurrent policies with memory) and hybrid DP–VLA architectures; analyze trade-offs between manipulation precision and instruction adherence.
- Closed-loop language use: Study language-conditioned corrective behaviors (e.g., iterative instruction, self-reflection), multi-step natural language plans, and disambiguation strategies to improve task adherence beyond simple paraphrased prompts.
- Evaluation metrics: Validate the custom Motion Progress Score with inter-rater reliability, release scoring scripts, and compare against standardized benchmarks to enable cross-paper comparability.
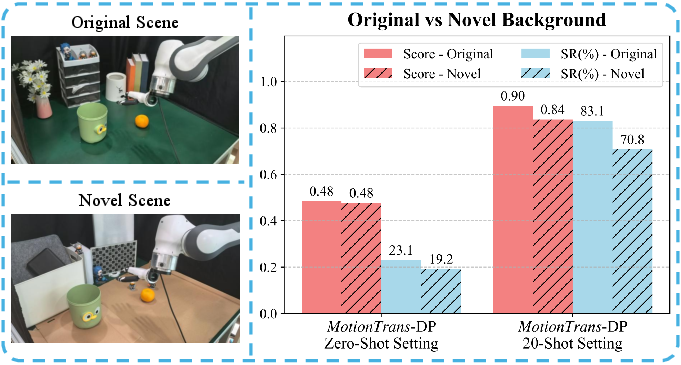
- Generalization to new scenes/objects: Provide controlled evaluations on novel environments, background shifts, and unseen object categories (beyond the default “green table”); report systematic out-of-distribution performance.
- Human data diversity: Report and analyze the number and diversity of human demonstrators (hand sizes, handedness, skill level), and quantify how subject diversity influences transfer and robustness.
- Deformable and liquid manipulation: The system excluded some tasks (e.g., folding towel, pouring milk bottle) due to hardware; evaluate with appropriate end-effectors/sensors and measure transfer for deformable/flowing materials.
- Safety and compliance: Quantify contact forces, collision rates, and failure recovery; integrate formal safety constraints or compliance controllers for zero-shot deployment in the presence of speed and embodiment mismatches.
- Failure mode taxonomy: Provide a detailed breakdown of failure phases (approach, alignment, grasp, manipulation, release) per task and tie each to dataset or modeling deficiencies to guide targeted data collection.
- Scaling laws: Establish scaling relationships between human data size/diversity and zero-/few-shot performance; identify diminishing returns and the most valuable motions/tasks to collect next.
- Few-shot finetuning boundaries: Characterize when human-only or robot-only pretraining suffices, and when combined pretraining is necessary, across a broader range of finetuning budgets and tasks.
- Language grounding robustness: Move beyond GPT paraphrases to test spontaneous human instructions with ambiguity, compositionality, and noise; measure instruction sensitivity and robustness.
- Real-time performance: Report inference latency, throughput, and compute requirements on robot hardware; analyze how control frequency affects precision, safety, and success.
- Comparison baselines: Devise fair comparisons to intermediate-representation pipelines (e.g., affordances, keypoints) by wrapping them into end-to-end training or evaluating on shared tasks, to contextualize gains from motion-level learning.
- Dataset bias and selection: Quantify how the “discard low-quality human demos” protocol influences dataset bias; provide statistics on rejection rates and their impact on learned policies.
- Privacy and ethics: Address consent, privacy, and data governance for in-the-wild human collection; outline anonymization and ethical deployment practices for broad adoption.
- Reproducibility across labs: Evaluate MotionTrans on different hardware stacks and sensing rigs to test reproducibility, reporting sensitivity to camera intrinsics, mount positions, and rig-specific calibration.
Practical Applications
Below is a concise synthesis of practical applications derived from the paper’s findings, methods, and innovations. Each item includes sector alignment, potential tools/products/workflows, and key assumptions or dependencies that may affect feasibility.
Immediate Applications
- Rapid bootstrapping of robot manipulation skills using human VR data
- Sector: robotics, manufacturing, warehousing, consumer robotics
- Tools/workflows: MotionTrans open-source dataset/code/model weights; Diffusion Policy or π₀-VLA; VR headset (Meta Quest 3) + ZED2 camera; dex-retargeting; unified action normalization; weighted cotraining; few-shot finetuning (5–20 demos)
- Assumptions/dependencies: availability of comparable robot hardware (e.g., Franka arm + dexterous hand), egocentric camera setup, accurate calibration, task similarity and motion coverage, safety controls for speed mismatch
- Low-cost remote data collection and pretraining pipeline for new tasks
- Sector: industry (field service, manufacturing), academia
- Tools/workflows: VR-based teleoperation and data capture in-the-wild; transform human data into robot observation–action space; pretrain on mixed human–robot data; finetune with limited robot demos
- Assumptions/dependencies: reliable LAN connectivity, collector guidance/feedback, sufficient scene diversity; data quality management
- Pretraining to improve few-shot finetuning performance (+40% success rate)
- Sector: robotics/software
- Tools/workflows: MotionTrans multi-task cotraining; reuse checkpoints to finetune on small robot datasets for target tasks
- Assumptions/dependencies: downstream tasks share motion primitives with pretrained set; embodiment remains consistent; appropriate normalization and action representations
- Personalized home robot training via VR demonstrations
- Sector: daily life, consumer robotics
- Tools/workflows: capture household tasks (pick-place, pour, wipe, press/open) via VR; transform and cotrain with existing robot data; finetune per household objects/scenes
- Assumptions/dependencies: single-arm tasks; dexterous gripper/hand; safety and supervision; alignment of egocentric viewpoints
- Assistive and eldercare task transfer from caregiver demonstrations
- Sector: healthcare/assistive robotics
- Tools/workflows: collect caregiver VR demonstrations for daily activities (e.g., fetching items, opening containers, pouring); pretrain and finetune for user-specific environments
- Assumptions/dependencies: strict safety validation; regulatory compliance; robust grasping precision; ethical data collection and consent
- Benchmarking and academic research on motion-level transfer
- Sector: academia
- Tools/workflows: use MotionTrans Dataset across >10 scenes; evaluate architectures (DP vs. π₀-VLA); adopt Motion Progress Score and success rate metrics; ablate normalization and action representations
- Assumptions/dependencies: reproducible setups; calibrated sensing; accessible compute
- Teleoperation-assisted training and fallback operations
- Sector: industrial robotics
- Tools/workflows: integrate teleoperation (Open-Television) to seed datasets and provide operational fallback while training policies
- Assumptions/dependencies: operator training; safe environment; latency and control stability
- Quality assurance and deployment-readiness evaluation
- Sector: robotics/software
- Tools/workflows: Motion Progress Score to quantify partial task competence (e.g., reaching vs. grasping vs. full completion); rollout protocols across diverse configurations
- Assumptions/dependencies: consistent scoring rubrics; standardized test scenes and object layouts
Long-Term Applications
- Generalist manipulation foundation models trained on large-scale human VR motion
- Sector: robotics/software
- Tools/products: scalable human-in-the-wild VR data pipelines; cross-task and cross-scene pretraining; model hubs for manipulation foundations
- Assumptions/dependencies: massive data collection; compute scaling; robust cross-domain generalization; safety certification
- Cross-embodiment motion transfer across diverse robot platforms
- Sector: robotics
- Tools/workflows: unified observation–action spaces; improved retargeting (multi-arm, mobile bases); adaptive speed downsampling; advanced domain adaptation
- Assumptions/dependencies: standardized kinematics interfaces; high-fidelity retargeters; hardware diversity and calibration
- Skill marketplaces and SDKs for motion-level policies
- Sector: software/robotics ecosystem
- Tools/products: “MotionTrans Studio” SDKs; skill packages (pick-place, pour, wipe, press/open); subscription services for pretraining/finetuning
- Assumptions/dependencies: IP/licensing/licence-compliant datasets; versioned model artifacts; integration with common robot stacks (ROS, OEM APIs)
- Healthcare and surgical robotics training from expert VR data
- Sector: healthcare
- Tools/workflows: collect surgeon procedures via VR; hierarchical policies for multi-step precision tasks; simulation-to-real validation
- Assumptions/dependencies: stringent regulatory approval; extremely fine manipulation precision; risk management; domain-specific hardware
- Field maintenance in energy and construction
- Sector: energy, construction
- Tools/workflows: teach robots motions like valve turning, pushing/pressing, lifting/opening via VR; deploy to hazardous environments after pretraining
- Assumptions/dependencies: ruggedized hardware; variable lighting and clutter; domain-specific safety and reliability standards
- Regulatory frameworks for crowdsourced human motion data collection
- Sector: policy and governance
- Tools/workflows: consent management; privacy preservation; data provenance/audits; guidelines for safe robot deployment trained from human data
- Assumptions/dependencies: stakeholder alignment; harmonized standards across jurisdictions; incident reporting and liability frameworks
- Human-in-the-loop adaptive training pipelines
- Sector: robotics
- Tools/workflows: online learning from updated VR demos; continuous evaluation with Motion Progress Score; safety gates to prevent catastrophic actions
- Assumptions/dependencies: robust monitoring; rollback mechanisms; real-time retargeting stability
- Long-horizon, multi-step task learning from human data
- Sector: robotics, manufacturing, household automation
- Tools/workflows: hierarchical policies; task graphs; temporal credit assignment; language-conditioned VLA extensions
- Assumptions/dependencies: richer datasets with complex sequences; improved memory architectures; better instruction-following and planning
- Standardized egocentric sensing kits and interoperability
- Sector: hardware/standards
- Tools/products: mass-produced VR + egocentric camera mounts; standardized calibration; shared coordinate frames across platforms
- Assumptions/dependencies: vendor cooperation; cross-device compatibility; cost-effective kits
- Retail/warehousing: fast onboarding of new SKUs via VR demonstrations
- Sector: retail, logistics
- Tools/workflows: capture human motions for handling novel items; zero-/few-shot policy updates; model monitoring for grasping precision
- Assumptions/dependencies: consistent packaging; grasp-friendly objects; robust perception under occlusion
- Synthetic/augmented data generation (improved rendering and sim-to-real)
- Sector: software/simulation
- Tools/workflows: advanced visual rendering to reduce domain gaps (robot insertion into human videos, physics-consistent sims); automated data augmentation
- Assumptions/dependencies: better rendering efficacy than current baselines; physics fidelity; validated transfer gains
- Safety-certified motion transfer and deployment protocols
- Sector: policy/industry standards
- Tools/workflows: standardized test suites; certification criteria using success rate and Motion Progress Score; change control processes
- Assumptions/dependencies: cross-industry consensus; third-party auditing; continuous post-deployment monitoring
Notes on core assumptions and dependencies across applications:
- Hardware parity: results are strongest when robot embodiment (arm/hand DOFs) aligns with human demonstrations; single-arm tasks are the current focus.
- Egocentric vision: shared camera viewpoint and coordinate frames are critical for effective transfer.
- Motion coverage: broad task-related motion in training is key to transfer; success improves with diverse scenes and objects.
- Safety and speed: human motion must be slowed/interpolated; safe planning and rate limits are essential.
- Data quality: calibration accuracy, consistent normalization, and reliable retargeting directly impact performance.
- Compute and scaling: multi-task cotraining and model training demand significant compute; benefits grow with dataset scale.
- Legal/ethical: privacy, consent, and licensure of human motion data must be addressed before commercialization.
Glossary
- Ablation study: A controlled experimental analysis that removes or varies components to identify their impact on performance. "Through ablation study, we also identify key factors for successful motion learning: cotraining with robot data and broad task-related motion coverage."
- Action chunk: A block of consecutive future actions predicted together by the policy. "The policy outputs an action chunk prediction ~\cite{chi2023diffusion}, where denotes the action prediction horizon."
- Action prediction horizon: The length of time steps into the future that the policy predicts actions for. "where denotes the action prediction horizon."
- Action-chunk-based relative poses: Representing actions as relative changes over an action chunk to reduce distribution mismatches. "We utilize action-chunk-based relative poses~\cite{chi2023diffusion, zhao2024aloha} as wrist action representation to reduce distribution mismatches between human and robot data."
- Affordances: Object properties or cues that indicate possible interactions or manipulations. "Previous works have leveraged human demonstrations to extract task-aware representations, such as affordances~\cite{bahl2023affordances} or keypoint flows~\cite{yuan2024generalflow}, to support motion transfer."
- Dex-retargeting library: A system that maps human hand keypoints to robot hand joint commands via inverse kinematics. "we employ the dex-retargeting library~\cite{qin2023anyteleop}, an optimization-based inverse kinematics solver, to map human hand keypoints to robot hand joint state ."
- Diffusion Policy: An end-to-end visuomotor policy that uses diffusion models to generate action sequences. "we focus on two widely-used architectures for imitation learning: Diffusion Policy~\cite{chi2023diffusion} and the Vision-Language-Action Model (-VLA)~\cite{black2024pi_0}."
- DINOv2: A large-scale self-supervised vision backbone used to improve visual perception in policy learning. "The visual encoder is replaced with DINOv2~\cite{oquab2023dinov2} to enhance visual perception ability~\cite{lin2024datascaling}."
- Domain adaptation: Techniques to transfer knowledge across differing data distributions or domains. "We also try domain adaptation training techniques like domain confusion~\cite{tzeng2017adversarial,tzeng2014mmd} to promote knowledge transfer from human domain to robot domain in our earlier exploration."
- Domain confusion: An adversarial training objective that encourages domain-invariant representations. "We also try domain adaptation training techniques like domain confusion~\cite{tzeng2017adversarial,tzeng2014mmd} to promote knowledge transfer from human domain to robot domain in our earlier exploration, but do not find it beneficial for motion transfer..."
- Egocentric camera coordinate system: A coordinate frame centered on the agent’s camera used for measuring poses. "We use the egocentric camera coordinate system (camera captures ) for both human and robot data."
- Egocentric view: A first-person visual perspective aligned with the agent’s viewpoint. "We use egocentric view for both human and robot data, as shown in Figure~\ref{fig:main_dataset}."
- Embodiment gap: The mismatch in physical form and capabilities between humans and robots that complicates transfer. "Considering the embodiment gap between human and robot~\cite{kareer2024egomimic}, we explore this problem within a multi-task humanârobot cotraining framework..."
- Few-shot finetuning: Adapting a pretrained model to new tasks using only a small number of demonstrations. "In this section, we investigate whether motion transfer from human-robot cotraining can also enhance performance in a few-shot finetuning setting..."
- Imitation learning: Learning policies by imitating behaviors from demonstrations rather than explicit reward optimization. "Scaling real robot data is a key bottleneck in imitation learning, leading to the use of auxiliary data for policy training."
- Instruction following: The capability of models to execute actions conditioned on natural language commands. "a policy architecture integrating large-scale pretrained Vision-LLMs~\cite{steiner2024paligemma} for multimodal perception and instruction following."
- Inverse kinematics: Computing joint configurations that achieve desired end-effector poses. "an optimization-based inverse kinematics solver"
- In-the-wild setting: Data collection in uncontrolled, real-world environments rather than lab settings. "For scene diversity (shown as the ``In the Wildâ metric), we report the proportion of data collected in daily-life environments (in-the-wild setting~\cite{lin2024datascaling, tao2025dexwild}) rather than controlled lab settings."
- Motion Progress Score: A metric quantifying partial task completion based on meaningful motion towards goals. "we define a Motion Progress Score (Score) to quantify the quality of policy motion for task completion."
- Motion-level learning: Learning transferable motion skills directly, rather than only perception or language understanding. "These findings unlock the potential of motion-level learning from human data, offering insights into its effective use for training robotic manipulation policies."
- Multi-task cotraining: Jointly training a single policy across multiple tasks from different data sources. "we systematically explore this potential through multi-task human-robot cotraining."
- Proprioceptive states: Internal sensor readings such as joint angles and poses used as policy inputs. "the policy receives an egocentric RGB image and proprioceptive states ."
- SLAM: Simultaneous Localization and Mapping, a technique to estimate sensor pose and build environment maps. "Human motion data can be captured through hand-held SLAM-based device~\cite{chi2024umi, xu2025dexumi}, but often limited to only wrist camera sensing~\cite{tao2025dexwild}."
- Teleoperation: Controlling a robot remotely by mirroring human motions. "For robot data collection, we use teleoperation to record demonstrations."
- Unified Action Normalization: Applying a single normalization scheme across domains to stabilize training and avoid train–test mismatch. "Unified Action Normalization. To improve training stability, we apply Z-score normalization to both proprioceptive states and actions before training~\cite{chi2023diffusion, chi2024umi}."
- Vision-Language-Action model: A policy that integrates vision, language, and action modalities for instruction-conditioned control. "Vision-Language-Action model (-VLA): we adopt network structure from~\cite{black2024pi_0}, a policy architecture integrating large-scale pretrained Vision-LLMs~\cite{steiner2024paligemma}..."
- Visual grounding: Linking visual inputs to semantic concepts or instructions to guide actions. "These works have shown policy improvements in visual grounding~\cite{luo2025being}, robustness~\cite{qiu2025humanoidhuman, yang2025egovla}, and training efficiency~\cite{bi2025hrdt, kareer2024egomimic}."
- Weighted cotraining: Balancing losses from different datasets during joint training to handle data imbalance. "a weighted cotraining strategy that jointly optimizes over both human and robot tasks."
- Zero-shot: Deploying a model on tasks without using any task-specific robot data at training time. "Notably, 9 tasks achieve non-trivial success rates in zero-shot manner."
Collections
Sign up for free to add this paper to one or more collections.