- The paper introduces parallel Newton methods that reframe sequential state evaluations as a global nonlinear root-finding problem, enabling O(log T) parallel iterations.
- It proposes quasi-DEER and ELK variants to balance scalability and stability, significantly reducing per-iteration computational and memory costs.
- Rigorous theoretical analysis and empirical results validate strong global convergence guarantees even in near-chaotic and high-dimensional settings.
Parallel Newton Methods: Foundations, Algorithms, and Parallelizing Sequential Computation
Introduction and Context
Sequential computation underpins essential primitives in machine learning, control, and simulation, with recurrent neural networks (RNNs) and discrete state space models (SSMs) as prominent examples. Historically, these models suffered from a strict O(T) sequential evaluation bottleneck, deemed "inherently sequential," therefore poorly matching the parallelism-rich architectures of modern hardware such as GPUs. This has driven the field toward architectures like Transformers that are "embarrassingly parallel."
This dissertation, "Unifying Optimization and Dynamics to Parallelize Sequential Computation: A Guide to Parallel Newton Methods for Breaking Sequential Bottlenecks" (2603.16850), systematically dismantles the assumption that nonlinear SSMs and RNNs must be inherently sequential. It develops a comprehensive methodology—parallel Newton methods—that enables efficient, scalable, and stable evaluation of nonlinear sequential processes on parallel hardware. The thesis provides deep theoretical characterizations of when such parallelization is possible and efficient, unifies disparate lines of numerical and machine learning research, and empirically demonstrates both the power and limitations of these techniques.
At its core, the approach reframes the evaluation of SSMs as a global nonlinear root-finding problem. Concretely, given a discrete-time Markovian system st+1=ft(st), the roll-out of states s1:T can be recovered by finding the unique root of the residual function:
r(s)=[s1−f1(s0),s2−f2(s1),…,sT−fT(sT−1)],
i.e., solving r(s⋆)=0. This high-dimensional root-finding problem is then targeted by Newton-type methods, which crucially leverage the block-bidiagonal structure of the Jacobian of r—allowing each Newton or quasi-Newton iteration to be computed by an explicit linear dynamical system (LDS), and hence parallelized using a prefix-sum/associative scan in O(logT) computational depth.
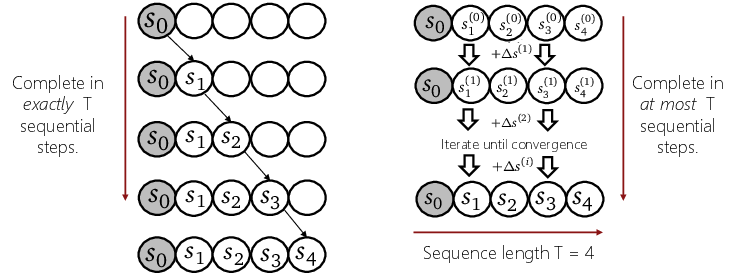
Figure 1: Comparison of standard sequential evaluation of an SSM (left) with parallel iterative evaluation of an SSM (right). In the parallel paradigm, updates for the entire sequence are computed in parallel.
In summary, SSM evaluation reduces to iteratively applying a block-tridiagonal linear operator—ideally suited for parallel scan algorithms extensively developed in the parallel computing literature.
Methodological Extensions: Quasi-Newton and Trust Region Methods
Practical application of parallel Newton methods faces two main challenges:
- Scalability: The memory and compute costs of a full Newton iteration across all T time steps and D-dimensional states scales as O(TD2) (memory) and O(TD3) (compute).
- Stability: Newton iterations can be numerically unstable for certain nonlinear dynamics, leading to divergence or prohibitively slow convergence.
Quasi-DEER: Diagonal Quasi-Newton Methods
To address scalability, the dissertation introduces quasi-DEER—parallel quasi-Newton methods using diagonal or other structured approximations to the dynamics Jacobians. This dramatically reduces per-iteration costs to O(TD), enabling deployments on large models and long sequences.
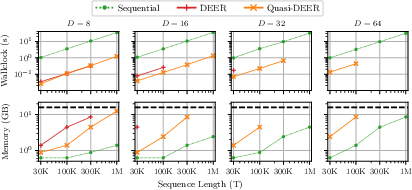
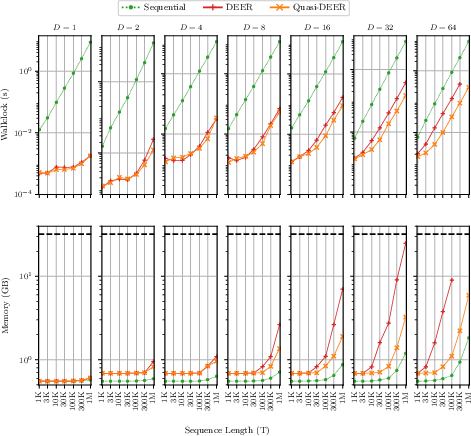
Figure 2: Relative wall-clock time and memory utilization of sequential, full Newton (DEER), and diagonal quasi-Newton (quasi-DEER) methods. Quasi-DEER achieves lower memory and computation overhead, scaling to larger sequences and states.
Despite these aggressive approximations, the paper proves strong global convergence guarantees: any quasi-Newton method in this class converges to the correct trajectory in at most T iterations, independently of initialization—a property rarely available for Newton-type algorithms in nonlinear settings.
Trust-Region Stabilization: ELK
To systematically address numerical instability, the dissertation develops a stabilized trust-region variant, ELK (Evaluating Levenberg-Marquardt with Kalman). ELK interprets each step as a damped Gauss-Newton update, which can itself be parallelized efficiently via the Kalman filter/smoother machinery. The trust-region perspective ensures stable progress even when naive Newton steps would be excessively aggressive.
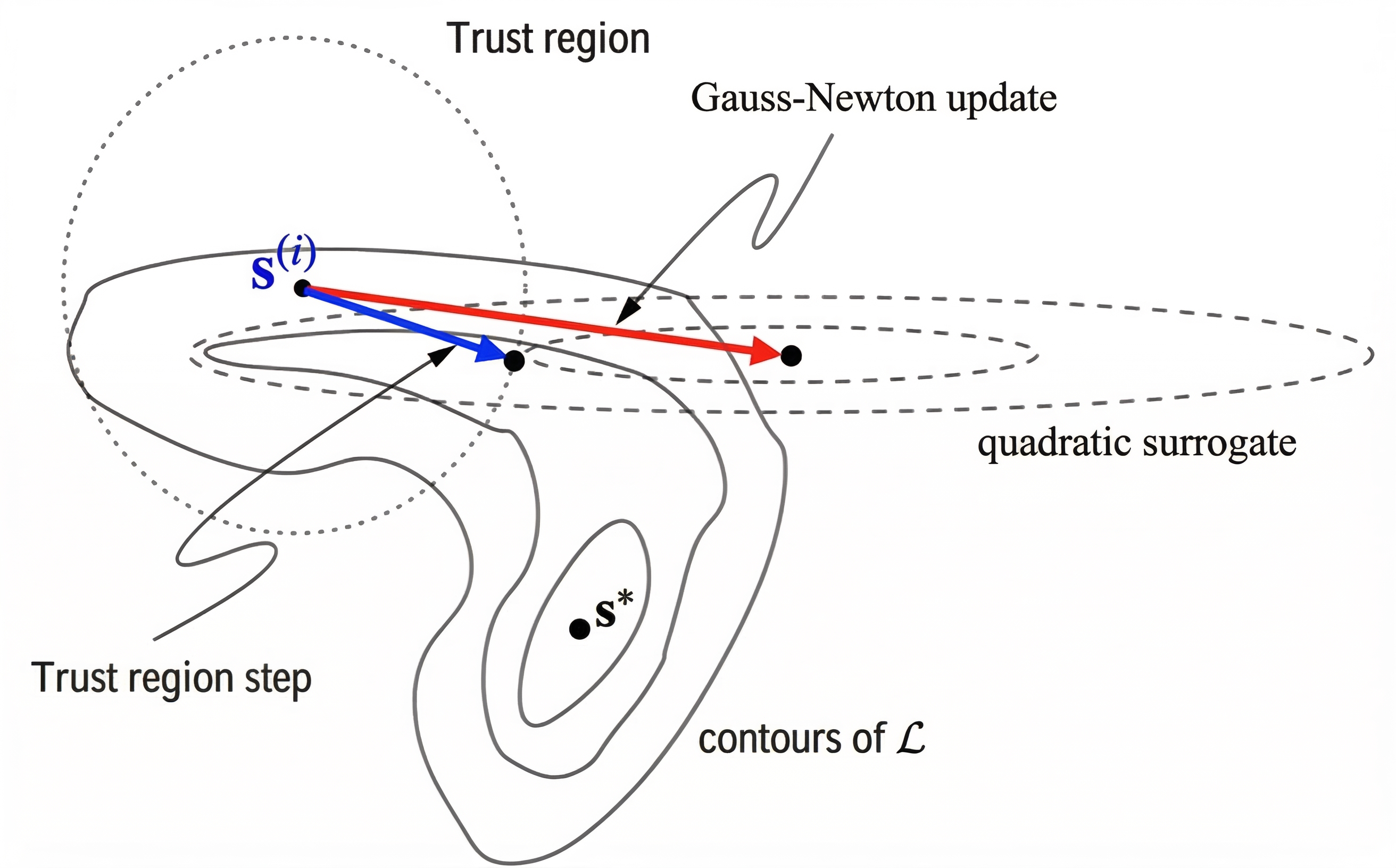
Figure 3: A trust-region (blue) step is bounded within the contours of a quadratic surrogate and the trust region, while an undamped Newton step (red) may overshoot. Trust-region methods stabilize Newton updates in nonconvex, ill-conditioned loss landscapes.
Empirical results confirm that ELK and its quasi-variants accelerate convergence and maintain stability in challenging nonlinear and near-chaotic recurrent systems where undamped methods either fail to converge or require disruptive heuristics.
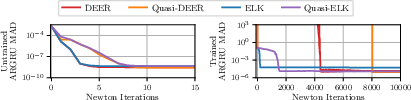
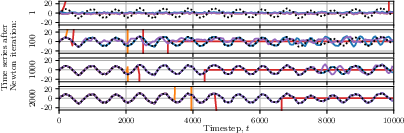
Figure 4: ELK stabilizes and accelerates the convergence of parallel evaluation in near-chaotic AR GRUs, outperforming undamped DEER which is often unstable.
Unification of Parallelizable Fixed-Point Methods
A major conceptual contribution is the unification of Newton, quasi-Newton, Picard, and Jacobi (and related) fixed-point solvers under a single linear-dynamical-system (LDS) framework. Each variant corresponds to a different (possibly structured or block-sparse) transition Jacobian in the LDS:
- Full Newton: dense, input-conditioned Jacobians (requiring most compute, fastest convergence if affordable);
- Quasi-Newton: structured approximations (diagonal, block-diagonal, or otherwise), trading off accuracy for efficiency;
- Picard/Jacobi: zeroth-order (no Jacobian), best matched for systems with weak or identity-like coupling.
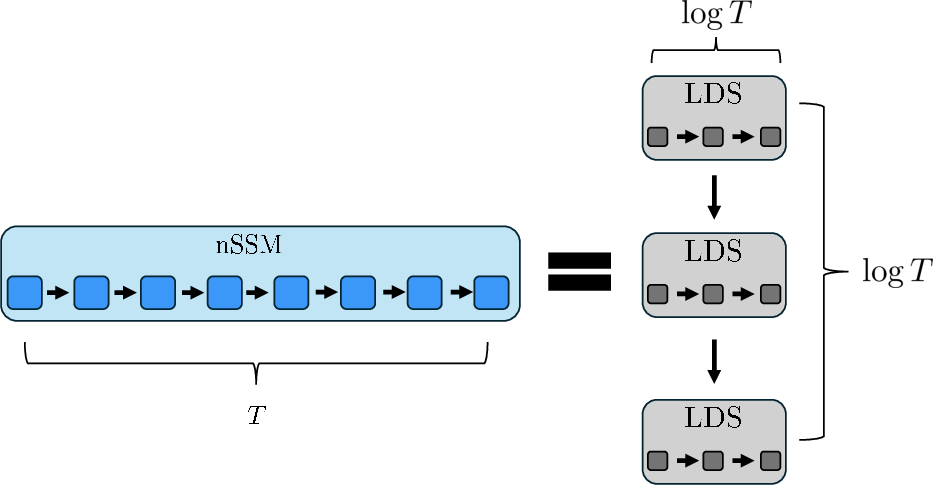
Figure 5: A contractive nonlinear SSM can be decomposed into an O(logT) stack of LDSs, each evaluated efficiently in parallel, mirroring the action of repeated quasi-Newton or Newton steps.
This fixed-point LDS perspective enables a systematic, problem-adaptive selection of parallel solvers based on underlying dynamics—providing practitioners with both theoretical guidance and practical recipes.
Theoretical Results: Conditioning, Convergence, and the Lyapunov Exponent
A central theoretical result is a precise characterization of when and why parallel Newton/quasi-Newton methods are efficient. The key determinant is the interplay between the largest Lyapunov exponent (LLE) of the system and the conditioning of the merit function minimized by the algorithm (Polyak-Łojasiewicz constant μ):
- Predictable/stable systems (LLE<0): the norm of Jacobian products decays exponentially (contractive system), resulting in a well-conditioned merit landscape (μ=Θ(1) for T→∞), allowing convergence in O(logT) iterations.
- Unpredictable/chaotic systems (LLE>0): Jacobian products can explode, making the merit landscape extremely flat (μ∼exp(−LLE⋅T)), leading to prohibitive iteration counts and eliminating any potential for practical speedup.
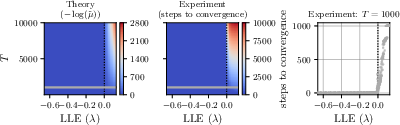
Figure 6: DEER (parallel Newton) exhibits rapid convergence for predictable RNNs (negative LLE), but iteration count grows superlinearly or exponentially in the unpredictable/chaotic regime (positive LLE), aligning tightly with theoretical conditioning predictions.
Rigorous proofs relate the worst-case and average-case convergence rates, the polylogarithmic scaling threshold, and the ultimate limitations of these methods—all in terms of the system’s dynamical predictability.
The dissertation provides extensive empirical validation on synthetic, controlled, and real-world sequence modeling tasks:
Implications and Future Directions
Practical Implications
- Choice of Solver: The best fixed-point method depends on both the system’s coupling structure (Jacobian approximation accuracy) and its contractivity (LLE/conditioning). Use the most structured/cheap approximation that yields acceptable convergence.
- Architecture Design: To maximize parallelizability, design sequence models to be predictable (contractive, negative LLE) where possible. Diagonal or block-diagonal structures are especially favorable for extreme scale.
- Hardware Adaptation: Efficient parallel scan implementations, chunking/sliding-window techniques, and low-precision/quantized arithmetic are all essential for deployment on modern hardware.
Theoretical Implications
- Merit Landscape Geometry: The core insight is that unpredictability (positive LLE) results in an excessively flat optimization landscape, explaining the inherent difficulty (or impossibility) of parallelization for chaotic or highly unstable systems.
- Unification of Algorithms: The LDS-based taxonomy elegantly connects classical numerical analysis, parallel computation, and modern machine learning.
Open Directions
- Extending parallel Newton techniques to general boundary-value, multi-scale, or multi-modal sequential problems.
- Bringing in further algorithmic ideas from numerical analysis (e.g., multigrid, Anderson acceleration, randomized linear solvers).
- Developing robust, hardware-aware, and numerically stable parallel scan primitives across all major ML frameworks.
- Integration into domain-specific applications where latency and sequence length preclude sequential evaluation (e.g., massive-scale simulation, parallel MCMC, neuromorphic computation).
Conclusion
This dissertation delivers a rigorous, unified framework for parallelizing nonlinear sequential computation using Newton-type and related methods. By thoroughly addressing both methodological and theoretical aspects—culminating in strong global guarantees for broad classes of quasi-Newton schemes, precise characterizations of convergence regimes, and a practical unification of fixed-point solvers—the work brings nonlinear SSMs and RNNs into the ambit of large-scale, parallel sequence modeling. The tools, results, and insights provided are set to inform future research in machine learning algorithms, sequential inference, and high-performance computing, and are anticipated to catalyze the design of new, scalable architectures beyond the current limitations of "inherently sequential" computation.