- The paper presents a framework that recasts diverse fixed-point methods (Newton, quasi-Newton, Picard, Jacobi) as iterative LDS evaluations to parallelize sequential models.
- It demonstrates reducing sequential runtime from O(T) to O(log T) through parallel scan algorithms and provides empirical case studies on convergence and resource trade-offs.
- The work offers practical guidelines for selecting methods based on convergence speed, memory use, and hardware constraints in RNNs, diffusion models, and other sequence tasks.
Unifying Parallel Fixed-Point Methods for Sequential Models via Linear Dynamical Systems
This paper presents a rigorous framework that unifies diverse approaches to parallelizing sequential machine learning models through the lens of Linear Dynamical Systems (LDSs). It demonstrates that fixed-point methods—including Newton, quasi-Newton, Picard, and Jacobi iterations—can all be cast as iterative LDS evaluations, thereby facilitating parallelization of nonlinear recursive processes that traditionally appear inherently sequential. The authors provide precise mathematical characterization, algorithmic details, and empirical guidance regarding method selection with respect to problem structure and hardware constraints.
Fixed-Point Iterations as Parallel Linear Dynamical Systems
The core technical contribution is the proof that fixed-point solvers for nonlinear recursions, xt+1=ft+1(xt), can be transformed into iterative application of LDSs, with the transition matrix At+1 approximating the Jacobian ∂xt∂ft+1. By executing these LDSs with a parallel scan algorithm, practitioners can reduce evaluation time from O(T) to O(logT) on appropriate parallel hardware.
- Newton Iterations use the full Jacobian for maximal convergence per iteration, but incur O(TD2) memory and O(TD3) compute per step.
- Quasi-Newton Iterations (e.g., diagonal Jacobian) lower computational cost to O(TD) but require more iterations.
- Picard Iterations set A=ID, yielding minimal memory footprint and computational cost.
- Jacobi Iterations set A=0, which is only suitable for non-Markovian recurrences.
An important theoretical result is global convergence for all these methods within T iterations for any Markovian sequence, irrespective of the linearization quality.
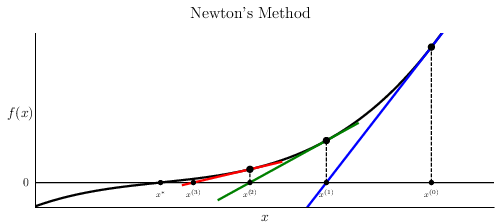
Figure 1: Iterative formation of "parallel chords" in Newton's method underlines the geometric intuition behind linearizing nonlinear recursive updates at each fixed-point iteration.
Method Selection: Empirical Case Studies
The framework is concretized via three canonical experiments, each assessing convergence properties and resource utilization trade-offs.
Case 1: Group Word Problem
Linear recursions with input-dependent, non-diagonal transition matrices (e.g., permutation matrices for S5 group word problem) demonstrate that Newton iterations converge in a single iteration, whereas Quasi-Newton and Picard require up to T iterations due to suboptimal Jacobian approximations. Wall-clock time confirms that full Newton is preferable when memory allows.
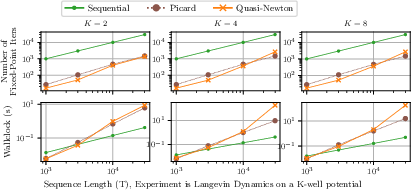
Figure 2: In a similar setting as Figure 2well (Langevin), fast convergence is observed for Newton iterations; alternative methods scale poorly with problem size.
Case 2: RNNs with Nonlinear Dynamics
Nonlinear GRU models with full coupling between latent dimensions are poorly approximated by ID (Picard) or diagonal Jacobians (Quasi-Newton), except possibly for special network initializations. First-order methods, especially Quasi-Newton, balance convergence speed and resource usage, outperforming Picard in both iterations and wall-clock time for typical RNN use cases.
Case 3: Langevin Dynamics and Diffusion Models
When the Jacobian is close to the identity—as in discretized Langevin diffusion with small step size—Picard iterations are highly efficient, rapidly converging with minimal hardware burden. This phenomenon generalizes to other scenarios with weak coupling or nearly identity dynamics functions.
Implementation and Deployment Guidance
Selecting the optimal fixed-point strategy involves balancing convergence per iteration, per-iteration resource intensity, and overall wall-clock time.
- Newton: Use for small-D and short-T, or when low-iteration count is critical and hardware permits full Jacobian evaluation.
- Quasi-Newton: Preferred in high-dimensional or long sequences, especially when diagonal Jacobian suffices—a sweet spot for practical deployment.
- Picard: Optimal for nearly-linear, weakly-coupled dynamics or when extreme memory constraints exist.
- Jacobi: Only for specialized non-Markovian architectures (e.g., deeply skip-connected networks).
Numerical stability must be actively monitored, especially for LDS matrices with spectral norm near unity. Chunking and hybrid fixed-point/scan strategies can further alleviate hardware bottlenecks.
Theoretical and Practical Implications
The unification of parallel fixed-point methods via LDSs establishes:
- A precise mapping between linearizations of nonlinear recursions and parallel scan implementations.
- Global convergence (within sequence length T) for all LDS-cast fixed-point methods in Markovian settings.
- Empirical guidelines for matching method to problem structure and hardware characteristics.
The framework lends itself to direct application in deep state space models, diffusion model sampling, implicit layers, MCMC, and any sequence modeling scenario requiring efficient parallel computation. Future work may focus on efficient parameterizations of structured transition matrices (e.g., block-diagonal, permutation, scaled identity), optimal chunking strategies, and integration with high-throughput hardware primitives.
Conclusion
By expressing Newton, quasi-Newton, Picard, and related solvers as iterative LDS evaluations that admit parallel scan computation, this work offers both an elegant theoretical synthesis and actionable guidance for practitioners seeking to parallelize inherently sequential machine learning processes. The authors’ case studies show that appropriate method selection—guided by Jacobian structure, memory constraints, and hardware specifics—enables significant efficiency gains in real-world deployments.
Future research directions include developing adaptive Jacobian approximations for intermediate complexity recurrences, optimizing LDS implementation on emerging hardware, and extending the framework to stochastic and probabilistic dynamical models. This unified treatment sets a foundational standard for both algorithmic analysis and design of parallel sequential model architectures.

