- The paper introduces a novel image-only training paradigm (IOMM) that decouples visual pre-training from text-image pairs to enhance efficiency.
- It employs a two-stage framework with a lightweight Residual Query Adapter and masked image modeling to refine generative quality.
- Empirical results show that the IOMM framework reduces computational cost while achieving state-of-the-art performance on UMM benchmarks.
Summary of "Rethinking UMM Visual Generation: Masked Modeling for Efficient Image-Only Pre-training" (2603.16139)
Introduction
The paper addresses the limitations of Unified Multimodal Models (UMMs) in visual generation, particularly their reliance on inefficient pre-training processes and scarce text-image paired data. It introduces a novel paradigm, Image-Only Training for UMMs (IOMM), designed to enhance data efficiency by decoupling the pre-training of visual generative components from paired data dependency. The methodology involves a two-stage training framework that initially leverages unlabeled image-only data and subsequently fine-tunes using a mixture of unlabeled images and text-image pairs. This approach not only improves training efficiency but also achieves state-of-the-art (SOTA) performance metrics.
Methodology
The IOMM framework introduces two key innovations:
- Residual Query Adapter (RQA): This adapter allows the adaptation of frozen Multimodal LLMs (MLLMs) to generative tasks without substantial parameter overhead. It refines visual conditions through a lightweight cross-attention mechanism.
- Masked Image Modeling: By framing the pre-training as a sparse-to-dense reconstruction task, the paper enhances the model's ability to learn a robust visual prior, fostering improved generative quality.
The training paradigm involves two stages, starting with pre-training on image-only data to build a foundational understanding, followed by fine-tuning on mixed datasets to align instructions and improve generation quality.
Experimental Results
Empirical validations demonstrate that the IOMM-B model, trained from scratch using image-only data, achieves impressive results with minimal computational cost—surpassing existing models like BAGEL-7B and BLIP3-o-4B on benchmarks such as GenEval and WISE. The model trained with IOMM shows improved data and compute efficiency while maintaining or improving performance. Results indicate an increased GenEval score and competitive scores in reasoning benchmarks like WISE, underscoring the approach's effectiveness.

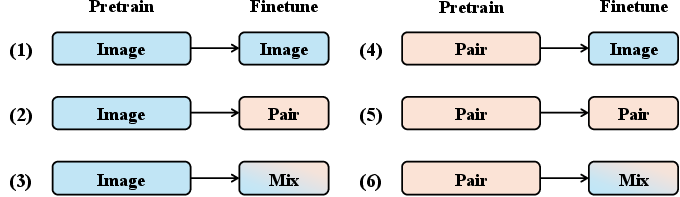
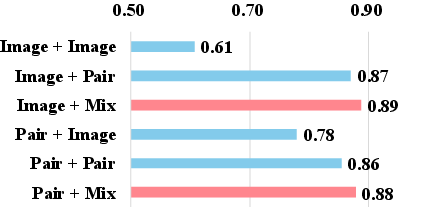
Figure 1: Multi-resolution visualizations from our IOMM-XL.
Impact on Unified Models
The paper conducts systematic analyses of six training recipes for UMMs, revealing that a two-stage paradigm yields the best performance. Mixed-data fine-tuning emerges as a generalizable and effective technique across various models, enhancing instruction-following fidelity and image generation quality. The IOMM framework's ability to integrate seamlessly with existing powerful UMMs validates its versatility and applicability across different architectures.
Ablation Studies
Ablation studies confirm the efficacy of the novel components, particularly the RQA, which improves the model's adaptability to generative tasks. Additionally, varying the mask ratio significantly impacts generation quality, with optimal sparse-to-dense learning scenarios reinforcing the model's compositional abilities.
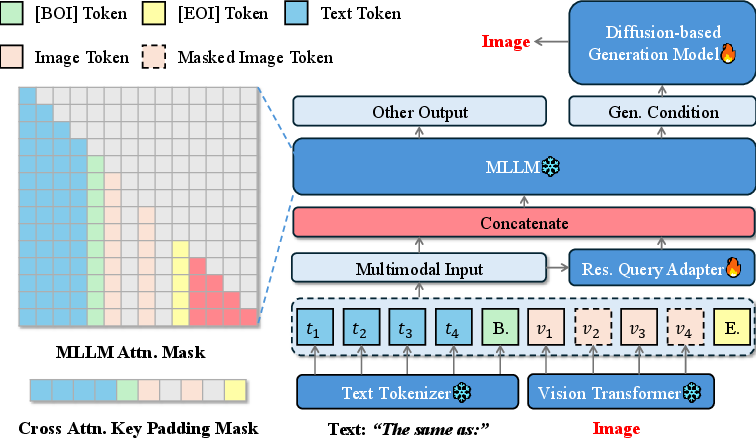
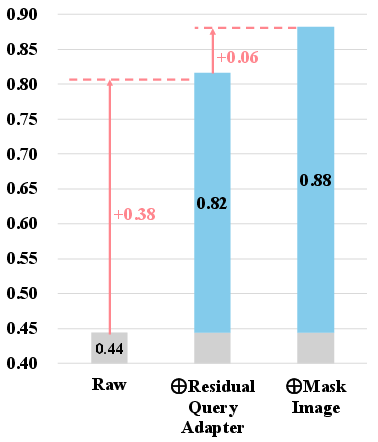
Figure 2: The architecture of our image-only pre-training stage.
Conclusion
The paper presents a pioneering paradigm that efficiently addresses the constraints of typical UMM visual generation processes. By reducing reliance on text-image pairs through innovative training methods, the IOMM framework demonstrates potential for generating high-quality images with superior instruction alignment. The demonstrated improvements in computational efficiency and model performance underscore the significance of the contributions to the ongoing advancements in UMM research.
In conclusion, the IOMM paradigm opens avenues for more efficient multimodal model training, highlighting a shift towards leveraging abundant unlabeled data without compromising on quality or alignment capabilities. Future work may focus on scaling the approach further and exploring its application to broader multimodal AI tasks.