- The paper presents a three-stage synthesis pipeline that generates high-quality multimodal datasets purely from text.
- It employs instruction-tuning and modality representation transfer to align synthetic image embeddings with textual semantics.
- Experimental results show Unicorn-8B achieving competitive vision-language performance while significantly cutting API costs and storage needs.
Unicorn: Text-Only Data Synthesis for Vision LLM Training
Vision-LLMs (VLMs) have become essential in artificial intelligence by combining visual and textual data to enhance machine learning capabilities. However, the reliance on large-scale image-text datasets poses challenges in terms of cost, quality, and storage. The paper "Unicorn: Text-Only Data Synthesis for Vision LLM Training" (2503.22655) presents a novel framework for synthesizing high-quality multimodal datasets purely from text, addressing these issues with a scalable, cost-effective approach for VLM training.
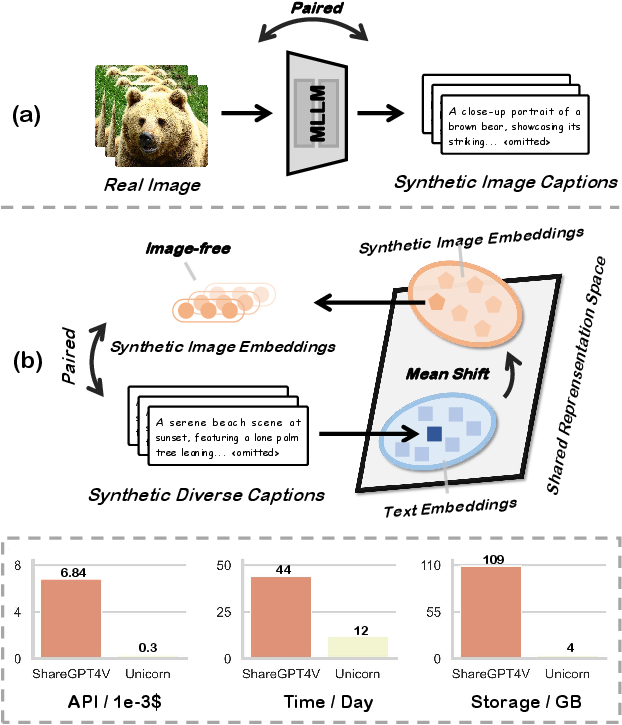
Figure 1: Unlike traditional image-text data synthesis frameworks, Unicorn removes the dependency on real image data, offering a more efficient and scalable solution by cutting down API costs, synthesis time, and storage requirements.
Data Synthesis Pipeline
The Unicorn framework integrates a three-stage multimodal data synthesis pipeline that yields two key datasets: Unicorn-1.2M, used for pretraining, and Unicorn-471K-Instruction for instruction-tuning. This process enables efficient dataset generation devoid of real image dependencies.
Stage 1: Diverse Caption Data Synthesis
The first stage involves generating semantically rich captions from caption seeds using the Qwen2.5-72B-Instruction model. This expands the sparse caption seeds to a comprehensive set of 1.2M diverse captions, ensuring high-quality text representation of visual content.
Stage 2: Instruction-Tuning Data Synthesis
In this stage, the diverse captions are transformed into instruction-tuning tasks, producing 471K samples across multiple-choice, question-answering, and complex reasoning tasks. This synthesis facilitates advanced reasoning capabilities within VLMs, entirely based on textual data.
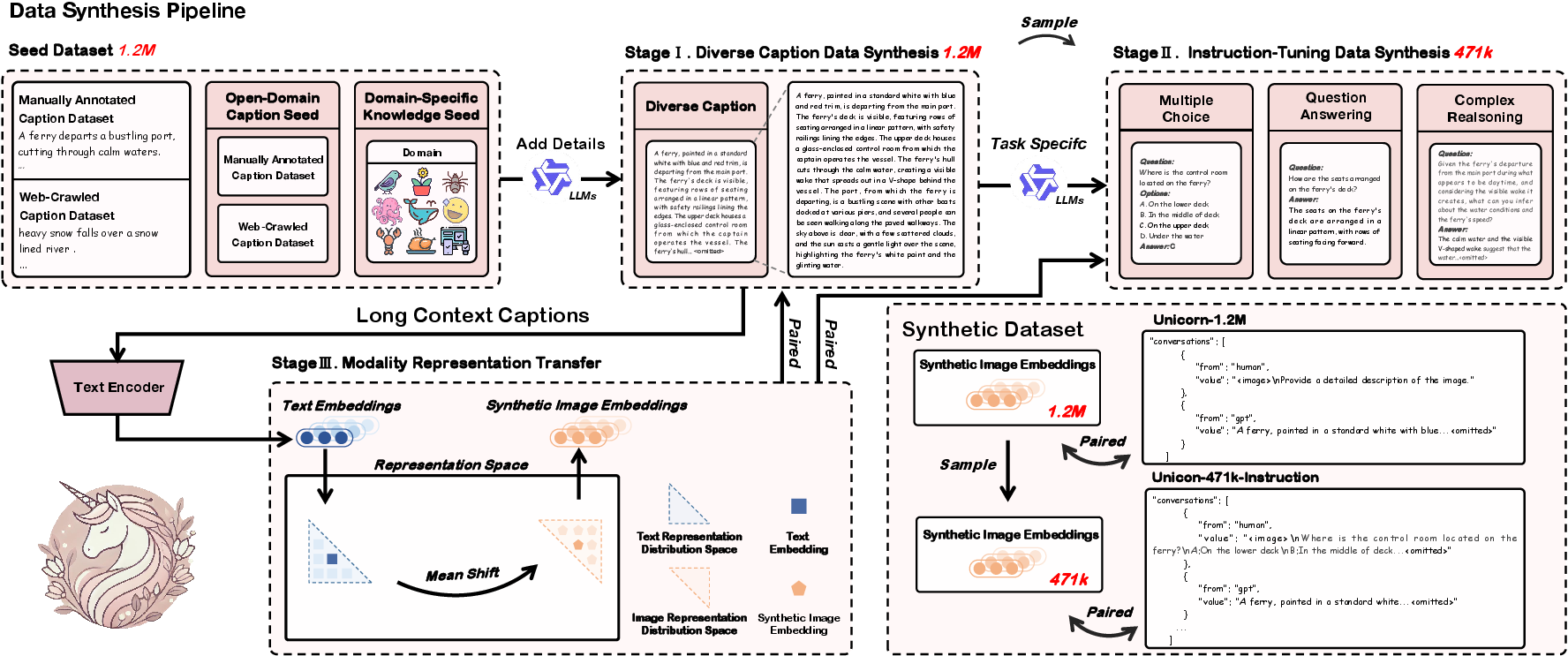
Figure 2: Unicorn's text-only data synthesis pipeline, comprising three cross-integrated stages, ultimately generating synthetic datasets entirely free of real image data.
Stage 3: Modality Representation Transfer
The final stage transcends traditional approaches by converting text representations into visual modality representations using LLM2CLIP. This method mitigates modality gaps by aligning synthetic image embeddings with textual semantic spaces, enabling effective VLM training.
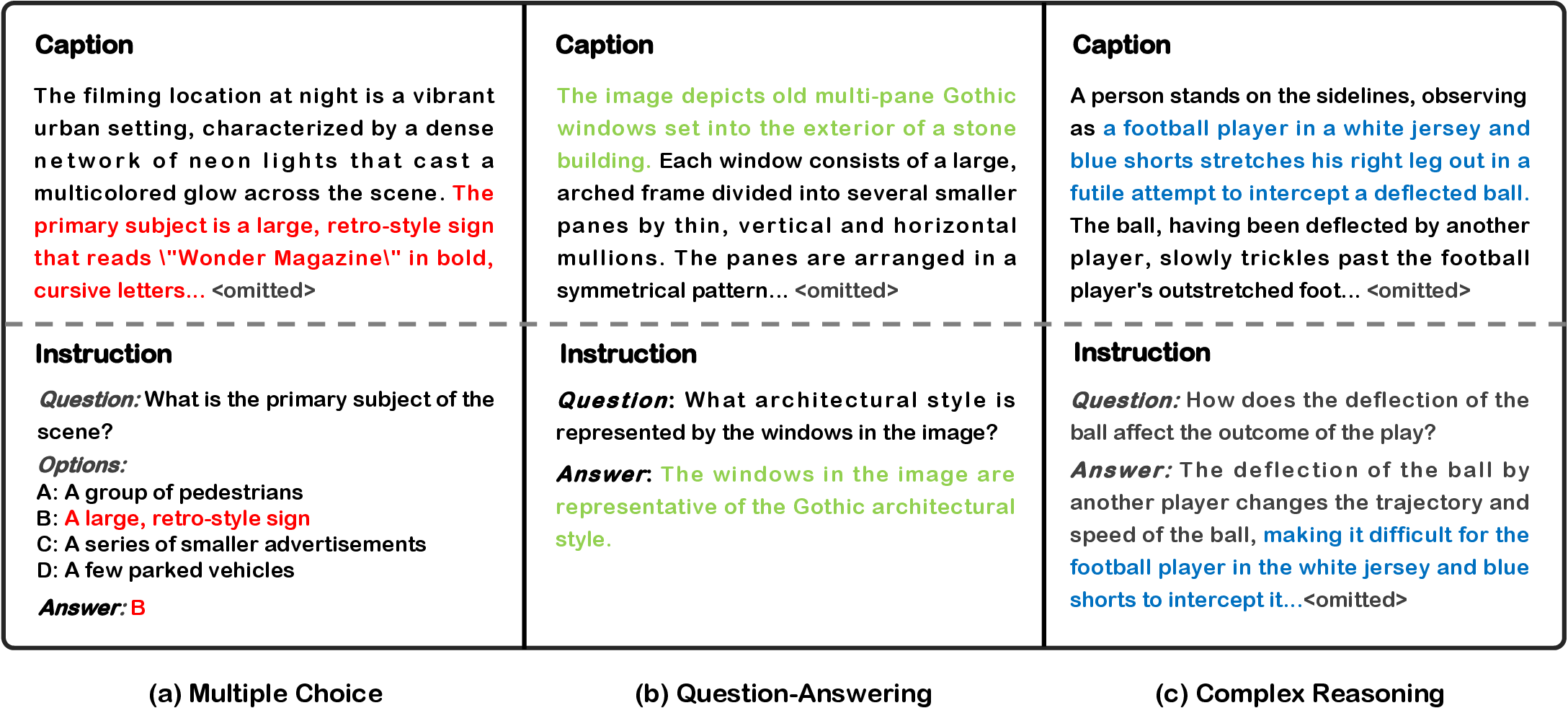
Figure 3: Data formats for the three instruction-tuning tasks.
Unicorn-8B Model
Unicorn-8B is trained using the synthetic datasets without real image data, demonstrating competitive performance across multiple benchmarks. Its architecture employs a projector and backbone LLM, facilitating seamless integration of synthetic data into training protocols.
Training and Inference
Training involves aligning synthetic image-representation embeddings with those of a pre-trained LLM, refining cross-modal alignment while freezing core model weights. The inference process uses subtractive adjustments to mitigate modality gaps.
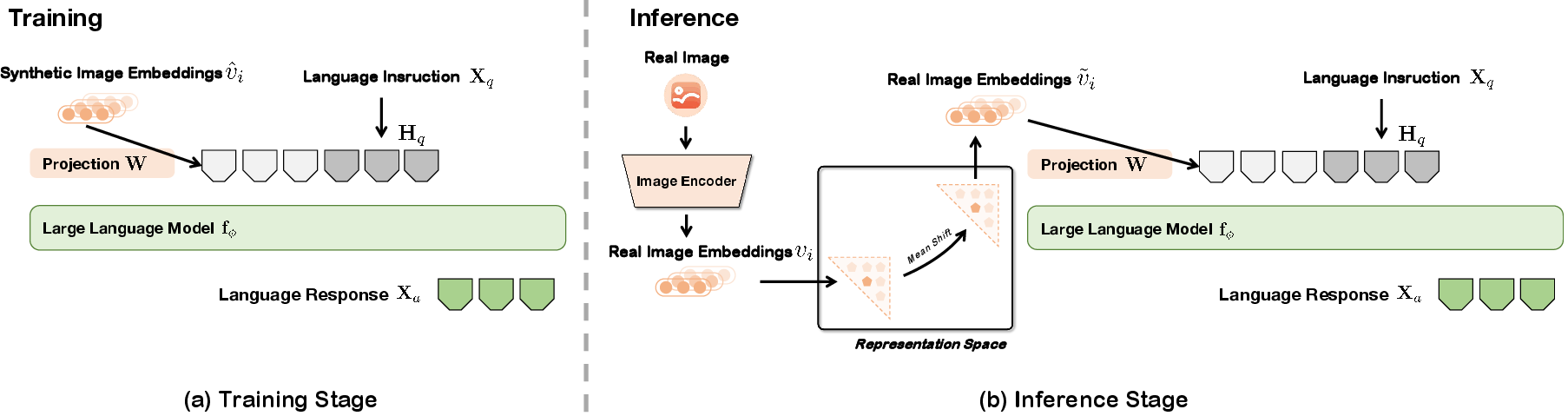
Figure 4: Training aligns synthetic image representations with LLM embeddings.
Experimental Validation
Unicorn achieves competitive results in various vision-language benchmarks, underscoring the efficacy of text-only data synthesis. The cost-effective nature of Unicorn-1.2M is highlighted by reduced API usage and storage needs compared to traditional datasets.
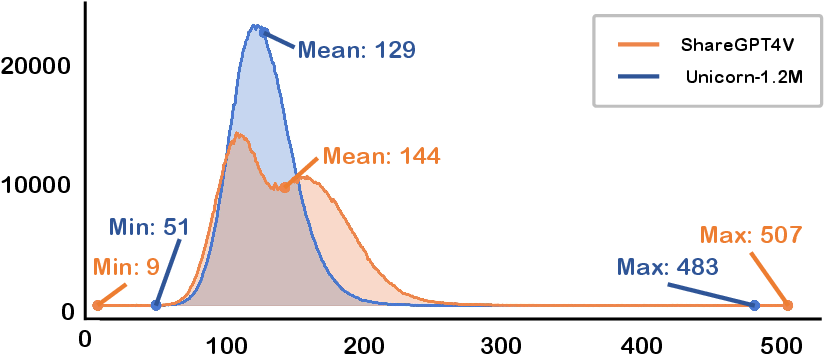
Figure 5: Comparison of the data length distributions between Unicorn-1.2M and ShareGPT4V.
Unicorn-8B’s performance across diverse benchmarks demonstrates its ability to adapt to complex multimodal tasks, matching or surpassing traditional methods reliant on costly image datasets.
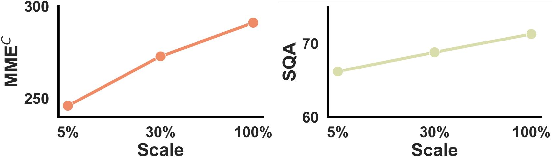
Figure 6: Performance on the MMEC and ScienceQA benchmarks across different training data scales.
Conclusion
Unicorn presents an innovative method for text-only data synthesis in VLM training, significantly reducing dependencies on image data while maintaining dataset quality and diversity. This approach paves the path for scalable and cost-effective VLM training solutions by leveraging abundant textual data.
While Unicorn demonstrates impressive potential, its limitations include challenges in addressing fine-grained visual tasks and incorporating specific domain knowledge. Future work can explore enhancing synthetic representation quality and expanding domain-specific knowledge integration.