Mixture-of-Depths Attention
Abstract: Scaling depth is a key driver for LLMs. Yet, as LLMs become deeper, they often suffer from signal degradation: informative features formed in shallow layers are gradually diluted by repeated residual updates, making them harder to recover in deeper layers. We introduce mixture-of-depths attention (MoDA), a mechanism that allows each attention head to attend to sequence KV pairs at the current layer and depth KV pairs from preceding layers. We further describe a hardware-efficient algorithm for MoDA that resolves non-contiguous memory-access patterns, achieving 97.3% of FlashAttention-2's efficiency at a sequence length of 64K. Experiments on 1.5B-parameter models demonstrate that MoDA consistently outperforms strong baselines. Notably, it improves average perplexity by 0.2 across 10 validation benchmarks and increases average performance by 2.11% on 10 downstream tasks, with a negligible 3.7% FLOPs computational overhead. We also find that combining MoDA with post-norm yields better performance than using it with pre-norm. These results suggest that MoDA is a promising primitive for depth scaling. Code is released at https://github.com/hustvl/MoDA .



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces a new way for LLMs to use information from earlier layers more effectively as they get deeper. The method is called Mixture-of-Depths Attention (MoDA). It helps prevent useful signals from getting “washed out” as the model adds more layers, and it does this while staying fast on modern hardware.
The main goal and questions
The authors ask:
- How can we make very deep LLMs keep and reuse useful information from earlier layers, instead of losing it as the data moves through many layers?
- Can we design a method that’s both effective (better accuracy) and efficient (fast and not too expensive to run) on GPUs?
How they approached it (in everyday language)
First, a quick idea of how Transformers work:
- A Transformer processes a sequence of tokens (like words). Each layer looks at tokens around a position to decide what matters using “attention.”
- Attention uses “queries” (Q), “keys” (K), and “values” (V). You can think of this like: the query is a question, keys are labels on information, and values are the actual information. The model matches questions to labels and then gathers the information.
The problem with depth:
- As you stack more layers, the model repeatedly updates its hidden state. This can cause “information dilution,” where strong, useful features found early on get faded or mixed away by later layers.
What MoDA does:
- Instead of only letting each layer look across the sequence (left-to-right in a sentence), MoDA also lets each attention head look “down the stack” into earlier layers at the same token position.
- In simple terms: each layer doesn’t just ask “which earlier words in the sentence are important?” It also asks “what did earlier layers already figure out at this spot?”
- The model then mixes both kinds of information in one go, using a single softmax (the step that turns scores into weights). This makes the choice between “sequence info” and “depth info” fair and coordinated.
How they made it fast on hardware:
- GPUs love regular, blocky math operations and hate jumping around in memory.
- Naively, looking back at all earlier layers would require messy memory access. The authors:
- Packed earlier-layer memories into a tidy layout.
- Used “chunks” of the sequence so each group of tokens only scans its relevant earlier-layer info, not everything.
- Used “group-aware” indexing (aligned with grouped-query attention) so several queries reuse the same earlier-layer blocks.
- Fused sequence- and depth-attention into one pass, sharing the same online softmax state, so there’s no extra back-and-forth.
- The result is a kernel that runs at about 97.3% of the speed of a highly optimized baseline (FlashAttention-2) when handling very long sequences (up to 64,000 tokens).
What they found and why it matters
Key results (on 700M and 1.5B parameter models trained on 400B tokens):
- Accuracy improves consistently:
- On 1.5B models, average perplexity (a measure of how “surprised” the model is—lower is better) improved by about 0.2 across 10 validation sets.
- Average performance on 10 downstream tasks improved by about 2.11%.
- Small compute cost:
- Only about 3.7% more FLOPs (a measure of computation). That’s a modest overhead for the gains achieved.
- Works well with standard training tricks:
- Combining MoDA with “post-norm” (a common way to place layer normalization) works better than with “pre-norm.”
- Better use of attention:
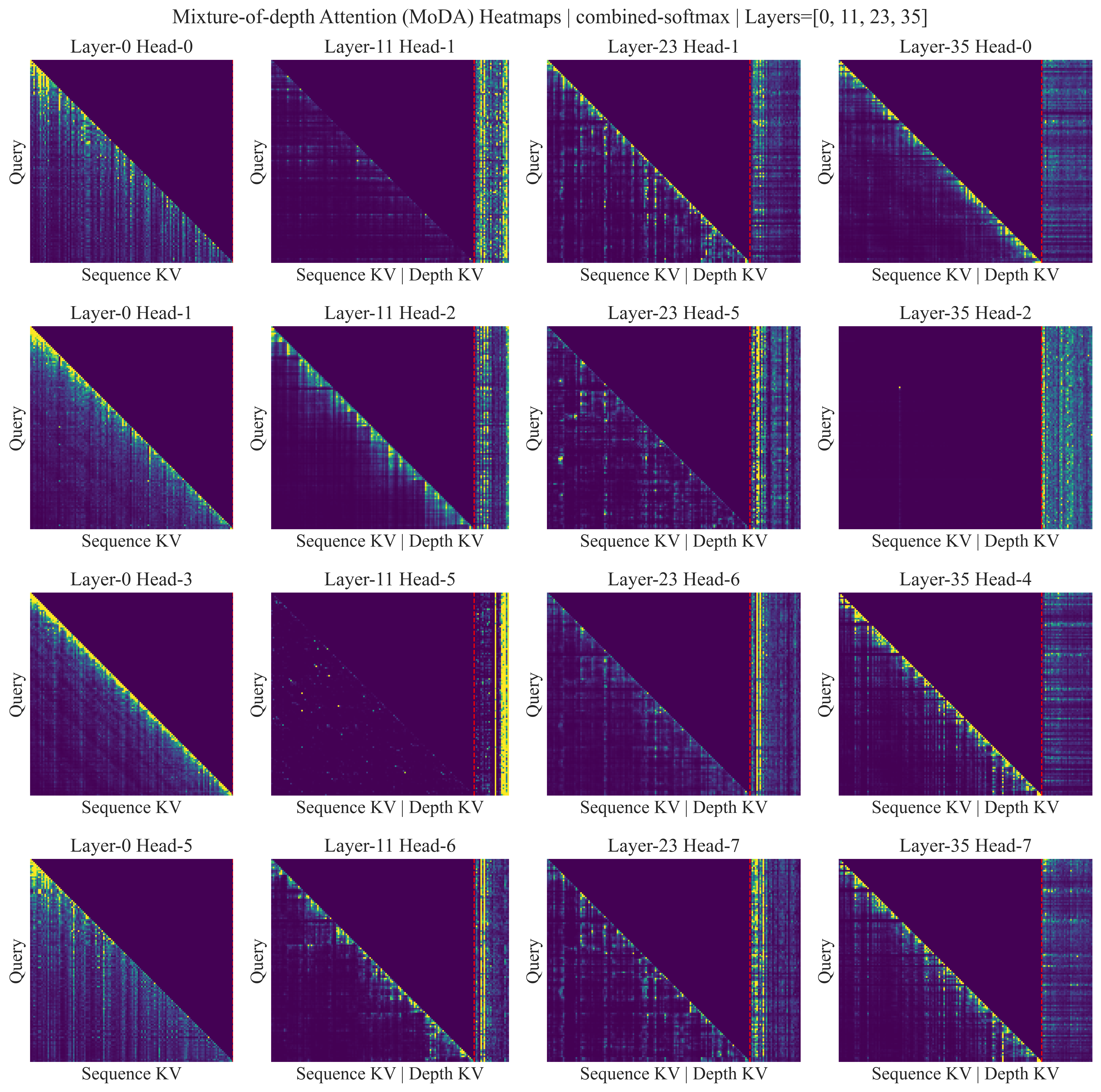
- The model reduces “attention sink” behavior (wasting attention on unhelpful tokens) by redistributing attention to useful sequence and depth signals.
- Design insights about where to add depth information:
- Reusing attention’s existing K/V projections as depth memories already helps a lot with almost no cost.
- Adding depth memories from the FFN (feed-forward) parts of each layer helps even more.
- Adding extra, separate attention K/V projections for depth gives only tiny gains but adds noticeable cost—so it’s usually not worth it.
Why this is important:
- Depth is a powerful way to make models smarter, but it’s been tricky to use well because information can get diluted.
- MoDA gives models a “memory across layers” they can actively read from, helping deeper models actually act deeper (not just bigger).
- And it achieves this without blowing up computation or breaking GPU efficiency—crucial for training and serving large models at scale.
The big picture impact
- For researchers and engineers: MoDA is a practical building block for making deeper LLMs more effective. It keeps training stable and adds useful retrieval from earlier layers with minimal extra cost.
- For real-world use: Better language understanding and reasoning at similar costs means you can get stronger models without needing dramatically more compute.
- For future models: Because MoDA unifies sequence and depth attention under one softmax, it creates a clean, efficient way to blend “what other tokens say” with “what earlier layers already learned,” opening doors for better depth scaling in next-generation LLMs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide future research:
- Scaling beyond 1.5B parameters remains untested; it is unclear whether MoDA’s gains persist or amplify at larger scales (e.g., 7B–70B+) and with substantially deeper networks (e.g., L≥128–256) in full training runs.
- The effect of MoDA on true depth scaling is not fully demonstrated; experiments do not test whether adding many more layers (at fixed or growing parameter budgets) benefits more from MoDA than baseline residual stacks.
- Generality across architectures is unknown; results are limited to decoder-only LLMs with GQA. Behavior with MHA/MQA, encoder-decoder models, multi-modal transformers, and non-causal or bidirectional attention remains unstudied.
- Interaction with positional encodings is unspecified; it is unclear how RoPE or other positional schemes are applied to depth K/V and whether alternative encodings change MoDA’s effectiveness.
- The unified softmax mixes sequence and depth scores in a single normalization; the potential competition between depth and sequence attention (e.g., depth dominating or suppressing sequence retrieval) is not characterized or mitigated (e.g., via temperature scaling, per-source gating, or separate normalizations).
- Depth attention is restricted to same-position K/V across layers; whether allowing cross-position depth retrieval (e.g., attending to earlier layers at different positions) would help or harm is unexplored.
- Layer selection over depth is exhaustive (all preceding layers); no study tests limiting to the last k layers, learned sparsity, top-k depth selection, or decay schemes to reduce O(L2 D) compute growth and improve efficiency for very deep stacks.
- Sharing strategy for depth K/V is underexplored; the paper reuses attention K/V and adds a lightweight FFN K/V projection, but does not compare alternatives (e.g., per-layer learned gates, shared or tied projections across layers, low-rank or quantized depth K/V).
- The cost and benefits of storing FFN-derived depth K/V at scale are unclear; actual memory footprint and throughput impact during training and long-context inference are not reported.
- Inference-time latency and memory usage are not benchmarked end-to-end; while microbenchmarks compare to FlashAttention-2, real autoregressive decoding performance (tokens/sec) and KV-cache memory growth for practical batch sizes and long prompts are absent.
- Portability and hardware coverage are limited; efficiency is shown on A100 with Triton kernels. Performance on H100, AMD GPUs, TPUs, or CPUs, and integration with other runtimes (FlashAttention-3, xFormers, PyTorch 2 compile, JAX, TensorRT-LLM) are unreported.
- Training stability and optimization dynamics are insufficiently analyzed; beyond noting post-norm performs better than pre-norm, the paper does not examine gradient norms, optimization pathologies, sensitivity to residual/normalization variants (e.g., DeepNet, RMSNorm variants), or the role of MoDA in mitigating vanishing/exploding gradients with extreme depth.
- Robustness to different data mixtures and domains is not established; results are tied to the OLMo2 400B-token recipe. Cross-corpus generalization (e.g., cross-lingual, code-heavy, math/logic), domain shifts, and low-resource settings are untested.
- Downstream evaluation breadth is modest; there is no assessment on strong reasoning (e.g., GSM8K, MATH), coding (e.g., HumanEval), summarization, long-context tasks, or instruction-following/alignments (SFT/RLHF), which may stress depth retrieval differently.
- Comparisons to alternative depth-preserving or cross-layer mechanisms are limited; empirical baselines do not include competitive designs such as DenseFormer variants, gated residual/Highway/DeepNet-style modifications, cross-layer attention modules, or recurrent/state-space alternatives (e.g., Mamba/Hyena).
- Theoretical understanding of “information dilution” mitigation is limited; there is no formal analysis of how unified softmax over depth and sequence preserves salient features, nor probing/diagnostic metrics beyond qualitative attention visualizations.
- Hyperparameters unique to MoDA are not systematically ablated (e.g., chunk size C, group size G in training—not just kernel runtime; head dimension, depth temperature, per-head depth–sequence mixing ratios), leaving open how to tune MoDA across regimes.
- Numerical stability and precision sensitivity are not fully characterized; the unified online softmax across sequence and depth may introduce subtle stability trade-offs under fp16/bf16, long contexts, or very deep networks.
- Memory–compute trade-offs for very long contexts are uncertain; training was at T=4096, but kernel efficiency is shown up to 64K without demonstrating end-to-end training or inference feasibility (batch sizes, activation checkpointing, gradient accumulation constraints).
- Applicability to sparse or structured attention patterns (sliding window, local-global, retrieval-augmented) is untested; how MoDA integrates with such patterns or with external memory modules remains open.
- Effects on interpretability and behavior (e.g., attention sink, head specialization) are only briefly mentioned; comprehensive analyses of where depth attention focuses, how it evolves with training, and whether it improves compositionality or factual consistency are missing.
- Potential over-reliance on shallow-layer features is not assessed; deeper layers attending heavily to early representations could impede abstraction—no diagnostics quantify this risk or propose regularizers to encourage healthy depth usage.
- Fault tolerance and training efficiency at scale are unreported; impact on distributed training (pipeline/tensor parallelism), activation checkpointing compatibility, communication overhead, and recoverability from hardware faults are not discussed.
- Open-source reproducibility scope is unclear; the paper links code but does not specify which kernels, training configs, and checkpoints are released, hindering independent validation and ablation at scale.
Practical Applications
Immediate Applications
Below are practical, deployable use cases that can adopt Mixture-of-Depths Attention (MoDA) with today’s tooling and hardware. Each item notes relevant sectors, potential tools/products/workflows, and key dependencies.
- Integrate MoDA into small- to mid-size LLM training pipelines to improve quality at low overhead
- Sectors: software/AI infrastructure, cloud ML platforms, open-source model ecosystems
- What: Replace standard attention with MoDA in 0.7B–1.5B parameter decoder-only models to reduce information dilution across layers and gain ~2% downstream task accuracy with ~3.7% FLOPs overhead (as reported).
- Tools/workflows:
- Incorporate the authors’ Triton-based MoDA kernel into PyTorch training loops.
- Enable post-norm Transformer blocks (authors report better performance with post-norm than pre-norm).
- Use GQA (grouped-query attention) to maximize depth utilization and kernel efficiency.
- Assumptions/dependencies:
- Availability of NVIDIA GPUs (e.g., A100/H100) and FlashAttention-2-style kernels; bf16 training.
- Retrofitting requires architectural changes and retraining (not a pure post-hoc patch to existing checkpoints).
- Memory overhead from depth KV caches must fit device budgets; kernel performance depends on chunk and GQA settings.
- Long-context model training and inference with near-FlashAttention-2 efficiency up to 64K tokens
- Sectors: legal and compliance (e-discovery), finance (10-K/earnings call analysis), research (literature review), enterprise knowledge management
- What: Use MoDA’s fused kernel (97.3% of FlashAttention-2 efficiency at 64K) to support long-context prefill with minimal speed loss, enabling high-throughput processing of very long documents.
- Tools/workflows:
- Swap in MoDA kernels for attention layers in long-context LLMs.
- Adjust chunk sizes and GQA groups to boost depth utilization and throughput.
- Assumptions/dependencies:
- Adequate GPU memory for longer KV caches (sequence + depth).
- Gains are demonstrated on decoding/prefill cost models; careful profiling needed for production serving.
- Domain-specific small models with better reasoning at similar cost
- Sectors: healthcare (clinical note summarization, guideline Q&A), finance (policy/compliance Q&A), education (textbook Q&A), customer support (ticket triage)
- What: Fine-tune 1B-class models with MoDA for domain tasks where modest but consistent accuracy gains reduce error rates and operational costs.
- Tools/workflows:
- Use MoDA with FFN-side depth KV projections (authors’ recommended variant) for best accuracy/efficiency trade-off.
- Apply standard domain-adaptive fine-tuning on proprietary corpora.
- Assumptions/dependencies:
- High-stakes deployments still require task-specific validation, monitoring, and guardrails.
- Some domains (e.g., non-English) may need further evaluation beyond the OLMo2 recipe.
- Software engineering assistants over large codebases
- Sectors: software/tools
- What: Improved cross-layer signal retention and long-context efficiency translate to better code navigation, summarization, and refactoring suggestions across large repositories.
- Tools/workflows:
- Integrate MoDA into code LLMs for better multi-file context handling (e.g., 32–64K context windows).
- Pair with retrieval-augmented workflows for indexing repositories.
- Assumptions/dependencies:
- Code tasks benefit from long sequences and better depth scaling; benchmark to confirm task-specific gains.
- Academic baselines and ablation studies for depth scaling
- Sectors: academia/research
- What: Use MoDA as a new baseline primitive for studying depth scaling, attention sink mitigation, and cross-layer information flow.
- Tools/workflows:
- Reproduce the paper’s 700M/1.5B settings; extend to varied norms, layer counts, and GQA group sizes.
- Analyze attention distributions and cross-layer retrieval behaviors.
- Assumptions/dependencies:
- Availability of training compute; correctness of MoDA kernels for custom setups.
- Cloud providers and MLOps: Offer MoDA-ready training/inference profiles
- Sectors: cloud/AI platforms
- What: Provide MoDA-optimized images/containers, with kernels, configs (chunk-aware and group-aware layouts), and recipes to ease adoption.
- Tools/workflows:
- Pre-built Docker images with Triton kernels; templates for JAX/PyTorch backends.
- Monitoring dashboards capturing throughput, depth utilization, and memory.
- Assumptions/dependencies:
- Kernel maintenance across CUDA/Triton versions; support for mixed precision and different GPUs.
Long-Term Applications
These opportunities require further R&D, scaling experiments, or broader ecosystem support before widespread deployment.
- Scaling MoDA to large (10B–100B+) LLMs and production-grade inference
- Sectors: foundational model providers, cloud AI
- What: Evaluate MoDA’s stability, memory overheads, and inference-time caching at very large scales; optimize kernels and caches for latency-critical serving.
- Tools/products:
- Advanced KV cache managers that handle both sequence and depth states efficiently.
- Compiler-level fusion in frameworks like Transformer Engine or cuDNN-like libraries.
- Assumptions/dependencies:
- Depth KV cache growth and memory bandwidth must be tamed (e.g., through quantization, compression, or selective depth retrieval).
- Kernel portability and stability across hardware generations.
- Multimodal and non-language Transformers with depth-aware retrieval
- Sectors: vision (ViTs/video LMs), speech, robotics (policy networks, planners)
- What: Extend MoDA’s unified softmax over sequence+depth to cross-layer retrieval in multimodal architectures (e.g., video-text) and in long-horizon control/robotics models where depth signal dilution is a bottleneck.
- Tools/products:
- MoDA-enabled ViT/video-Transformers for long videos; policy networks for planning that retrieve earlier layer states adaptively.
- Assumptions/dependencies:
- Empirical validation on multimodal datasets and real-world robotics tasks; kernel adaptations to different tensor shapes and modalities.
- Depth-efficient ultra-deep networks as a width/lightweight alternative
- Sectors: edge/on-device AI, sustainability
- What: Use MoDA to make deeper-but-narrower models competitive with wider architectures, reducing parameter growth and potentially energy use at similar quality.
- Tools/workflows:
- Co-design with reversible/post-norm layers and memory-optimized training (activation checkpointing, ZeRO).
- Automated architecture search to trade off depth, width, and GQA groups under MoDA.
- Assumptions/dependencies:
- System-level gains depend on hardware/memory constraints; measured carbon and cost savings must be validated in real deployments.
- Structured depth-memory management and compression
- Sectors: AI systems, compiler/runtime tooling
- What: Develop learned policies to store/retrieve only the most salient depth KV states (e.g., top-k layers), with quantization or sparsity for cache compression.
- Tools/products:
- Cache compression modules; attention over learnable depth indices; hardware schedulers for depth-aware caching.
- Assumptions/dependencies:
- Must preserve accuracy while cutting memory and bandwidth; requires new training objectives or regularizers.
- Standards and policy for efficient AI scaling
- Sectors: public sector, sustainability policy, procurement
- What: Encourage architectural primitives (like MoDA) that offer better quality-per-FLOP and controlled parameter growth as part of AI procurement and sustainability guidelines.
- Tools/workflows:
- Benchmarks and reporting templates for depth-aware efficiency (quality gains vs overhead, memory footprints).
- Assumptions/dependencies:
- Independent evaluations across tasks/domains to justify including such primitives in standards; policy adoption cycles.
- Education-scale long-context systems (textbook- or course-length inputs)
- Sectors: education technology
- What: Build tutoring and assessment tools that accept very long inputs (full chapters/books), relying on MoDA’s long-context efficiency for feasible training/inference.
- Tools/products:
- Course content analyzers; study-planner generation from large materials.
- Assumptions/dependencies:
- Requires model alignment and safety for educational settings; GPU resources for long-context serving; domain-specific fine-tuning.
- High-stakes domains (healthcare, legal) with rigorous validation
- Sectors: healthcare, legal
- What: Apply MoDA-enhanced models to complex, long-document tasks (e.g., EHR summarization, case analysis), leveraging improved depth retention and long-context handling.
- Tools/products:
- On-prem or VPC deployments with MoDA kernels; audit and logging around depth/sequence attention behaviors.
- Assumptions/dependencies:
- Extensive clinical/legal validation and oversight; robust privacy/security; clear documentation of model limitations.
Notes on feasibility across applications:
- The paper’s reported gains are demonstrated at 700M–1.5B parameters with OLMo2 training recipes on 400B tokens; generalization to other sizes, data distributions, and languages requires further testing.
- MoDA performs best with post-norm Transformers and GQA; results may differ with pre-norm or non-GQA settings.
- Inference-time memory overhead increases due to depth KV caches; engineering may be required for latency-critical workloads.
- Adoption depends on availability of the open-sourced MoDA code, compatibility with current CUDA/Triton versions, and maintenance across hardware generations.
Glossary
- AdamW: An Adam optimizer variant with decoupled weight decay commonly used to train large models. "AdamW~\cite{loshchilov2018decoupled} optimizer"
- attention-sink: A failure mode where attention probability collapses onto uninformative positions, reducing useful signal. "reduced attention-sink~\cite{xiao2023attnsink} behavior via better probability allocation to informative sequence and depth KV."
- bfloat16 (bf16): A 16-bit floating-point format with an 8-bit exponent that preserves FP32 dynamic range while reducing memory/compute. "All models are trained in bfloat16 (bf16) precision."
- causal attention: An attention setting that prevents positions from attending to future tokens via a triangular mask. "For causal attention, if and otherwise."
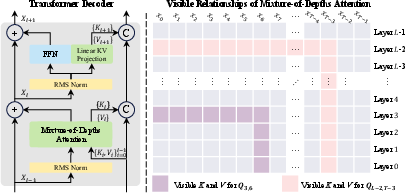
- chunk-aware MoDA: A hardware-aware layout that groups queries into chunks to localize depth-KV access and improve utilization. "Right: chunk-aware MoDA groups queries by chunk size and reorganizes depth KV by chunk, reducing the effective depth span from to per chunk, where is the GQA group number."
- decoder-only LLMs: Autoregressive Transformer models that generate tokens without an encoder, typical for LLMs. "We validate MoDA on decoder-only LLMs trained with the 400B-token OLMo2 recipe"
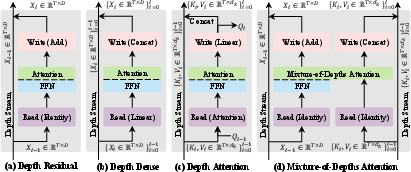
- Dense cross-layer connections: DenseNet-style links that concatenate features from all previous layers to preserve information across depth. "Dense cross-layer connections (DenseNet-style) preserve richer layer-wise history and thus mitigate information dilution"
- Depth attention: An attention mechanism that reads historical information across layers (depth) in a data-dependent way. "we propose depth attention that reads historical depth information using attention in a data-dependent way"
- Depth Dense: A depth-wise dense connectivity scheme that concatenates outputs from all preceding layers, improving information flow but with high cost. "From Table~\ref{tab:complexity}, Depth Dense is dominated by quadratic depth growth."
- Depth KV: The set of keys and values stored from preceding layers at the same token position, used for depth-wise retrieval. "the historical depth KV stream ."
- depth stream: The pathway across layers in deep networks through which representations propagate and are aggregated. "Along the depth stream, we can view a Transformer block as a three-step procedure: read, operate, and write."
- depth utilization: The fraction of computed depth-attention logits that are valid (unmasked) relative to the full computed matrix. "We define this ratio as depth utilization, i.e., if computed densely over the full matrix, the depth utilization is $\eta_{\text{depth}=\frac{T\cdot L}{T\cdot (T\cdot L)}=\frac{1}{T}$."
- Feed-forward network (FFN): The position-wise multilayer perceptron sublayer in Transformer blocks. "or the feed-forward network (FFN), denoted by ."
- Flash-compatible depth-KV layout: A flattened depth-cache memory layout that enables contiguous GPU accesses compatible with FlashAttention-style kernels. "Our first step is a flash-compatible depth-KV layout that flattens the depth cache along a single axis of length ."
- FlashAttention-2: A highly optimized attention kernel that fuses operations for speed and memory efficiency. "achieving 97.3\% of FlashAttention-2's efficiency at a sequence length of 64K."
- FLOPs: A measure of computational cost counting floating-point operations. "with a negligible 3.7\% FLOPs computational overhead."
- grouped causal mask: A causality mask aligned with GQA grouping that enforces attention only to allowed base-time indices. "and apply grouped causal mask "
- Grouped Query Attention (GQA): A technique where multiple query heads share a smaller set of key-value heads to reduce memory and compute. "Under grouped query attention (GQA)~\cite{ainslie2023gqa}, , , and :"
- HBM (High Bandwidth Memory): Off-chip GPU memory with high throughput but higher latency than on-chip memory. "HBM offers large capacity but higher access latency, whereas on-chip SRAM structures, i.e., registers, shared memory, and cache, are much faster but limited in size."
- information dilution: The phenomenon where salient features fade as layers stack due to repeated residual mixing. "address the modern LLM's information dilution problem"
- KV projection: Linear mappings that produce keys and values from hidden states for attention or caching. "we obtain its corresponding key-value pair via a light-weight KV projection."
- Mixture-of-Depths Attention (MoDA): The proposed mechanism that jointly attends over sequence and depth keys/values under a single softmax. "We introduce mixture-of-depths attention (MoDA), a mechanism that allows each attention head to attend to sequence KV pairs at the current layer and depth KV pairs from preceding layers."
- Online softmax: A streaming approach to compute softmax statistics across blocks without materializing full logits in memory. "with shared online-softmax states."
- OnlineSoftmaxUpdate: The kernel routine that updates running softmax maxima, normalizers, and outputs during fused attention. "OnlineSoftmaxUpdate(m,acc,o,S,\mathbf{V}_{[b_s]})"
- perplexity (PPL): A standard metric for LLMs indicating predictive uncertainty; lower values are better. "We further report the training perplexity (PPL), C4 validation perplexity (Val PPL)"
- post-norm: A Transformer variant that applies layer normalization after the sublayer, affecting optimization and stability. "combining MoDA with post-norm yields better performance than using it with pre-norm."
- pre-norm: A Transformer variant that applies layer normalization before the sublayer. "combining MoDA with post-norm yields better performance than using it with pre-norm."
- ResNet-style residual pathway: The additive skip-connection mechanism that stabilizes training in deep networks. "The standard residual pathway (ResNet-style) improves optimization stability in deep networks"
- sequence attention: The standard self-attention over token positions in a sequence, often with causality in autoregressive models. "Compared with vanilla causal sequence attention, MoDA additionally allows query to attend to depth memories"
- signal degradation: The weakening of informative signals across layers due to repeated residual updates. "they often suffer from signal degradation: informative features formed in shallow layers are gradually diluted by repeated residual updates"
- SRAM: Fast on-chip GPU memory (e.g., shared memory/registers) used to reduce HBM traffic during kernels. "Load from HBM to SRAM (on chip)"
- Streaming Multiprocessors (SMs): The fundamental parallel processing units of NVIDIA GPUs that schedule and execute thread blocks. "An NVIDIA GPU is composed of many SMs, which are the basic on-chip units for parallel execution and resource management."
- Tensor Cores: Specialized GPU units that accelerate matrix multiply-accumulate operations for deep learning workloads. "CUDA cores support general arithmetic instructions, while Tensor Cores provide much higher throughput for structured matrix multiply-accumulate operations."
- unified softmax operator: A single normalization over combined sequence and depth attention logits to allocate probability mass jointly. "MoDA aggregates sequence and depth information with a unified softmax operator"
Collections
Sign up for free to add this paper to one or more collections.