MHLA: Restoring Expressivity of Linear Attention via Token-Level Multi-Head
Abstract: While the Transformer architecture dominates many fields, its quadratic self-attention complexity hinders its use in large-scale applications. Linear attention offers an efficient alternative, but its direct application often degrades performance, with existing fixes typically re-introducing computational overhead through extra modules (e.g., depthwise separable convolution) that defeat the original purpose. In this work, we identify a key failure mode in these methods: global context collapse, where the model loses representational diversity. To address this, we propose Multi-Head Linear Attention (MHLA), which preserves this diversity by computing attention within divided heads along the token dimension. We prove that MHLA maintains linear complexity while recovering much of the expressive power of softmax attention, and verify its effectiveness across multiple domains, achieving a 3.6\% improvement on ImageNet classification, a 6.3\% gain on NLP, a 12.6\% improvement on image generation, and a 41\% enhancement on video generation under the same time complexity.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at a popular AI building block called “attention,” which helps computers decide what parts of a long input (like a sentence, an image, or a video) to focus on. Regular attention (used in Transformers) is powerful but slow and memory-hungry when inputs get very long. A faster version called “linear attention” fixes the speed problem but often performs worse. The authors introduce a new method, MHLA (Multi-Head Linear Attention), that keeps the speed of linear attention while bringing back much of the accuracy and “smart focus” of regular attention.
What questions did the researchers ask?
- Why does fast “linear attention” lose accuracy, especially on long inputs like high‑resolution images and videos?
- Can we redesign linear attention so it stays fast but recovers the ability to focus differently for different parts of the input (like a person paying attention to different details at different moments)?
- Will this new design work well across many tasks—image classification, text tasks, image generation, and video generation—without adding heavy, slow parts?
How did they try to solve it? (Simple explanation of the method)
First, some quick, plain-language terms:
- Token: a small piece of input (a word in a sentence, a patch of an image, a tiny chunk of a video).
- Attention: like a spotlight the model moves around to focus on the most helpful tokens.
- Self-attention: every token looks at every other token to decide what’s important. Powerful, but slow for long inputs (cost grows like “length × length”).
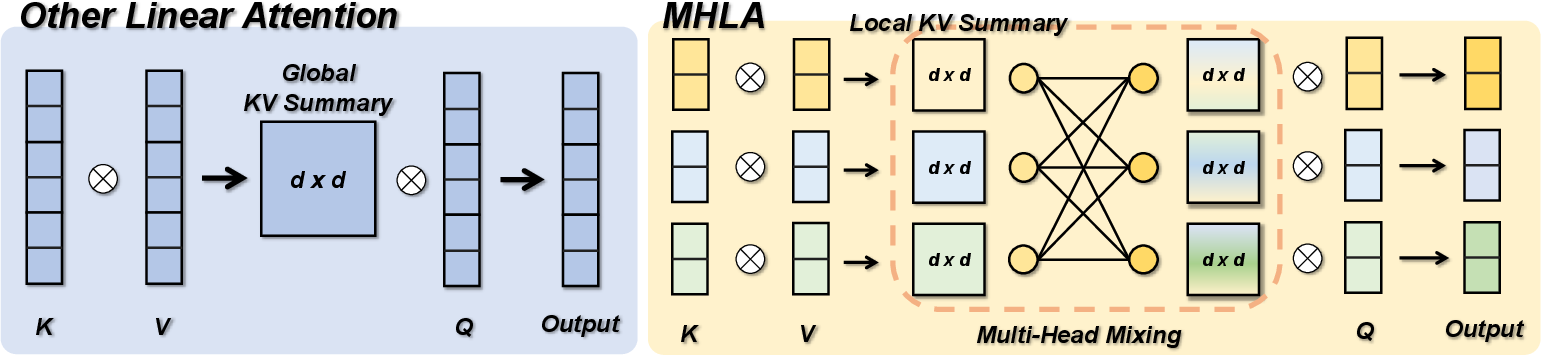
- Linear attention: a faster shortcut that summarizes all tokens into one global summary. Fast, but it tends to treat everything too similarly.
The problem the authors found:
- In linear attention, all tokens are squished into one “global summary,” which every part of the model shares. Imagine blending a smoothie from many fruits: if you only taste the smoothie, you lose the distinct flavors of each fruit. As sequences get longer, the “flavor” becomes more uniform. The authors call this “global context collapse”—the model loses diversity and can’t focus sharply on specific, relevant tokens.
Their solution (MHLA) in everyday terms:
- Instead of one giant blended summary, MHLA splits the tokens into several groups (think of them as neighborhoods).
- For each neighborhood, it makes a small local summary.
- Then, for each part of the input that’s “asking a question” (each query), the model learns how to mix these neighborhood summaries with its own set of weights—like turning dials to choose which neighborhoods matter more right now.
- Inside the selected neighborhoods, it still reweights individual tokens, so it can zoom in on specific details.
- This two-step focusing (pick neighborhoods, then pick tokens inside them) restores diversity and sharp focus, but stays fast because it avoids comparing every token with every other token.
Why it stays efficient:
- MHLA keeps the main linear-attention trick (using fast math with summaries) and adds a lightweight “mixing” step. The time grows roughly in a straight line with input length, so it works well for long sequences (like big images or long videos).
What did they find, and why does it matter?
In short: MHLA keeps the speed benefits of linear attention and brings back much of the “smart focus” of regular attention. Here’s what the authors showed:
- Across different areas, MHLA improved results while keeping the same fast time complexity as linear attention:
- Image classification (ImageNet): about +3.6% improvement.
- Natural language tasks (NLP): about +6.3% improvement.
- Image generation: about +12.6% improvement.
- Video generation: about +41% improvement (very important because videos are extremely long).
- On some large image-generation models, MHLA even matches or beats standard (slower) self-attention quality, while running much faster.
- Technical checks show why it works:
- More diversity: The “rank” (a math measure of how varied the attention patterns are) increases with MHLA, instead of being capped too low as in basic linear attention.
- Better focus: The attention becomes less uniform and more concentrated on the right tokens (lower entropy), meaning the model pays attention to fewer, more relevant places.
Why this matters:
- You get models that think more carefully (better focus) without paying the big speed and memory costs of standard attention.
- MHLA helps especially when inputs get very long (long documents, high-resolution images, long videos), where normal attention is too slow to use.
What could this change in the future?
- Faster, smarter AI: MHLA could make high-quality models run faster on big tasks—useful for real-time video tools, large image generation, and long-context language understanding.
- Lower costs: Because it scales well with input length, it can reduce computing and memory needs, making advanced models more accessible.
- Broad use: The method is simple, avoids heavy extra modules, and works across vision and language. It can also be combined with other speed-up tricks for even bigger gains.
- Better long-context handling: As AI tackles longer videos, larger images, or massive documents, methods like MHLA can keep quality high without slowing everything down.
In one sentence: MHLA is a smart redesign of linear attention that keeps it fast while bringing back the ability to focus sharply and differently across tokens—leading to better, more efficient AI across images, text, and video.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved and could guide future research.
- Content-conditioned mixing: The mixing coefficients m_i are learned per block and appear static across inputs; there is no mechanism to make block weights content-dependent at inference. How would dynamically computing m_i from queries (or local block features) affect expressivity, stability, and cost?
- Granularity of cross-block selectivity: MHLA applies the same weight to all tokens within a selected block (via m_{i,b}), with token differentiation only inside a block. Can we design low-overhead mechanisms to enable token-level reweighting across blocks (e.g., top-k token routing across blocks) without breaking linear-time behavior?
- Block partitioning strategy: The paper uses non-overlapping blocks and a locality-biased initialization, but provides no principled recipe for choosing M, block shapes, or handling boundaries. What are optimal partitioning strategies (overlapping windows, adaptive/hierarchical partitions, learned block layouts), and how do they generalize across modalities and resolutions?
- Scaling rule for M: The guideline M2 ≤ N is heuristic. What theoretical or empirical scaling laws govern the trade-off between rank/accuracy and the O(M2 d2) mixing cost, and how should M be scheduled as N, d, or model size grows?
- Memory footprint and practicality: MHLA stores M local summaries S_b ∈ R{d×d} and performs M2 d2 mixing. How does this memory and compute overhead scale in large d and large M regimes (e.g., 3D video grids), and on different hardware (A100/H100 vs consumer GPUs/TPUs/CPUs)? Provide systematic memory–throughput benchmarks and deployment guidance.
- Streaming/stateful inference details: The paper claims compatibility with chunkwise/causal execution but does not provide end-to-end KV-caching, latency, and memory results. What is the exact caching scheme for S_b, z_b, and mixed summaries in long-generation scenarios (text/video), and does MHLA maintain low-latency streaming at 16k–128k contexts?
- Normalizer omission: The normalizer z is omitted in language and video for “stability,” but the conditions and trade-offs are unclear. When is dropping normalization beneficial or harmful? Provide theoretical analysis and empirical ablations quantifying scale drift, calibration, and training stability.
- Kernel feature map choice: The method assumes a positive feature map φ(·) but does not specify or compare alternatives (e.g., Performer RFF, elu+1, softmax-backed kernels). How sensitive is MHLA to φ, and can non-positive or signed feature maps (allowing inhibitory effects) improve expressivity?
- Theoretical expressivity vs softmax: Rank bounds show improvement, but there is no formal characterization of how closely MHLA can approximate softmax attention (e.g., approximation error bounds, conditions for matching sparsity patterns). Can we provide guarantees or constructive schemes for approximating classes of attention maps?
- Learned mixing matrix behavior: The nonnegative, clipped, normalized M×M mixing matrix is initialized with locality bias. How do these constraints affect optimization and convergence (e.g., saturation, collapse, over-localization), and do regularizers (entropy, sparsity, Laplacian priors) improve generalization?
- Adaptivity across sequence length and resolution: MHLA is trained at fixed lengths (e.g., 2048 context for NLP; padded 256 for images). How robust is performance when inference lengths/resolutions differ from training, and does M need to change accordingly (dynamic-M strategies)?
- Cross-attention and encoder–decoder use: The paper evaluates self-attention replacements only. How should MHLA be applied to cross-attention (keys/values from a different sequence), multi-modal fusion (text–image/video), and retrieval-augmented settings?
- Boundary effects and positional bias: Non-overlapping blocks may introduce artifacts at block borders. Do overlapping blocks, learned boundary blending, or position-aware mixing (e.g., relative position kernels) reduce edge artifacts, especially in high-res vision and video?
- Finer-grained hierarchical mixing: A single level of block mixing may be insufficient for ultra-long sequences. Can multi-scale/hierarchical MHLA (coarse→fine block mixtures) further raise rank/sparsity with limited overhead?
- Comprehensive fairness in comparisons: Several baselines differ in training budgets and regimes (from-scratch vs fine-tuning, added modules like CPE/gating). Provide standardized, controlled comparisons across domains (same data/steps/compute) to isolate MHLA’s contribution.
- Robustness and distribution shift: The paper does not evaluate robustness under noise, occlusion, domain shift, or adversarial perturbations. How does MHLA’s blockwise inductive bias affect robustness compared to softmax/sparse/state-space models?
- Interplay with orthogonal accelerations: The claim that MHLA “can be combined with orthogonal techniques” is not empirically validated. What are the synergies/conflicts with FlashAttention, block-sparse patterns, kernel fusion, quantization, low-rank S_b, or state-space layers (e.g., Mamba/S4 hybrids)?
- Token/channel multi-head compatibility: MHLA splits along the token dimension; how does it interact with traditional multi-head along the channel dimension? Are there benefits to jointly using channel-wise heads and token-wise MHLA heads, and what are efficient fusion strategies?
- Parameter and regularization budgeting: The size of M_c (M×M) and any per-block parameters are not fully quantified. What is the parameter overhead across scales, and do techniques like weight tying, low-rank parameterization, or sparsifying M_c help?
- Task coverage gaps: Beyond classification/generation and LongBench, evaluate tasks requiring fine-grained alignment and selective focus (retrieval QA, program synthesis/debugging, math reasoning, dense detection/segmentation) to probe MHLA’s cross-block token selectivity limits.
- Choice of distance metric for initialization: Euclidean distance on grids is used for locality bias. In non-spatial sequences (text) or irregular layouts (graphs), what alternative metrics (graph distances, learned embeddings, semantic proximity) improve initialization and outcomes?
- Failure modes at extreme scales: In ultra-long sequences (e.g., 100k+ tokens or 4K–8K video), does the O(M2 d2) term or storage of S_b become bottlenecks? Identify regimes where MHLA breaks down and propose mitigations (e.g., sparse M_c, low-rank/quantized S_b, top-k block mixing).
- Empirical analysis of entropy and rank: Reported improvements in entropy and rank are shown for specific settings (e.g., DeiT-T). Provide broader analyses across more models, training stages, and modalities, and disentangle the contributions of M, φ, and initialization to these metrics.
Practical Applications
Immediate Applications
The following applications can be deployed now using the authors’ open-source implementation (GitHub/Hugging Face) and standard deep learning stacks (PyTorch, CUDA/Tensor Cores), as MHLA is a drop-in attention module relying on GEMMs and compatible with chunkwise/streaming execution.
- Faster, higher-quality image generation in production diffusion pipelines
- Sectors: Media/entertainment, advertising, gaming, e-commerce, design tooling (software).
- Tools/products/workflows: Replace self-attention or vanilla linear attention in DiT/DiG/Sana-based pipelines with MHLA to double throughput at 512px (vs self-attn) and improve FID at equal or lower latency; integrate into inference servers (e.g., Hugging Face Diffusers backends) for batch/interactive generation; enable higher resolution or more steps within the same latency budget.
- Assumptions/dependencies: Choose token-head count M so M2 ≤ N; rely on efficient GEMM kernels (Tensor Cores) for maximum speed; confirm license compatibility for commercial use; minor hyperparameter tuning (e.g., mixing init, gating optional).
- Long-sequence video generation with linear-time scaling
- Sectors: Film/VFX previsualization, marketing, synthetic data generation for autonomy, social media content.
- Tools/products/workflows: Replace FlashAttention or vanilla linear attention with MHLA in video diffusion models (e.g., Wan-like, SVD-type architectures) to achieve ~2× speedups vs quadratic attention and avoid linear-attention collapse at very long sequences; deploy hybrid stacks (partial MHLA layers) to optimize quality-latency trade-offs.
- Assumptions/dependencies: Spatiotemporal block partitioning must match tokenization; ensure stable mixing coefficient training (locality-biased init, nonnegativity/normalization); validate content safety and moderation pipelines due to higher throughput.
- Higher-accuracy, lower-cost vision backbones for classification and downstream tasks
- Sectors: Retail (product recognition), manufacturing/quality control, autonomous systems, mobile/embedded vision, scientific imaging.
- Tools/products/workflows: Swap attention in DeiT/VLT-like backbones with MHLA to improve ImageNet accuracy at similar FLOPs; propagate gains to detection/segmentation (via backbone finetuning); publish MHLA variants in model zoos (timm/torchvision).
- Assumptions/dependencies: Maintain typical training schedules; adjust spatial block layout for non-224 inputs (padding to 256 was used by authors for head partitioning).
- Long-context document QA, summarization, and code understanding in enterprise workflows
- Sectors: Legal, finance, consulting, compliance, developer tooling.
- Tools/products/workflows: Integrate MHLA into small/medium LMs to improve LongBench-style tasks (multi-doc QA, summarization, code) with linear memory/time scaling; deploy longer contexts (e.g., 16k–64k) for contract analysis, due diligence, repo-level code assistants, and meeting minutes summarization.
- Assumptions/dependencies: In text, partition tokens 1D by chunks; tune M and chunk size for latency/quality; combine with retrieval and masking where appropriate; evaluate on domain-specific corpora.
- Cost and energy reduction in model training and serving
- Sectors: Cloud providers, AI platform teams (FinOps), sustainability/ESG reporting.
- Tools/products/workflows: Replace quadratic attention in long-sequence workloads to reduce GPU-hours and memory pressure; scale input lengths without quadratic blow-up; report reduced energy per sample/step for sustainability KPIs.
- Assumptions/dependencies: Realized savings depend on sequence length and kernel efficiency; track M2 overhead and memory footprint for KV summaries.
- Real-time or near-real-time multimodal applications with streaming/stateful execution
- Sectors: Live content creation, interactive media, streaming analytics.
- Tools/products/workflows: Use MHLA’s compatibility with chunkwise/causal execution to enable low-latency incremental generation (e.g., progressive video frames or sliding-window vision tasks); deploy stateful inference for continuous inputs.
- Assumptions/dependencies: Stable training for causal setups (normalizer term may be omitted at very long contexts as noted by the authors); engineering for streaming buffers.
- Scientific sequence modeling under long contexts
- Sectors: Bioinformatics (genomics/proteomics), materials, astrophysics, climate modeling.
- Tools/products/workflows: Replace quadratic attention in transformer-based sequence models to extend context windows (e.g., full-genome windows) with linear compute; use block partitioning aligned to biological or structural segments.
- Assumptions/dependencies: Domain validation required; careful selection of block granularity to reflect domain structure; potential integration with sparse priors.
- Multimodal vision-language systems with larger token budgets
- Sectors: Assistive AI, enterprise search/analytics, education.
- Tools/products/workflows: Apply MHLA to encoders handling many image patches/frames or long OCR tokens, improving context selectivity and throughput; support multi-page document reasoning with dense visual tokens.
- Assumptions/dependencies: Tokenization and block assignment across modalities must be consistent; may combine with cross-attention patterns or routing layers.
Long-Term Applications
These opportunities are feasible but likely require further scaling, engineering, or research (e.g., better kernels, training recipes, safety/evaluation work).
- Frontier-scale video foundation models with minute-long memory
- Sectors: Creative suites, broadcasting, simulation for robotics/autonomy.
- Tools/products/workflows: Train models to condition on thousands of frames (long stories, multi-shot continuity) using MHLA’s linear scaling; enable coherent long-form generation and editing workflows.
- Assumptions/dependencies: Robust kernels for very large M and N; curriculum training for ultra-long contexts; content safety and watermarking.
- World-models for robotics with continuous perception streams
- Sectors: Robotics, logistics, industrial automation, AR/VR.
- Tools/products/workflows: Replace attention in perception/planning modules to maintain long temporal histories; support closed-loop, on-robot inference with improved latency and memory footprint.
- Assumptions/dependencies: Real-time constraints on embedded accelerators; task-specific validation; safety and reliability requirements.
- Million-token LLM contexts via hierarchical/chunked MHLA
- Sectors: Enterprise knowledge management, legal discovery, scientific literature assistants.
- Tools/products/workflows: Combine MHLA with hierarchical chunking, retrieval, and routing to approach 105–106 token contexts; enable whole-repository/codebase, multi-book, or multi-year log analysis in a single pass.
- Assumptions/dependencies: Careful design so M2 overhead remains subdominant; hierarchical summaries and learned mixing across levels; strong evaluation for faithfulness and recall.
- Privacy-preserving on-device generative and assistant models
- Sectors: Mobile, wearables, automotive, healthcare, smart home.
- Tools/products/workflows: Use MHLA’s memory efficiency to host larger contexts on-device for private document summarization, photo/video editing, and copilots; local-first experiences with minimal cloud calls.
- Assumptions/dependencies: Further kernel optimization for mobile NPUs; quantization/distillation; thermal/power constraints.
- Standardized, fused kernels and compiler support across ecosystems
- Sectors: AI infrastructure, semiconductor, frameworks (PyTorch/JAX/ONNX).
- Tools/products/workflows: Develop FlashAttention-like fused kernels for MHLA (block summaries + mixing + outputs), Triton/CUTLASS implementations, ONNX ops, and graph-level schedulers exploiting GEMM tiling and locality.
- Assumptions/dependencies: Vendor support (NVIDIA/AMD/Intel/Apple); ABI stability; autotuning for various tensor shapes and M.
- Energy-aware AI policy and procurement guidelines
- Sectors: Public policy, sustainability offices, cloud procurement.
- Tools/products/workflows: Encourage linear-complexity attention mechanisms (like MHLA) in public RFPs for long-sequence AI workloads; certify/benchmark models on energy per token/frame; incorporate “green attention” standards.
- Assumptions/dependencies: Transparent reporting, standardized long-context benchmarks, third-party audits.
- Domain-specialized MHLA variants and curricula
- Sectors: Healthcare (medical imaging/video), geospatial (remote sensing), finance (long time-series).
- Tools/products/workflows: Tailor block partitioning and mixing priors to domain geometry (e.g., anatomical regions, geotiles, market sessions); develop training curricula for sparse, high-resolution, or irregular sampling.
- Assumptions/dependencies: Regulatory constraints (esp. healthcare); rigorous validation; domain-specific data availability.
- Rich multimodal assistants for education and enterprise
- Sectors: Education, HR/L&D, enterprise productivity.
- Tools/products/workflows: Assistants that read entire textbooks, long lecture videos, or multi-day project logs, enabling detailed study guides, feedback, and knowledge synthesis.
- Assumptions/dependencies: Alignment and safety; evaluation of long-context comprehension; IP and content-licensing considerations.
- Hybrid attention stacks for optimal quality-latency budgets
- Sectors: Production ML platforms serving heterogeneous SLAs.
- Tools/products/workflows: Architectures mixing MHLA and softmax attention across layers/stages to meet strict latency while preserving peak quality; autoML policies to select replacement ratio by workload.
- Assumptions/dependencies: Scheduling/orchestration support; monitoring of quality drift; robust A/B testing at scale.
- Security analytics over ultra-long logs and traces
- Sectors: Cybersecurity, SRE/observability.
- Tools/products/workflows: Apply MHLA-based sequence models to months of logs/telemetry, enabling long-horizon anomaly detection and root-cause analysis without prohibitive quadratic costs.
- Assumptions/dependencies: Data privacy, stream processing integration, alerting and interpretability requirements.
Notes on feasibility across applications
- Dependencies that strongly impact outcomes: the choice of token-block partitioning, head count M (keeping M2 ≤ N), kernel efficiency (GEMM/Tensor Cores), and stable training (locality-biased initialization, coefficient clipping, optional normalizer removal in very long sequences).
- Interoperability: MHLA is compatible with chunkwise/causal/streaming execution and can be combined with orthogonal techniques (positional encodings like CPE, output gating, retrieval, sparsity).
- Risk/safety: Faster, higher-throughput generative models require strengthened safeguards (curation, watermarking, moderation) before broad deployment.
Glossary
- Associative feature maps: Feature mappings used to approximate softmax attention with kernel methods, enabling linear-time attention via associative properties. "replace the softmax kernel with associative feature maps."
- Autoregressive modeling: Sequence modeling paradigm where each token is predicted conditioned on previous tokens, typically used in language modeling. "To evaluate MHLA under autoregressive modeling, we test its performance in language modeling."
- Causal masking: A masking scheme that prevents attention to future tokens to preserve temporal causality in sequence models. "maintain linear-time complexity under causal masking"
- Chunkwise linear attention: Executing linear attention in contiguous blocks (“chunks”) to enable efficient training/inference under causality constraints. "the overall complexity remains identical to chunkwise linear attention."
- Classifier-free guidance (CFG): A diffusion-model sampling technique that combines conditional and unconditional predictions to guide generation quality. "without classifier-free guidance (CFG)"
- CLIP score: A metric measuring text–image alignment using CLIP embeddings; higher indicates better semantic consistency. "CLIP "
- Conditional Positional Encoding (CPE): A positional encoding mechanism (often implemented with depthwise convolution) used to inject spatial bias into Transformer layers. "We try extra CPE~\citep{cpe} and the output gating module~\citep{yang2024gatedlinearattentiontransformers}."
- Cosine learning rate schedule: A learning-rate policy that decays following a cosine curve, often improving training stability. "using a cosine learning rate schedule (max LR 3e-4)"
- Depthwise separable convolution: A convolutional layer decomposed into depthwise and pointwise steps to reduce computation while preserving spatial processing. "through extra modules (e.g., depthwise separable convolution)"
- DeiT: Data-efficient Image Transformer; a vision Transformer architecture optimized for image classification. "DeiT~\citep{deit}"
- DiG: A diffusion-model variant leveraging Gated Linear Attention for image generation. "DiG~\citep{Zhu_2025_CVPR}"
- DiT: Diffusion Transformer; a Transformer-based architecture for diffusion image generation. "DiT~\citep{peebles2023scalable}"
- DWConv (Depthwise Convolution): A convolution that applies a single spatial filter per input channel, commonly used for efficient positional encoding. "DWConv (CPE)~\citep{rala}"
- FlashAttention: An optimized attention algorithm that improves speed and memory efficiency via IO-aware kernels. "replacing its FlashAttention modules with MHLA."
- Fréchet Inception Distance (FID): A metric assessing generative image quality by comparing feature distributions of real and generated images. "we report the FID in the table at a resolution of ."
- Gated DeltaNet (GDN): A gated recurrent/state-space model used as a strong linear baseline in language modeling. "GDN (360M)"
- Gated Linear Attention (GLA): A linear attention variant augmented with gating mechanisms to improve expressivity. "GLA~\citep{yang2024gatedlinearattentiontransformers}"
- GEMM: General Matrix–Matrix multiplication; a standard high-performance primitive used to implement attention efficiently. "implementation only relies on standard GEMMs"
- GenEval: A benchmark suite evaluating text-to-image generation with compositional and semantic metrics. "GenEval "
- Global context collapse: A failure mode where compressing all keys/values into a single global summary reduces representational diversity. "global context collapse, where the model loses representational diversity."
- Kernelized formulation: Rewriting attention using kernel feature maps to enable linear complexity computations. "For efficiency, we adopt a kernelized formulation"
- Key–Value summary (KV summary): An aggregated representation of keys and values shared across queries in linear attention. "global key–value summary (KV summary)"
- LongBench: A benchmark evaluating long-context understanding across diverse tasks. "we evalute the models performance on LongBench~\citep{bai2024longbench}."
- Mamba: A state-space sequence model providing efficient long-context processing, used as a baseline. "Mamba (390M)"
- Mamba2: An improved Mamba variant with stronger performance on long-context tasks. "Mamba2 (340M)"
- MHLA (Multi-Head Linear Attention): The proposed linear attention method that partitions tokens into heads and mixes local summaries to restore query-dependent diversity. "Multi-Head Linear Attention (MHLA)"
- Multi-Head Mixing: A learned mixture over local key–value summaries per query-block to recover token-level selectivity. "Through Multi-Head Mixing, MHLA restores query-conditioned selectivity"
- Perplexity (ppl): A language modeling metric indicating how well a model predicts a sequence; lower is better. "ppl "
- Sana: An efficient high-resolution diffusion Transformer for text-to-image generation. "SANA*~\citep{xie2024sanaefficienthighresolutionimage}"
- Softmax attention: Standard attention mechanism that computes query-specific distributions via the softmax of dot products. "recovering much of the expressive power of softmax attention"
- Streaming/stateful execution: Incremental processing that maintains running state to handle long sequences efficiently. "retaining compatibility with streaming/stateful execution."
- VBench: A comprehensive benchmark for video generation quality and semantics. "We evaluate all models on VBench"
Collections
Sign up for free to add this paper to one or more collections.