- The paper demonstrates that, despite increased model depth, only a small core of layers substantially contributes new features.
- It employs methods such as residual cosine similarity, logit lens, and layer skipping to quantitatively analyze layer contributions.
- Findings suggest that many layers perform redundant computations, highlighting potential for efficiency improvements via architectural innovations.
Effective Depth Utilization in LLMs: An Empirical Examination
Introduction
Effective utilization of architectural depth in LLMs has critical implications for both interpretability and future model design. Recent work has questioned whether the increased depth resulting from scaling Transformer-based LLMs yields a proportional increase in compositional, hierarchical computation per token. The investigated paper examines the operational depth utilized by models across scales, training regimes, and task difficulty, emphasizing systematic empirical analysis of the Qwen-2.5 family and related long-CoT variants. This essay presents the main findings, numerical results, and their implications for model design and research.
Methodology and Probing Framework
To assess effective depth, the authors leverage and extend a set of qualitative and quantitative probes. Notably:
- Residual Cosine Similarity quantifies orthogonality of sublayer outputs to the residual stream, marking transitions between feature erasure, creation, and amplification.
- Logit Lens methods (KL divergence and top-5 token overlap) track the stabilization of intermediate output distributions toward the final prediction.
- Layer Skipping interventions analyze the downstream influence of selectively removing computation at specific layers.
- Residual Erasure and Integrated Gradients attribute per-layer contributions to target predictions.
These probes are systematically applied to a range of Qwen-2.5 variants (1.5B–32B parameters, including math-specialized and instruction-tuned models), as well as their DeepSeek-R1-Distill long-CoT counterparts. Tasks spanning the natural language understanding and mathematical reasoning spectrum (HellaSwag, GSM8K, AIME24) are considered.
Model Scale and Depth Utilization
A primary result is that, although the absolute number of effective layers (i.e., those substantially contributing new features) increases with model size, the ratio of effective depth to total depth remains stable across all model scales. This is evident in the residual cosine similarity analysis: for all model sizes, early layers integrate context, a mid-section exhibits feature erasure, and a phase transition toward feature refinement occurs in the latter half.
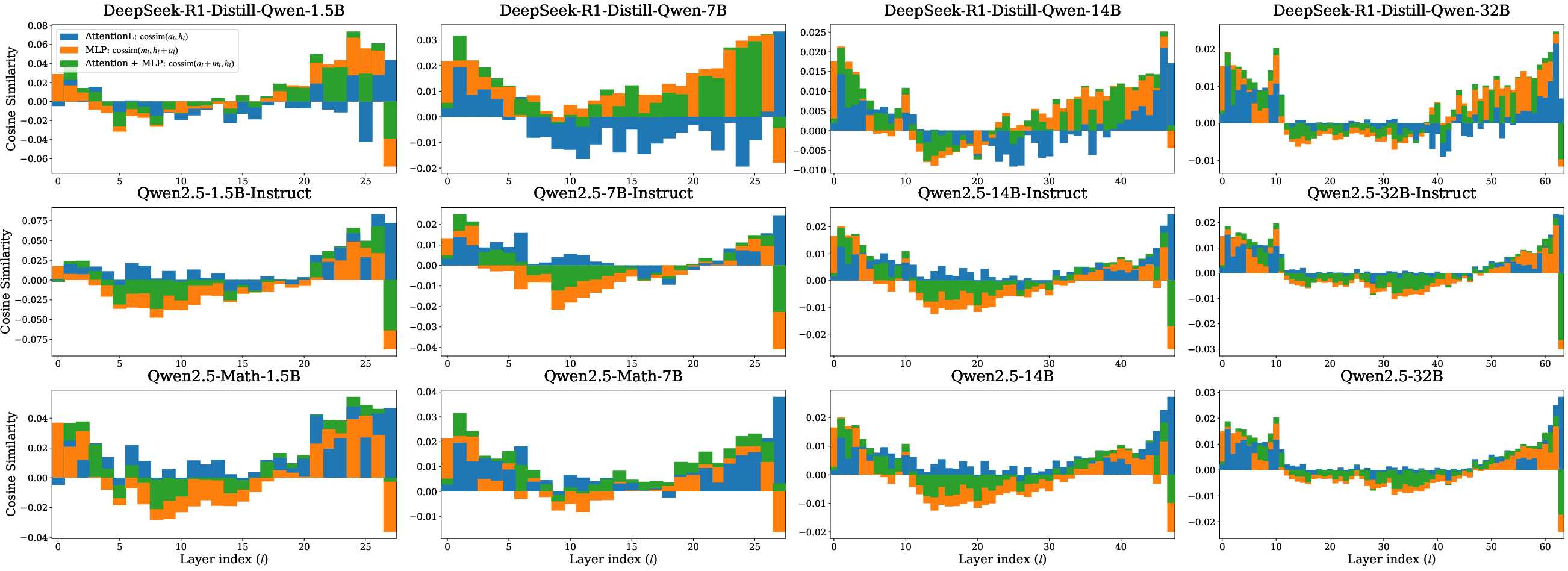
Figure 1: Cosine similarity of (sub)layer contributions and the residual evaluated on GSM8K.
Transition points, computed across models using both cosine similarity and logit lens tests, consistently indicate that a significant fraction of layers in deeper models function redundantly, primarily performing minor refinements rather than novel feature composition. This finding highlights the diminishing returns of increasing model depth in contemporary LLM architectures.
Logit Lens and Distributional Analysis
Logit lens analyses align with the above, showing that early layer outputs are distributionally distant from the final output, but there is a sharp convergence in later layers. The inflection point, signified by a rapid drop in KL divergence and corresponding rise in token overlap, marks the boundary between computation and decisional refinement.
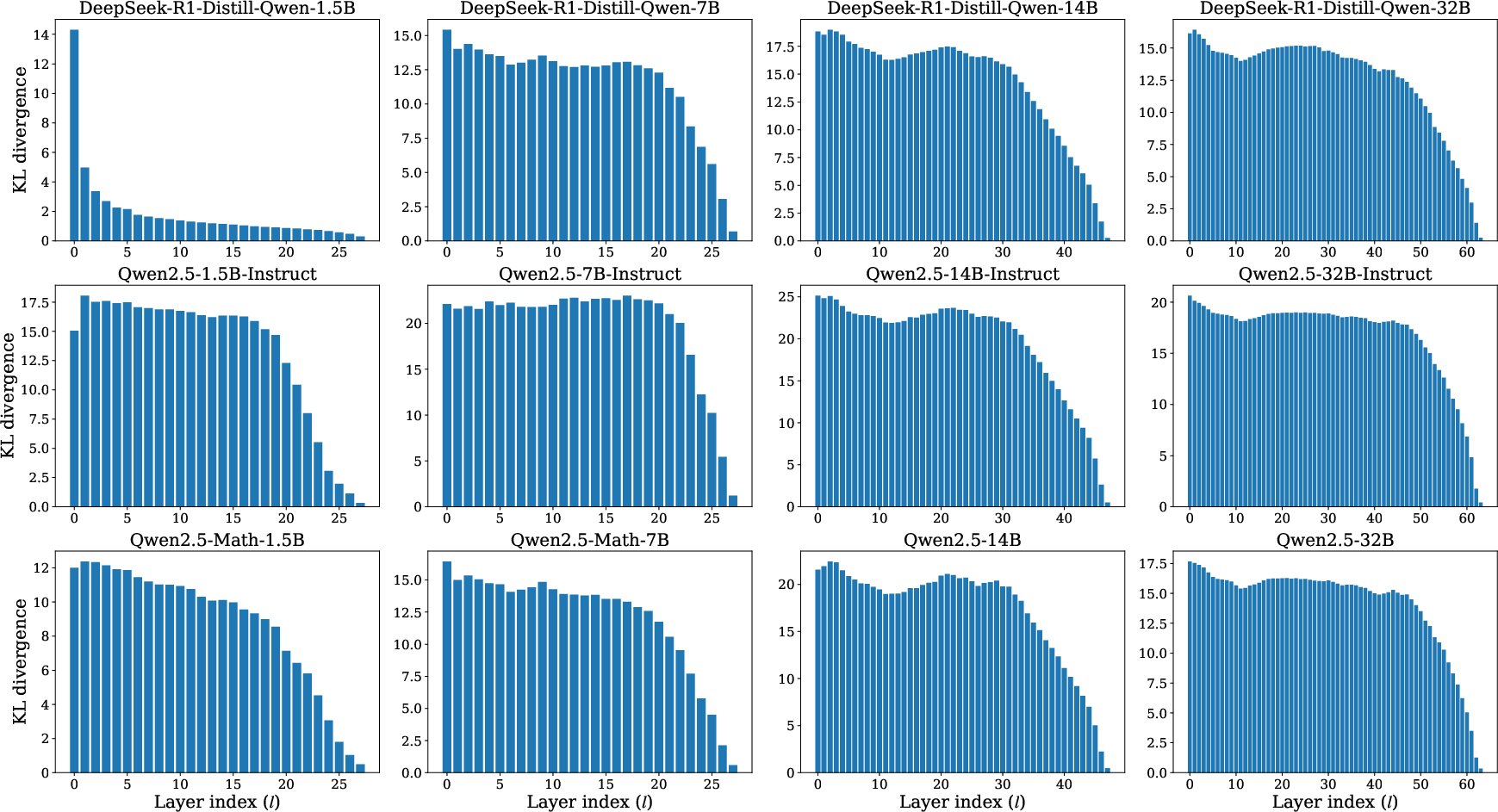
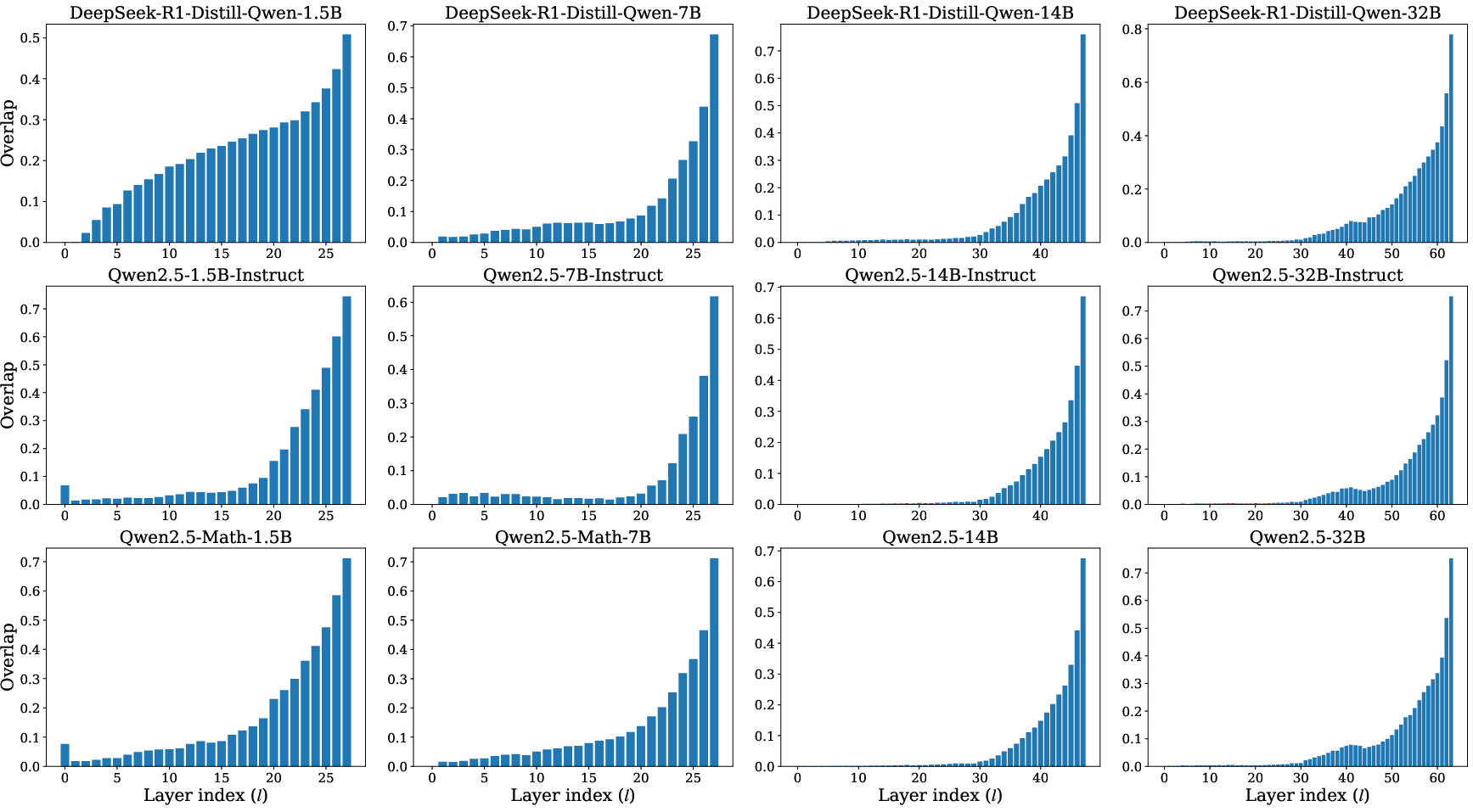
Figure 2: Logit lens results on GSM8K.
KL divergence and top-5 overlap metrics further substantiate the claim that effective depth does not scale with total depth—most nontrivial computation is concentrated in the initial and central network segments irrespective of total layer count.
Downstream Effects of Layer Skipping
Layer skipping experiments demonstrate that eliminating a layer in the first half has substantial impact on downstream computation and output, whereas later layers can often be bypassed with minimal effect. This suggests that sequential dependencies crucial for prediction are encoded early and consolidated, with late layers predominantly delivering slight adjustments.
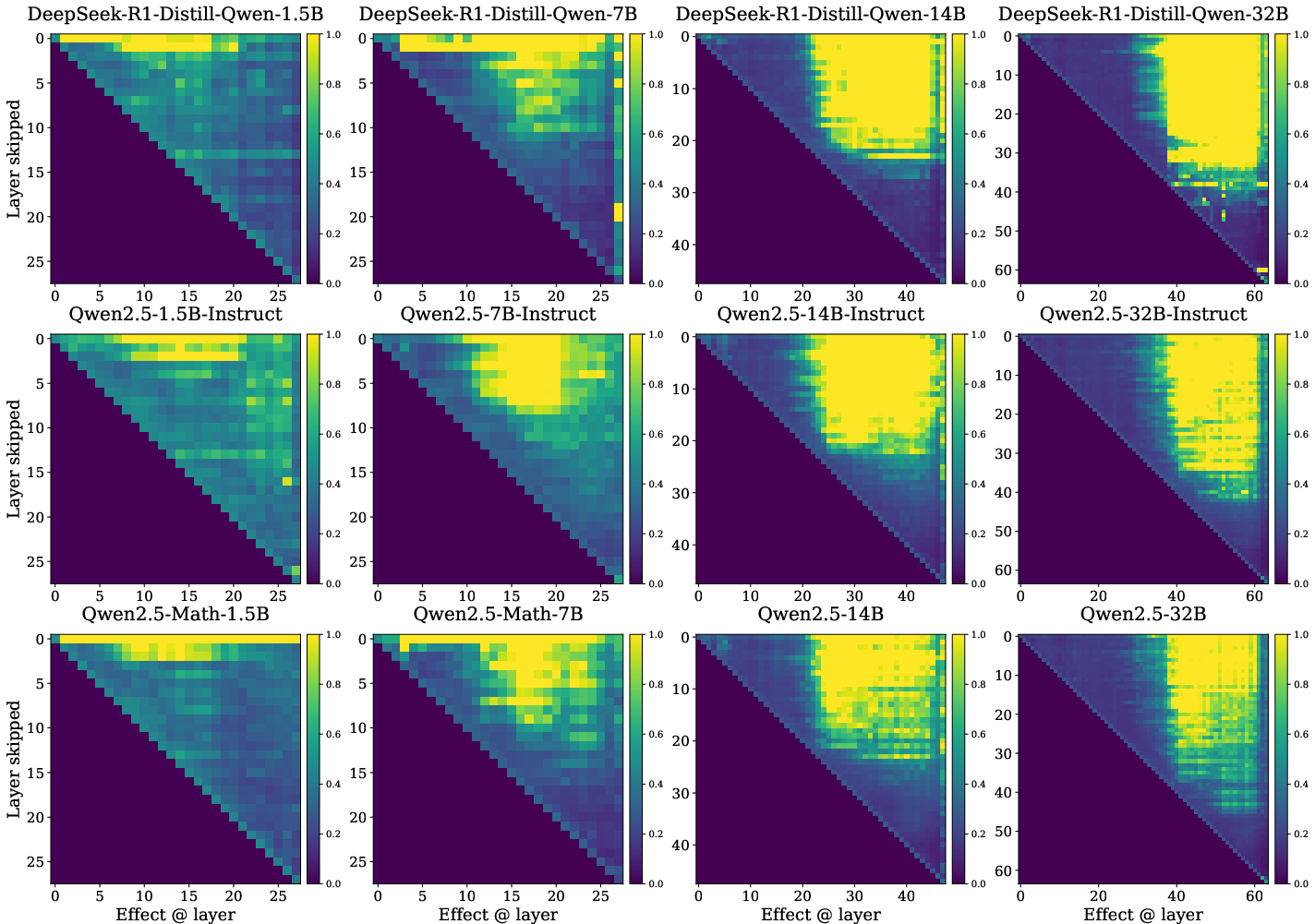
Figure 3: Effect of skipping a layer on future computation evaluated on GSM8K.
Long-CoT Training Regimes and Effective Depth
Notably, long-CoT (chain-of-thought) models, despite high performance on complex reasoning tasks, do not engage more effective depth per forward pass compared to their base or instruction-tuned counterparts. Consistency in effective depth ratio is observed across all probing dimensions, implying that improvements arise from sequence-level reasoning strategies (longer context, better use of temporal dependencies), not from increased per-token computational hierarchy.
Task Difficulty and Dynamic Depth Allocation
Analysis across HellaSwag, GSM8K, and AIME24 reveals no significant adaptive response in effective depth to task difficulty. The subset of layers utilized remains consistent, indicating that current architectures lack mechanisms for conditionally leveraging greater depth when faced with greater computational demand.
Figure 4: Residual cosine similarity of all models on GSM8K and HellaSwag.
Figure 5: The effects of skipping a layer on future computations, the results include all models on GSM8K and HellaSwag.
Figure 6: The effects of skipping a layer on output distributions, the results include all models on GSM8K and HellaSwag.
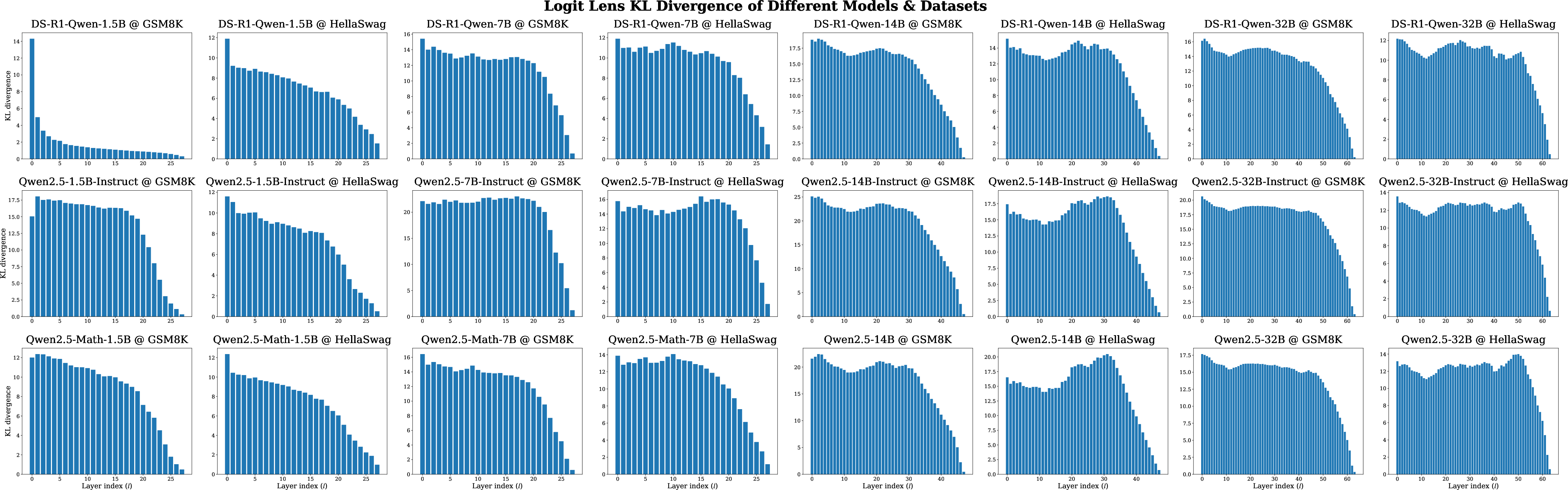
Figure 7: Logit lens KL divergence between early layer distributions and the final distributions. The results include all models on GSM8K and HellaSwag.
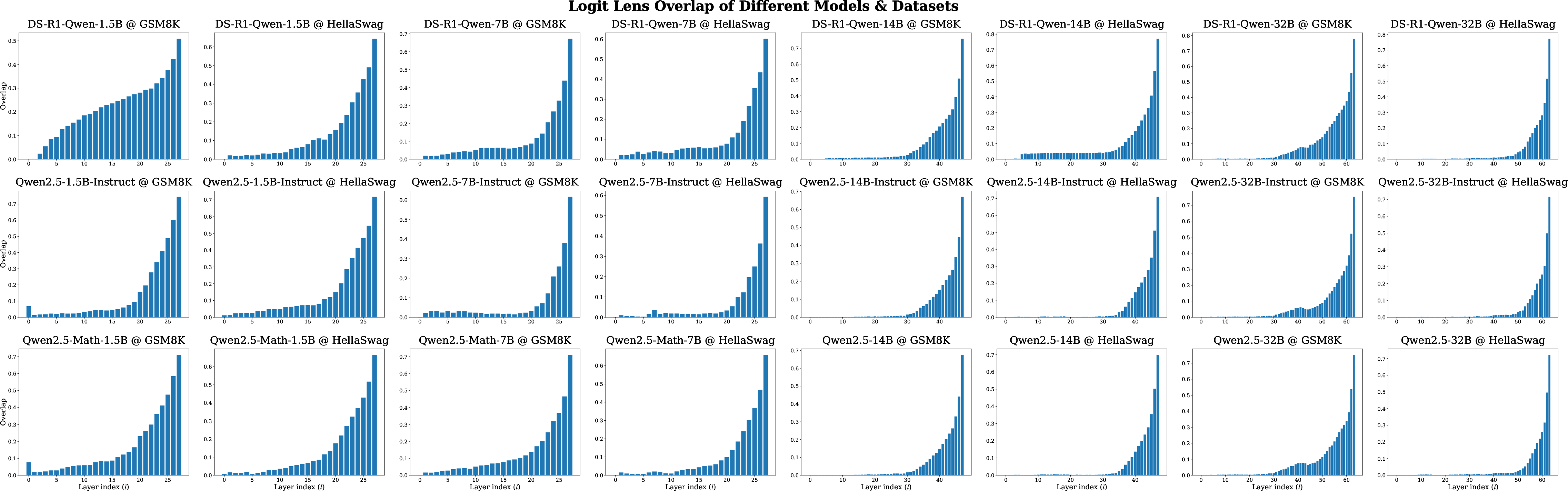
Figure 8: Logit lens top-5 overlap between early layer distributions and the final distributions. The results include all models on GSM8K and HellaSwag.
Implications and Future Research Directions
The results demonstrate that present-day LLMs substantially under-utilize their architectural depth, with redundant computation over large segments of the model regardless of training or task. This has several key implications:
- Model Efficiency: Pruning or early-exit mechanisms have substantial theoretical headroom, potentially enabling smaller or faster models to achieve near-parity with much deeper networks.
- Architectural Innovations: There is a strong incentive to explore architectures that enable explicit dynamic allocation of computational resources (e.g., adaptive depth, recurrence, or routing strategies) in response to input and task demands.
- Interpretability: These findings provide a rationale for why post-hoc interpretability typically localizes decisive computation to a narrow band of layers rather than diffusing across the network.
From a theoretical perspective, these observations challenge the assumption that network capacity scales usefully with depth in the absence of explicit mechanisms enforcing compositional reasoning across all layers.
Conclusion
This comprehensive empirical analysis establishes that LLMs do not exploit the majority of their available depth for high-level feature composition or adaptive computation, regardless of model scale, training (including long-CoT), or task complexity. The effective depth ratio remains stationary, with a small core of layers performing all substantial computation. Addressing this inefficiency—via architectural changes, training protocols, or inference-time adaptations—constitutes a critical path for improving both performance and computational efficiency in future LLM generations.