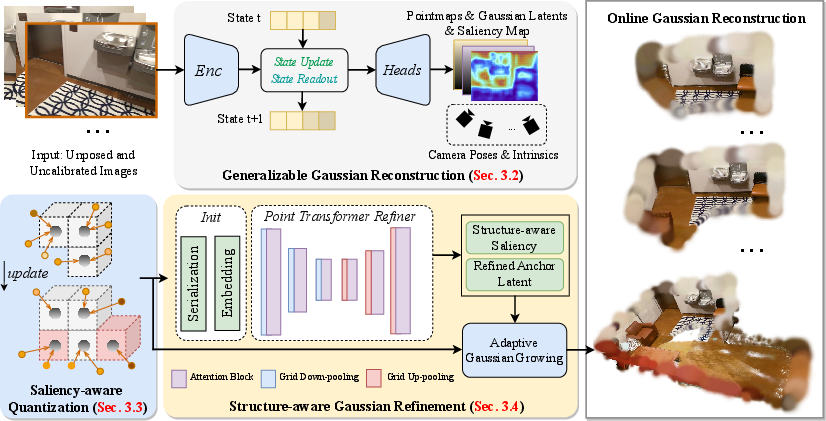
SaLon3R: Structure-aware Long-term Generalizable 3D Reconstruction from Unposed Images
Abstract: Recent advances in 3D Gaussian Splatting (3DGS) have enabled generalizable, on-the-fly reconstruction of sequential input views. However, existing methods often predict per-pixel Gaussians and combine Gaussians from all views as the scene representation, leading to substantial redundancies and geometric inconsistencies in long-duration video sequences. To address this, we propose SaLon3R, a novel framework for Structure-aware, Long-term 3DGS Reconstruction. To our best knowledge, SaLon3R is the first online generalizable GS method capable of reconstructing over 50 views in over 10 FPS, with 50% to 90% redundancy removal. Our method introduces compact anchor primitives to eliminate redundancy through differentiable saliency-aware Gaussian quantization, coupled with a 3D Point Transformer that refines anchor attributes and saliency to resolve cross-frame geometric and photometric inconsistencies. Specifically, we first leverage a 3D reconstruction backbone to predict dense per-pixel Gaussians and a saliency map encoding regional geometric complexity. Redundant Gaussians are compressed into compact anchors by prioritizing high-complexity regions. The 3D Point Transformer then learns spatial structural priors in 3D space from training data to refine anchor attributes and saliency, enabling regionally adaptive Gaussian decoding for geometric fidelity. Without known camera parameters or test-time optimization, our approach effectively resolves artifacts and prunes the redundant 3DGS in a single feed-forward pass. Experiments on multiple datasets demonstrate our state-of-the-art performance on both novel view synthesis and depth estimation, demonstrating superior efficiency, robustness, and generalization ability for long-term generalizable 3D reconstruction. Project Page: https://wrld.github.io/SaLon3R/.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces SaLon3R, a new way for computers to quickly build a 3D model of a scene from a stream of ordinary photos or video frames, even when we don’t know where the camera was or how it was set up. It focuses on making the 3D model accurate, compact, and fast to update, so it can handle long videos in real time.
The method is “structure-aware,” which means it pays special attention to the important shapes and details in the scene, and it avoids wasting effort on flat, simple areas.
What questions does the paper try to answer?
- How can we rebuild a detailed 3D scene from many images when we don’t know the camera positions (no precomputed poses or calibration)?
- How can we do this fast enough to work with long videos (50+ views) in real time (over 10 frames per second)?
- How can we avoid creating millions of unnecessary 3D pieces that waste memory and slow things down?
- How can we keep the 3D model consistent and clean across many frames (fewer “floaters,” less blur, fewer mismatches in color and geometry)?
- Can this work well on new, unseen scenes without extra training time?
How does it work? (Simple explanation of the approach)
Think of making a 3D scene like building a model with tiny, fuzzy paint blobs floating in space. This popular technique is called 3D Gaussian Splatting (3DGS). If you just add one blob per pixel from every image, you get way too many blobs—slow and messy.
SaLon3R keeps only the blobs that matter and fixes inconsistencies by following a smart pipeline:
- Step 1: Understand the scene from each image
- A backbone network (like CUT3R or VGGT) looks at each incoming image and guesses:
- Where points in the image are in 3D (a “point map”).
- A first guess of the little 3D blobs (their color, size, shape).
- A “saliency map” that says which areas are complex or important (edges, textures) and which are simple (flat walls).
- It also estimates camera information on the fly—no need for known camera poses.
- Step 2: Compress similar blobs into anchors
- Imagine dividing space into small 3D boxes (like a Minecraft grid). Nearby blobs that fall in the same box get merged into a single “anchor.”
- Important areas (high saliency) get more attention, so fine details are preserved. Less important regions get fewer blobs.
- This “saliency-aware quantization” removes 50%–90% of redundant blobs while keeping detail where it counts.
- Step 3: Make the anchors smarter with structure
- A lightweight “Point Transformer” looks at the anchors together, paying attention to their 3D neighborhood (like noticing how Lego pieces fit into the bigger structure).
- It corrects color/shape mismatches and fixes 3D alignment problems across frames.
- Step 4: Grow blobs where needed, prune where not
- From each refined anchor, the system can “grow” a few blobs in the right places to improve detail.
- Areas marked as important get more blobs; simple areas get fewer.
- A learned importance score (saliency) helps keep or discard blobs automatically.
- Step 5: Render and update in real time
- The system renders images from new viewpoints and updates quickly as new frames arrive, keeping the 3D scene consistent.
In everyday terms: The method first guesses a rich 3D sketch from each image, packs duplicates together, uses a “structure reader” to fix mistakes, and then unpacks just enough detail to look great—without wasting memory.
What did they find, and why does it matter?
Main results:
- Speed and scale: Reconstructs over 50 views at more than 10 frames per second (real-time friendly).
- Huge size reduction: Cuts the number of 3D blobs by 50%–90%, which saves memory and improves speed.
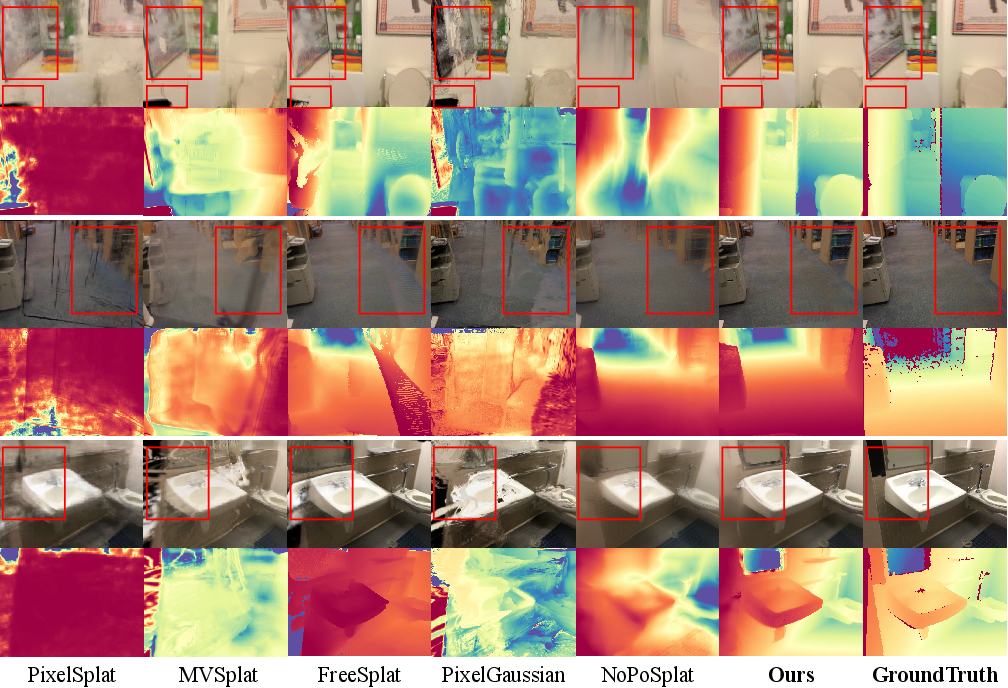
- Quality: Produces clean, high-quality renderings and very accurate depth maps (how far away things are), often beating methods that even know the camera poses.
- Robustness: Works well on new datasets (zero-shot), meaning it generalizes to new scenes without extra training.
- Stability on long videos: Keeps the 3D consistent across many frames, with fewer artifacts like “floaters” and color mismatches.
Why it matters:
- Many real-world videos are long and don’t come with camera information. Being able to reconstruct 3D scenes fast, accurately, and without known camera poses opens the door to practical applications like robotics, AR/VR, and quick scene scanning.
What could this change in the future?
- Better tools for AR/VR: Phones or headsets could build reliable 3D maps on the fly from casual videos.
- Robotics and drones: Robots can understand their surroundings quickly from raw camera input without heavy preprocessing.
- Faster 3D content creation: Artists and engineers can turn videos into 3D assets more efficiently.
- Research directions: The method currently focuses on static scenes. In the future, it could be extended to handle moving objects (dynamic scenes) for full 4D (changing over time) reconstruction.
In short
SaLon3R is a smart, real-time 3D reconstruction method that:
- Doesn’t need known camera poses,
- Knows where to keep detail and where to compress,
- Fixes cross-frame inconsistencies using 3D structure,
- Runs fast and scales to long video sequences,
- And generalizes well to new scenes.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Dynamic scenes are not supported; the method is designed for static reconstruction. How to extend anchor-based quantization and structure-aware refinement to 4D dynamic content (moving objects, deformations, view-dependent dynamics) remains open.
- Camera intrinsics and poses are estimated without detailed validation. The accuracy, stability, and failure modes of intrinsic estimation (e.g., focal length via the Weiszfeld algorithm) and pose estimation under rolling shutter, lens distortion, motion blur, and strong perspective effects are not characterized.
- The saliency map is learned only via rendering loss (no ground truth) and its behavior across domains is not analyzed. There is no study of how saliency correlates with true geometric complexity, texture frequency, or depth gradients, nor how it generalizes to outdoor, specular, and low-texture scenes.
- Voxel size γ for quantization is a key trade-off parameter, yet no sensitivity analysis, per-scene adaptation, or automatic selection strategy is provided. The impact of γ on reconstruction quality, redundancy removal rate, and runtime/memory is unknown.
- Adaptive Gaussian growing uses fixed M=4 and threshold β without systematic tuning or an automatic policy. There is no principled scheme to select M and β based on scene content, performance targets, or hardware constraints.
- The choice of serialization curve (z-order vs. Hilbert) and patch attention configurations in the point transformer are not ablated. How these design choices affect spatial neighborhood preservation, refinement efficacy, and runtime is unclear.
- Structure-aware refinement leverages local attention only; no global consistency mechanisms (e.g., loop closure, global graph constraints) are explored to mitigate drift across very long sequences or revisit views.
- Incremental merging uses only Gaussians near the current view frustum. The consequences for maintaining occluded or temporarily invisible geometry, longer-range consistency, and forgetting effects are not analyzed.
- Photometric inconsistencies and view-dependent effects are only indirectly addressed via SH coefficients; there is no explicit reflectance or lighting model. The method’s robustness to specularities, gloss, and non-Lambertian materials is not evaluated.
- Extrapolation rendering is claimed to improve, but there is no quantitative metric (e.g., viewpoint distance bins, angular baselines) or controlled protocol to measure extrapolation vs. interpolation performance.
- Runtime and memory are reported for A100 GPUs and 512×384 resolution only. The method’s efficiency and scalability on commodity hardware (e.g., RTX 3060/4080, laptop GPUs), higher resolutions, and larger scenes are not characterized.
- The 50–90% redundancy removal claims are dataset-specific and lack theoretical or empirical guarantees across scene types (outdoor, large-scale, cluttered, high-frequency textures). How redundancy removal scales with view count and scene complexity remains open.
- Anchor and Gaussian covariance parameterization details (e.g., enforcement of positive-definiteness, anisotropy, orientation) are not specified or ablated. The impact of covariance modeling choices on geometry fidelity and rendering artifacts is unknown.
- No uncertainty modeling is provided. How to propagate confidence from the reconstruction backbone into anchors/Gaussians, and use uncertainty to drive pruning, saliency, or refinement is unexplored.
- The method fixes backbone weights (CUT3R/VGGT) and trains heads/refiner only. The benefits and risks of end-to-end finetuning (or partial finetuning) for joint optimization of pose, pointmaps, saliency, and GS are not studied.
- Depth evaluation uses mono-depth metrics but lacks discussion of scale handling, alignment procedures, and sensitivity to intrinsic errors. The relationship between pointmap metricity and rendered depth accuracy is not rigorously analyzed.
- Robustness to severe view sparsity (<15% overlap), rapid camera motion, and in-the-wild degradations (noise, exposure changes, white balance shifts) is not evaluated.
- Failure cases are not reported. Typical breakdown scenarios (e.g., heavy textureless regions, repetitive patterns, thin structures, strong parallax, misestimated poses) and their diagnostic signals are missing.
- Baseline comparisons are limited by out-of-memory constraints for some methods; fair configurations (e.g., pruning settings, lower resolution runs, memory-optimized variants like Octree-GS/LightGaussian) are not provided, leaving comparative efficiency and quality partly unresolved.
- No adaptive quality–latency control is proposed. How to dynamically trade off GS density, refinement depth, and rendering quality based on runtime budget or application constraints is an open design problem.
- The impact of training data scale and diversity is underexplored (trained primarily on ScanNet). Generalization to outdoor scenes, large open spaces, multi-room environments, and diverse photometric domains needs systematic evaluation.
- Edge-aware depth smoothness loss may oversmooth fine geometry; no analysis of its effect on thin structures, high-frequency edges, or texture–geometry disentanglement is provided.
- Integration with test-time adaptation or lightweight online optimization (to correct residual misalignment or photometric drift) is not considered; whether small per-scene updates would significantly improve quality remains an open question.
- Data I/O and end-to-end latency (including pre-/post-processing, serialization, anchor fusion) are not broken down; profiling (GFLOPs, memory footprint per module) is missing, hindering practical deployment planning.
Practical Applications
Immediate Applications
Below are specific, deployable use cases enabled by SaLon3R’s pose-free, online 3D Gaussian Splatting with saliency-aware quantization and structure-aware refinement (>10 FPS, 50–90% redundancy removal, strong depth accuracy), organized by sector and including potential tools and dependencies.
- (AR/VR, Mobile) Pose-free room capture and AR occlusion
- What: Real-time 3D scene capture and high-quality depth from handheld video without intrinsics/poses for occlusion, physics, and object placement.
- Tools/workflows: Unity/Unreal plugin that streams camera frames to a SaLon3R runtime; mobile SDK for iOS/Android; on-device or edge inference.
- Assumptions/dependencies: Static or quasi-static scenes; moderate frame overlap (~15–50%); sufficient light/texture; mobile GPU/NPUs or cloud offload.
- (Real estate, AEC, Facilities) Rapid indoor digital twin creation from unposed walks
- What: Quick scans of apartments/offices for floor planning, virtual tours, and change detection; reduced storage via compact anchor-based 3DGS.
- Tools/workflows: “Walk-and-capture” app; ingestion into digital twin viewers; export to mesh or GS-to-mesh pipeline for BIM interoperability.
- Assumptions/dependencies: Static interiors; evaluation resolution close to 512×384 (or scaled); export pipeline for non-GS consumers.
- (Logistics, Robotics) Monocular online mapping in warehouses and factories
- What: Online reconstruction and dense depth for mapping and inspection using a single RGB camera on AMRs/UAVs in GPS-denied indoor spaces.
- Tools/workflows: ROS2 node producing depth/poses/GS; frustum-based incremental updates; integration with occupancy grid or ESDF builders.
- Assumptions/dependencies: Static infrastructure; robust handling of moving forklifts via masking; compute on edge GPU (Jetson-class) or base station.
- (Media/VFX) Depth for post-production from ordinary footage
- What: Feed-forward depth for 2.5D parallax, relighting, and compositing without LiDAR or SfM pre-process.
- Tools/workflows: Nuke/After Effects/DaVinci Resolve plugin; batch processing with edge-aware depth smoothing.
- Assumptions/dependencies: Static backgrounds; consistent exposure; temporal consistency post-filtering for long takes.
- (Cultural heritage, Museums) Fast documentation of interiors and exhibits
- What: Quick 3D capture for conservation, walkthroughs, and educational visualization.
- Tools/workflows: Curator app with automatic redundancy pruning; viewer that streams compact Gaussians.
- Assumptions/dependencies: Limited crowd motion; stable lighting; rights management for sensitive assets.
- (Retail, Interior design) In-situ visualization and measurement
- What: Place furniture digitally, measure spaces, and generate virtual layouts with pose-free scanning.
- Tools/workflows: Consumer AR app providing live depth and novel-view previews; integration with SKU catalogs.
- Assumptions/dependencies: Room-scale, static scenes; calibration-free focal estimation quality sufficient for measurements (tolerance disclosure).
- (Security, Telepresence) Remote situational awareness in indoor environments
- What: Real-time 3D scene for remote operators (inspection/maintenance) using a monocular bodycam or drone feed.
- Tools/workflows: Streaming 3DGS viewer; bandwidth savings from anchor quantization.
- Assumptions/dependencies: Scene staticity; network QoS; privacy/compliance safeguards.
- (Education, Research) Generalizable 3D reconstruction baseline and teaching aid
- What: Reference implementation for pose-free online recon, redundancy-aware quantization, and anchor refinement.
- Tools/workflows: Open-source training/inference scripts; reproducible course modules with ScanNet/Replica subsets.
- Assumptions/dependencies: GPU availability; licensing of datasets; fixed backbones (CUT3R/VGGT) per paper.
- (Graphics, Content delivery) 3DGS compression/pruning in existing pipelines
- What: Use saliency-aware quantization and adaptive growing to cut 3DGS memory and speed up rendering.
- Tools/workflows: Offline optimizer/pruner for existing GS assets; compatibility with Scaffold-GS/CompGS toolchains.
- Assumptions/dependencies: Access to Gaussian attributes; tuning voxel size γ and opacity threshold β.
- (Insurance, Field inspection) Rapid interior documentation for claims and audits
- What: One-pass scans for structure and depth to support damage assessment and claim triage.
- Tools/workflows: Field agent app; export to standardized report formats with depth maps and novel views.
- Assumptions/dependencies: Static scenes during capture; guidance on minimal view overlap; accuracy thresholds communicated to users.
- (SLAM/SfM tooling) Bootstrapping initial structure and poses
- What: Provide pointmaps/poses to accelerate or stabilize traditional pipelines in low-texture or unposed settings.
- Tools/workflows: API to export estimated intrinsics/extrinsics and anchor pointmaps; downstream bundle-adjustment refinement.
- Assumptions/dependencies: Static scenes; occasional pose drift addressed by downstream optimization.
- (Privacy-preserving edge compute) On-device mapping to minimize raw video sharing
- What: Convert video to compact 3DGS/depth in situ and upload only the compressed representation.
- Tools/workflows: Edge inference on smartphones/Jetsons; controlled data-handling policies.
- Assumptions/dependencies: Sufficient on-device compute; threat modeling for 3D reconstruction privacy.
Long-Term Applications
The following use cases are feasible with further research, scaling, or engineering, including handling dynamics, outdoor variability, and multi-user/global consistency.
- (Healthcare, Surgical robotics) Dynamic, deformable 4D reconstruction from endoscopic videos
- What: Extend SaLon3R to dynamic tissue for consistent 4D depth and surface during procedures.
- Tools/workflows: Dynamic Gaussian Splatting and motion-aware saliency; temporal regularizers and biomechanical priors.
- Assumptions/dependencies: Algorithmic extension to dynamics; domain-specific training; clinical validation and regulatory approval.
- (Geospatial, Autonomous driving) City-scale outdoor mapping from dashcams/bodycams
- What: Large-scale reconstruction with changing illumination, weather, and heavy dynamics.
- Tools/workflows: Fleet data processing; sunlight-invariance and sky handling; distributed GS storage/streaming.
- Assumptions/dependencies: Outdoor generalization; robust dynamic object handling; long-range scaling and loop closure.
- (Robotics) Navigation and planning from monocular-only perception
- What: Use SaLon3R-derived depth/structure for obstacle avoidance and planning without LiDAR/SfM.
- Tools/workflows: Tight integration with VIO/SLAM; failsafes; redundancy with cheap radar/ultrasonic.
- Assumptions/dependencies: Certified safety; real-time guarantees; dynamic obstacle modeling.
- (AR Cloud, Multi-user) Crowdsourced, pose-free 3DGS fusion across users and sessions
- What: Aggregate unposed captures into consistent, updatable digital twins.
- Tools/workflows: Global anchor indexing; cross-session anchor alignment; drift correction and semantic anchoring.
- Assumptions/dependencies: Identity/consistency across sessions; privacy and consent management; scalable backends.
- (Construction, AEC) Progress monitoring at building scale with BIM comparison
- What: Weekly scans producing GS/meshes aligned to BIM for deviation detection and progress KPIs.
- Tools/workflows: GS-to-mesh conversion; BIM alignment; change detection dashboards.
- Assumptions/dependencies: Accurate global alignment; outdoor-in indoor transitions; enterprise-grade QA.
- (Emergency response, Public safety) Rapid 3D mapping in GPS-denied hazardous environments
- What: Indoor UAVs/bodycams reconstructing layouts for SAR planning.
- Tools/workflows: Onboard/edge inference; smoke/dust robustness; multi-agent fusion.
- Assumptions/dependencies: Dynamic debris; low-light; robust domain adaptation and safety protocols.
- (Consumer XR) Real-time room-scale capture in headsets with monocular RGB
- What: Provide occlusion, hand/prop interaction physics, and quick room meshes without depth sensors.
- Tools/workflows: XR runtime integration; on-device sparse anchor updates; power-aware scheduling.
- Assumptions/dependencies: Efficient on-device inference; thermal budgets; SLAM co-design.
- (E-commerce, Manufacturing) Turntable-free product digitization at scale
- What: Short hand-held videos to produce compact 3D assets for catalogs or QA.
- Tools/workflows: Controlled capture booths; GS-to-textured-mesh conversion; automated QC.
- Assumptions/dependencies: Domain adaptation to small, glossy, or textureless objects; micro-baseline imaging; controlled lighting.
- (Security, Privacy) Semantic redaction in 3D reconstructions
- What: Automatic removal/down-weighting of sensitive regions (faces, screens) in 3DGS.
- Tools/workflows: Semantic-aware saliency; encryption and secure sharing of redacted GS.
- Assumptions/dependencies: Reliable semantic segmentation; policy alignment; audit trails.
- (Content streaming) Standardized 3DGS streaming for real-time remote rendering
- What: CDN-like delivery of compact GS anchors for interactive telepresence and virtual tours.
- Tools/workflows: GS codecs, rate control, and progressive refinement; edge caches.
- Assumptions/dependencies: Interoperable formats; client GPU support; network QoS.
- (Policy, Standards) Guidelines for pose-free 3D capture and data governance
- What: Best practices for overlap, lighting, and privacy; benchmarks for accuracy and robustness; procurement specs for agencies.
- Tools/workflows: Public test suites; conformance tests for dynamic/static scenes; redaction policies.
- Assumptions/dependencies: Multi-stakeholder consensus; legal frameworks; sustainable dataset stewardship.
- (Science, Foundation models) Unified 3D perception pretraining with persistent state
- What: Train large models that jointly learn pose, depth, and compact GS across domains.
- Tools/workflows: Multi-dataset training (indoor/outdoor/dynamic); self-supervised objectives; structure-aware tokenization.
- Assumptions/dependencies: Large-scale compute; diverse, licensed data; evaluation standards across tasks.
Glossary
- Abs Rel: Absolute Relative Error; a depth estimation metric measuring per-pixel error relative to ground truth depth. "To evaluate the depth, we report two common metrics in mono-depth estimation: Abs Rel and ()."
- Adaptive Gaussian Growing: A technique that predicts multiple Gaussians per anchor and prunes or allocates them based on refined saliency to control density. "Adaptive Gaussian Growing."
- Anchor primitives: Compact representative units created by fusing points within a voxel to reduce redundancy while preserving geometry. "Our method introduces compact anchor primitives to eliminate redundancy through differentiable saliency-aware Gaussian quantization"
- CUT3R: A continuous 3D perception model with a persistent state used as the reconstruction backbone for pointmaps, Gaussians, and saliency. "Specifically, we adopt CUT3R~\citep{wang2025continuous} as the backbone to predict global pointmaps, per-pixel Gaussian latents, and associated saliency map."
- Delta-1 (δ1): The fraction of depth predictions within a threshold, commonly reported as the percentage with . "Abs Rel and ()."
- DPT-like architecture: A Dense Prediction Transformer-style head used to produce pixel-wise Gaussian latents and saliency. "we adopt the DPT-like architecture~\citep{ranftl2021vision} as Gaussian head"
- Edge-aware depth regularization loss: A loss encouraging smooth depth while respecting image edges, improving geometric consistency. "we apply an edge-aware depth regularization loss on the rendered depth"
- Extrapolation rendering: Rendering novel views outside the context-view distribution, requiring robustness to out-of-distribution poses. "our model also enhances the extrapolation rendering ability for better rendering quality and robustness."
- Feed-forward reconstruction: Single-pass scene reconstruction without per-scene optimization or test-time adaptation. "enable a feed-forward reconstruction, achieving generalizable view synthesis."
- Frustum: The pyramidal viewing volume used to select nearby Gaussians for incremental updates. "only part of the global Gaussian that are near the frustum of the current view are extracted"
- Gaussian anchor: A fused representation of Gaussian attributes at a voxel that is later decoded into multiple Gaussians. "Gaussian anchors are adaptively decoded into Gaussians based on the updated 3D saliency of each voxel"
- Gaussian latent: A per-pixel latent vector encoding Gaussian attributes prior to decoding. "pixel-wise Gaussian latents"
- Gaussian quantization: Compressing dense Gaussians by saliency-weighted fusion into sparse anchors to reduce redundancy. "saliency-aware Gaussian quantization"
- Hilbert curve: A space-filling curve used to serialize 3D points into an ordered sequence for efficient processing. "i.e., z-order curve and Hilbert curve"
- LPIPS: Learned Perceptual Image Patch Similarity; a perceptual metric for image quality assessment. "LPIPS~\citep{zhang2018unreasonable}"
- Neural Radiance Fields (NeRF): An implicit volumetric representation that models view-dependent radiance for novel view synthesis. "Neural Radiance Fields (NeRF)~\citep{mildenhall2021nerf}"
- Novel View Synthesis (NVS): Rendering images from unseen viewpoints given multi-view inputs and a reconstructed 3D scene. "novel view synthesis (NVS)"
- Octree: A hierarchical 3D partitioning data structure for efficient Gaussian organization and rendering. "Octree-GS~\citep{ren2024octree} utilizes an octree-based structure to hierarchically partition 3D space."
- Photometric inconsistency: Appearance discrepancies across views due to view-dependent effects or reconstruction errors. "degradation in rendering quality due to photometric inconsistency and 3D misalignment"
- Point Transformer V3 (PTV3): An attention-based point-cloud encoder used to refine anchor attributes and saliency with structural priors. "we adopt Point Transformer V3 (PTV3)~\citep{wu2024point,chen2024splatformer} as an efficient structure-aware point cloud encoder"
- Pointmap: A per-pixel 3D point representation in world coordinates predicted for reconstruction. "predict global pointmaps, per-pixel Gaussian latents, and associated saliency map"
- PSNR: Peak Signal-to-Noise Ratio; a metric quantifying reconstruction fidelity in novel view synthesis. "We evaluate the performance of novel view synthesis with PSNR, SSIM~\citep{wang2004image}, and LPIPS~\citep{zhang2018unreasonable}."
- Saliency map: A predicted spatial map encoding regional geometric and photometric complexity to guide fusion and decoding. "a saliency map encoding regional geometric complexity."
- Space-filling curve: A mapping from multi-dimensional space to a one-dimensional order used to serialize point clouds. "order in a space-filling curve (i.e., z-order curve and Hilbert curve)."
- Spherical harmonics: Basis functions used to model view-dependent color with per-Gaussian coefficients. "spherical harmonics coefficients ."
- SSIM: Structural Similarity Index; a perceptual metric comparing luminance, contrast, and structure between images. "We evaluate the performance of novel view synthesis with PSNR, SSIM~\citep{wang2004image}, and LPIPS~\citep{zhang2018unreasonable}."
- Structure-from-Motion (SfM): A pipeline that estimates camera poses and 3D structure from images via matching and triangulation. "e.g., Structure-from-Motion."
- Structure-aware inductive bias: A prior encouraging models to respect global 3D spatial relationships during fusion and refinement. "without additional structure-aware inductive bias"
- U-Net: An encoder–decoder architecture with skip connections used here in the point transformer refiner. "The point transformer follows the structure of U-Net"
- VGGT: A feed-forward network that directly estimates 3D attributes from many views, used as a reconstruction backbone. "VGGT~\citep{wang2025vggt} proposes a feed-forward neural network to directly estimate the key 3D attributes from hundreds of views."
- Voxel downsampling: Reducing Gaussian density by aggregating points within fixed-size voxels before anchor fusion. "encode the pixel-wise dense Gaussians into compact Gaussian anchors by voxel downsampling"
- Voxelization: Mapping continuous 3D points to discrete voxel cells for aggregation and fusion. "we first voxelize the scene from the Gaussian centers"
- Weiszfeld algorithm: An iterative method for the geometric median; used here to estimate focal length. "we estimate focal length with the Weiszfeld algorithm~\citep{plastria2011weiszfeld}"
- z-order curve: A Morton-order space-filling curve used to serialize points for efficient processing. "i.e., z-order curve and Hilbert curve"
Collections
Sign up for free to add this paper to one or more collections.

