Self-Supervised Flow Matching for Scalable Multi-Modal Synthesis
Abstract: Strong semantic representations improve the convergence and generation quality of diffusion and flow models. Existing approaches largely rely on external models, which require separate training, operate on misaligned objectives, and exhibit unexpected scaling behavior. We argue that this dependence arises from the model's training objective, which poses a denoising task with little incentive to learn semantic representations. We introduce Self-Flow: a self-supervised flow matching paradigm that integrates representation learning within the generative framework. Our key mechanism, Dual-Timestep Scheduling, applies heterogeneous noise levels across tokens, creating an information asymmetry that forces the model to infer missing information from corrupted inputs. This drives learning strong representations alongside generative capabilities without external supervision. Our method generalizes across modalities and enables multi-modal training while following expected scaling laws, achieving superior image, video, and audio generation.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper shows a new way to train image, video, and audio generators so they “understand” what they’re making without needing extra helper models. The authors call their method Self-Flow. It teaches a single generative model to build strong internal understanding (representations) while it learns to create pictures, videos, and sounds. This makes the generator better at structure (like faces and hands), readable text in images, and smooth motion in videos, and it works across different types of media.
What questions the researchers asked
The paper focuses on three simple questions:
- Can a generator learn to “understand” content on its own instead of borrowing understanding from a separate model?
- Will doing this make the generator better and faster to train?
- Will it work not just for images, but also for videos and sounds—and still scale well as we use bigger models and more data?
How the method works (in everyday language)
First, a quick idea of how these generators usually work:
- Flow/diffusion models learn to turn random noise into a finished picture, video, or sound by taking many small steps from “static” to “clear.”
- Today, many training recipes ask the generator to match features from a separate “teacher” model (like an image encoder). That teacher wasn’t built to generate things; it was built to recognize things. This helps, but it creates problems: you need extra training, it may not fit other media (like audio), and bigger teachers don’t always help.
The authors’ new idea: teach understanding inside the generator itself.
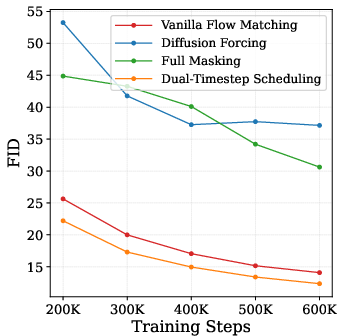
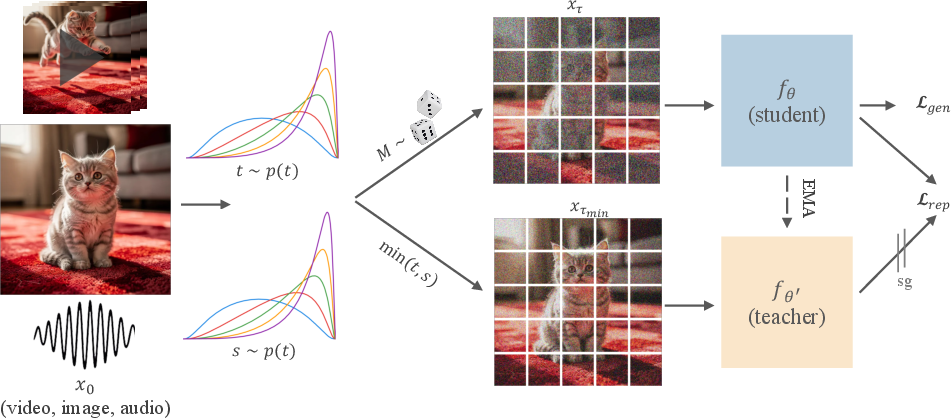
- Think of the input (an image or video broken into small pieces called “tokens”) like a puzzle. They blur some pieces a lot and others only a little. This is called Dual-Timestep Scheduling.
- Then they do two passes through the model:
- Student pass: The model sees the mixed-blur puzzle (some pieces very blurry, some clearer) and tries to predict both how to denoise it and what a “cleaner-view” model would think about it.
- Teacher pass: A gently updated copy of the same model (an “EMA teacher”—basically a smoothed version of the student over time) sees a cleaner version of the puzzle and produces internal features (its “notes” about what’s in the image/video/audio).
- The student is trained to: 1) Turn noise into a clean result (normal generative training), and 2) Predict the teacher’s internal features from its harder, more-blurred view.
Why this works:
- The mixed blur creates “information asymmetry.” To fill in the very blurry parts, the model must use clues from the clearer parts. That encourages it to learn global, meaningful patterns (like “this is a face,” “these letters spell a word,” or “this is how objects move over time”).
- Because both teacher and student are the same model (just at different stages), the system learns strong internal representations without any external model.
Key terms in simple words:
- Tokens: small chunks of data (like image patches or short audio slices).
- Noise: blur or static.
- Representations: the model’s internal notes that summarize “what’s going on” (e.g., “there’s a dog facing left”).
- EMA teacher: a softly averaged, slightly older copy of the model that provides stable guidance.
Main findings and why they matter
Here’s what they found when they tested images, videos, and audio:
- Better quality with no extra helper model:
- Images: Sharper structure (faces, hands), more accurate details, and better text rendering in images.
- Videos: Smoother, more consistent motion over time.
- Audio: Better scores on audio quality metrics.
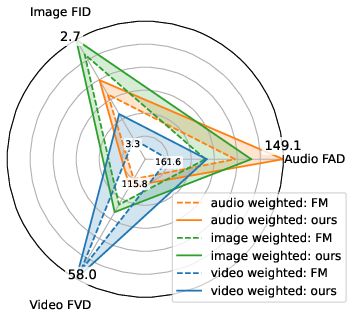
- Works across multiple media: It helps images, videos, and audio—together and separately. They also trained one model on all three at once and still saw improvements.
- Faster and more reliable training: On text-to-image tasks, their method converged faster than popular alignment methods that rely on external teachers.
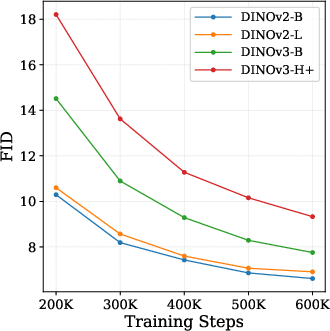
- Scales the way you’d hope: As models get bigger or you use more compute, their method keeps improving. In contrast, aligning to bigger external teacher models often made things worse, which is surprising and not what you’d expect.
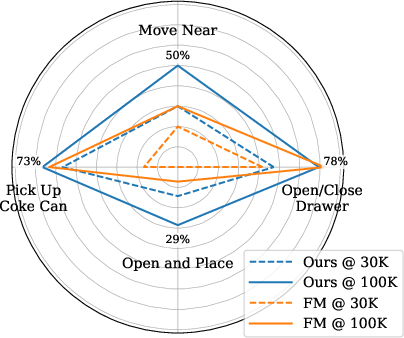
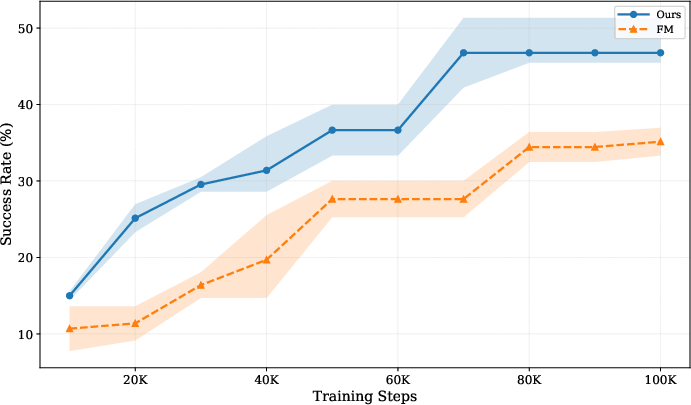
- Robotics-style tasks: When predicting both future video and robot actions, their method learned faster and handled tougher, multi-step tasks better.
Why that’s important:
- No extra teacher models means simpler pipelines and less guesswork about which teacher to pick.
- It avoids strange “scaling fails” where bigger external teachers don’t help or even hurt.
- It’s a single, unified approach that works across images, videos, and audio, which is useful for future “world models” that need to handle many kinds of data together.
What this could lead to
- More general, reliable generators: Models that truly “get” what they’re making can create more accurate, consistent content.
- Easier, more scalable training: No need to attach different external teachers for different tasks or media.
- Stronger foundations for multi-modal AI: Better internal understanding can help in complex settings like video+audio generation or robotics, where reasoning over time and across senses matters.
In short
The paper proposes a simple but powerful training trick—mixing different amounts of blur across parts of the input and having the model learn from a cleaner version of itself—that teaches a generator to understand what it’s making. This removes the need for external teacher models, improves quality across images, video, and audio, speeds up training, and scales well as models grow.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a focused list of specific gaps and open issues that remain unresolved and could guide future research:
- Theoretical grounding of heterogeneous per-token timesteps: No formal analysis shows that training with Dual-Timestep Scheduling preserves the rectified-flow ODE solution learned under homogeneous timesteps at inference. Clarify conditions under which per-token noise training converges to the same (or a better) velocity field as standard flow matching.
- Train–inference mismatch quantification: While Dual-Timestep Scheduling is proposed to reduce the mismatch seen in naive masking/diffusion forcing, there is no quantitative study of residual mismatch (e.g., error vs. t across the trajectory, solver stability, or step-wise denoising fidelity).
- Sensitivity to noise scheduler p(t): Performance depends on the choice of p(t), but there is no principled procedure to choose or learn it. Explore learned or adaptive scheduler curricula, modality- or token-adaptive p(t), and the interaction between scheduler shape and mask ratio.
- Mask ratio design and dynamics: The mask ratio R_M is fixed (≤0.5), with no study of larger ratios, curriculum schedules, adaptive ratios per modality, or token-importance-aware masking (e.g., content-aware/attention-guided masking).
- Coupling between t and s sampling: The method samples t and s i.i.d. from p(t); alternative couplings (e.g., controlled gap distributions |t−s|, curriculum over noise gaps, or per-head/per-layer gaps) are not explored.
- Choice of layers l and k for representation alignment: There is no systematic methodology for selecting student/teacher layers or for multi-layer, layer-weighted alignment; sensitivity and optimal configurations remain unknown.
- Alignment loss design: Only cosine similarity is reported; stability and performance of alternatives (e.g., InfoNCE, decoupled contrastive losses, whitening, temperature scaling, feature normalization strategies) are not evaluated.
- EMA teacher dynamics: The EMA decay schedule, its sensitivity, and the effect of teacher lag on stability and sample quality are not reported; it is unclear whether learned teachers or bootstrapped teachers (e.g., BYOL-style) perform better.
- Projection head architecture: The choice of MLP head hθ is under-specified; ablations on depth, normalization, and bottleneck width are missing, leaving representation capacity vs. stability trade-offs unexplored.
- Loss weighting γ schedule: The paper uses a fixed γ but does not explore schedules (warm-up/annealing), adaptive weighting (e.g., uncertainty- or gradient-based), or per-layer/per-modality γ.
- Interaction with classifier-free guidance (CFG): No analysis of how self-supervised alignment affects optimal guidance scales, guidance intervals, or failure modes (e.g., over-saturation, prompt overfitting).
- Tokenization and patching effects: The impact of patch size, stride, sequence length, and variable-length handling (especially for long videos or audio sequences) on masking efficacy and semantics is not studied.
- Multi-modal architectural details: Cross-modal coupling mechanisms (shared vs. modality-specific blocks, positional encodings, normalization sharing) are not described or ablated, impeding reproducibility and limiting insights on what enables multi-modal gains.
- Negative transfer in mixed training: Although radar plots show averaged gains, the conditions that trigger negative transfer between modalities (e.g., video harming audio) and strategies to mitigate it (e.g., gradient surgery, orthogonalization, per-modality adapters) are not investigated.
- Generalization beyond holdout splits of training data: Most evaluations use holdout sets from the same training distributions; robustness under domain shift (e.g., COCO, LAION subsets, UCF101/Kinetics, AudioSet/ESC-50) and out-of-distribution performance is not assessed.
- Benchmark coverage and metrics: For T2I, widely used human preference metrics (e.g., HPS-v2, PickScore, Aesthetic) and COCO FID are missing; for video, long-horizon temporal metrics and standard cross-dataset FVD are absent; for audio, standard FAD and MOS/human studies are not reported.
- High-resolution and long-context limits: The method’s effectiveness at very high image resolutions (e.g., 1024–4096px), long videos (e.g., >16 seconds), and long audio clips is not tested; computational/memory scaling and quality retention are unknown.
- Compute accounting and convergence claims: Claims of 2.8× faster convergence lack detailed compute budgets (FLOPs, wall-clock, memory footprint), per-method throughput, and training-time vs. quality Pareto curves across scales.
- Stability and failure mode analysis: The paper lacks a failure case taxonomy (e.g., over-smoothing, loss of diversity, artifacts at high t, text rendering edge cases) and does not report instability episodes (e.g., divergence, feature norm explosion beyond the L1 anecdote).
- Interplay with autoencoders: Although several autoencoders are cited, there is no systematic study of how latent geometry (semantic vs. reconstruction latents), compression ratio, and perceptual loss design affect Self-Flow benefits.
- Representation quality beyond ImageNet linear probes: Only early-stage ImageNet linear probing is reported; cross-modal probing, transfer to downstream tasks (e.g., segmentation, retrieval), and robustness (e.g., corruption, occlusion) are untested.
- Robotics scope: Joint video-action results are in simulation (SIMPLER) with limited tasks; there is no real-robot evaluation, no generalization to unseen objects/tasks, and limited detail on action tokenization and control stability.
- Safety, bias, and toxicity: No analysis of demographic, cultural, or content biases; no safety red-teaming or harmful content assessments, especially for text-to-image/video generation.
- Reproducibility and implementation specifics: Critical hyperparameters (exact p(t), EMA decay, γ, l/k selection), training data composition/licensing, and code/model release status are unclear, hindering independent verification.
- Alternative explanations for gains: It remains uncertain how much of the improvement stems from Dual-Timestep Scheduling alone versus the representation loss, across modalities and scales; more granular, modality-specific ablations are needed.
- Scalability beyond 4B and across hardware: Only a limited large-scale demonstration is shown (typography figure); systematic scaling curves at 2–8B+ parameters, memory–latency trade-offs, and hardware efficiency (e.g., tensor parallelism effects) are not provided.
- Compatibility with other training paradigms: Interactions with distillation (e.g., one-step/teacher-student generators), RL fine-tuning, or reinforcement-driven goal conditioning are unexplored.
- Extensions to additional modalities and tasks: Applicability to 3D (NeRF/mesh), audio-visual speech, text generation, or non-perceptual modalities (e.g., tabular/time-series) is untested; design adaptations for these cases remain open.
Practical Applications
Immediate Applications
These applications can be deployed with current generative modeling stacks that use flow/diffusion transformers and latent autoencoders.
- Industry (Software/Media/Advertising): Faster, cheaper training of image generators
- Use case: Replace external-representation alignment (e.g., REPA/DINO) with Self-Flow to cut time-to-quality (~2.8× faster convergence on T2I) and improve FID/CLIP scores without external encoders.
- Tools/workflow: Add Dual-Timestep Scheduling (two timesteps per batch; masking ratio ≤ 0.5), EMA teacher pass, and cosine feature alignment; keep standard flow loss and sampler.
- Assumptions/dependencies: Availability of flow/DiT-style backbone (e.g., FLUX.2, SiT-XL), autoencoder (e.g., SD VAE), and moderate tuning of noise scheduler p(t) and γ (alignment weight); compute overhead of a second forward pass is acceptable.
- Industry (Video, Entertainment, Social, e-Commerce): Higher-quality video generation with better temporal consistency
- Use case: Train or fine-tune T2V models with Self-Flow to reduce FVD and per-frame FID and suppress temporal artifacts (e.g., flicker, missing limbs).
- Tools/workflow: Plug Self-Flow into existing video latents (Wan2.2 or similar), maintain mixed-noise student vs. cleaner EMA teacher features at training time.
- Assumptions/dependencies: Video autoencoder availability; sufficient video-text data; scheduler tuning matters more in video.
- Industry (Audio/Music/Podcasts/Gaming): Cleaner T2A audio generation
- Use case: Produce soundtracks, sound effects, or audio beds with improved FAD metrics across CLAP variants by training with Self-Flow instead of external encoders (e.g., MERT).
- Tools/workflow: Use audio autoencoders (e.g., Songbloom) with Self-Flow; retain standard inference ODE.
- Assumptions/dependencies: Paired text–audio data; proper pre-emphasis and loudness normalization in pipeline.
- Industry (Branding/Design/Marketing): More reliable typography in image generation
- Use case: Generate product shots, posters, and ads with accurate brand text and slogans; Self-Flow improves text rendering fidelity vs standard flow matching.
- Tools/workflow: Fine-tune on brand fonts/assets with Self-Flow; evaluate with CLIP/text-rendering benchmarks.
- Assumptions/dependencies: Data licenses for brand assets; prompt engineering and font-aware augmentations help.
- Industry (Robotics): Better vision-action models for embodied tasks from limited data
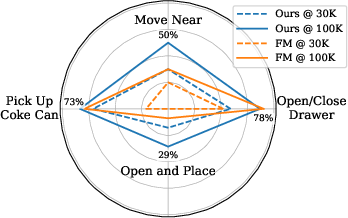
- Use case: Improve success rates on complex, sequential tasks (e.g., Move Near, Open and Place) by initializing video-action models with Self-Flow and fine-tuning on RT-1-like datasets; useful for QA, pick-and-place, and warehouse robotics.
- Tools/workflow: Joint video-action prediction with mixed-noise training; initialize from video-weighted mixed-modality Self-Flow model.
- Assumptions/dependencies: Paired video–action logs; simulator or real data; controller integration required for deployment.
- Industry/Academia (R&D Efficiency): Predictable scaling without external encoder bottlenecks
- Use case: Scale models/compute and expect consistent gains; avoid paradoxical degradation observed when scaling external encoders (e.g., DINOv3-H+).
- Tools/workflow: Use Self-Flow for all scales (290M–1B+) to achieve better performance per FLOP; replace external feature teachers with EMA teacher inside the model.
- Assumptions/dependencies: Training infra to handle EMA; monitoring for feature norm stability (cosine similarity recommended).
- Academia (Representation Learning & Multimodal Research): Unified, encoder-free multimodal training
- Use case: Train a single backbone across images, video, and audio with modality-specific weights; see consistent cross-modality improvements without external encoders.
- Tools/workflow: Mixed-modality training with weighted losses wI, wV, wA; analyze representations with linear probes to validate semantic gains.
- Assumptions/dependencies: Modality-specific autoencoders and datasets; careful weighting to avoid modality underfitting.
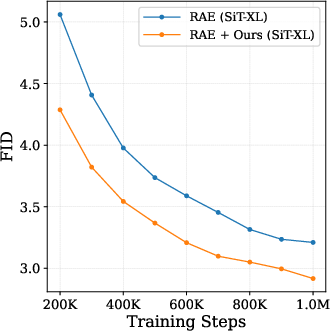
- Industry/Academia (Autoencoders/Compression): Enhance performance in representation autoencoders (RAE)
- Use case: Improve quality and training dynamics when using semantic latents (RAE + Self-Flow improves FID vs. RAE alone).
- Tools/workflow: Apply Dual-Timestep Scheduling and self-supervised alignment in latent space during generator training.
- Assumptions/dependencies: Access to RAE/semantic-latent autoencoder and compatible latent resolution.
- Industry (Synthetic Data Generation for CV/NLP/ASR): Higher-quality, semantically rich synthetic datasets
- Use case: Generate more coherent images, videos, and audio for pretraining/fine-tuning downstream models (e.g., OCR, action recognition, ASR) with stronger semantics learned internally.
- Tools/workflow: Use Self-Flow models to produce labeled synthetic corpora; quality-check via CLIP/FID/FAD.
- Assumptions/dependencies: Labeling via prompts or weak/auto-labelers; dataset governance.
- Policy/Compliance (Licensing & Supply Chain): Reduced reliance on third-party encoders
- Use case: Avoid licensing/usage restrictions tied to external encoders (e.g., DINO/SigLIP), simplifying compliance and supply-chain risk.
- Tools/workflow: Self-contained training with EMA teacher; internal model cards reflect fewer third-party assets.
- Assumptions/dependencies: Legal review still required for training data; maintain provenance logs.
- Policy/Sustainability (Compute Efficiency): Lower energy and cost via faster convergence
- Use case: Reduce compute budgets and emissions for model updates and domain adaptation; align with sustainability goals.
- Tools/workflow: Track wall-clock to target FID/FVD/FAD; report CO2e per checkpoint for transparency.
- Assumptions/dependencies: Marginal extra cost from teacher pass balanced by faster training; relies on robust infra telemetry.
- Daily Life (Creative Apps/Prosumer Tools): Better on-device or small-cloud generative quality
- Use case: Deploy smaller models (e.g., ~625M) with quality competitive to larger externally aligned models (1B REPA), enabling mobile or cost-sensitive deployments for image/video/audio creation.
- Tools/workflow: Distill Self-Flow checkpoints to edge-friendly formats; leverage quantization/pruning.
- Assumptions/dependencies: Hardware constraints; careful scheduler and guidance settings for resource-limited inference.
Long-Term Applications
These opportunities require additional research, scaling, data, or integration before broad deployment.
- Industry/Robotics (Household/Industrial Autonomy): World-model-based planning with unified semantics
- Use case: Combine Self-Flow’s learned representations with model-based planning to achieve robust multi-step task execution in the real world.
- Tools/workflow: Joint video-action(-audio) modeling plus planning modules; sim2real pipelines leveraging temporally consistent video generation.
- Assumptions/dependencies: Large-scale embodied datasets; robust control; safety and failure-recovery systems.
- Industry (Multimodal Assistants): Unified text-to-image/video/audio co-generation with tighter cross-modal coherence
- Use case: Produce synchronized video+audio (and potentially captions or actions) from a single prompt with shared internal semantics.
- Tools/workflow: Extend mixed-modality Self-Flow to joint co-generation (e.g., storyboard + soundtrack); add cross-modal constraints at training time.
- Assumptions/dependencies: Paired multimodal corpora; alignment metrics and loss design for synchronization.
- Healthcare (Imaging & Audio Diagnostics): Data augmentation and simulation with improved semantic fidelity
- Use case: Create synthetic but semantically coherent medical images and audio (e.g., heart/lung sounds) for training diagnostic models.
- Tools/workflow: Domain-specific autoencoders, regulatory auditing, bias checks; Self-Flow training on de-identified datasets.
- Assumptions/dependencies: Strict compliance (HIPAA/GDPR), clinical validation, bias and safety assessments.
- Education (Content Generation & Accessibility): Accurate text-in-image and narrated video generation
- Use case: Generate lecture visuals with precise in-image text and consistent tutorial videos with aligned narration for multilingual instruction.
- Tools/workflow: Multilingual prompt pipelines; joint T2V+T2A generation; QA with OCR and ASR evaluations.
- Assumptions/dependencies: Curriculum-aligned datasets; content safety and factuality screening.
- Finance/Retail (Product Visualization & Compliance): Trusted creatives with audit-friendly pipelines
- Use case: Generate ads and product visuals where accurate text rendering and brand semantics are mandatory; maintain traceable, inward-facing representation learning (no external encoders).
- Tools/workflow: Approval workflows with automated OCR/brand-checkers; versioned Self-Flow checkpoints; watermarking/signature integration.
- Assumptions/dependencies: Legal oversight on claims; watermarking standards adoption.
- Security/Integrity (Deepfake Mitigation Research): Standardized internal-representation training for provenance
- Use case: Study how self-supervised internal features affect detectability and integrate cryptographic watermarks that survive post-processing.
- Tools/workflow: Co-train watermark heads with Self-Flow; benchmark detectability under transformations.
- Assumptions/dependencies: Community standards; collaboration with platform providers.
- Energy/Compute (Greener Foundation Models): Systematic scaling with better returns
- Use case: Build next-gen multimodal foundation models that follow expected scaling laws without external alignment bottlenecks, optimizing compute per unit quality.
- Tools/workflow: Training planners that model FLOPs→quality curves for Self-Flow; automated scheduler/γ tuning services.
- Assumptions/dependencies: Extensive pretraining compute; reproducible evaluation suites.
- Tooling Ecosystem (Open Training Stacks): Plugins and SDKs for self-supervised flow matching
- Use case: Off-the-shelf “Self-Flow” modules for PyTorch/JAX frameworks to retrofit existing generative pipelines in industry labs and academia.
- Tools/workflow: Libraries offering Dual-Timestep Scheduling, EMA teacher management, projection heads, and evaluation dashboards.
- Assumptions/dependencies: Reference implementations and benchmarks; community adoption and maintenance.
- Public Policy (Model Procurement & Governance): Guidance favoring self-contained generative training
- Use case: Procurement policies that incentivize models trained without opaque third-party encoders to improve supply-chain transparency and licensing clarity.
- Tools/workflow: Model cards highlighting external dependency reduction; audits focusing on internal representation learning.
- Assumptions/dependencies: Consensus on transparency metrics; alignment with international AI governance frameworks.
Cross-cutting assumptions and dependencies
- Data quality and licensing remain central; Self-Flow removes encoder dependencies but not dataset obligations.
- A second forward pass (EMA teacher) adds training cost; overall savings depend on convergence gains and infra efficiency.
- Optimal performance requires tuning of noise scheduler p(t), masking ratio, and representation loss weight γ; defaults may be adequate but task-specific tuning helps.
- Modality-specific autoencoders must be available and performant; latent resolution/rescaling choices influence outcomes.
- Safety, watermarking, and provenance mechanisms should be integrated for high-stakes domains (healthcare, finance, political content).
Glossary
- Autoencoder: A neural network that encodes data into a latent representation and decodes it back, used here as the input/output space for generative models. "our method is agnostic to autoencoder choice: we demonstrate consistent improvements across SD~\cite{ldm}, FLUX.2~\cite{bfl2025representation}, Wan2.2~\cite{wan2025}, Songbloom~\cite{yang2025songbloom}, and representation autoencoders~\cite{rae} (Sec.~\ref{sec:experiments})."
- CLIP: A contrastive vision–LLM used for zero-shot evaluation and alignment across modalities. "CLIP~\citep{clip} and SigLIP~\citep{siglip,siglip2} extend this paradigm to vision-language alignment, enabling zero-shot transfer across tasks."
- Cosine similarity: A feature alignment metric measuring the cosine of the angle between vectors. "using cosine similarity as the alignment metric:"
- Depth Anything 3: A pretrained depth estimation model used as an external encoder baseline for video alignment. "w/ Depth Anything 3"
- Diffusion forcing: A training variant that samples independent noise per token, which can create a train–inference mismatch. "Diffusion forcing and full masking create a train-inference gap which degrades generations."
- DINOv2: A family of self-supervised vision encoders commonly used for external feature alignment in generative training. "Alignment methods achieve optimal performance when aligning with an external pretrained encoder, with DINOv2-B~\citep{dinov2} being the predominant choice~\citep{repa,repae,irepa}."
- DINOv3-H+: A stronger DINO variant whose use as an external teacher is observed to degrade generative performance. "DINOv2-B, the smallest and weakest variant, achieves the best FID, while the most capable model, DINOv3-H+, performs the worst."
- Dual-Timestep Scheduling: The proposed scheme that applies two different noise levels across tokens to create information asymmetry for self-supervision. "Our key mechanism, Dual-Timestep Scheduling, applies heterogeneous noise levels across tokens, creating an information asymmetry that forces the model to infer missing information from corrupted inputs."
- EMA teacher network: A teacher model updated via exponential moving average of student parameters to provide stable targets. "an EMA teacher network "
- External alignment: Aligning the generative model’s internal features to a frozen, external encoder’s representations. "external alignment fails to uphold expected scaling laws"
- FAD (Fréchet Audio Distance): A distributional metric for evaluating audio generation quality in an embedding space. "Our method achieves the best FAD scores across all CLAP variants, while external alignment with MERT provides no benefit over vanilla flow matching."
- FD-DINOv2: Fréchet distance computed in the feature space of DINOv2, used to assess alignment with DINO representations. "T2I FD-DINOv2"
- Feature alignment: Encouraging the generative model’s internal features to match target features (from a teacher) during training. "Recent works~\citep{repa,repae,sra} demonstrate that flow matching training benefits substantially from feature alignment."
- FID (Fréchet Inception Distance): A standard metric for image generation quality comparing distributions of features from a pretrained network. "our method achieves the best FID (3.61) among all methods"
- FLUX.2: A transformer-based backbone used for image, video, and audio experiments in this work. "All other experiments use the FLUX.2~\cite{bfl2025representation} transformer with domain-specific autoencoders."
- Flow matching: A generative training objective that learns a velocity field to transport noise to data along a probability path. "In standard flow matching, uniform noise is applied to all tokens"
- FVD (Fréchet Video Distance): A metric measuring video generation quality by comparing distributions in a video feature space. "achieving the best FVD (47.81)"
- Heterogeneously-noised input: An input where different tokens are corrupted with different noise levels. "one with the mixed, heterogeneously-noised input"
- Information asymmetry: A setup where some tokens are noised more heavily than others so the model must infer missing information from cleaner context. "creating an information asymmetry that forces the model to infer missing information from corrupted inputs."
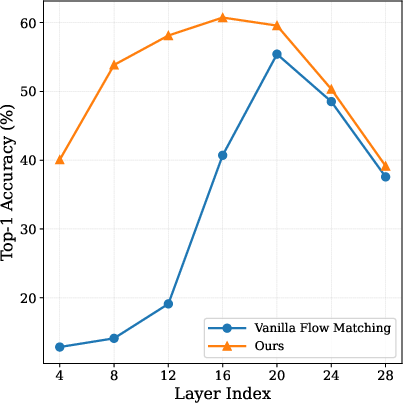
- Linear probing: Evaluating learned representations by training a simple linear classifier on frozen features. "Linear probing confirms that our method learns stronger representations than standard flow matching."
- Masking ratio: The fraction of tokens assigned to the higher-noise subset in Dual-Timestep Scheduling. "with a masking ratio ."
- Momentum-updated teacher: A teacher network updated via momentum (EMA) whose targets the student matches. "DINO variants~\citep{dino,dinov2,dinov3} train a student network to match a momentum-updated teacher."
- Noise scheduler: The distribution over timesteps used to sample noise levels during training, which impacts masking/inference behavior. "the noise scheduler requires tuning as it determines masking behavior."
- Ordinary differential equation (ODE): The differential equation integrated at inference to transform noise into data under the learned velocity field. "At inference, generation proceeds by solving the ordinary differential equation (ODE) "
- Probability path: A continuous-time interpolation between noise and data distributions along which the model learns transport. "modeling a continuous-time probability path."
- Projection head: A small MLP applied to features before computing the alignment loss. "an MLP projection head."
- Rectified flows: A specific flow matching formulation using straight-line trajectories between noise and data. "Our approach builds on rectified flows \citep{liu2022flow, albergo2023buildingnormalizingflowsstochastic, fmgen}"
- Representation alignment: Training with an auxiliary objective to align the model’s features to teacher/target representations. "our representation alignment objective is given by using the teacher network as the representation network"
- Representation autoencoder (RAE): An autoencoder trained to produce semantic latents for generation rather than pure reconstruction latents. "our method improves the performance of RAE~\citep{rae}, demonstrating our method's robustness to autoencoder choice."
- Self-Flow: The proposed self-supervised flow matching framework that jointly learns representations and generation. "We introduce Self-Flow: a self-supervised flow matching paradigm that integrates representation learning within the generative framework."
- SigLIP 2: A vision–LLM used as an external encoder baseline for text–image alignment. "aligning text-to-image models with SigLIP 2~\citep{siglip2} performs worse than DINOv2~\citep{dinov2}"
- sFID (sliced Fréchet Inception Distance): A variant of FID computed with sliced Wasserstein approximations for efficiency/sensitivity. "sFID"
- Student network: The model being trained to both denoise and match teacher features in the self-supervised objective. "a student network that learns from heterogeneously noised inputs "
- Timestep sampling distribution: The distribution over noise levels from which timesteps are drawn during training. "where denotes the timestep sampling distribution"
- V-JEPA2: A video self-supervised model used as an external encoder baseline for alignment in video experiments. "w/ V-JEPA2"
- Velocity field: The vector field giving the instantaneous direction to move samples along the probability path from noise to data. "The velocity field along this path is given by "
- Wan2.2: A video autoencoder used as the latent space for text-to-video experiments. "for text-to-video (T2V), the Wan2.2~\cite{wan2025} autoencoder with 6M videos"
- Zero-shot transfer: The ability to apply a model to new tasks without task-specific fine-tuning. "enabling zero-shot transfer across tasks."
Collections
Sign up for free to add this paper to one or more collections.