OneFlow: Concurrent Mixed-Modal and Interleaved Generation with Edit Flows
Abstract: We present OneFlow, the first non-autoregressive multimodal model that enables variable-length and concurrent mixed-modal generation. Unlike autoregressive models that enforce rigid causal ordering between text and image generation, OneFlow combines an insertion-based Edit Flow for discrete text tokens with Flow Matching for image latents. OneFlow enables concurrent text-image synthesis with hierarchical sampling that prioritizes content over grammar. Through controlled experiments across model sizes from 1B to 8B, we demonstrate that OneFlow outperforms autoregressive baselines on both generation and understanding tasks while using up to 50% fewer training FLOPs. OneFlow surpasses both autoregressive and diffusion-based approaches while unlocking new capabilities for concurrent generation, iterative refinement, and natural reasoning-like generation.
















Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces OneFlow, a new kind of AI model that can create text and images at the same time, in the same sequence, and in any order. Unlike most models that write or draw step-by-step in a fixed order, OneFlow can insert words and pictures wherever they’re needed and refine them together. The goal is to make AI generation more flexible, faster to train, and better at understanding and following complex prompts.
Key Questions the Paper Tries to Answer
To make their case, the authors test OneFlow against strong baselines and ask simple questions:
- Does OneFlow scale better (get stronger as it gets bigger) than standard models?
- Is training on mixed text-and-image generation better than training on them separately?
- Does OneFlow show “reasoning-like” behavior when answering visual questions?
- How does OneFlow compare to other top models in image generation and image understanding?
- What new abilities does OneFlow unlock that older methods couldn’t do?
How OneFlow Works (Explained Simply)
Think of OneFlow like a creative assistant that’s drafting a comic page: it can write the story and draw the pictures at the same time, adding and polishing pieces in whatever order makes sense.
Here are the key ideas:
Non-autoregressive generation (not strictly one-by-one)
- Many models are “autoregressive,” which means they must generate the next token (word or image piece) in order, one at a time, like typing a sentence without ever going back to insert a new word.
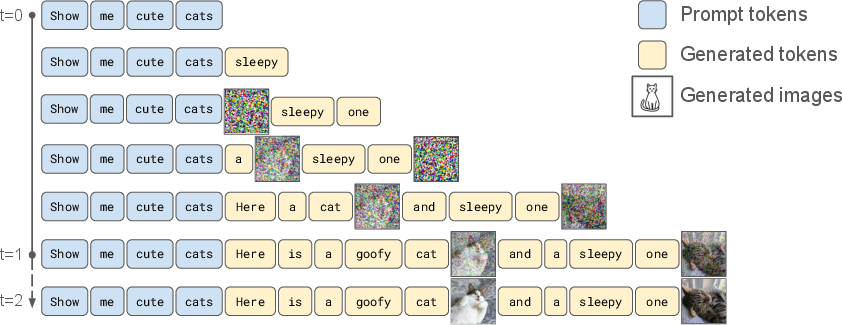
- OneFlow is “non-autoregressive,” meaning it can insert something (a word or an image) anywhere in the sequence at any time. It’s like editing a document while you write—adding sentences and pictures in the middle when inspiration strikes.
Edit Flows for text (adding the right words)
- For text, OneFlow uses “Edit Flows,” which you can imagine as an “insertion engine.”
- It starts with an empty (or very rough) version and keeps inserting the most useful words where they belong.
- First, it figures out where something is missing (like “there should be a noun here”), then it decides which specific word to add. This helps it focus on content first and grammar later, like sketching the big ideas before polishing the details.
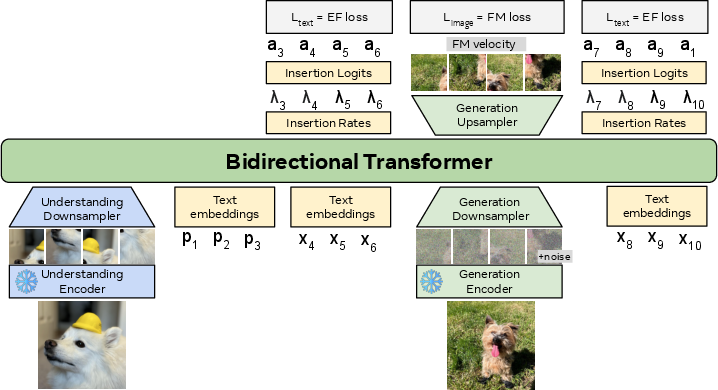
Flow Matching for images (cleaning up noise into a picture)
- For images, OneFlow uses “Flow Matching,” which is like starting with a blurry static noise image and steadily cleaning it until it becomes a clear picture.
- When the model decides an image should be inserted (based on the text that’s being written), it drops an “image placeholder” into the sequence and begins refining it from noise to a final image.
- This happens at the same time as the text is being edited, so the description and the drawing help shape each other.
Interleaved mixed-modal generation (words and pictures together)
- OneFlow treats text tokens and image latents as parts of one long sequence.
- If the model inserts an image later in the process, that image starts with its own timer (its own refinement schedule) so it can “catch up.”
- This lets OneFlow generate any number of images within a single answer and refine them alongside the text, rather than finishing one before starting the other.
- Big idea: text and images influence each other live, during generation, instead of being strictly separated by order.
Main Findings and Why They Matter
The authors run thorough tests across different model sizes (from about 1 billion to 8 billion parameters) and training setups. Here’s what they found:
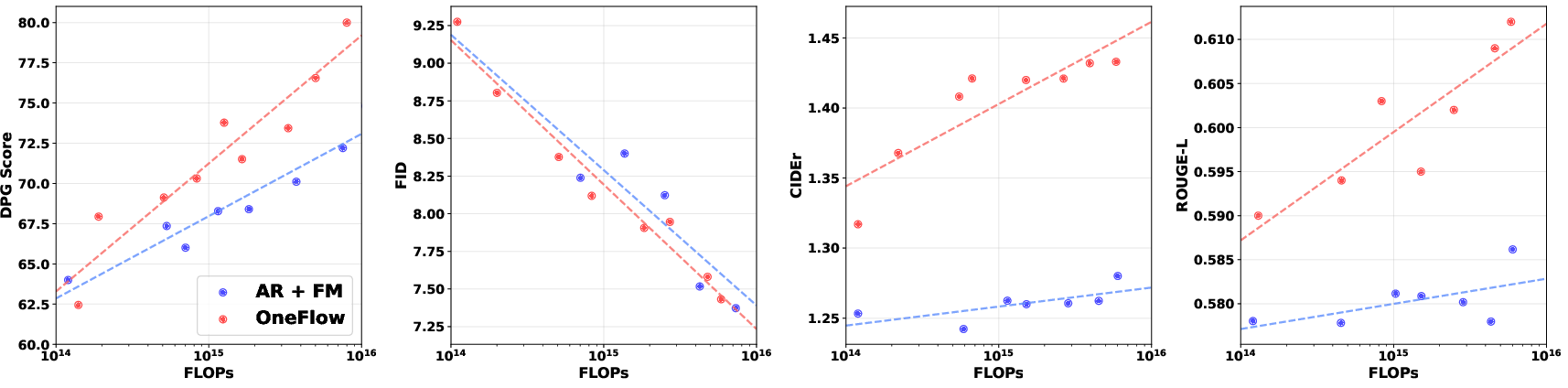
1) Better scaling and less compute
- OneFlow often beats strong autoregressive baselines as the model size and data grow.
- It needs up to about 50% fewer training FLOPs (a measure of computing effort) to reach similar or better performance on many tasks. In simple terms: it trains more efficiently.
Why this matters: High-quality models are expensive to train. Saving half the compute while improving performance is a big deal.
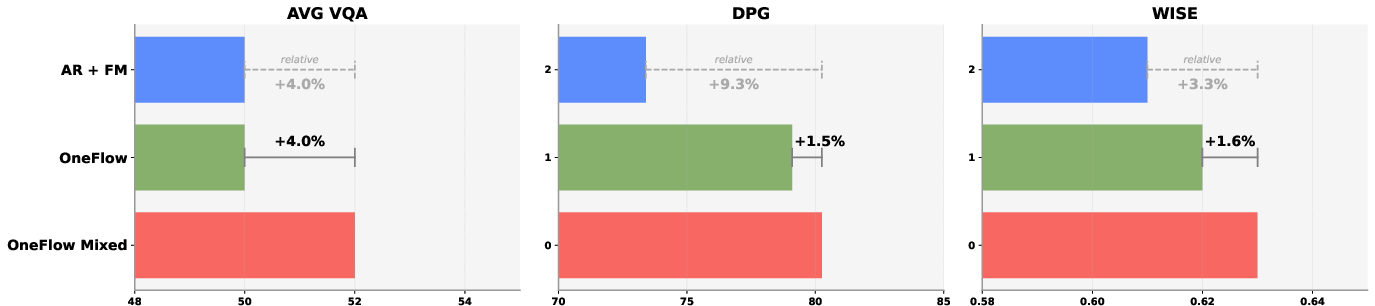
2) Mixed-modal training helps
- Training the model to generate text and images together (instead of separately) improves visual question answering (VQA) by about 4% and slightly improves image generation quality.
- This suggests that learning both modes at the same time strengthens the model’s understanding of how words relate to pictures.
Why this matters: Better synergy between text and images means stronger prompt following and more accurate outputs.
3) Natural “reasoning-like” generation
- When asked visual questions (like “Is there a snowboard in the image? Explain why.”), OneFlow tends to insert and refine the “hard” parts later, like a human building a chain of thought: it identifies important visual details first, then finalizes the answer.
- It does this without special “think step-by-step” tricks. The behavior emerges naturally from its hierarchical, insert-then-refine process.
Why this matters: It hints that careful generation order (content first, details later) can produce smarter answers, even without traditional step-by-step decoding.
4) Strong results on both generation and understanding
- On image generation, OneFlow matches or beats top models on metrics like FID (lower is better, meaning more realistic images) and scores that measure how well the image matches the prompt (like CLIPScore and DPG-Bench).
- On image captioning and VQA, OneFlow often outperforms strong baselines, especially on real-world visual tasks.
Why this matters: OneFlow is competitive or better at both making images and understanding them, with the added benefit of generating both together.
5) New capabilities that older methods lacked
- OneFlow can generate a variable number of images inside a single text response and let the text depend on the images (and vice versa) while everything is being created.
- It supports concurrent generation, iterative editing, and interleaving text and pictures in flexible ways—useful for creative tools, educational apps, and assistants that show their work.
Why this matters: This opens doors for interactive experiences where the AI can draft text and visuals simultaneously, refine them together, and adjust to user feedback mid-generation.
Implications and Potential Impact
- More creative, interactive AI: Imagine asking for a story with three pictures, and the AI writes and illustrates it at the same time, adjusting each panel as the plot evolves.
- Faster training and better scaling: Lower compute costs and better performance make it more practical to build bigger, better multimodal models.
- Improved reasoning in vision tasks: The “content-first, details-later” approach may lead to clearer, more trustworthy answers in tasks like VQA, tutoring, and data visualization.
- Flexible multimodal workflows: Because OneFlow can insert images anywhere and refine both text and images together, it fits naturally into editing tools, design apps, and any setting where words and visuals must be tightly aligned.
In short, OneFlow shows that letting text and images be created together—not one strictly after the other—can make AI both smarter and more useful, while also reducing training costs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to enable concrete follow-up by future researchers.
- Theoretical consistency of the “time-independent” insertion parameterization: the model omits feeding and drops the factor; provide proofs of consistency, convergence, and bias/variance impacts under these deviations from Edit Flows theory.
- Formal analysis of the interleaved time schedule: rigorously derive the joint likelihood for mixed-modal generation with and ; quantify induced biases and variance in insertion times, and compare against alternative schedules.
- Sensitivity to the deletion scheduler : beyond a brief test, systematically study performance sensitivity to scheduler shape, learnable schedulers, and data-dependent schedules (e.g., content-conditioned ).
- Ordering vs. bag-of-tokens prediction: models sets of missing tokens without explicit ordering; measure impacts on syntactic coherence, grammar, and discourse structure; explore heads that jointly predict counts and ordered token lists.
- Captioning and language fluency limitations: the text notes a gap vs AR in captioning; characterize when AR is superior, diagnose causes (e.g., bag-of-tokens, lack of time conditioning), and propose remedies (ordering heads, hybrid decoding).
- Quantitative evaluation of interleaved multi-image generation: define metrics for cross-modal dependency and interleaved coherence (e.g., image-text mutual constraints during generation) and benchmark variable-number-of-images scenarios.
- Sequence length and memory constraints: clarify how long sequences are handled when inserting high-dimensional image latents; analyze worst-case complexity, memory usage, truncation strategies, and failure modes with many images or long text.
- Fixed image latent dimensionality (): study support for variable resolution, aspect ratio, and dynamic latent lengths; evaluate training/inference schedules for multi-resolution generation.
- Inference efficiency and latency: report wall-clock speed, throughput, and GPU memory vs AR and masked diffusion at matched quality; quantify gains from non-autoregressive concurrent generation.
- User-controllable image count: provide mechanisms and evaluation for constraining or targeting the number of images inserted at inference; measure robustness to over/under-insertion.
- Zero-inflated count modeling adequacy: validate the + Poisson model for missing-token counts; test over-dispersed alternatives (e.g., Negative Binomial, hurdle models), and quantify calibration and sampling accuracy.
- Sampling strategy ablations: systematically compare sampling based on expectation vs the proposed π-first strategy across tasks and scales; analyze sensitivity to step-size and adaptive schedulers.
- Guidance and solver hyperparameters: OneFlow uses entropy-rectifying guidance (scale 5.0) and 50 FM steps; match baselines on solver/guidance and study the quality-speed Pareto front and robustness across step budgets.
- Encoder/adapter confounds: disentangle contributions from dual encoders (SigLIP2 for understanding, SD3 VAE for generation) and U-Net adapters; provide ablations with alternative encoders/VAEs and without adapters.
- Mixed-modal pretraining regime: the 0.2 mixed probability is not explored; sweep concurrent-generation ratios, curricula, and scheduling to find optimal regimes and generalization properties.
- Statistical reliability: report seeds, error bars, and statistical significance for improvements (e.g., 4% VQA, 1.5% image gen) across scales; assess variance and reproducibility under data resampling.
- Human evaluation of interleaved coherence and reasoning: complement automatic metrics with human judgments on reasoning quality, interleaving fidelity, and text-image mutual consistency.
- Safety, bias, and robustness: beyond POPE and limited WISE cultural metrics, assess bias, toxicity, and adversarial robustness under mixed-modal concurrent generation; study whether concurrency reduces or amplifies hallucinations.
- Edit operations beyond insertion: investigate deletions, substitutions, and reordering within Edit Flows for text and cross-modal edits; evaluate iterative refinement/editing tasks and interactive user corrections.
- Failure mode characterization: analyze duplicate insertions, looping behaviors, incoherent image-text bindings, and termination errors; build detectors and mitigation strategies (e.g., stopping criteria beyond thresholds).
- Grammar vs content trade-offs: the claim that sampling “prioritizes content over grammar” is anecdotal; design metrics to quantify grammaticality vs semantic coverage and explore explicit control knobs.
- Large-scale scaling laws: extend results beyond 8B parameters and across data regimes; verify FLOP parity advantages at ≥20B scales and test whether scaling trends persist.
- Generalization to other modalities: assess extension to audio, video, or spatiotemporal streams; derive interleaved schedules for non-image continuous modalities and evaluate architectural changes.
- Distribution of inserted images during training: verify that training-time deletion/insertion distribution matches real multi-image data distributions; explore targeted rebalancing to avoid bias toward single-image patterns.
- Data curation transparency: provide detailed filtering criteria, licensing compositions, quality controls, and contamination checks; evaluate OOD generalization and domain robustness (e.g., charts/OCR-heavy domains).
- Reasoning dynamics measurement: the paper argues emergent hierarchical reasoning without AR decoding; measure token “difficulty ordering,” intermediate latent plans, and causal pathways using process-tracing techniques.
- Inference controllability and APIs: specify interfaces for controlling interleaving, schedules, and insertion policies at inference; evaluate user experience and reliability in interactive applications.
Practical Applications
Immediate Applications
The following items are deployable now, leveraging OneFlow’s concurrent mixed-modal generation, insertion-based Edit Flows for text, Flow Matching for images, hierarchical sampling, and demonstrated improvements in VQA, captioning, and prompt alignment with reduced training FLOPs.
- Content authoring with live interleaved media (Software, Media/Marketing)
- Tools/products/workflows: Document editors and CMS plugins that draft narrative text while inserting generated images (
<|image|>) in place, concurrently refining both; outline-first workflows that prioritize content before grammar; ad creative generators that maintain prompt fidelity (higher DPG scores). - Assumptions/dependencies: Production-grade VAE/U-Net pipelines; guidance tuning (e.g., Euler + ERG); guardrails for brand safety and IP; latency acceptable for 512×512 image sampling.
- Tools/products/workflows: Document editors and CMS plugins that draft narrative text while inserting generated images (
- E-commerce listing assistant with concurrent media (Retail)
- Tools/products/workflows: Unified pipeline that generates titles, descriptions, and product shots together; variant images (color, context) inserted during drafting; A/B creatives, with prompt-alignment metrics (CLIPScore/DPG) for automatic selection.
- Assumptions/dependencies: Catalog data quality; content moderation; image licensing; human-in-the-loop review for compliance.
- Multimodal customer support copilot (Software, Telecom)
- Tools/products/workflows: Assistants that interpret user-submitted photos/screenshots and answer questions while inserting clarifying images (e.g., annotated callouts) and text explanations in one pass; implicit hierarchical reasoning improves explain-then-answer behavior.
- Assumptions/dependencies: Data privacy, secure handling of user media; robust OCR/Chart tasks for documents; specialized finetuning for domain FAQs.
- Accessibility enhancement for documents (Public sector, Education)
- Tools/products/workflows: Auto-generation of alt-text, captions, and illustrative figures for public communications; concurrent interleaving ensures images and explanations co-evolve, improving alignment.
- Assumptions/dependencies: Accessibility standards compliance (WCAG); cultural sensitivity (WISE benchmarks); review workflows.
- Instructional content with step images (Education)
- Tools/products/workflows: Tutorial generators (recipes, DIY, science labs) that concurrently produce step-by-step text and images (e.g., tool placement, intermediate states), improving clarity without Chain-of-Thought prompting.
- Assumptions/dependencies: Domain-specific datasets; user safety checks for hazardous instructions; clear usage licenses for generated media.
- Visual QA and captioning APIs (Software)
- Tools/products/workflows: OneFlow-backed inference endpoints for VQA and captioning with improved performance over AR baselines; outputs include explanations via hierarchical sampling without explicit CoT; better real-world perception tasks.
- Assumptions/dependencies: Serving infrastructure for 1B–8B models; GPU memory for mixed-modal sequences; consistency in encoders (e.g., SigLIP2 for understanding, SD3 VAE for generation).
- Leaner multimodal pretraining for labs (Academia, Industry R&D)
- Tools/products/workflows: Training pipelines adopting deletion schedules (linear
κ_t) to save up to ~50% text FLOPs, mixing concurrent generation (20%) to improve downstream VQA and generation scores; parity FLOP ratios guiding budget decisions. - Assumptions/dependencies: Comparable datasets (e.g., CC12M, YFCC, licensed data); reproducible schedules and metrics; integration with FlashAttention-style FLOP accounting.
- Tools/products/workflows: Training pipelines adopting deletion schedules (linear
- Synthetic dataset augmentation with interleaved assets (ML/AI MLOps)
- Tools/products/workflows: Generation of paired captions and images with controllable prompt alignment for training and evaluation; insertion-based text generation enables variable-length packaging (e.g., multiple images per sample).
- Assumptions/dependencies: Quality control (DPG/FID/CLIP); deduplication; labeling policies; watermarking for provenance.
- Marketing and social media post creation at scale (Media/Marketing)
- Tools/products/workflows: Campaign tools that concurrently generate copy and visuals with higher prompt fidelity and lower training cost; iterative refinement loops guided by hierarchical sampling.
- Assumptions/dependencies: Brand constraints; regulatory compliance; approval workflows.
- Personal assistants for everyday tasks (Daily life)
- Tools/products/workflows: Travel itineraries, room layout suggestions, or “how-to” guides with illustrative images inserted while drafting text; smartphone apps that answer questions about user-captured photos and generate step images.
- Assumptions/dependencies: On-device quantization or cloud offload; privacy controls; mobile latency constraints.
Long-Term Applications
These items require further research, scaling, engineering, or policy development—e.g., extending OneFlow to more modalities (audio/video), optimizing for low-latency edge deployment, and building robust safety/compliance frameworks.
- Real-time multimodal copilot on edge devices (Software, Consumer Electronics)
- Tools/products/workflows: On-device assistants that interpret camera feeds and generate explanations/visualizations concurrently, e.g., AR overlays while describing scenes.
- Assumptions/dependencies: Model compression/quantization for 1B-class models; faster image solvers; energy-efficient hardware; robust privacy.
- Robot perception-grounded planning and explanation (Robotics)
- Tools/products/workflows: Planners that jointly produce visual plans (annotated scene images) and textual rationales, using hierarchical sampling to explain step ordering; variable-length sequences support multi-image planning updates.
- Assumptions/dependencies: Integration with control stacks; safety supervision; domain datasets; real-time constraints.
- Scientific reporting with auto-generated figures and captions (Academia, R&D)
- Tools/products/workflows: Systems that draft method sections while inserting schematic figures, experiment diagrams, and captions; iterative refinement across text and images to improve clarity and alignment.
- Assumptions/dependencies: Domain adaptation (STEM, medical); provenance and citation tracking; peer-review alignment; figure ethics.
- Financial and business analytics with co-generated charts and narratives (Finance, Enterprise Software)
- Tools/products/workflows: Report generators that interpret data, produce
ChartQA-grade visualizations, and interleave executive summaries; interactive what-if scenarios with updated visuals and text. - Assumptions/dependencies: Data connectors; correctness guarantees; regulatory reporting guidelines (SOX/MiFID); audit trails.
- Tools/products/workflows: Report generators that interpret data, produce
- Infrastructure inspection and maintenance reports (Energy, Civil Engineering)
- Tools/products/workflows: Field apps that ingest photos of equipment/structures, answer diagnostic questions, and generate annotated images and text recommendations in one pass.
- Assumptions/dependencies: Domain finetuning; safety validation; offline operation; standards compliance.
- Cross-modal creative suites (Design, Media/Entertainment)
- Tools/products/workflows: Collaborative environments where teams co-develop storyboards, scripts, and concept art concurrently; OneFlow’s variable-length insertion enables dynamic addition of frames and revisions.
- Assumptions/dependencies: Rights management; versioning for generated assets; long-context multimodal editing.
- Multimodal education platforms with interactive textbooks (Education)
- Tools/products/workflows: Curriculum tools that dynamically generate lessons, figures, and assessments; implicit reasoning produces explanations before answers, supporting formative feedback.
- Assumptions/dependencies: Alignment with standards; bias/sensitivity reviews; accessibility tooling; classroom device support.
- Policy-aligned content generation and evaluation frameworks (Public policy, Governance)
- Tools/products/workflows: Toolkits for government/NGOs to create accessible materials with alt-text and compliant visuals; evaluation dashboards monitoring hallucination (e.g., POPE) and cultural measures (WISE).
- Assumptions/dependencies: Transparent data sources; watermarking; public-sector procurement standards; content labeling legislation.
- Multi-modality extensions (Audio, Video) under unified Edit/Flow regimes (Academia, Industry R&D)
- Tools/products/workflows: Research prototypes extending insertion-based edits to audio tokens and Flow Matching to video latents, enabling concurrent timeline-aware generation (e.g., interleaving narration with video frames).
- Assumptions/dependencies: New schedulers for temporal modalities; scalable autoencoders; larger compute; benchmarking suites.
- Sustainable AI training initiatives (Industry R&D, Policy)
- Tools/products/workflows: Programs leveraging OneFlow’s reduced text FLOPs and better scaling laws to lower energy use; reporting frameworks for parity FLOP ratios; incentives for mixed-modal pretraining to improve utility per watt.
- Assumptions/dependencies: Standardized FLOP/energy accounting; hardware utilization telemetry; policy buy-in.
- Safety, compliance, and provenance pipelines for mixed-modal generation (All sectors)
- Tools/products/workflows: End-to-end pipelines with content filters, cultural sensitivity checks, watermarking, and governance tailored to interleaved sequences (text + images); automated red-teaming for multimodal prompts.
- Assumptions/dependencies: Robust filters across modalities; clear IP/licensing; incident response playbooks; third-party audits.
Notes on feasibility and dependencies across applications:
- Model performance hinges on high-quality, licensed datasets and consistent encoder/decoder stacks (e.g., SigLIP2 for understanding, SD3 VAE for generation).
- Latency and memory constraints are non-trivial for concurrent interleaving; production systems may need batching, caching, and quantization.
- Safety, IP, and accessibility must be first-class: content moderation, watermarking, alt-text, and culturally aware evaluation (WISE) are necessary for responsible deployment.
- Compute savings and scaling benefits depend on the deletion schedule (
κ_t) and mixed-modal training proportion; reproducibility requires stable training pipelines and metrics (FID, CLIPScore, DPG, VQA suites).
Glossary
- Autoencoder: A neural network that compresses data into a latent representation and reconstructs it back, often used to work in lower-dimensional spaces. "we use a pretrained autoencoder to map images into latent space."
- Autoregressive (AR): A generation paradigm that produces outputs sequentially, each conditioned on previously generated tokens. "Autoregressive models can handle interleaved data but require strict sequential generation — each image must be fully completed before text generation can continue, preventing simultaneous cross-modal refinement."
- Bag-of-tokens prediction: A modeling approach that predicts the set (multiset) of missing tokens without enforcing order among them. "Bag-of-tokens prediction (). To determine what token to insert at each position, we make use of the output head "
- Binary cross entropy (BCE): A loss function for binary classification tasks measuring the difference between predicted probabilities and binary labels. "We train π by using a binary cross entropy (BCE) loss to detect if the missing count is zero,"
- BLEU4: An n-gram precision-based metric (with 4-grams) for evaluating text generation quality, commonly used in machine translation and captioning. "BLEU4"
- Bregman divergence: A general class of divergences used to define loss functions derived from convex functions. "The original Edit Flows loss was constructed through a choice of Bregman divergence"
- Chain-of-Thought (CoT): A prompting technique that elicits intermediate reasoning steps before final answers. "without any Chain-of-Thought (CoT) prompting or RL post-training."
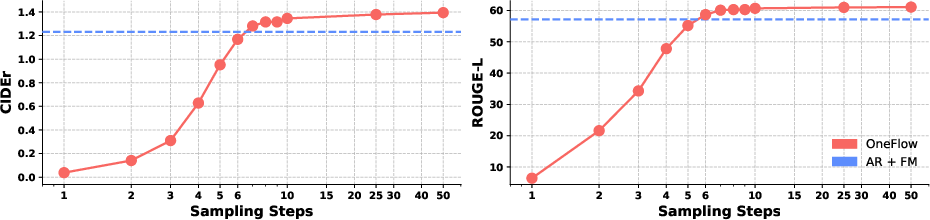
- CIDEr: An image captioning evaluation metric based on TF–IDF-weighted n-gram similarity to consensus references. "For image-to-text caption quality, we report CIDEr and ROUGE."
- CLIPScore: A metric that measures text–image alignment using CLIP embeddings. "To assess prompt alignment, we report CLIPScore~\citep{clipscore} and DPG-Bench~\citep{dpgbench}."
- Continuous-time Markov chain (CTMC): A stochastic process with transitions occurring in continuous time, used here to model edit operations. "Edit Flows uses a continuous-time Markov chain (CTMC) to iteratively refine variable-length discrete sequences."
- DPG-Bench: A benchmark for dense prompt alignment assessing how well generations match fine-grained prompt details. "For text-to-image generation, we report DPG-Bench and FID."
- Dual-encoder setup: An architecture that uses separate encoders (e.g., for image and text) whose outputs are combined downstream. "Unlike Transfusion, we follow Janus-Flow~\citep{janusflow} and adopt a dual-encoder setup."
- Edit Flows: A framework for variable-length sequence generation via edit operations such as insertions. "we make use of the Edit Flows~\citep{havasi2025edit} framework which enables variable-length sequence generation through the use of edit operations."
- Entropy rectifying guidance: A sampling guidance technique that adjusts entropy during generation to improve sample quality or alignment. "we use a first order Euler solver with entropy rectifying guidance~\citep{ifriqi2025entropyrectifyingguidancediffusion}, we set the guidance scale to $5.0$ across $50$ sampling steps."
- Euler solver: A first-order numerical method for integrating ordinary differential equations during generative sampling. "For image generation, we use a first order Euler solver with entropy rectifying guidance"
- FID: Fréchet Inception Distance, a metric that compares the distributions of generated and real images via features from an Inception network. "We evaluate image generation quality using the FID metric~\citep{fid} on the COCO-2014~\citep{coco2014} validation set"
- Flash Attention: An optimized attention algorithm/library that reduces memory and improves speed in transformer training/inference. "We use Flash Attention and follow their FLOP estimation \citep{flashattention}."
- Flow Matching: A training paradigm that learns a velocity field to continuously transform noise into data samples. "OneFlow combines an insertion-based Edit Flow for discrete text tokens with Flow Matching for image latents."
- Flow Matching loss: The mean-squared error objective used to train the velocity field in Flow Matching. "The Flow Matching loss can then be written as"
- FLOPs: Floating point operations, a measure of computational cost for training or inference. "while using up to 50\% fewer training FLOPs."
- Hierarchical sampling: A generation behavior where high-level or easier tokens are produced first, with more uncertain or detailed tokens generated later. "resulting in a natural hierarchical sampling and implicit reasoning where the most difficult answer tokens are generated later."
- Instruction finetuning: Fine-tuning a pretrained model on instruction-following datasets to improve task adherence and response quality. "Our training consists of two main stages: multimodal pretraining and instruction finetuning."
- Interleaved time schedule: A schedule that couples text and image time variables during concurrent generation with insertions, ensuring consistent noise levels across modalities. "We call this the interleaved time schedule, which imposes a distributional dependency between the time values for each image and the text time ."
- Latent space: A lower-dimensional representation space where data (e.g., images) are encoded for efficient modeling and generation. "we use a pretrained autoencoder to map images into latent space."
- Masked diffusion model: A diffusion-based model that uses masking mechanisms to handle discrete/continuous modalities or partial conditioning. "a masked diffusion model based on LLaDA~\citep{nie2025large}."
- Mixed modal pretraining: Pretraining that concurrently generates and learns from multiple modalities (e.g., text and images) rather than sequentially. "In this section, we study the impact of mixed modal pretraining."
- Non-autoregressive: A generation approach that does not rely on strictly sequential token-by-token decoding, enabling parallel or insertion-based generation. "a variable-length non-autoregressive model that can concurrently generate interleaved text and variable number of images"
- Ordinary differential equation (ODE): An equation involving derivatives with respect to a single variable; used here to define continuous-time generation dynamics. "applying a deterministic generation procedure that follows an ordinary differential equation."
- Parity FLOP ratio: A compute-efficiency metric comparing how many FLOPs different models need to reach the same performance. "Parity FLOP Ratio represents the relative amount of OneFlow FLOPs needed to match the final AR + FM performance."
- Poisson distribution: A discrete probability distribution modeling counts, used here to model the number of missing tokens. "can be interpreted as the negative log-likelihood of a Poisson distribution"
- ROUGE: A recall-oriented n-gram overlap metric for evaluating text generation quality. "For image-to-text caption quality, we report CIDEr and ROUGE."
- U-Net adapters: Architectural components that connect or adapt U-Net features to other backbones (e.g., transformers) for multimodal modeling. "Following Transfusion, we use U-Net adapters."
- U-Nets: Encoder–decoder convolutional architectures with skip connections commonly used in image generation and diffusion models. "with additional U-Nets to downsample and upsample between the backbone and autoencoder embedding spaces"
- VAE: Variational Autoencoder, a generative model that learns probabilistic latent representations for data. "an SD3 VAE~\citep{sd3} for generation."
- Velocity field: A function that specifies the instantaneous direction/speed to move a sample in latent space during continuous-time generation. "is a velocity field that determines the direction to transform into a clean sample by ."
- Visual question answering (VQA): A task where a model answers questions about images, requiring joint visual–linguistic reasoning. "Visual question answering. OneFlow generates by simply inserting tokens based on confidence, resulting in a natural hierarchical sampling and implicit reasoning"
- WISE: A benchmark evaluating culturally-aware or knowledge-based image generation/alignment. "Additionally, we include WISE~\citep{wise} cultural to better understand knowledge-based generation."
Collections
Sign up for free to add this paper to one or more collections.

