- The paper introduces a novel two-stage framework that leverages self-supervised pre-training and end-to-end fine-tuning to bypass the complexity of VAEs.
- The methodology employs contrastive and representation consistency losses, achieving state-of-the-art FID scores for both diffusion and consistency models on ImageNet.
- Empirical results demonstrate improved efficiency and scalability, including one-step high-resolution generation that outperforms prior pixel-space approaches.
End-to-End Pixel-Space Generative Modeling via Self-Supervised Pre-Training
Introduction and Motivation
Pixel-space generative models, particularly diffusion and consistency models, have historically lagged behind their latent-space counterparts in both sample quality and computational efficiency. The dominant paradigm leverages pre-trained VAEs to compress the data manifold, enabling more tractable and efficient generative modeling. However, this introduces significant complexity: VAE training is nontrivial, reconstructions are imperfect for out-of-distribution latents, and the overall pipeline requires maintaining and optimizing multiple large models. The paper "Advancing End-to-End Pixel Space Generative Modeling via Self-supervised Pre-training" (2510.12586) addresses these limitations by proposing a two-stage training framework that enables high-fidelity, efficient pixel-space generation without reliance on VAEs or external models.
Methodology
Two-Stage Training Framework
The proposed approach decomposes the generative modeling pipeline into two distinct stages:
- Self-Supervised Pre-Training of the Encoder: The encoder is trained to capture robust visual semantics from images at varying noise levels, using a combination of contrastive and representation consistency losses. The contrastive loss (InfoNCE) encourages semantic alignment between augmented views of clean images, while the representation consistency loss enforces alignment between temporally adjacent points along the same deterministic sampling trajectory (i.e., points connected by the probability flow ODE of the diffusion process).
- End-to-End Fine-Tuning with a Decoder:
After pre-training, the encoder is combined with a randomly initialized decoder and fine-tuned end-to-end for either diffusion or consistency modeling. The decoder is conditioned on the encoder's representations and trained to generate pixels directly, using standard denoising or consistency objectives.
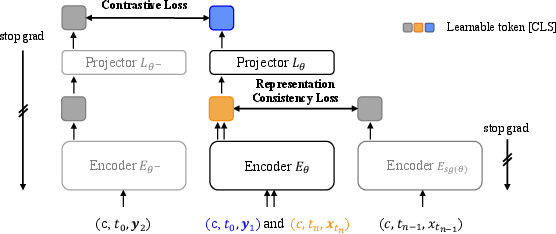
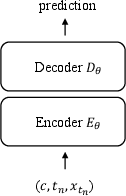
Figure 1: Overview of the two-stage training framework: (Left) self-supervised pre-training with contrastive and representation consistency losses; (Right) end-to-end fine-tuning for generative modeling.
Representation Consistency Learning
The pre-training objective is:
E[InfoNCE(Lθ(Eθ(x1,t0)),Lθ−(Eθ−(x2,t0)))+InfoNCE(Eθ(xtn,tn),Esg(θ)(xtn−1,tn−1))]
where x1,x2 are augmented views, xtn,xtn−1 are temporally adjacent points on the same ODE trajectory, Lθ is a projector, and θ− is an EMA of θ. The temperature parameter τ is annealed to stabilize early training and improve representation quality at high noise levels.
Fine-Tuning and Auxiliary Loss
During fine-tuning, the projector is discarded. The encoder and decoder are trained jointly for the generative task. For consistency models, an auxiliary contrastive loss is introduced between the model output and the clean image, using a frozen copy of the pre-trained encoder. This provides additional supervision and accelerates convergence, especially in the early stages of training.
Empirical Results
Diffusion Models
The EPG (End-to-end Pixel-space Generative) model achieves an FID of 2.04 on ImageNet-256 and 2.35 on ImageNet-512 with only 75 function evaluations (NFE), outperforming all prior pixel-space methods and matching or surpassing leading latent-space models at comparable training cost.
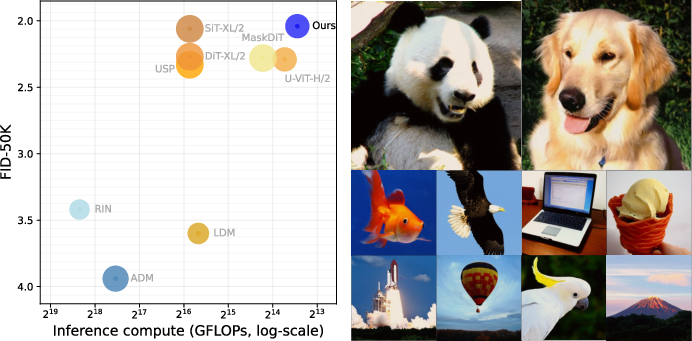
Figure 2: (Left) EPG achieves state-of-the-art generation quality with lower inference cost compared to both pixel-space and latent-space models. (Right) Images generated by the EPG diffusion model.
Consistency Models
The EPG consistency variant achieves an FID of 8.82 on ImageNet-256 in a single sampling step, significantly outperforming latent-space consistency models and prior pixel-space approaches. This is the first demonstration of successful high-resolution, one-step pixel-space generation without reliance on pre-trained VAEs or diffusion models.

Figure 3: Images generated by EPG-L via one-step sampling, demonstrating high-fidelity synthesis in a single forward pass.
Scaling and Efficiency
The framework exhibits strong scaling properties: increasing pre-training batch size and model parameters leads to monotonic improvements in downstream generative performance.

Figure 4: Downstream generative model performance scales with pre-training compute budgets, indicating efficient utilization of additional resources.
Qualitative Results
Uncurated samples generated by EPG-XL across various classes and guidance scales demonstrate high diversity and fidelity, with competitive visual quality to state-of-the-art latent diffusion models.

Figure 5: Uncurated samples from EPG-XL (class 1, guidance 4.5).

Figure 6: Uncurated samples from EPG-XL (class 22, guidance 4.5).

Figure 7: Uncurated samples from EPG-XL (class 89, guidance 2.5).
Ablation and Analysis
Ablation studies confirm that both the representation consistency loss and the auxiliary contrastive loss are critical for stable training and optimal generative performance. The temperature schedule for the InfoNCE loss is shown to be important for avoiding early training collapse. Comparisons with alternative pre-training strategies (e.g., MoCo v3, REPA, rRCM) demonstrate that the proposed method yields superior downstream FID scores in both diffusion and consistency modeling regimes.
Theoretical and Practical Implications
This work demonstrates that with appropriate self-supervised pre-training, pixel-space generative models can match or exceed the performance of latent-space models, while eliminating the need for complex VAE pipelines. The approach is theoretically grounded in the alignment of representations along diffusion trajectories and empirically validated at scale. The method is modular, requiring no external models, and is compatible with both diffusion and consistency modeling frameworks.
Practically, this enables more streamlined, efficient, and robust generative modeling pipelines, particularly for high-resolution image synthesis. The framework is also well-suited for extension to multi-modal and conditional generation tasks, given its strong scaling properties and independence from VAE bottlenecks.
Future Directions
Potential avenues for further research include:
- Incorporating external supervision (e.g., off-the-shelf SSL models) to further accelerate training.
- Extending the framework to multi-modal or text-conditional generation.
- Investigating the integration with flow matching and other generative paradigms.
- Exploring the limits of scaling in terms of model size, data, and compute.
Conclusion
The two-stage self-supervised pre-training and end-to-end fine-tuning framework presented in this work closes the longstanding performance and efficiency gap between pixel-space and latent-space generative models. By decoupling semantic representation learning from pixel generation and leveraging robust contrastive and consistency objectives, the method achieves state-of-the-art results in both diffusion and consistency modeling, with strong scaling and practical efficiency. This establishes a new baseline for pixel-space generative modeling and provides a foundation for future advances in high-fidelity, efficient image synthesis.
