- The paper proposes a joint optimization method combining photometric and geometric losses to stabilize poses and enhance 3D reconstruction quality.
- It integrates global SfM initialization, persistent feature tracks, and MCMC-based densification to improve accuracy and resolve early constraints.
- Empirical results demonstrate significant gains in PSNR and speed over COLMAP-based pipelines across benchmarks like MipNeRF360 and Tanks and Temples.
GloSplat: Joint Pose-Appearance Optimization for Faster and More Accurate 3D Reconstruction
The conventional paradigm in scene reconstruction pipelines separates feature extraction, Structure from Motion (SfM), and radiance field optimization into independent modules. These compartmentalized approaches propagate pose errors, leading to blurred reconstructions and inconsistencies in geometric fidelity. While incremental SfM, exemplified by COLMAP, is robust, it induces drift accumulation, quadratic complexity in exhaustive feature matching, and prohibits photometric feedback post pose estimation. Prior attempts at joint optimization (BARF, NeRF--, 3RGS) rely exclusively on photometric gradients for pose adjustment and are susceptible to early-stage pose drift due to sparse geometric anchoring. GloSplat addresses these deficiencies by sustaining explicit geometric constraints throughout training, integrating global SfM initialization, and dual photometric-geometric optimization during 3D Gaussian Splatting (3DGS) training.
Pipeline Architecture
GloSplat is instantiated in two variants: GloSplat-F (fast, retrieval-based matching, COLMAP-free) and GloSplat-A (maximum quality, exhaustive matching). Both architectures leverage learned feature extraction and matching (XFeat+LightGlue or SIFT), global SfM (rotation averaging, parallel positioning, bundle adjustment) for robust pose initialization, and continuous joint optimization during 3DGS training.
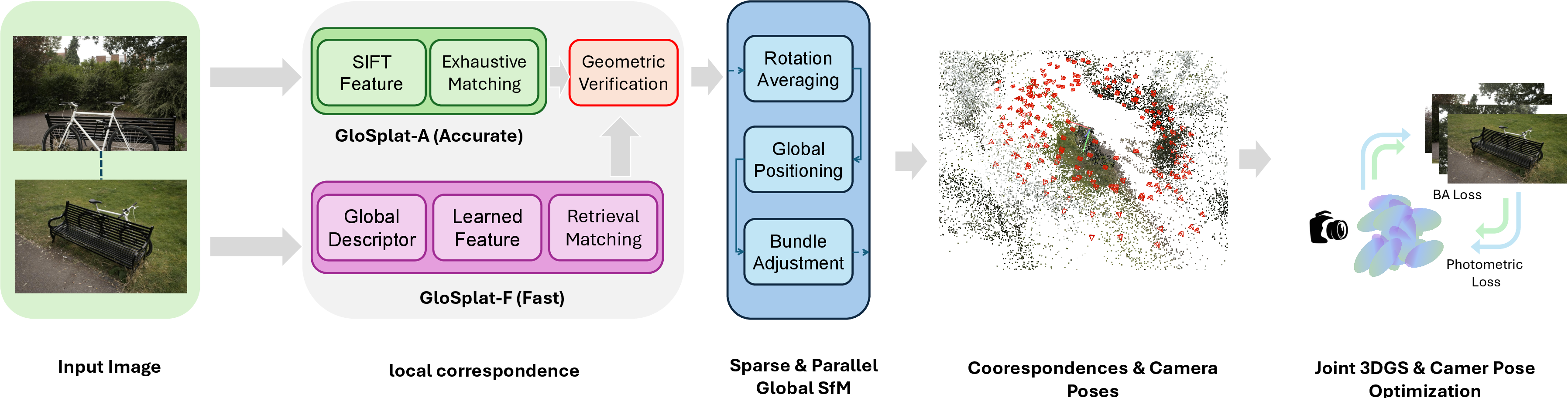
Figure 1: The GloSplat pipeline integrates preprocessing feature extraction and matching, global SfM for pose and track estimation, and joint 3DGS training with persistent geometric constraints.
The architectural innovation is the preservation of SfM feature tracks as persistent, optimizable entities, maintained separately from Gaussian primitives. The reprojection-based bundle adjustment (BA) loss operates on these tracks, concurrently with photometric rendering loss, stabilizing optimization against catastrophic pose drift in early stages where Gaussians are poorly initialized. MCMC-based densification provides principled control over primitive allocation.
Joint Optimization and Methodology
GloSplat preserves explicit SfM tracks during 3DGS training, enabling multi-view geometric anchoring via a robust BA loss. Pose refinement proceeds continuously, benefiting from both photometric gradients and geometric constraints. The system’s optimization loop updates Gaussian parameters, camera extrinsics (receiving both photometric and geometric gradients), and track points (receiving only geometric gradients). This separation prevents conflicting gradient objectives that arise in naive merged parameterization and ensures geometric anchors survive MCMC-based densification.
Empirical Evaluation
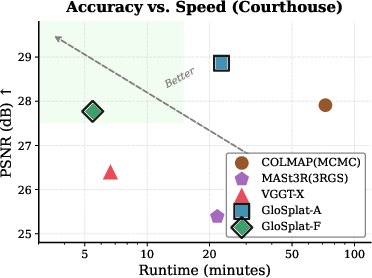
Evaluations on MipNeRF360, Tanks and Temples, and CO3Dv2 benchmarks demonstrate GloSplat-F sets performance standards for COLMAP-free pipelines, and GloSplat-A surpasses all COLMAP-based baselines. Notable numerical outcomes include:
Ablation studies attribute +0.61 dB improvement to joint optimization, +0.34 dB to global SfM, and further gains to MCMC densification. Freezing poses after SfM or eliminating geometric constraints causes substantial degradation (up to --8.59 dB PSNR). Separating track points from Gaussian means is validated as necessary for preventing optimization conflicts and ensuring geometric stability under densification.
Computational Efficiency and Scaling
GloSplat-F’s linear complexity in pair selection and parallel global SfM provide substantial scalability advantages. At 1000 images, it realizes a 13.3× speedup versus COLMAP. The lightweight BA loss imposes negligible overhead compared to photometric rendering. VGGT-X achieves faster runtimes at smaller scales but is overtaken at higher input counts due to GloSplat’s superior asymptotic scaling.
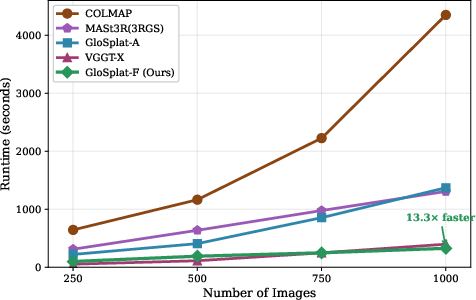
Figure 3: End-to-end reconstruction time demonstrates GloSplat-F’s scalability as image count grows, outperforming all baselines at large scales.
Qualitative Analysis
Qualitative results show GloSplat-A producing sharper, more accurate structures in challenging scenes containing fine details, thin objects, and complex geometry. LPIPS and PSNR improvements are corroborated visually.















Figure 4: Representative view synthesis comparisons across scenes; GloSplat-A distinctly outperforms other methods in detail, edge fidelity, and perceptual metrics.
Implications and Future Directions
Practically, GloSplat’s dual optimization scheme enables usage in real-time 3D capture, AR/VR, and robotic simulation scenarios demanding efficient and accurate large-scale scene reconstruction. Theoretically, its persistent geometric anchoring points to a new class of differentiable, constraint-aware pipelines that transcend historic modular boundaries. Future directions include end-to-end differentiable architectures propagating gradients through feature extraction and matching; improved retrieval strategies for sparse but informative view selection; and generalization to dynamic or semantic-rich environments.
Conclusion
GloSplat operationalizes a unified framework for 3D reconstruction, leveraging explicit global SfM initialization, persistent track-based geometric anchoring during 3DGS optimization, and principled densification. Empirical validations demonstrate its capacity to outperform both modular and joint photometric-only approaches in accuracy, perceptual quality, and computational efficiency. This system-level integration sets a robust foundation for future scalable, differentiable multi-stage vision pipelines, offering substantial performance gains for research and applied domains in machine perception (2603.04847).