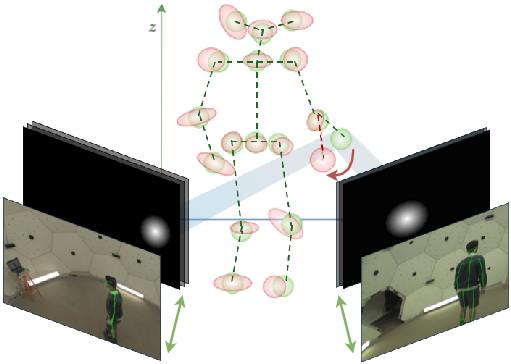
SkelSplat: Robust Multi-view 3D Human Pose Estimation with Differentiable Gaussian Rendering
Abstract: Accurate 3D human pose estimation is fundamental for applications such as augmented reality and human-robot interaction. State-of-the-art multi-view methods learn to fuse predictions across views by training on large annotated datasets, leading to poor generalization when the test scenario differs. To overcome these limitations, we propose SkelSplat, a novel framework for multi-view 3D human pose estimation based on differentiable Gaussian rendering. Human pose is modeled as a skeleton of 3D Gaussians, one per joint, optimized via differentiable rendering to enable seamless fusion of arbitrary camera views without 3D ground-truth supervision. Since Gaussian Splatting was originally designed for dense scene reconstruction, we propose a novel one-hot encoding scheme that enables independent optimization of human joints. SkelSplat outperforms approaches that do not rely on 3D ground truth in Human3.6M and CMU, while reducing the cross-dataset error up to 47.8% compared to learning-based methods. Experiments on Human3.6M-Occ and Occlusion-Person demonstrate robustness to occlusions, without scenario-specific fine-tuning. Our project page is available here: https://skelsplat.github.io.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces SkelSplat, a new way to figure out where a person’s body joints are in 3D using several cameras at once. Instead of training a big neural network on lots of labeled 3D data, SkelSplat models each joint (like the elbow or knee) as a soft 3D “cloud” and adjusts these clouds so that, when seen from different cameras, they line up with the 2D joint detections. The goal is to work well in many different camera setups and even when parts of the person are hidden (occluded), without needing to retrain for each new place.
Key Objectives
The paper asks and answers these main questions:
- How can we estimate a person’s 3D pose from multiple cameras without relying on expensive 3D training data?
- Can we make a method that works well even when camera positions change or the person is partly blocked from view?
- Can we adapt a graphics technique called “Gaussian Splatting” (normally used to render scenes) to accurately locate human joints in 3D?
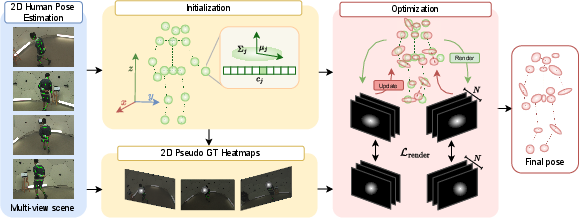
How SkelSplat Works (Methods in Simple Terms)
Think of each human joint as a small, soft glowing ball in 3D space. These balls are called “Gaussians.” SkelSplat uses several ideas to place and refine these balls:
- Multi-view input: You have multiple cameras watching the person at the same time. A standard 2D pose detector finds joint locations in each camera image (like dots for elbows, knees, etc.).
- Rendering and matching: If you project each 3D glowing ball onto a camera’s image, it looks like a fuzzy spot (a “heatmap”). SkelSplat “renders” these spots from the 3D model and compares them to the actual 2D detections from the cameras. If they don’t match, it nudges the 3D balls to fit better. This nudging is “differentiable,” which means the system can smoothly figure out how to move each ball to reduce the mismatch.
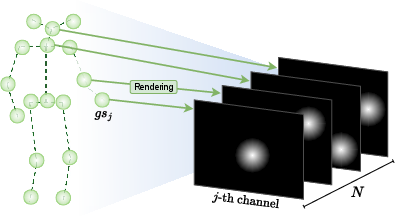
- One-hot joint channels: To avoid mixing up joints when they overlap in 2D, SkelSplat assigns each joint its own channel—like each joint gets its own labeled lane. When rendering, it produces a stack of images where each slice shows the fuzzy spot for just one joint. This “one-hot” setup avoids confusion and lets each joint be optimized independently.
- Pseudo ground truth from 2D: The system doesn’t need 3D labels. It creates “pseudo ground truth” heatmaps from the 2D detections (the camera sees a joint at X,Y, so it makes a 2D Gaussian there). It also makes these 2D shapes consistent with the camera’s perspective, so closer joints look larger and farther ones look smaller—just like in real photos.
- Symmetry regularization: Human bodies are generally symmetric (left and right arms/legs have similar lengths). SkelSplat adds a gentle rule that encourages these limb lengths to be similar, helping when some joints are hard to see.
- Cross-view optimization: Instead of updating the 3D balls view-by-view, SkelSplat gathers information (gradients) from all cameras before updating. This makes the final 3D pose more stable and consistent across views.
- No scene-specific tricks: It doesn’t add or remove balls (no “densification” or “pruning”) and doesn’t retrain for each new environment. It just optimizes the joint positions directly for the scene you’re working on.
In everyday terms: SkelSplat starts with a rough 3D skeleton. It looks at what each camera thinks about where joints are in 2D, renders its guess from those angles, and adjusts the 3D skeleton so all views agree, using common-sense rules like body symmetry.
Main Findings and Why They Matter
Across several well-known datasets, SkelSplat shows strong accuracy, generalization, and robustness:
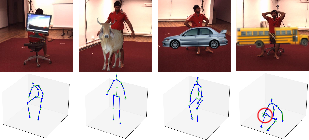
- Human3.6M (a standard benchmark): SkelSplat reaches errors around 20 mm (about 2 cm) when using high-quality 2D inputs, competing with or beating methods that don’t use 3D training data. It’s only topped by methods that were trained directly with full 3D supervision on that dataset.
- Cross-dataset generalization: When other methods are trained on one dataset (CMU Panoptic) and tested on another (Human3.6M), their accuracy drops a lot. SkelSplat, which doesn’t train on 3D data, reduces cross-dataset error by up to about 48% compared to those learning-based methods. This means it’s more reliable when you change camera setups or environments.
- CMU Panoptic Studio: In a 4-camera setup, SkelSplat outperforms several generalization-focused baselines without any special training.
- Occlusions (parts of the body hidden): On Human3.6M-Occ and Occlusion-Person, SkelSplat stays accurate even when multiple views are blocked by objects. It often beats baselines, including some methods designed specifically for occlusions, and does so without retraining or scene-specific fine-tuning.
In short: SkelSplat is accurate, works in new places without retraining, and handles occlusions better than many competitors.
Implications and Potential Impact
- Easier deployment: Because SkelSplat doesn’t need 3D training data or scene-specific fine-tuning, it’s simpler to use in new locations—like different rooms, labs, or studios with different camera placements.
- Robust to real-world messiness: People get partially blocked by furniture or other people. SkelSplat’s ability to handle occlusions makes it practical for real applications like sports analysis, animation, AR/VR, and human-robot interaction.
- A new way to use graphics for vision: The paper shows that techniques from computer graphics (Gaussian Splatting) can be repurposed to solve vision problems about body pose. This could inspire similar ideas for other 3D tasks that don’t have lots of labeled training data.
- Confidence/uncertainty: Since each joint is a “Gaussian,” its spread (covariance) can hint at how certain the system is about that joint’s position—useful for making safer decisions in robotics or for highlighting areas that need manual review.
Bottom line: SkelSplat is a flexible, accurate, and practical method for estimating 3D human poses from multiple cameras, especially when you want something that works well across different setups and doesn’t require lots of retraining or 3D labels.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list identifies specific areas where the paper leaves questions unresolved or where further research is needed to strengthen, extend, or validate SkelSplat.
- Multi-person scenes: How to scale one-hot joint encoding and the optimization to multiple people in the same scene, including robust person-joint association, disambiguation under inter-person occlusion, and per-person channel management without exponential growth in channels.
- Temporal modeling: The method optimizes per frame; it does not exploit temporal continuity. How to incorporate temporal smoothness, velocity/acceleration priors, and temporal visibility reasoning to improve stability, handle brief detector failures, and reduce jitter.
- Calibration and synchronization robustness: The approach assumes accurate, synchronized, calibrated cameras. What is the sensitivity to calibration errors and timestamp offsets, and can SkelSplat jointly refine extrinsics/intrinsics or handle mildly asynchronous views?
- Explicit occlusion modeling in the renderer: Occlusions are handled implicitly via masked losses and enlarged covariances. How to incorporate differentiable visibility (e.g., alpha/transparency, z-buffering, ray compositing) or occlusion-aware rendering/losses so gradients reflect actual visibility along rays.
- Use of 2D detector confidences and heatmaps: SkelSplat does not leverage per-joint confidences or detector-provided heatmaps. Can confidence-weighted losses, multi-peak heatmap supervision, or per-view reliability modeling improve robustness under noisy detections and occlusions?
- Uncertainty calibration of covariances: Covariances are optimized but not used to quantify predictive uncertainty (only coverage is reported). Are these covariances calibrated, and how can they be integrated for adaptive loss weighting, cross-view fusion, or downstream decision-making (e.g., robot planning)?
- Structural priors beyond symmetry: Only a weak symmetry loss is used. What is the impact of stronger kinematic constraints (bone length constancy, joint angle limits), anthropometric priors, or parametric human models (e.g., SMPL) on accuracy and failure modes?
- Efficiency and real-time feasibility: Runtime, memory footprint, and scalability to many cameras or long sequences are not reported. Can the optimization be made real-time (e.g., warm starts, incremental updates, view subsampling, faster differentiable rasterization)?
- Robust loss design: The masked L2 loss can be sensitive to outliers/background interference. Do robust losses (Huber, Geman–McClure), spatially adaptive weighting, or cross-view consistency terms reduce the impact of spurious detections and overlapping joints?
- Handling missing/corrupted 2D detections: The pipeline assumes available 2D keypoints; failure modes when joints are missing or misdetected are not analyzed. How to implement per-view outlier rejection, inpainting from other views, or joint-wise confidence gating?
- Skeleton definition mismatches across datasets: Joint sets differ (COCO, H36M, Panoptic). How to automatically map or adapt one-hot channels across heterogeneous skeletons, including dynamic reconfiguration for missing/extra joints?
- Operation with uncalibrated or moving cameras: Can SkelSplat be extended to uncalibrated, handheld, or moving cameras (self-calibration, bundle adjustment within the optimization), and how robust is it to moderate ego-motion?
- Densification/pruning choices: GS densification/pruning is disabled to keep joint cardinality fixed. Would per-joint mixtures (multiple Gaussians per joint), adaptive splitting/merging, or learned cardinality help under heavy occlusion or multi-modal hypotheses?
- Depth ambiguity with few views: The paper shows improved results with more cameras but does not characterize failure modes with sparse views. How to inject epipolar constraints or global 3D pose priors to mitigate front/back flips and depth ambiguities when views are limited?
- Validation under real occlusions: H36M-Occ and Occlusion-Person are synthetic occlusion setups. How does SkelSplat perform under real-world occlusions (cluttered scenes, inter-person occlusions, shadows), and can datasets with real occluders be used for evaluation?
- Person segmentation and scene context: The optimization does not use person masks or scene segmentation. Can incorporating segmentation, depth maps, or 3D scene geometry improve occlusion handling and reduce background-induced gradients?
- Initialization-free or coarse initialization: The method relies on a 3D pose guess (triangulation or monocular fusion) and degrades with large errors (>60–100 mm). Can SkelSplat converge from coarse or root-only initialization, or can global search strategies reduce reliance on good initial guesses?
- Adaptation to non-human skeletons: The approach targets human joints; its applicability to animals or variant kinematic trees is not studied. What changes are needed in encoding, priors, and optimization for different articulated species?
- Using covariance in downstream tasks: The paper hints at covariance utility but does not demonstrate it. How to convert covariances into actionable measures (e.g., per-joint credible intervals, reliability thresholds, task-aware weighting) for applications in robotics, AR/VR, or tracking.
- Hyperparameter selection and early stopping: Symmetry weight (1e-5), covariance scaling (1.25×), and early stopping criteria are set empirically. Can principled or adaptive schemes be developed to tune these per-scene/person/view, improving convergence and generalization?
- View weighting and gradient accumulation strategy: Gradients are accumulated across views uniformly. Would learned or geometry-informed view weighting, scheduling, or curriculum strategies improve stability under asymmetric view quality or occlusion patterns?
- Physical plausibility and contact constraints: The optimization does not enforce physically plausible poses or ground contacts. Can physics-based constraints or contact reasoning reduce improbable poses, especially in occlusions?
- Integration with parametric models: The paper avoids SMPL-like models to remain flexible. What are the trade-offs and gains if weak parametric priors or shape spaces are integrated (e.g., as regularizers) while retaining generalization?
- Expanded evaluation metrics: Only absolute MPJPE is reported. Evaluating PCK, occluded-joint recall, temporal consistency, and uncertainty calibration (e.g., reliability diagrams) would provide a more complete picture of performance and robustness.
Practical Applications
Immediate Applications
Below is a concise set of actionable, sector-linked use cases that can be deployed with SkelSplat’s current capabilities.
- Markerless multi-view motion capture for VFX/game studios [Media/Entertainment]
- Potential tools/products/workflows: Post-production pipeline that ingests calibrated multi-camera footage, runs off-the-shelf 2D keypoint detectors, and optimizes 3D skeletons via SkelSplat; DCC plugins (Blender, Unreal, Unity) for exporting rigged joint trajectories; batch processing for episodic shoots; covariances used to flag uncertain frames for artist review.
- Assumptions/dependencies: Calibrated and synchronized cameras; sufficient lighting for 2D detectors; single- or few-person scenes; GPU availability for iterative optimization; joint definition consistency across tools.
- Sports performance analysis in arenas/gyms [Sports/Analytics]
- Potential tools/products/workflows: Stadium-side service that fuses existing broadcast cameras to reconstruct 3D poses of athletes; coaches’ dashboards for kinematics (joint angles, stride, jump mechanics); latency-tuned optimization for near-live replay; covariance-driven confidence overlays to handle occlusions.
- Assumptions/dependencies: Accurate camera extrinsics/intrinsics; stable 2D detection under motion blur/lighting; permissions for camera use; compute budget for per-clip optimization.
- Human–robot collaboration safety monitoring [Robotics/Manufacturing]
- Potential tools/products/workflows: HRI safety module that continuously reconstructs worker 3D pose from fixed factory cameras to monitor safe separation distances, reach envelopes, and near-miss events; triggers in robot controllers; retrospective incident analysis using uncertainty metrics.
- Assumptions/dependencies: Factory camera calibration and synchronization; viable frame rate (optimization budget vs. safety requirements); robust 2D keypoints under PPE/occlusions; policy compliance for workplace monitoring.
- Workplace ergonomics and EHS compliance auditing [Enterprise/EHS]
- Potential tools/products/workflows: Ergonomics scoring tool that evaluates posture risk (RULA/REBA-like metrics) from multi-view 3D pose; heatmaps of frequent risky motions; periodic audits with report generation; uncertainty-aware filtering to avoid false positives under heavy occlusion.
- Assumptions/dependencies: Multi-camera coverage and calibration; consistent joint definitions across models; adequate 2D detection in variable lighting; privacy-compliant storage (prefer skeleton-only data).
- Data generation for robot learning and imitation [Robotics/AI]
- Potential tools/products/workflows: “SkelSplat Dataset Builder” that converts multi-view human demonstrations into consistent 3D joint trajectories for policy learning; automatic per-scene optimization without retraining; uncertainty scores for dataset curation.
- Assumptions/dependencies: Good 2D detections across views; scene calibration; single demonstrator or clear identity separation; GPU resources for large-scale dataset creation.
- Clinical gait and rehabilitation assessment (offline) [Healthcare]
- Potential tools/products/workflows: Clinic-friendly multi-camera kit capturing walking or exercises; post-session 3D pose reconstruction and report generation (spatiotemporal gait parameters, ROM); covariances used as an uncertainty indicator for occluded joints (e.g., assistive devices).
- Assumptions/dependencies: Clinical camera calibration; offline workflow preferred (not hard real-time); validated 2D detectors in clinical lighting; regulatory considerations for patient data.
- Event and rehearsal analytics for choreography and stage blocking [Performing Arts]
- Potential tools/products/workflows: Multi-camera rehearsal capture with 3D pose feedback to choreographers; export to animation software; occlusion-robust tracking in crowded stage settings using covariance to identify ambiguous joints for manual correction.
- Assumptions/dependencies: Synchronized cameras; stage coverage; identity management if multiple performers overlap; 2D detector robustness to costumes.
- Cross-domain academic benchmarking and reproducible pose estimation without 3D GT [Academia]
- Potential tools/products/workflows: Open-source SkelSplat pipelines for multi-view fusion research; occlusion robustness studies; cross-dataset generalization experiments and camera-configuration ablations; uncertainty evaluation using Gaussian covariances.
- Assumptions/dependencies: Access to calibrated multi-view datasets; consistent joint conventions; compute for optimization; careful reporting of 2D detector choices.
- Camera placement and occlusion planning tool [Software/Facilities]
- Potential tools/products/workflows: “Occlusion-aware camera planner” that uses SkelSplat’s geometry and covariance behavior to simulate and optimize camera layouts before deployments; sensitivity analyses for view count and resolution.
- Assumptions/dependencies: Environment CAD or site survey; anticipated motion envelopes; ability to run synthetic 2D detection and rendering; facility constraints.
- Multi-camera home fitness for advanced users (offline) [Consumer/Daily Life]
- Potential tools/products/workflows: DIY setups using two or more smartphones/webcams; post-workout 3D pose reconstruction for form feedback; export to coaching apps; uncertainty indicators for occluded angles (e.g., ankles behind furniture).
- Assumptions/dependencies: Basic calibration via checkerboard/AR markers; enough light; user tolerance for offline, non-real-time feedback; consistent joint taxonomy with coaching app.
Long-Term Applications
The following use cases require further research, scaling, real-time engineering, multi-person handling, or regulatory/operational development.
- Real-time multi-person 3D pose estimation with occlusion robustness [Software/Robotics/AR/VR]
- Potential tools/products/workflows: Streamed differentiable Gaussian rendering with accelerated kernels; per-person one-hot joint channels; identity tracking across views; tight integration with AR/VR avatar driving and telepresence.
- Assumptions/dependencies: Significant GPU optimization, parallelization, and memory management; robust multi-person 2D detections; view synchronization; low-latency constraints.
- Closed-loop human–robot collaboration and co-manipulation [Robotics]
- Potential tools/products/workflows: Real-time 3D pose-informed controllers (impedance/admittance) reacting to human motion; predictive models using pose covariances for uncertainty-aware planning; safety certification.
- Assumptions/dependencies: Real-time guarantees; certified safety stacks; reliable perception under PPE/occlusion and clutter; rigorous validation.
- Infrastructure-scale pedestrian analytics for smart cities and autonomous driving [Mobility/Public Sector]
- Potential tools/products/workflows: Roadside multi-camera rigs reconstructing pedestrian 3D poses at intersections; vulnerability assessments in occluded zones; near-real-time feeds to AV and traffic management systems.
- Assumptions/dependencies: Large-scale calibration and synchronization; weather/lighting robustness for 2D detectors; privacy and data governance; operational costs.
- Privacy-preserving, skeleton-only analytics standards [Policy/Compliance]
- Potential tools/products/workflows: Policy frameworks that mandate skeleton-only storage with controlled retention; standardized joint taxonomies and uncertainty reporting; audits of occlusion-induced bias across demographics and attire.
- Assumptions/dependencies: Stakeholder alignment (regulators, enterprises, public); technical standards for anonymization; fairness and bias evaluations; legal acceptance.
- Smart gyms and tele-coaching with multi-camera setups [Consumer/HealthTech]
- Potential tools/products/workflows: Guided camera calibration for users; on-device or edge-based optimization; dynamic workout-specific pose scoring; progress tracking and injury prevention alerts.
- Assumptions/dependencies: UX for easy calibration; affordable edge compute; robust 2D detectors in variable environments; liability considerations.
- Clinical diagnostics and at-home monitoring (regulated) [Healthcare]
- Potential tools/products/workflows: Validated medical-grade pipelines for gait disorders, movement screening; longitudinal monitoring; integration with EMR; decision support for therapists using quantitative pose metrics and uncertainties.
- Assumptions/dependencies: Clinical trials and regulatory approvals; data privacy and security; robustness across diverse patient populations and assistive devices.
- Crowd analytics for event safety and evacuation planning [Public Safety]
- Potential tools/products/workflows: Multi-person tracking under heavy occlusion with uncertainty-aware aggregation; detection of abnormal movement patterns; digital twins of venues for safety drills.
- Assumptions/dependencies: Multi-person scalability; reliable identity separation; venue-wide camera calibration; stakeholder governance.
- Low-cost volumetric human capture by combining SkelSplat and body surface modeling [Media/XR]
- Potential tools/products/workflows: Hybrid pipelines fusing joint Gaussians (SkelSplat) with Gaussian-splat avatar reconstruction for high-fidelity meshes; motion retargeting; real-time avatar puppeteering.
- Assumptions/dependencies: Fusion with surface reconstruction algorithms; temporal consistency; compute optimization; handling garments and accessories.
- Insurance risk analytics and premium adjustment based on ergonomic exposure [Finance/InsurTech]
- Potential tools/products/workflows: Workplace posture risk scoring at scale; trend analyses tied to claims; incentives for interventions; uncertainty-aware thresholds to reduce false alarms.
- Assumptions/dependencies: Policyholder consent; rigorous validation of metrics; privacy-preserving deployment; clear causal links to claim reductions.
- SkelSplat SDK and ecosystem for multi-view pose [Software/Developer Tools]
- Potential tools/products/workflows: SDK exposing interfaces for calibrated camera ingestion, 2D detector integration, optimization control, covariance-based uncertainty; “Calibration Assistant” and “Occlusion Planner” modules; cloud and edge runtimes.
- Assumptions/dependencies: Ongoing maintenance, documentation, and support; standardized joint definitions across detectors; hardware variability; community adoption.
Glossary
- Adam: An adaptive stochastic optimization algorithm that estimates first and second moments of gradients to set per-parameter learning rates. "the optimization, based on Adam, is run for up to 125 iterations"
- Affine approximation: A locally linear transformation (matrix plus translation) used to approximate a more complex projective mapping. "using an affine approximation of the projective transformation."
- Algebraic Triangulation: A linear method to recover 3D points from multiple 2D observations by solving algebraic constraints. "Algebraic Triangulation and RANSAC from~\cite{iskakov2019learnable}."
- Anisotropic 3D Gaussian: A Gaussian distribution in 3D with direction-dependent variance, represented by a full covariance. "represented as a set of anisotropic 3D Gaussians "
- Camera extrinsic transformation: The matrix mapping world coordinates to camera coordinates, encapsulating the camera’s rotation and translation. "where is the camera extrinsic transformation (world-to-camera)"
- Covariance matrix: A matrix describing the spatial spread and orientation of a Gaussian distribution. "a covariance matrix "
- Densification: The process of increasing the number of Gaussians to better fit the scene during optimization. "Gaussians densification and pruning are performed to better fit the entire scene."
- Differentiable Gaussian rendering: A rendering approach that projects Gaussian primitives while providing gradients for optimization. "leveraging differentiable Gaussian rendering for view fusion;"
- Epipolar geometry: The geometric relationship between two camera views constraining corresponding points to epipolar lines. "He et al.~\cite{he2020epipolar} use epipolar geometry to attend to geometrically consistent pixels."
- Gaussian Splatting: A technique that represents scenes as oriented 3D Gaussians and renders them by projecting their “splats” onto images. "Gaussian Splatting~\cite{kerbl20233d} had a disruptive impact on graphics"
- Gradient accumulation: Aggregating gradients across multiple views before updating parameters to improve stability. "we accumulate gradients across all views, improving stability and cross-view coherence."
- Jacobian matrix: A matrix of partial derivatives that linearizes how changes propagate through a transformation. "J_i is the Jacobian matrix of the perspective projection at the joint position in camera coordinates."
- Masked L2 loss: An L2 (squared error) loss computed only over selected (non-background) pixels via a binary mask. "The choice of a masked loss over the standard one is due to the high presence of background regions that can reduce convergence."
- Mean Per Joint Position Error (MPJPE): The average Euclidean distance (in mm) between predicted and ground-truth 3D joint positions. "We assess 3D pose estimation accuracy using the Mean Per Joint Position Error (MPJPE)"
- One-hot encoding: A representation where only one channel is active to indicate identity (here, the joint index). "we introduce a one-hot encoding scheme for joints"
- Perspective projection: The mapping from 3D points to the 2D image plane according to camera intrinsics, causing size to vary with depth. "the Jacobian matrix of the perspective projection at the joint position in camera coordinates."
- Photometric loss: A loss comparing pixel intensities between rendered and ground-truth images. "to minimize the photometric loss between the rendered images and the ground truth RGB images."
- Pruning: Removing Gaussians during optimization to simplify the representation and avoid redundancy. "Gaussians densification and pruning are performed to better fit the entire scene."
- Pseudo-ground truth: Supervision generated from detections or cues (not manual annotations) used to guide optimization. "Pseudo-ground truth heatmaps are generated from the 2D detections and used to supervise the optimization"
- RANSAC: A robust estimation algorithm that iteratively fits models to random subsets and selects the one with maximal consensus. "Algebraic Triangulation and RANSAC from~\cite{iskakov2019learnable}."
- SO(3): The special orthogonal group of 3D rotations (set of 3×3 rotation matrices). ""
- Spherical harmonics: Orthogonal basis functions on the sphere used to model view-dependent appearance. "modeled using spherical harmonics~\cite{ramamoorthi2001efficient} to support view-dependent radiance."
- Splat: The projected 2D footprint of a 3D Gaussian on an image plane. "each channel corresponds to the splat of a single joint Gaussian on a camera view."
- Structure-from-Motion (SfM): A method to recover camera poses and 3D structure from multiple images. "initialized from Structure-from-Motion (SfM)"
- View-dependent radiance: Appearance that varies with the viewing direction, modeled to capture specularities and shading changes. "modeled using spherical harmonics~\cite{ramamoorthi2001efficient} to support view-dependent radiance."
Collections
Sign up for free to add this paper to one or more collections.