YoNoSplat: You Only Need One Model for Feedforward 3D Gaussian Splatting
Abstract: Fast and flexible 3D scene reconstruction from unstructured image collections remains a significant challenge. We present YoNoSplat, a feedforward model that reconstructs high-quality 3D Gaussian Splatting representations from an arbitrary number of images. Our model is highly versatile, operating effectively with both posed and unposed, calibrated and uncalibrated inputs. YoNoSplat predicts local Gaussians and camera poses for each view, which are aggregated into a global representation using either predicted or provided poses. To overcome the inherent difficulty of jointly learning 3D Gaussians and camera parameters, we introduce a novel mixing training strategy. This approach mitigates the entanglement between the two tasks by initially using ground-truth poses to aggregate local Gaussians and gradually transitioning to a mix of predicted and ground-truth poses, which prevents both training instability and exposure bias. We further resolve the scale ambiguity problem by a novel pairwise camera-distance normalization scheme and by embedding camera intrinsics into the network. Moreover, YoNoSplat also predicts intrinsic parameters, making it feasible for uncalibrated inputs. YoNoSplat demonstrates exceptional efficiency, reconstructing a scene from 100 views (at 280x518 resolution) in just 2.69 seconds on an NVIDIA GH200 GPU. It achieves state-of-the-art performance on standard benchmarks in both pose-free and pose-dependent settings. Our project page is at https://botaoye.github.io/yonosplat/.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces YoNoSplat, a fast and flexible computer vision system that can build 3D scenes from regular photos. It works even when the camera positions and settings are unknown, and it can handle any number of images. Instead of slowly fine-tuning a model for each new scene, YoNoSplat uses a single, pre-trained model to directly predict a 3D scene made of many tiny “soft blobs” called Gaussians. This lets it reconstruct new scenes in just a few seconds.
What problems is the paper trying to solve?
In simple terms, the authors want a single model that can:
- Turn a bunch of photos into a high-quality 3D scene very quickly.
- Work with different situations: sometimes the camera positions are known, sometimes they aren’t; sometimes the camera settings (like zoom) are known, sometimes they aren’t; and the number of input images can vary a lot.
- Avoid complex, slow per-scene training (so it’s practical for real-world use).
Put another way: “You Only Need One Model” (YoNoSplat) that works almost everywhere, without special setup.
How does YoNoSplat work?
Think of making a 3D model like building a sculpture out of many small, soft balls (Gaussians). If you place and color enough balls in 3D, then look at them from different angles, they can match the photos you took. YoNoSplat predicts where those balls should go and how they should look.
Here are the key ideas, explained with everyday language:
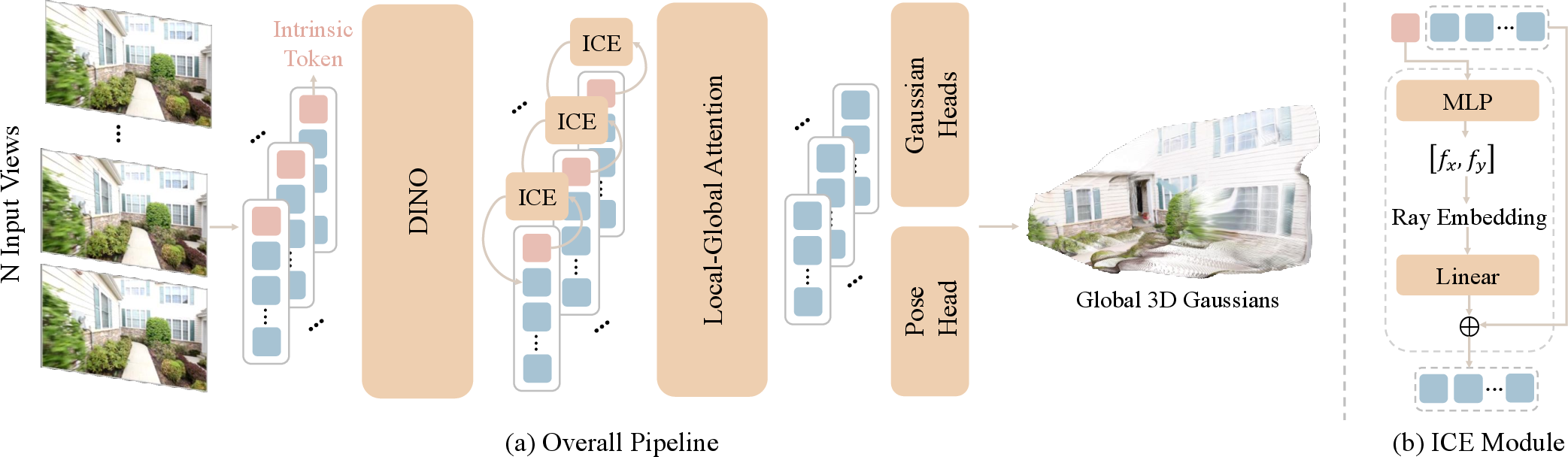
- Feedforward prediction: Instead of slowly adjusting the model for each new scene, YoNoSplat makes one quick pass to predict the 3D scene from your photos. That’s what “feedforward” means: fast, one-shot computation.
- Local-to-global design: For each input photo, the model predicts “local” Gaussians (balls placed in that photo’s own coordinate system) and also predicts the camera’s pose (its 3D position and orientation). Then it uses those poses to merge the local Gaussians into one “global” 3D scene. If you already know the camera poses, it can use them; if not, it predicts them.
- Camera pose and intrinsics:
- Pose means where the camera is and which way it’s pointing.
- Intrinsics are the camera’s internal settings, like focal length (how zoomed-in the camera is). YoNoSplat can also guess these if they’re not provided.
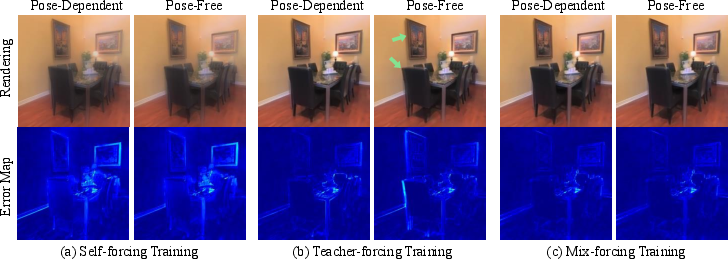
- Mix-forcing training (a stability trick): Learning both the 3D balls and the camera poses at the same time is tricky. If the camera pose is wrong, the 3D balls go to the wrong places; if the balls are wrong, the pose learning gets confused. The authors use a “training wheels” approach:
- Start by using the known, correct camera poses (“teacher-forcing”) so the model learns stable 3D shapes.
- Gradually mix in the model’s own predicted poses (“self-forcing”), so it learns to handle its own imperfections.
- This “mix” avoids instability and prepares the model for both cases: when poses are given and when they aren’t.
- Fixing scale ambiguity (knowing how big things are): If the data doesn’t include depth, it’s hard to tell if a scene is tiny and close or huge and far away. YoNoSplat handles this in two ways: 1) Scene normalization: It rescales the scene during training based on the largest distance between any two camera positions. This gives a consistent sense of “how big” the scene is. 2) Intrinsic Condition Embedding (ICE): The model predicts camera intrinsics (like focal length) from each image, turns them into “camera rays,” and feeds them back into the network as extra clues. If ground-truth intrinsics are available, it uses those instead. This helps the model nail the correct scale.
- Model architecture: YoNoSplat uses a Vision Transformer (a type of neural network that processes image patches) with smart attention that looks both within each image and across all images. It has separate “heads” (sub-networks) for:
- Gaussian centers and properties (color, size, orientation),
- Camera pose,
- Camera intrinsics.
- Training signals:
- Rendering loss: It renders images from the predicted 3D Gaussians and compares them to the real photos (using standard image similarity measures).
- Pose loss: It trains the pose head using the relative differences between camera pairs (this is robust when absolute scale is unknown).
- Intrinsic loss: It trains the intrinsics head to match known focal lengths (when available).
- Opacity regularization: It encourages using fewer Gaussians by penalizing unnecessary ones, then prunes very faint ones to keep the scene efficient.
What did they find?
- Speed: YoNoSplat can reconstruct a scene from 100 images (at 280×518 resolution) in about 2.69 seconds on a powerful GPU. That’s very fast for this kind of task.
- Versatility and accuracy: Across several standard datasets and many different setups (with and without known camera info), YoNoSplat reaches or beats state-of-the-art performance. Even when camera poses and intrinsics are unknown, it still produces high-quality results.
- Stability and robustness: The mix-forcing training strategy avoids the common pitfalls of training both geometry and camera poses together. It stabilizes learning and reduces the “exposure bias” problem (where a system trained only on perfect data struggles on imperfect real data).
- Better scale handling: Normalizing by the maximum distance between camera positions works best, and using ICE to condition on camera intrinsics helps fix the “how big is this scene?” problem—especially when intrinsics aren’t given.
- Generalization: The model trained on one dataset performs well on other datasets it hasn’t seen before. It also improves when you give it more input images, which shows it can effectively combine information from many views.
Why is this important?
- Real-world flexibility: In practice, you don’t always know the camera poses or intrinsics, and the number of photos varies. YoNoSplat handles all of that in one model.
- Less setup, more speed: You can get a good 3D reconstruction quickly, without spending a lot of time calibrating cameras or running slow per-scene training. That’s valuable for apps like AR/VR, robotics, mapping, video editing, and 3D content creation.
- Strong foundation: The ideas (mix-forcing training, scale normalization, and intrinsic conditioning) are broadly useful. They could improve other 3D and multi-view systems that struggle with similar issues.
What does this mean for the future?
YoNoSplat makes 3D scene building from photos more practical and accessible. Imagine:
- Phone apps that turn your photo albums into explorable 3D spaces without special hardware or calibration.
- Robots and drones mapping environments quickly using ordinary cameras.
- Faster 3D content creation for games and films.
By showing that “you only need one model” that works across many conditions, this research pushes the field toward more general-purpose, easy-to-use 3D reconstruction tools.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, written to be concrete and actionable for future research:
- Limited intrinsic modeling: the method appears to predict only focal length for intrinsics; principal point, aspect ratio, skew, and lens distortion are not modeled. Extend ICE and the intrinsic head to full camera models (including distortion parameters and non-pinhole cameras) and quantify their impact on scale recovery and rendering quality.
- Training-time dependence on ground-truth intrinsics for conditioning: conditioning the decoder on intrinsics predicted by the encoder caused instability. Investigate stabilizing mechanisms (e.g., stop-gradient, teacher–student, EMA targets, scheduled sampling on intrinsics, confidence-weighted conditioning) to enable training with predicted intrinsics and reduce train–test mismatch.
- Reliance on ground-truth poses during training: although inference is pose-free, training uses SfM-derived poses and relative pose supervision. Explore fully self-supervised training without any pose metadata via multi-view photometric and epipolar constraints, and assess performance when all camera parameters are unknown.
- Mix-forcing curriculum design: the schedule and final mixing ratio (e.g.,
t_start,t_end,r=0.1) are fixed and not ablated. Study adaptive mixing based on pose-confidence or training loss, alternative curricula (nonlinear schedules, view-dependent mixing), and sensitivity across datasets and view counts. - Metric scale recovery: max pairwise distance normalization resolves relative scale only; ICE with focal length does not guarantee metric scale. Investigate metric scale grounding via auxiliary cues (IMU/GPS, known object size priors, ground-plane constraints) or learned monocular scale calibration, and evaluate metric accuracy explicitly.
- Robustness to camera non-idealities: rolling shutter, strong lens distortion, fisheye cameras, and radiometric variations (exposure/white balance) are not discussed. Benchmark and augment the model to handle these conditions; extend the camera model and conditioning to account for per-view radiometric calibration.
- Dynamic/non-rigid scenes: training/evaluation focuses on static scenes. Develop motion-aware extensions (time-varying Gaussians, layered decompositions, motion segmentation) and evaluate on datasets with moving objects and non-rigid deformation.
- Scalability and efficiency for very large inputs: attention over many views and per-pixel Gaussian prediction scales poorly; results are reported up to 100 views on GH200. Design memory-efficient architectures (sparse/streaming/hierarchical attention, tile-based processing), learned view selection, and test on hundreds–thousands of views and consumer GPUs.
- Gaussian density control: opacity regularization with hard thresholding is a crude sparsification strategy. Develop learned sparsification/deduplication, adaptive per-pixel Gaussian counts, and spatial clustering/merging to reduce floaters and redundancy while preserving detail.
- Post-optimization dependence: optional post-optimization significantly boosts performance but introduces an optimization step. Investigate ways to reach similar accuracy purely feedforward (e.g., meta-learning, test-time adaptation without iterative optimization) and characterize trade-offs in speed/quality.
- Pose-free evaluation protocol: pose-free NVS evaluation requires optimizing target poses with a photometric loss. Develop evaluation protocols that avoid per-scene optimization (e.g., direct feedforward target-pose prediction, alignment-invariant metrics) to better measure true feedforward capability.
- Geometry accuracy metrics: evaluation focuses on photometric metrics (PSNR/SSIM/LPIPS). Add geometric assessments (depth error, surface/point cloud metrics, completeness) and analyze how photometric improvements translate to geometric fidelity.
- Handling extremely sparse overlap and wide baselines: performance and failure modes under very low overlap, extreme baselines, and Internet photo collections (unordered, noisy, heterogeneous cameras) are not characterized. Systematically evaluate and devise robustness strategies (epipolar-aware attention, overlap estimation, view curation).
- Domain generalization: while ScanNet++ generalization is reported, performance remains modest and domains (nighttime, aerial, urban at scale, synthetic/CGI) are not studied. Pursue domain adaptation, augmentation, and backbone alternatives tailored to diverse domains.
- Rotation parameterization: 9D rotation with SVD orthogonalization can yield suboptimal gradients when predictions are far from SO(3). Evaluate alternative parameterizations (quaternion, Lie algebra ) and their impact on stability and accuracy.
- Sensitivity to noisy SfM annotations: the paper hypothesizes SfM pose noise explains pose-free outperforming pose-dependent at low view counts but lacks quantification. Model annotation noise, use robust losses, and measure performance as a function of controlled pose/intrinsic noise.
- View selection policy: farthest point sampling is used but not evaluated. Study learned or task-aware view selection policies (e.g., uncertainty-aware sampling, overlap-aware selection) and their impact on quality and efficiency.
- Multi-view occlusion and visibility reasoning: explicit handling of occlusions/visibility in 3DGS compositing is not discussed. Incorporate visibility-aware training/inference (e.g., z-buffer approximations, learned occlusion masks) to reduce blending artifacts.
- Radiometric consistency: no modeling of per-view appearance changes (exposure, vignetting, color shifts). Add appearance normalization or per-view appearance parameters to improve cross-view consistency.
- Resolution scaling and token efficiency: only two resolutions are explored and token upsampling is fixed. Investigate multi-scale tokenization, pyramid features, and resolution-aware heads to improve detail without quadratic attention cost.
- Evaluation at extreme input sizes: training samples 2–32 views; inference up to 100. Characterize behavior at 2–4 views (few-shot), and at 200+ views (large-scale scenes), including memory, speed, and quality scaling curves.
- Integration of partial priors: while the model can use GT poses/intrinsics, strategies for partially available or weak priors (subset of views with GPS/IMU/poses, rough focal ranges) are not detailed. Design principled fusion mechanisms to optimally exploit heterogeneous priors.
Practical Applications
Below is a structured analysis of practical, real-world applications that follow from the paper’s findings, methods, and innovations. Each item notes the sector, actionable use case, potential tools/workflows, and key assumptions/dependencies. Applications are grouped by deployment horizon.
Immediate Applications
The following applications can be deployed now, primarily via GPU-backed services or existing enterprise pipelines.
- Rapid, calibration-free 3D scene capture for property marketing and as-built documentation (Real Estate, AEC)
- Use YoNoSplat to convert 20–100 smartphone photos into interactive 3D Gaussian scenes for virtual tours or as-built verification.
- Workflow: image ingestion → feedforward reconstruction (2–3s per 100 views on GH200) → optional post-optimization → publish via a web viewer or export to engines (Unreal/Unity) or DCC tools (Blender).
- Assumptions/dependencies: static scenes; sufficient coverage and overlap; server-side GPU; 3DGS viewer support; optional conversion to mesh via third-party tools.
- Environment scanning and previs for film, TV, and games (Media & Entertainment)
- Quickly reconstruct indoor/outdoor sets without rigged cameras; enable rapid blocking and lighting tests through novel-view synthesis.
- Tools/workflows: DCC plugin to import 3DGS, live previews, and fast re-captures; integrate ICE to handle unknown cameras on set.
- Assumptions/dependencies: static set elements; GPU access; acceptable fidelity without per-scene optimization.
- Offline mapping from image batches for robotics and drones (Robotics)
- Generate a globally consistent 3D scene and relative poses from ad-hoc image collections (e.g., drone fly-bys) to bootstrap localization and mapping.
- Workflow: batch images → YoNoSplat → predicted camera poses + 3DGS → optional post-optimization → export to downstream SLAM/visual odometry pipelines.
- Assumptions/dependencies: non-degenerate motion; static environments; pose accuracy improves with more views; may need loop-closure downstream.
- Rapid assessment of accident or damage scenes from user photos (Insurance, Forensics)
- Reconstruct scenes from multi-angle smartphone images for adjusters or investigators; enable photometrically consistent novel views and measurements.
- Tools/workflows: secure upload portal → feedforward 3D reconstruction → adjuster viewer with annotation tools; optional mesh extraction for measurement.
- Assumptions/dependencies: privacy handling; static scenes; capture guidelines; GPU capacity.
- Cultural heritage and archives digitization from heterogeneous photos (Museums, Preservation)
- Use uncalibrated archival images to reconstruct site artifacts or facades; leverage ICE to handle unknown intrinsics.
- Tools/workflows: image preprocessing → YoNoSplat with intrinsic prediction → archival viewer for curators; cross-dataset generalization shown (ScanNet++).
- Assumptions/dependencies: variable image quality; static content; careful coverage selection; potential artifacts in reflective/textureless regions.
- Multi-view dataset curation and baseline generation (Academia, Research)
- Generate consistent 3DGS scenes and relative poses as baselines across datasets without depth annotations, accelerating benchmarking and ablation studies.
- Tools/workflows: standardized pipelines using mix-forcing, pairwise distance normalization, and ICE; reproducible evaluation without SfM dependence.
- Assumptions/dependencies: access to training/inference GPUs; adherence to licensing for training corpora (RE10K/DL3DV).
- Foundational training strategy for entangled multi-task models (Software/ML Engineering)
- Apply mix-forcing as a generic curriculum to stabilize joint learning of intertwined variables (e.g., camera pose + geometry, multi-sensor calibration).
- Tools/workflows: incorporate staged mixing ratios in training loops; monitor exposure bias vs. self-forcing instability.
- Assumptions/dependencies: access to ground-truth or proxy signals to bootstrap teacher-forcing; curriculum tuning per domain.
- 3D product visualization from consumer captures (E-commerce)
- Convert multi-image product shots into interactive 3D scenes without calibrated turntables; enable NVS for richer product pages.
- Tools/workflows: capture guidelines (background, coverage), server-side reconstruction, 3DGS web viewer with lighting control.
- Assumptions/dependencies: small objects benefit from controlled backgrounds; static subject; trade-offs vs. photogrammetry meshes.
- Site documentation and inspection (Energy, Utilities)
- Reconstruct substations, towers, or equipment from ad-hoc photo sets to support remote inspection and digital twins.
- Tools/workflows: secure ingestion → YoNoSplat → 3DGS viewer for inspectors → annotate and archive; optional mesh conversion for CAD interop.
- Assumptions/dependencies: static assets; safety and privacy constraints; GPU resources; cross-sensor fusion left to downstream tools.
- Room scanning for interior planning, listings, and sharing (Daily life)
- Smartphone app uploads a burst of images; cloud service returns an interactive 3D scene for layout planning or social sharing.
- Tools/workflows: client capture helper → cloud inference → in-app viewer with novel-view controls.
- Assumptions/dependencies: quality capture and overlap; cloud GPU backend; bandwidth and data privacy.
Long-Term Applications
The following applications require further research, scaling, or engineering development (e.g., model compression, dynamic-scene handling, multi-session alignment).
- Real-time, on-device AR scene reconstruction (Mobile AR, Consumer Tech)
- Achieve interactive scanning on smartphones or AR glasses by compressing the model (smaller ViT, quantization, distillation) and accelerating 3DGS rendering.
- Dependencies: efficient mobile inference; hardware acceleration; dynamic-scene robustness; battery/thermal constraints.
- Unified 3D mapping stack for robotics (Robotics, Autonomy)
- Integrate feedforward reconstruction and pose prediction into online SLAM for mapping, loop closure, and navigation in large, dynamic environments.
- Dependencies: handling dynamics, drift, multi-session alignment, loop-closure integration, and cross-sensor fusion (e.g., LiDAR, IMU).
- City-scale reconstructions from citizen imagery (Urban Planning, Policy)
- Crowdsource uncalibrated images to produce living digital twins for planning and resilience (e.g., disaster response, infrastructure updates).
- Dependencies: scalable training/inference; privacy controls; georegistration and scale consistency; governance and data stewardship.
- Endoscopic and intraoperative reconstruction without calibration (Healthcare)
- Fast 3D reconstruction from monocular endoscope shots to assist navigation and documentation when exact intrinsics are unknown.
- Dependencies: domain-specific training, non-Lambertian tissue handling, tool occlusions, regulatory approval, clinical validation.
- Continuous digital twin updates with lightweight capture (Industry 4.0, AEC)
- Replace periodic scans with frequent photo bursts from staff; pipeline auto-updates 3DGS twins and flags changes.
- Dependencies: change detection, versioning, accurate scale alignment across sessions, mesh export for CAD compliance.
- Standardized scale normalization across devices and datasets (Standards & Interop)
- Adopt pairwise camera-distance normalization in multi-view pipelines to ensure consistent scale in multi-source imagery workflows.
- Dependencies: consensus around normalization practices; tooling support; handling GPS/IMU for absolute scale.
- Multi-agent collaborative reconstruction (Defense, Search & Rescue)
- Stitch reconstructions and poses from multiple agents into unified scenes for situational awareness.
- Dependencies: robust multi-session merging; communication constraints; trust and security; dynamic-scene support.
- Editable 3DGS for measurement, simulation, and design (Software Tools)
- Build tooling to convert, edit, and measure within Gaussian scenes; integrate with physics simulators and CAD.
- Dependencies: reliable Gaussian-to-mesh pipelines; semantically aware editing; scale and unit consistency.
- Mixed-modality reconstruction (Sensors + Vision)
- Fuse images with depth/LiDAR to improve scaling, geometry, and robustness in adverse conditions.
- Dependencies: joint training objectives; calibration and synchronization; domain adaptation.
- Generalized mix-forcing curricula for complex systems (ML Methodology)
- Apply the paper’s mix-forcing concept to other entangled learning setups (e.g., pose+depth, intrinsic+extrinsic, multi-agent policy learning) to reduce instability and exposure bias.
- Dependencies: task-specific teacher signals; curriculum design; monitoring and evaluation protocols.
Notes on feasibility across applications:
- Performance and latency: The reported 2.69 s reconstruction time for 100 views depends on high-end GPUs (NVIDIA GH200) and specific resolutions; expect longer times on consumer hardware or larger images.
- Scene assumptions: Best results occur for static scenes with sufficient viewpoint coverage and texture; specular, transparent, or highly dynamic content may degrade reconstructions.
- Camera assumptions: ICE predicts focal length and conditions the network, but full intrinsics (e.g., distortion) and absolute scale may still require additional cues or alignment.
- Data and privacy: Many deployments imply sensitive imagery; ensure compliant data handling, consent, and privacy-preserving pipelines.
- Interoperability: 3DGS is excellent for novel-view synthesis but may need conversion for CAD/measurement workflows; plan for mesh export and unit calibration.
Glossary
- 3D Gaussian Splatting: A 3D scene representation and rendering technique that models scenes with anisotropic Gaussians and rasterizes them by splatting for fast view synthesis. "3D Gaussian Splatting (3DGS)"
- AUC (Area Under the Cumulative Angular Pose Error Curve): A summary metric measuring the proportion of pose estimates below angle thresholds, integrated over a range (e.g., 5°, 10°, 20°). "area under the cumulative angular pose error curve (AUC)"
- camera extrinsics: The parameters (rotation and translation) that place a camera in the world coordinate system, defining its position and orientation. "jointly learning camera intrinsics and extrinsics is an ill-posed problem"
- camera intrinsics: The internal camera parameters (e.g., focal length, principal point) that map 3D rays to image pixels. "camera intrinsics unknown"
- canonical space: A shared, fixed coordinate frame in which multi-view predictions are directly aligned across images. "predict Gaussians directly into a unified canonical space"
- DINOv2: A self-supervised visual representation learning model (ViT-based) used here as a feature encoder. "Features are extracted with a DINOv2 encoder"
- exposure bias: A training–inference mismatch where a model never sees its own predictions during training, causing degraded performance at test time. "introduces exposure bias"
- farthest point sampling: A subset selection strategy that iteratively picks the next sample farthest from the current set to ensure coverage. "farthest point sampling based on camera centers"
- feedforward model: A model that directly predicts outputs in a single pass without per-scene test-time optimization. "a feedforward model"
- Huber loss: A robust loss function less sensitive to outliers than squared error, quadratic near zero and linear for large errors. "calculate the Huber loss"
- Intrinsic Condition Embedding (ICE): A module that predicts camera intrinsics and encodes them (e.g., via rays) to condition the network, helping resolve scale ambiguity. "Intrinsic Condition Embedding (ICE) module"
- intrinsic token: A learnable token that aggregates image cues about camera intrinsics within a transformer encoder. "an intrinsic token with the input image tokens"
- local-global attention: An attention scheme combining per-frame self-attention with global attention across frames for multi-view fusion. "a local-global attention mechanism"
- LPIPS: A learned perceptual similarity metric used to evaluate or train for perceptual image quality. "LPIPS~\citep{lpips} loss"
- Max pairwise distance normalization: A scene normalization that scales camera centers by the maximum pairwise distance to fix scale ambiguity. "Max pairwise distance normalization leads to best performance."
- mix-forcing: A training curriculum that mixes ground-truth and predicted poses in aggregation to stabilize training and reduce exposure bias. "mix-forcing training strategy"
- novel view synthesis: Rendering images from new camera viewpoints given observations of a scene. "novel view synthesis task"
- opacity regularization: A sparsity-promoting penalty on Gaussian opacities to reduce redundant primitives. "opacity regularization loss"
- pairwise relative transformation loss: A supervision signal comparing predicted relative camera transforms between view pairs to ground truth. "pairwise relative transformation loss"
- photometric loss: An image-space loss (e.g., pixel/color differences) used to optimize poses or geometry via rendered views. "optimizes the poses through a photometric loss"
- Plücker coordinates: A ray representation in 3D defined by a direction and moment, useful for geometry-aware learning. "Plücker coordinates"
- pose-dependent: A setting where ground-truth camera poses are provided and used by the model. "pose-dependent"
- pose-free: A setting where camera poses are not provided and must be predicted or inferred by the model. "pose-free"
- PSNR: Peak Signal-to-Noise Ratio; a distortion metric (in dB) measuring reconstruction fidelity. "PSNR"
- relative pose loss: A loss penalizing errors in predicted relative rotation and translation between pairs of cameras. "relative pose loss"
- scene normalization: Rescaling/transforming camera poses (and sometimes geometry) to mitigate arbitrary scale and improve training stability. "Scene Normalization"
- scale ambiguity: The indeterminacy of absolute scale when only monocular images and up-to-scale poses are available. "scale ambiguity problem"
- self-forcing: Training that aggregates predictions using the model’s own predicted poses, tightly coupling pose and geometry learning. "self-forcing mechanism"
- SSIM: Structural Similarity Index; a perceptual image quality metric assessing structural fidelity. "SSIM"
- Structure-from-Motion (SfM): A pipeline that estimates 3D structure and camera poses from images, typically up to an unknown scale. "SfM methods"
- SVD orthogonalization: Converting an unconstrained 3×3 matrix to the nearest valid rotation matrix via singular value decomposition. "SVD orthogonalization"
- teacher-forcing: Training that uses ground-truth signals (here, poses) in the aggregation step rather than the model’s predictions. "teacher-forcing approach"
- Vision Transformer (ViT): A transformer-based architecture that processes images as sequences of patch tokens. "Vision Transformer (ViT) backbone"
Collections
Sign up for free to add this paper to one or more collections.