A Rubric-Supervised Critic from Sparse Real-World Outcomes
Abstract: Academic benchmarks for coding agents tend to reward autonomous task completion, measured by verifiable rewards such as unit-test success. In contrast, real-world coding agents operate with humans in the loop, where success signals are typically noisy, delayed, and sparse. How can we bridge this gap? In this paper, we propose a process to learn a "critic" model from sparse and noisy interaction data, which can then be used both as a reward model for either RL-based training or inference-time scaling. Specifically, we introduce Critic Rubrics, a rubric-based supervision framework with 24 behavioral features that can be derived from human-agent interaction traces alone. Using a semi-supervised objective, we can then jointly predict these rubrics and sparse human feedback (when present). In experiments, we demonstrate that, despite being trained primarily from trace-observable rubrics and sparse real-world outcome proxies, these critics improve best-of-N reranking on SWE-bench (Best@8 +15.9 over Random@8 over the rerankable subset of trajectories), enable early stopping (+17.7 with 83% fewer attempts), and support training-time data curation via critic-selected trajectories.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching a “critic” (a smart judge) to spot good and bad behavior in AI coding assistants during real conversations with people. In school-style tests, it’s easy to see if the code passes or fails. But in real life, people chat with the AI, change their minds, review code, and only sometimes give clear feedback. The authors build a critic that can judge how well the AI did from these messy, real-world interactions—even when direct success signals are rare—so we can pick better answers, stop bad attempts early, and train better coding agents.
What questions were the researchers asking?
They set out to answer:
- How can we reliably tell if a coding agent did a good job in real-world conversations where feedback is noisy, late, or missing?
- Can we learn a useful critic by using detailed “behavior checklists” from the conversation itself, even when final success labels are scarce?
- Will this critic help at decision time (picking the best attempt, stopping early) and during training (choosing better examples to learn from)?
How did they do it? (Methods in everyday language)
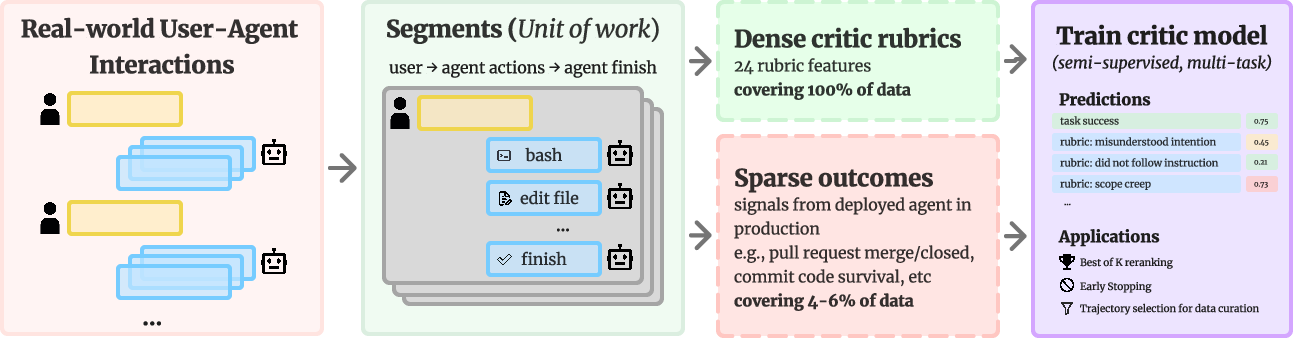
Think of a long group project chat as a movie. The researchers split each movie into short scenes called segments. A segment starts with a user request and ends when the AI says it’s done. This makes it easier to judge one unit of work at a time.
They then built three key pieces:
- A behavior checklist (Critic Rubrics): A 24-item “report card” that marks common success and failure signs you can see directly in the chat and tool logs—things like “misunderstood the request,” “skipped tests,” “looped on the same error,” or “user seemed frustrated.” This turns almost every segment into learning signal, because you can label behavior even when you don’t know the final outcome.
- Real-world outcomes, tied to segments:
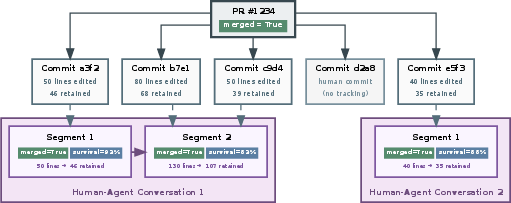
- PR merge: Was the pull request accepted? This is a rough, high-level signal and can be misleading because people often edit things before merging.
- Code survival: Of the code the AI wrote in a segment, how much stayed in the final merged code? This is like asking, “How much of your draft stuck in the final essay?” It’s more precise but available for fewer segments.
- A critic model that learns from both: They trained a critic to predict: 1) the rubric features (the checklist marks), and 2) whether a segment succeeded (using PR merge or code survival when available).
This is semi-supervised learning: the critic gets lots of practice on the checklist (dense and available for all segments) and occasional practice on final outcomes (sparse but important). Once trained, the critic can quickly score new attempts.
They used the critic in three practical ways:
- Best-of-K selection: Generate several solutions and use the critic to pick the best one.
- Early stopping: Stop generating more attempts as soon as one looks good enough.
- Data curation: Use critic scores to pick better real-world examples for fine-tuning the coding agent.
What did they find, and why does it matter?
Here are the key results and why they’re important:
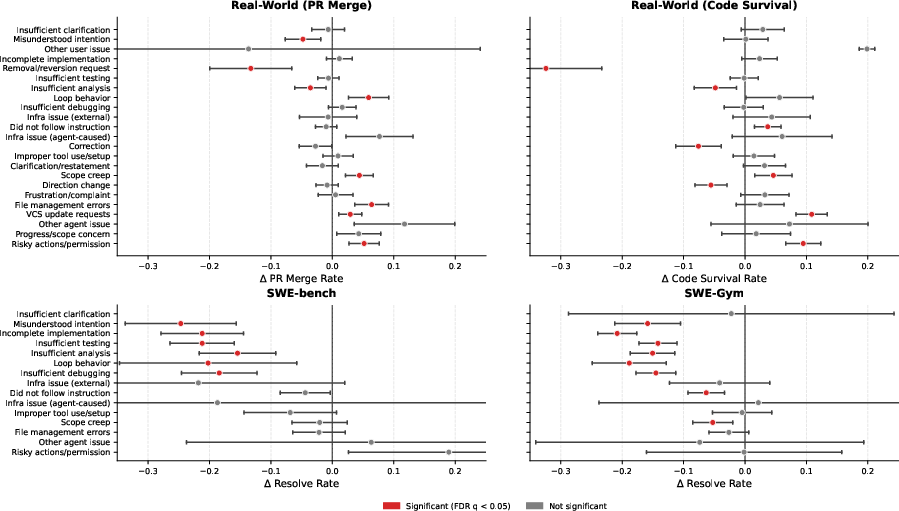
- Benchmark-only judges don’t work well in the real world.
- Critics trained only on academic-style tasks did poorly on real-world outcomes and could even make selection worse than random. Real conversations are different from neat, test-based benchmarks, so real-world data is necessary.
- “Code survival” is a better learning signal than “PR merged.”
- Even though code survival labels are rarer, they line up better with what actually succeeded at the segment level. It helped the critic learn more precise judgments than the coarse PR-merge signal.
- Rubric supervision makes the critic more robust.
- Training the critic to predict the behavior checklist (not just success/fail) made it work better across different AI backbones (different underlying LLMs). In contrast, success-only critics tended to overfit to one model and didn’t transfer well to another.
- Better decision-making at run time:
- Best-of-K: On a popular coding benchmark (SWE-bench), using the rubric-supervised critic to pick among 8 attempts improved success by +15.9 percentage points over random choice.
- Early stopping: With a simple threshold, they matched or beat selection performance while using 83% fewer attempts on average (1.35 tries instead of 8). That saves time and compute.
- Better training data:
- Choosing fine-tuning examples using critic scores beat random selection. It boosted solve rates compared to no selection, showing that the critic can help build better training sets from messy real-world logs.
Overall, these results show that a critic trained with behavior rubrics and a more precise outcome (code survival) can make coding agents more effective and efficient in real settings.
Why is this important?
- Real-world readiness: Most coding assistants live in chats with people, not just test suites. A critic that understands conversation-level behavior helps bridge that gap.
- Efficiency: Early stopping and better selection reduce wasted compute and developer time.
- Better learning: Curating training data with the critic helps agents improve faster and more reliably.
- Practical tools: The team is releasing the critic model, rubric definitions, and code, making it easier for others to adopt this approach.
Simple takeaway: Instead of waiting for rare, noisy “final scores,” this work teaches a judge to read the “story” of each attempt, use a rich checklist of behaviors, and give a fast, helpful score. That makes AI coding assistants more dependable and efficient in the real world.
Knowledge Gaps
Below is a single, focused list of the paper’s unresolved knowledge gaps, limitations, and open questions. Each item is written to be actionable for future research.
- External validity beyond the studied deployment: Evaluate whether rubric-supervised critics trained on OpenHands traces transfer to other agent scaffolds, organizational codebases, developer populations, and product surfaces (e.g., IDEs, chat assistants, CI bots).
- Domain generalization: Test applicability to non-coding agent tasks (e.g., data science notebooks, devops, documentation editing) and mixed-code/non-code workflows where outcome proxies differ.
- Programming language and stack diversity: Quantify performance across languages (Python, JS/TS, Java, C/C++, Rust), frameworks, and repository sizes; identify failure modes unique to strongly typed or build-heavy ecosystems.
- Segmentation robustness: Measure segmentation error rates against human-labeled ground truth; compare alternative boundary heuristics; study how mis-segmentation affects critic accuracy and downstream policies (reranking, early stopping).
- Multi-turn credit assignment: Develop sequence-level critics or temporal models that account for later user turns revising or invalidating earlier segments; compare segment-level vs conversation-level supervision.
- Commit attribution fidelity: Establish precision/recall of SHA-linking to segments using human audits; quantify how attribution mistakes propagate to survival scores and critic training.
- Code survival metric validity: Analyze sensitivity of survival to non-semantic changes (e.g., reformatting, minor edits), refactors, and code reorganization; explore semantic survival metrics (AST-level, function-level persistence, test outcome persistence).
- Better real-world outcome proxies: Investigate alternatives to PR merge and line-based survival (e.g., post-merge defect rates, unit/integration test outcomes, review comments, rollback frequency, production incident links).
- Proxy noise quantification: Systematically estimate confounding factors for PR merges (review bandwidth, product priorities, human edits) and quantify their impact on critic learning and evaluation.
- Rubric taxonomy coverage: Validate whether the 24 features sufficiently cover common failure modes; extend taxonomy to capture code quality (security, performance, readability), maintainability, and long-term outcomes (defect emergence).
- Rubric annotation reliability: Benchmark LLM-based rubric labels against expert human annotations; report inter-annotator agreement, error rates, systematic biases, and cost-quality tradeoffs; explore active learning for hard cases.
- Leakage audits: Confirm rubric annotator and critic training inputs never leak outcome signals (e.g., PR status, final diffs); document safeguards and audit procedures.
- Loss weighting and multi-task objectives: Ablate and tune weights between success and rubric heads; study how different losses (BCE-floor/round, MSE) affect calibration, transfer, and downstream selection.
- Score calibration across contexts: Calibrate critic outputs per backbone, repository, and task type; evaluate Platt scaling/temperature scaling for better early-stop thresholding and cross-backbone comparability.
- Model size and architecture sensitivity: Explore larger/smaller critics, different backbones, attention mechanisms for long traces, and memory-augmented models; quantify gains vs inference cost.
- Context truncation effects: Measure performance degradation from left truncation at 64K tokens; evaluate retrieval, hierarchical summarization, or process memory to preserve salient earlier context without leaking outcomes.
- Robustness to distribution shift: Track critic performance over time under changing tools, scaffolds, and model backbones; design drift detection and recalibration strategies.
- Adversarial robustness and reward hacking: Test whether agents can game critic scores (e.g., making cosmetic changes that boost survival or triggering rubric positives); design anti-gaming features and auditing procedures.
- RL with critic as reward: Evaluate on-policy/off-policy RL using the critic; study stability, sample efficiency, and whether critic-guided RL improves real-world outcomes without overfitting proxies.
- Data selection at scale: Extend SFT curation beyond small controlled sets; quantify gains across multiple base models, larger datasets, and varied selection criteria (e.g., high critic scores vs diverse rubric patterns).
- Comparative baselines: Benchmark against existing verifiers/reward models (PRMs, preference models, heuristic checklists) and human assessments to contextualize critic effectiveness.
- Causal analysis of rubrics: Move beyond association (AUC/effects) to interventions—test whether addressing specific rubric failures (e.g., debugging insufficiency) causally improves success in controlled studies.
- Early stopping policy design: Learn adaptive, instance-specific thresholds and stopping policies; analyze utility vs risk of premature stopping on hard or deceptive instances.
- Full-distribution evaluations: Report Best-of-K and early stopping gains across all tasks (not only mixed-outcome subsets); characterize where critics help, hurt, or are neutral.
- Safety and security coverage: Assess critic detection of risky actions, insecure code, and policy violations; add rubrics and evaluations for security-critical repositories.
- Privacy and compliance: Specify anonymization, consent, and governance for production traces; evaluate whether privacy-preserving transformations affect rubric and critic utility.
- Reproducibility details: Release training hyperparameters, loss schedules, seeds, and data processing scripts sufficient to replicate results; quantify variability across runs.
- Cross-agent/backbone breadth: Expand cross-backbone evaluation beyond Claude variants (e.g., OpenAI, Google, Mistral, Meta) and test portability to entirely different toolchains and agent frameworks.
- Long-term outcome alignment: Track whether critic-selected or critic-optimized changes reduce future developer workload (e.g., fewer follow-ups, faster reviews) and defects over weeks/months, not just immediate merging/survival.
Practical Applications
Immediate Applications
Below are actionable, deployable-now use cases that arise directly from the paper’s findings and released artifacts. Each item notes sector links, potential tools/products/workflows, and key assumptions or dependencies.
- Best-of-K reranking for coding agents
- Sectors: software, developer tools, finance, healthcare, energy (any domain with internal codebases)
- Tools/products/workflows: integrate the released critic model as a scoring service to rank multiple agent trajectories; select the top-scored trajectory before review or execution
- Evidence: improves SWE-bench Best@8 by +15.9 points over random; robust across LLM backbones when rubric supervision is used
- Assumptions/dependencies: access to agent interaction traces; ability to construct “segments” (user request → agent actions → finish); compatibility with the agent scaffold (e.g., OpenHands); initial threshold calibration for specific environments
- Compute-efficient early stopping for agent attempts
- Sectors: software, cloud operations, MLOps
- Tools/products/workflows: use critic score thresholds to stop sampling extra attempts once an attempt exceeds a target score; wire into orchestration pipelines or IDEs
- Evidence: +17.7 percentage points over random with 83% fewer attempts (1.35 avg. vs. 8)
- Assumptions/dependencies: critic latency (~1s with the 4B model) meets production SLAs; careful tuning of acceptance thresholds; guardrails to prevent premature stops on atypical tasks
- CI/CD quality gate for AI-generated code
- Sectors: software, finance, healthcare, gov/regulated industries
- Tools/products/workflows: gate agent-authored diffs behind critic scores; automatically route high-risk/risky-action rubrics to mandatory human review; combine with code survival analysis before merge
- Assumptions/dependencies: PR-commit-segment attribution in VCS; organizational policies that support human-in-the-loop gating; privacy/compliance alignment for telemetry
- Training-time data curation (SFT) using critic-selected segments
- Sectors: ML engineering, developer tools
- Tools/products/workflows: rank real-world segments by critic-predicted success; build higher-yield SFT datasets versus random sampling
- Evidence: critic-selected SFT improves solve rate (47.8% vs. 46.2% random); code-survival-filtered data shows an upper bound (50.4%)
- Assumptions/dependencies: rights to use production interaction data; deduplication and safe handling of private code; periodic recalibration to prevent drift
- Cross-backbone shared evaluator for multi-agent routing
- Sectors: platform engineering, AI infra, developer tools
- Tools/products/workflows: use rubric-supervised critic as a backbone-agnostic scorer to select among attempts from different LLMs (e.g., Sonnet vs. Opus) under a unified agent scaffold
- Evidence: rubric supervision generalizes across backbones; success-only critics risk backbone overfitting
- Assumptions/dependencies: consistent agent scaffolding (e.g., OpenHands); score normalization if inputs vary widely
- Risk and safety flags from rubric features
- Sectors: regulated industries, enterprise compliance, DevSecOps
- Tools/products/workflows: surface rubric signals like “risky_actions_without_permission,” “insufficient_testing,” or “file_management_errors” to reviewers; enforce guardrails for destructive actions
- Assumptions/dependencies: rubric schema adopted as an internal QA taxonomy; policy mappings (rubric → required control)
- Analytics and A/B testing for agent behavior in production
- Sectors: product analytics, developer tooling teams, academia
- Tools/products/workflows: use critic scores and rubrics to run experiments on agent prompts/backbones/tools; monitor distributions for drift; correlate critic signals with downstream business metrics
- Assumptions/dependencies: reliable data pipelines for segments; privacy-preserving aggregation; statistical power and proper experiment design
- PR triage and reviewer prioritization
- Sectors: engineering management, OSS maintainers
- Tools/products/workflows: rank PRs or segments by critic score and rubric-derived risk to prioritize human review; route low-risk changes to faster lanes
- Assumptions/dependencies: PR-commit-segment linkage; acceptance policies that permit score-based prioritization
- Human-in-the-loop UX that explains agent failures
- Sectors: IDEs, collaborative coding platforms
- Tools/products/workflows: embed concise rubric summaries in diff views to inform reviewers why an attempt may fail (e.g., “insufficient_debugging,” “misunderstood_intent”)
- Assumptions/dependencies: UI/UX integration; clear copy and thresholding to avoid alert fatigue
- Drift monitoring and quality assurance
- Sectors: MLOps, platform reliability
- Tools/products/workflows: monitor critic score distributions and rubric frequencies over time; trigger investigations when patterns shift (e.g., increased “loop_behavior” after a tool update)
- Assumptions/dependencies: observability for agent traces; sustained telemetry collection; ownership of QA processes
Long-Term Applications
These use cases require further research, scaling, validation in broader contexts, or organizational/process changes.
- Closed-loop RL training with rubric-supervised critics
- Sectors: ML research, developer tooling
- Tools/products/workflows: use critic as a reward model to optimize agents via RL; explore multi-task training (success + rubrics) for better credit assignment
- Dependencies: robust off-policy data; reward hacking safeguards; larger-scale, diverse deployment traces; evaluation beyond proxies
- Auto-merge policies for high-scoring segments
- Sectors: engineering operations, OSS at scale
- Tools/products/workflows: conditionally auto-merge small changes (e.g., non-sensitive refactors) when critic scores and rubrics indicate low risk
- Dependencies: rigorous calibration and post-deployment audits; domain-specific constraints and compliance checks; rollback tooling; organizational acceptance of automated merges
- Generalization of rubric-supervised critics beyond code (docs, data pipelines, spreadsheets, robotics)
- Sectors: education (autograders), office productivity, data engineering, robotics
- Tools/products/workflows: adapt segmenting and rubric taxonomies to other domains; build learned evaluators that can rerank, stop early, and curate training data for task-oriented assistants
- Dependencies: domain-specific rubrics, observables, and outcome proxies; tool instrumentation to capture traces; cross-domain validation and safety evaluations
- Personalized critics and adaptive thresholds
- Sectors: developer experience, enterprise tooling
- Tools/products/workflows: adjust rubric weights and acceptance thresholds by user/team preferences (e.g., stricter testing requirements in safety-critical teams)
- Dependencies: user-level telemetry and privacy controls; preference learning; careful handling to avoid bias against certain working styles
- Standardization of rubric taxonomies and evaluator governance
- Sectors: policy, standards bodies, enterprise compliance
- Tools/products/workflows: shared, auditable rubric definitions; guidance on acceptable use of critic scores in quality gates; audit protocols and reporting
- Dependencies: consensus-building across organizations; legal/privacy frameworks for trace logging; public artifacts and test suites
- Critic-as-a-Service ecosystems and marketplaces
- Sectors: AI platforms, developer tools vendors
- Tools/products/workflows: hosted evaluators with SLAs, versioning, and calibration profiles for different stacks; plug-ins for GitHub/GitLab/Jira
- Dependencies: robust APIs; cost-effective inference; safeguards against distribution shifts; transparent model updates
- Compute-aware multi-agent orchestration
- Sectors: AI infra, cloud optimization
- Tools/products/workflows: use critic scores to dynamically allocate sampling budgets across tasks and models (e.g., stop early on easy tasks, escalate for harder ones)
- Dependencies: orchestration frameworks that support adaptive budgets; reliable cross-model calibration; monitoring of cost-performance tradeoffs
- Active learning from live production traces
- Sectors: ML engineering, research
- Tools/products/workflows: continuous data selection via critics; schedule human labeling for the most ambiguous or high-impact segments; close the loop between deployment and training
- Dependencies: privacy-preserving pipelines; governance for human labeling; drift detection; robust retraining protocols
- Root-cause analytics and automated remediation
- Sectors: DevOps, SRE, quality engineering
- Tools/products/workflows: use rubric frequencies and survival metrics to identify systemic issues (e.g., tool misconfiguration); trigger automated playbooks to fix recurring problems
- Dependencies: integration with incident tooling; reliable causal interpretations; change-management guardrails
- Regulatory guidance for AI-assisted software changes
- Sectors: finance, healthcare, government
- Tools/products/workflows: incorporate critic-based evaluation and rubric auditing into compliance frameworks (e.g., documentation of AI change assessments, mandatory human oversight for flagged categories)
- Dependencies: collaboration with regulators; evidence that rubric-supervised critics reduce risk; standardized reporting formats
Notes on assumptions and dependencies (common to many applications)
- Access to real-world interaction traces and commit/PR metadata; segment extraction and attribution pipelines must be accurate and privacy-compliant.
- Outcome proxies (code survival, PR merge) are noisy and context-dependent; calibration and continuous monitoring are essential.
- Cross-backbone generalization is strongest when the agent scaffold is consistent; substantial changes in tools or workflows may require re-calibration or re-training.
- Rubric definitions influence behavior; organizations should audit and adapt the taxonomy to their domain and risk posture.
- Human-in-the-loop review remains critical, especially in regulated or safety-critical contexts; critics should be one signal among many, not the sole arbiter.
Glossary
- A/B testing: A method for comparing two system variants through controlled experiments to assess performance differences. "allow for systematic benchmarking and A/B testing"
- Agent scaffold: The framework that orchestrates tool usage and interaction patterns for an agent. "We use OpenHands Agent SDK~\citep{wang2025openhands,wang2025openhandssoftwareagentsdk} as the agent scaffold, which supports file editing, bash execution, web browsing, and MCP~\citep{mcp2025intro}."
- AUC: Area Under the ROC Curve; a measure of a classifier’s ability to rank positives higher than negatives. "On real-world data, they perform at or below random: AUC 0.48 for PR merge and 0.45 for code survival"
- BCE-floor: A Binary Cross-Entropy training variant that treats only perfect outcomes as positive labels. "BCE-floor (positive label only when survival=1)"
- BCE-round: A Binary Cross-Entropy training variant that rounds continuous outcomes to positives above a threshold. "BCE-round (positive label when survival )"
- Benjamini--Hochberg FDR correction: A statistical procedure to control the false discovery rate across multiple hypothesis tests. "control for multiple comparisons using Benjamini--Hochberg FDR correction."
- Best-of- selection: An inference-time strategy that samples multiple trajectories and selects the highest-scoring one. "enable inference-time scaling via best-of- selection"
- Code survival: The fraction of a segment’s code contributions that remain in the final merged diff. "we define code survival, which measures what fraction of a segment's code contributions persist in the final merged diff:"
- Commit attribution: The process of linking repository commits back to the agent segments that produced them. "For commit attribution, we extract commit SHAs from tool outputs and prioritize precision"
- Context condensation: A technique to compress conversation history while preserving salient details. "Real-world conversations can extend indefinitely (e.g., via context condensation, \citealt{smith2025-openhands-context-condensensation})"
- Credit assignment: The RL problem of determining which actions led to observed outcomes when feedback is delayed or noisy. "This also causes the typical credit assignment problem in reinforcement learning -- the final reward is only a noisy approximation of whether any particular agent action is accurate."
- Critic: A learned evaluator model that scores interaction segments for success or failure. "we propose a process to learn a ``critic'' model from sparse and noisy interaction data"
- Critic Rubrics: A taxonomy of 24 trace-observable behavioral features used to supervise critic learning. "we introduce Critic Rubrics, a rubric-based supervision framework with 24 behavioral features that can be derived from human-agent interaction traces alone."
- Cross-backbone results: Evaluation of methods across agents using different underlying LLM architectures to test generalization. "Cross-backbone results (#1{tab:cross-agent}) show this gain is robust"
- Early stopping: An inference-time policy that halts further attempts once a critic score exceeds a threshold. "enable early stopping (+17.7 with 83\% fewer attempts)"
- FDR-adjusted -value: A hypothesis test -value corrected under false discovery rate control. "red indicates FDR significance (, where is the FDR-adjusted -value)."
- Fisher's exact test: A statistical test for assessing association in contingency tables, suitable for small samples. "We test significance with Fisher's exact test and control for multiple comparisons using Benjamini--Hochberg FDR correction."
- Frontier reasoning model: A high-capability LLM optimized for complex reasoning tasks used for rubric annotation. "We run annotation at scale via batch API calls with a frontier reasoning model (o3 with high reasoning effort)."
- Inference-time scaling: Improving performance by sampling and ranking outputs at inference rather than relying solely on training. "enable inference-time scaling via best-of- selection"
- Left truncation: Dropping tokens from the beginning of a long context to fit the model’s window while preserving recent information. "We use a 64K context length with left truncation to preserve recent context."
- MCP: A protocol/interface for tool integration within agent environments. "and MCP~\citep{mcp2025intro}"
- Mean Reciprocal Rank (MRR): A ranking metric averaging the reciprocal of the rank of the first correct item. "MRR"
- MSE regression: Training to predict a continuous target by minimizing mean squared error. "and MSE regression on the continuous survival score."
- Multi-task critic: A critic model that jointly predicts rubric features and segment success. "train a semi-supervised, multi-task critic that predicts both rubric features and segment success."
- PR merge: A binary outcome indicating whether a pull request is accepted and merged. "PR merge success is a binary indicator of whether the associated PR was accepted and merged."
- Process-based supervision: Guidance derived from intermediate behaviors and steps rather than final outcomes. "enabling a process-based supervision scheme applicable to both real-world and benchmark traces."
- Reward model: A model that estimates the reward or quality of outputs to guide RL training or selection. "which can then be used both as a reward model for either RL-based training or inference-time scaling."
- Rubric supervision: Training that leverages rubric-derived behavioral labels as auxiliary signals. "rubric supervision yields a large end-task gain"
- Segment: A self-contained unit of interaction from a user request to an agent’s finish action. "we represent both benchmark traces and real-world interactions as segments"
- Semi-supervised objective: A training setup combining sparse outcome labels with dense auxiliary labels to leverage unlabeled data. "Using a semi-supervised objective, we can then jointly predict these rubrics and sparse human feedback (when present)."
- SFT (supervised fine-tuning): Further training of an LLM on curated labeled examples to specialize behavior. "supervised fine-tuning (SFT)"
- SWE-bench: A software engineering benchmark evaluating agents on code tasks with unit tests. "on SWE-bench (Best@8 +15.9 over Random@8 over the rerankable subset of trajectories)"
- SWE-Gym: A benchmark/environment for training and evaluating coding agents under simulated tasks. "We additionally include 4,238 trajectories from SWE-Gym~\citep{pan2025training} for training and evaluate on SWE-bench~\citep{DBLP:conf/iclr/JimenezYWYPPN24}."
- Trajectory: The sequence of user messages, agent actions, and observations in an interaction episode. "We write a full interaction trajectory as"
- Verified outcome supervision: Labeling success/failure via an external checker (e.g., unit tests). "provide verified outcome supervision: an agent attempt is labeled successful if it satisfies an external checker (e.g., unit tests pass)"
- vLLM: An inference engine/runtime for serving LLMs efficiently. "critic uses self-hosted vLLM."
Collections
Sign up for free to add this paper to one or more collections.

