RLAC: Reinforcement Learning with Adversarial Critic for Free-Form Generation Tasks
Abstract: Open-ended generation tasks require outputs to satisfy diverse and often implicit task-specific evaluation rubrics. The sheer number of relevant rubrics leads to prohibitively high verification costs and incomplete assessments of a response, making reinforcement learning (RL) post-training with rubric-based rewards difficult to scale. This problem is exacerbated by the fact that often the best way to combine these rubrics into one single reward is also highly prompt-specific. We propose Reinforcement Learning with Adversarial Critic (RLAC), a post-training approach that addresses these challenges via dynamic rubric verification. Our approach employs a LLM as a critic that dynamically identifies only the most likely failure modes (e.g., a factual error or unhandled edge case), which are then verified by an external validator to optimize both generator and critic jointly. By training both the generator and the critic, this game enhances the critic's error detection and the generator's output quality while reducing required verifications. Our experiments demonstrate that RLAC improves factual accuracy in text generation and correctness in code generation, while also outperforming exhaustive verification and reward model methods. We show that dynamic critics are more effective than fixed critics, showcasing the potential of RLAC for scaling RL post-training to free-form generation tasks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
RLAC: Teaching AI to Improve with a Smart “Critic” and a Real Checker
1) What this paper is about (big picture)
This paper introduces a new way to train AI systems that write text or code. These tasks are “open-ended,” meaning there isn’t just one right answer, and there are many rules a good answer should follow (like being factual, clear, safe, and so on). Checking all those rules every time is slow and expensive. The paper’s method, called RLAC (Reinforcement Learning with Adversarial Critic), makes this cheaper and more effective by training two AIs together:
- a generator (the one that writes), and
- a critic (the one that guesses where the generator might be wrong).
A separate tool (a validator) then checks whether the critic is right using real tests (like fact-checking or running code). Both the generator and the critic learn from this feedback.
2) What questions the paper asks
In simple terms, the paper asks:
- How can we train AI to produce better free-form answers (like biographies or code) without checking every single rule each time?
- Can a “smart critic” focus checking on the most likely mistakes, so we save time and still improve quality?
- Will this approach avoid “reward hacking,” where an AI learns to game a scoring system instead of truly getting better?
3) How the method works (in everyday language)
Think of the process like a classroom with three roles:
- The writer (generator) tries to produce a good answer.
- The peer reviewer (critic) carefully points out one thing that’s likely wrong (for example, “I think this fact about a person’s birth year is incorrect,” or “This code probably fails when the input is empty”).
- The official checker (validator) tests that specific point for real. For text, it might check the fact on Wikipedia. For code, it might run a test case.
What happens next:
- If the critic’s suspicion is correct (the point really is wrong), the critic gets rewarded for a good catch, and the generator learns to avoid that mistake.
- If the critic is wrong (the point is actually fine), the generator gets rewarded for producing something solid.
Over time, this “adversarial game” helps:
- the critic get better at spotting real weaknesses, and
- the generator get better at fixing them.
Why this is efficient: instead of checking every possible rule, the system checks just the most suspicious one each time, chosen by the critic. The validator keeps the process honest by using real, objective checks (not just opinions).
A note on training: the paper uses a stable training recipe (called DPO) to update both the generator and critic using simple “better vs. worse” signals. You don’t need to know the math—think of it as learning from clear wins and losses in this game.
4) What they found (main results and why they matter)
They tested RLAC on two types of tasks:
- Factual text (biographies):
- RLAC made the AI more factual than strong baselines.
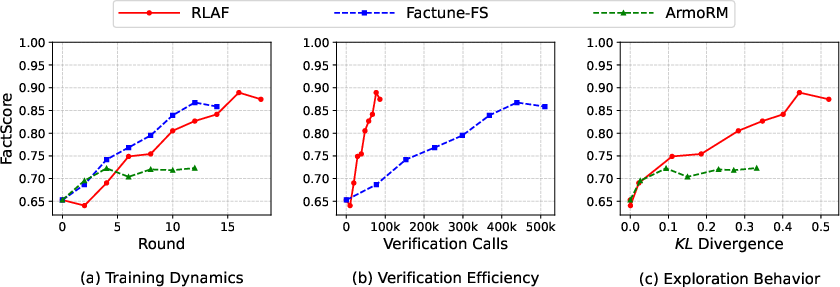
- Example: For 8-sentence biographies using a modern 8B model, RLAC reached a higher factual score (FactScore 0.889) than a method that checks all facts (0.867).
- It also used far fewer checks—about 5.7 times fewer verification calls—saving a lot of time and cost.
- Code generation:
- RLAC beat strong baselines across popular benchmarks (HumanEval, MBPP, BigCodeBench, LiveCodeBench).
- It did so while using only 9% of the training data some competitor methods used.
- It also ran far fewer tests during training (about a 97.5% reduction compared with a method that tries to check everything).
- Importantly, RLAC avoided “reward hacking” that can happen with learned judges (reward models). Those models can be tricked; RLAC’s real checks (validators) are harder to game.
Extra insights from ablations (controlled comparisons):
- If the validator (checker) is noisy or unreliable, training gets worse—so having a trustworthy checker matters.
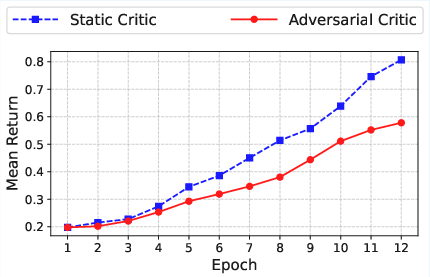
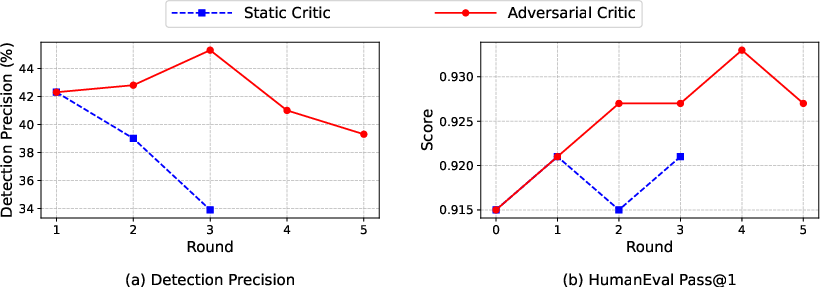
- A frozen or “static” critic isn’t great. The generator quickly learns its patterns and sneaks past it. A critic that keeps learning (adapts) works much better and keeps the pressure on.
Why this matters: RLAC improves quality while lowering the cost of checking. And it focuses the AI on fixing real errors, not on exploiting flaws in a scoring system.
5) Why this could be important in the long run
- Cheaper, scalable training: You don’t need to list and test every possible rule. The critic points to the most useful tests, and the validator confirms them.
- More reliable learning: Because the validator uses real checks (like running code or fact lookups), the AI is less likely to “cheat the score.”
- Broadly useful: The idea could extend to many open-ended tasks—writing stories, answering complex questions, or scientific text—where there are lots of “rules” but checking all of them every time is too costly.
- Better safety and quality: A dynamic critic can constantly seek out the AI’s current weaknesses, helping the model improve in targeted, meaningful ways.
In short, RLAC is like training an AI writer with a sharp-eyed reviewer and a trustworthy referee. By checking just the most likely problem each time—and learning from it—the AI gets better faster, with less effort and less chance of gaming the system.
Knowledge Gaps
Below is a single, focused list of the paper’s unresolved knowledge gaps, limitations, and open questions. Each item is concrete and actionable for future research.
- Dependence on reliable external validators: RLAC assumes access to accurate, binary validators (e.g., FactScore, test execution). How to extend RLAC to domains lacking robust validators, or to validators with uncertain/soft judgments?
- Validator noise and robustness: The paper shows noisy validation degrades training but offers no principled mitigation (e.g., repeated checks, uncertainty calibration, robust objectives). What techniques best harden RLAC against validator errors and flakiness?
- Theoretical guarantees and convergence: The min–max reformulation is claimed equivalent to optimizing all rubrics, but no formal proof, convergence analysis, or sample-complexity bounds are provided, especially under approximate critics/validators and DPO updates.
- Critic optimality and coverage: RLAC’s performance hinges on the critic finding true worst-case rubrics. How to measure and improve critic recall of diverse failure modes, avoid focusing on trivially verifiable rubrics, and ensure coverage across long-tail errors?
- Diversity vs. redundancy in rubric proposals: The critic currently proposes a small number of rubrics per output. What strategies (e.g., diversity-promoting decoding, determinantal sampling, curriculum over rubrics) best increase informative coverage without exploding verification cost?
- Sensitivity to hyperparameters (K, N, β): The paper fixes generator samples K and critic proposals N, and DPO β, without sensitivity analysis. How do these settings affect stability, cost, and final quality across tasks and model sizes?
- Reward shaping beyond binary feedback: RLAC uses binary rewards. Would graded or probabilistic feedback (e.g., factuality confidence, partial test coverage) improve stability and sample efficiency?
- Compute and wall-clock efficiency: Verification calls are counted, but total training cost (LLM inference for generator and critic, validator latency) and wall-clock time are not reported. How does RLAC’s end-to-end cost compare to enumerative and RM baselines?
- Scaling to larger models and longer outputs: Experiments use ~7–8B models and up to 8 sentences. How does RLAC behave with larger LLMs, long-form generation (e.g., multi-page writing), and increased output entropy?
- Generalization across domains: RLAC is evaluated on biographies and Python coding. Can it generalize to scientific writing, multi-hop QA, planning, dialogue safety, or multimodal tasks where rubrics are more subjective or partially unverifiable?
- Inference-time usage: The critic is only used for training. Could an inference-time critic (e.g., self-check before output) further improve reliability, and how would that affect latency and user experience?
- Reward hacking and collusion risks: The generator might learn patterns that systematically evade the critic/validator without improving true quality. What guardrails (e.g., adversarial training with ensembles, randomized validators, anti-collusion checks) reduce such degeneracy?
- Validator–critic interface design: The critic outputs natural-language rubrics, but mapping to validators (parsing, test-case synthesis) is under-specified. How to standardize rubric schemas, prevent injection/format errors, and verify rubric validity before execution?
- Formal verification for code: The approach relies on test-case enumeration and a “simulated solution” validator. How can RLAC integrate fuzzing, symbolic execution, or formal methods to detect deeper semantic bugs beyond finite tests?
- Multi-language and multi-paradigm code: Only Python is evaluated. How does RLAC perform on other languages (e.g., Java, C++), multi-file repos, or API-dependent tasks where validators are harder to construct?
- Benchmark contamination and evaluation rigor: Code benchmarks (e.g., LiveCodeBench, HumanEval Plus) have known contamination risks. What measures (e.g., strict decontamination, blinded evaluation, cross-benchmark validation) ensure robust performance claims?
- Human-centric quality trade-offs: Factuality is improved under sentence-length constraints, but impacts on fluency, coherence, style, and user preference are not measured. How does RLAC affect subjective quality dimensions, and can multi-criteria validators address this?
- Critic architecture and training objectives: The paper uses DPO for both policies but does not compare with PPO/GRPO or KL-regularized variants. Which objectives and regularizations maximize stability and prevent collapse in the min–max dynamic?
- Reference policies and initialization choices: Generator and critic share backbone models and are updated with reference policies; potential coupling effects are not analyzed. Does critic–generator backbone sharing introduce biases or information leakage?
- Adaptation speed and stability: Training exhibits an initial drop in factuality. What schedules (e.g., warm-start critic, alternating update ratios, critic lag, entropy bonuses) reduce early instability and accelerate convergence?
- Multi-rubric satisfaction vs. single-rubric checking: RLAC trains against one proposed rubric at a time. Under what conditions does optimizing a single adversarial rubric per step approximate “satisfy all rubrics,” and when is multi-rubric verification necessary?
- Measuring critic effectiveness: Besides validator outcomes and detection rates, richer metrics (e.g., precision–recall over error types, coverage of rubric taxonomy) could better quantify critic quality. How to build such diagnostics and feedback loops?
- Open-set rubrics and ambiguous tasks: Many free-form tasks involve subjective or evolving rubrics (e.g., creativity, fairness). How to incorporate soft/latent rubric models, disagreement-aware validators, and multi-annotator consensus into RLAC?
- Safety and ethics: The adversarial critic may push the generator toward risk-averse or overly conservative outputs to avoid failures. How to balance safety, creativity, and informativeness in domains with sensitive content?
- Reproducibility and transparency: Numerous LaTeX/prompting details are deferred to the appendix/website; code, prompts, and validator implementations are not exhaustively specified. Providing full artifacts, seeds, and configs would improve reproducibility.
- Practical deployment: RLAC’s multi-sample generation and critic proposals add latency and cost. What deployment strategies (e.g., distilling the critic into the generator, caching rubric patterns, adaptive stopping) make RLAC feasible in production systems?
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging RLAC’s adversarial critic, external validator, and stable policy optimization (e.g., DPO) to improve factuality and correctness with significantly fewer verification calls.
- Enterprise LLM factuality tuning (software)
- Use RLAC in post-training to improve factual responses for internal assistants, knowledge bots, and search copilots while cutting verification calls by 4–6× compared to exhaustive methods; evidence: FactScore gains (e.g., 0.889 vs. 0.867) at far fewer validator calls.
- Product/workflow: RLAC training loop that plugs into retrieval-based validators (e.g., Wikipedia/enterprise KB checks) and produces prompt-specific, verifiable supervision.
- Assumptions/dependencies: Reliable fact validators, domain-specific knowledge bases, sufficient compute; early-stage performance dip as critic learns.
- Coding assistants and CI augmentation (software, DevTools)
- Integrate a critic that generates targeted test cases to expose likely code errors; RLAC training reduces reliance on exhaustive tests, achieving higher average Pass@1 with ~97.5% fewer executed tests during training.
- Product/workflow: “Adversarial Test Generator” plugin for IDEs/CI that proposes tests per code change and validates via execution; feeds RLAC-tuned models or runs critic-in-the-loop inference.
- Assumptions/dependencies: Sandboxed execution, language-specific validators, robust runtime environment; coverage depends on critic quality.
- Editorial fact-checking co-pilot (media, publishing)
- For biographies, reports, and long-form content, use the critic to surface the most suspicious claims for verification, reducing manual effort while increasing precision.
- Product/workflow: A newsroom tool that highlights high-risk facts and automates checks via retrieval validators; integrates with CMS.
- Assumptions/dependencies: Access to authoritative sources, entity/linking tools; validators must be accurate and up-to-date.
- Customer support and knowledge-base QA (enterprise support)
- Improve bot reliability by dynamically checking claims most likely to be wrong against KBs or policies before responding.
- Product/workflow: “Critic-in-the-loop response” where the agent proposes one failure rubric (e.g., policy mismatch) and validates it pre-answer.
- Assumptions/dependencies: High-quality KB, latency budget for validation; guardrails against incomplete policy coverage.
- Safety and compliance checks for LLM outputs (policy, safety)
- Use the critic to propose likely violations (e.g., disallowed content, unsafe instructions), verifying them via rule-based or classifier validators.
- Product/workflow: Safety critic + validator pipeline integrated with red-team checks; monitors reward hacking by tracking KL/factuality.
- Assumptions/dependencies: Reliable safety validators and rules; careful tuning to avoid overblocking; transparency for audits.
- Targeted data labeling for RLHF (data operations)
- Reduce annotation cost by having the critic propose the most informative rubric or failure mode for human raters to label or verify.
- Product/workflow: “Adversarial labeling planner” that prioritizes instances and rubrics where the generator is weakest.
- Assumptions/dependencies: Human-in-the-loop processes, annotation tooling; balanced sampling to avoid biased critic focus.
- Dynamic benchmark augmentation (academia, evaluation)
- Use critics to generate rubrics/test cases that expose model blind spots without enumerating all criteria, improving evaluation coverage for free-form tasks.
- Product/workflow: “Rubric generator” that adds high-value checks to existing benchmarks; tracks detection rate over training.
- Assumptions/dependencies: Validator availability; calibration to avoid trivial or redundant rubrics.
- Healthcare documentation and clinical assistants (healthcare)
- Before emitting clinical summaries or recommendations, the critic flags likely incorrect or non-compliant claims (e.g., contraindications) and validates against medical knowledge bases.
- Product/workflow: Clinical drafting assistant with critic-led checks for contraindications, dosing ranges, guideline adherence.
- Assumptions/dependencies: Trusted medical KBs and policies, strict privacy/security; liability-aware deployment.
- Financial reporting and compliance drafting (finance)
- The critic identifies high-risk claims (e.g., revenue recognition details) for verification against filings and internal systems.
- Product/workflow: Compliance drafting co-pilot with critic-driven audit of key statements; integrates with document repositories (EDGAR, ERP).
- Assumptions/dependencies: Data access, audit trail requirements; validators must reflect current regulations and filings.
- Education: essay and proof feedback (education)
- Automated feedback systems can use the critic to prioritize which rubric to check (e.g., logical steps in a proof, factual references in essays) and validate them to give targeted guidance.
- Product/workflow: “Rubric-first grader” that surfaces one high-impact check per submission to reduce grading time and increase instructional value.
- Assumptions/dependencies: Institution-specific rubrics, validators for citations/math; fairness and transparency.
Long-Term Applications
These applications require further research, scaling, domain validators, and/or standardization to reach production maturity.
- Generalized scientific text generation and verification (academia, software)
- Train models to produce methods/claims with critic-proposed checks (e.g., reproducibility, dataset alignment) validated via symbolic math, statistical analysis, or pipelines.
- Tools/workflows: Scientific RLAC stack connecting critics to computational notebooks and validators for stats, plots, and references.
- Dependencies: Robust, multi-step validators; provenance tracking; domain expert oversight.
- Full-stack code agents with scalable test generation (software, robotics)
- RLAC-trained agents create and maintain test harnesses for large codebases, covering edge cases across languages and environments.
- Tools/workflows: Cross-language critic + execution sandboxes, dependency-aware validator orchestration.
- Dependencies: Environment simulation, flaky test mitigation, build system integration.
- Multi-modal RLAC for VLMs and robots (robotics, vision-language)
- Extend critics to propose verifiable rubrics over images/video/actions (e.g., grasp stability, collision avoidance), validated via simulators or sensors.
- Tools/workflows: Simulator-validated critic proposals; on-policy data collection loops for embodied tasks.
- Dependencies: High-fidelity simulators, hardware-in-the-loop validation, safe exploration protocols.
- Personalized tutoring and formative assessment (education)
- Dynamic rubric selection tailored to student weaknesses (e.g., specific algebra misconceptions) with targeted validators and adaptive curriculum.
- Tools/workflows: Tutor critic that models student profile to propose checks; validated via graded exercises and knowledge tracing.
- Dependencies: Student modeling, privacy-preserving analytics, pedagogical validation.
- AI governance and audit standards (policy)
- Regulators could mandate adversarial-verification workflows (critic + validator) for certain high-stakes deployments, reducing reward hacking and improving auditability.
- Tools/workflows: Standardized “Verification Profiles” per domain (health, finance, safety) with traceable logs of critic proposals and validator outcomes.
- Dependencies: Sector-specific validator standards, auditing infrastructure, legal frameworks.
- Compliance-by-design drafting for legal documents (legal, policy)
- Critic proposes likely non-compliant clauses or ambiguous language; validators reference case law and statutes.
- Tools/workflows: Legal drafting assistant with adversarial compliance checks and citation validation.
- Dependencies: Comprehensive legal KBs, jurisdictional updates, risk management.
- Energy and infrastructure planning (energy)
- Use critic-generated constraints (e.g., grid stability, emission limits) to test planning outputs; validators run simulations to confirm feasibility.
- Tools/workflows: Planning critic linked to power system simulators (e.g., MATPOWER) and policy validators.
- Dependencies: Accurate models, high-quality data, scenario generation at scale.
- Finance: strategy stress testing and risk controls (finance)
- The critic proposes adverse scenarios and constraint checks (e.g., liquidity stress) for algorithmic strategies; validators simulate outcomes and compliance.
- Tools/workflows: “Adversarial stress tester” integrated with backtesting engines and risk dashboards.
- Dependencies: Realistic market simulators, robust risk models, governance oversight.
- Safety alignment across multi-attribute objectives (AI safety)
- Train safety critics to propose rubrics over honesty, harmlessness, fairness; validators combine rule-based checks and specialist models to reduce reward hacking across attributes.
- Tools/workflows: Multi-attribute RLAC pipelines with interpretable rubric logging and validation traces.
- Dependencies: Reliable multi-attribute validators, balance between objectives, post-hoc interpretability.
- Validator and critic ecosystems (software, standards)
- Marketplaces and standards for reusable validators (facts, code, safety) and critic modules tailored to domains, enabling plug-and-play RLAC across tasks.
- Tools/workflows: Interoperable APIs, evaluation cards for validators/critics, provenance and reliability scoring.
- Dependencies: Community adoption, security/privacy guarantees, benchmarking frameworks.
Notes on Assumptions and Dependencies
- Validator reliability is critical: noisy validators can destabilize training; dynamic critics mitigate but do not eliminate the need for trustworthy checks.
- Domain-specific knowledge bases and simulators are required to ground the critic’s proposals in verifiable criteria.
- Early training phases may see a temporary performance dip while the critic learns to identify informative rubrics; monitoring and staged rollout help.
- Compute and latency budgets must accommodate critic proposals and validation calls, particularly for inference-time checks.
- Robust logging/auditing is necessary to prevent reward hacking and ensure traceability of critic–validator decisions.
Glossary
- AceCode-87K-hard subset: A curated subset of code problems used for training and evaluation in code generation studies. "For training data, we use the AceCode-87K-hard subset~\citep{zeng2025acecoder}, consisting of approximately 22K problems."
- AceCoder-RM: A reward-model-based reinforcement learning method for code generation that relies on a learned scalar judge. "AceCoder-RM, which uses RL with AceCodeRM-7B trained on approximately 300K preference pairs constructed from AceCode-87K dataset."
- AceCoder-Rule: An enumerative reinforcement learning method for code generation using rule-based binary rewards from test execution. "AceCoder-Rule, which employs RL with rule-based binary rewards from test execution;"
- Adversarial critic: A learned critic policy that adaptively proposes failure-inducing rubrics during training to challenge the generator. "In contrast, the adversarial critic maintains a stable detection rate greater than 39 by continuously adapting to the evolving behavior of the generator."
- Adversarial game: A min-max training formulation where a generator and critic compete, improving robustness and error detection. "We introduce Reinforcement Learning with Adversarial Critic (RLAC), which formulates the problem as an adversarial game between a generator and a {\em critic}."
- Auto-regressive decoding: A generation process where the model predicts tokens sequentially, conditioning on prior outputs. "the critic is prompted to generate a natural language output representing a rubric through auto-regressive decoding."
- BigCodeBench: A benchmark suite for evaluating code generation models across diverse programming tasks. "We evaluate code generation performance using widely studied benchmarks: HumanEval (Base and Plus)~\citep{chen2021evaluatinglargelanguagemodels, liu2023codegeneratedchatgptcorrect}, MBPP (Base and Plus)~\citep{austin2021programsynthesislargelanguage, liu2023codegeneratedchatgptcorrect}, BigCodeBench~\citep{zhuo2024bigcodebenchbenchmarkingcodegeneration}, and LiveCodeBench (V4)~\citep{jain2024livecodebenchholisticcontamination}."
- Binary verification function: A function that returns 1 if a specific rubric is satisfied by the generated output and 0 otherwise. "We assume access to a binary verification or reward function that returns 1 if a generated output satisfies the rubric on instruction , and returns 0 otherwise."
- DPO objective: Direct Preference Optimization, a training objective that optimizes a policy using binary preferences without explicit reward scaling. "the generator is updated using the DPO objective~\citep{rafailov2023dpo} with respect to the reference generator $\pi^g_{\text{ref}$:"
- Enumerative verification: Explicitly listing and checking all fine-grained criteria to evaluate outputs. "Enumerative verification explicitly extracts and checks every atomic fact before aggregating a scalar reward, which is accurate but expensive."
- External validator: A domain-specific tool or process that checks whether a proposed rubric is satisfied by the output. "which are then verified by an external validator"
- FactScore: A metric for factual precision that evaluates the correctness of atomic claims in generated text. "We use factual precision of the output (as defined by FactScore~\citep{min2023factscore}) as the primary metric"
- GRPO: An RL algorithm (Guided Reinforcement Policy Optimization) used for optimizing policies when evaluable outcomes exist. "we can solve this opimization problem via standard RL algorithms like PPO~\citep{schulman2017proximalpolicyoptimizationalgorithms} or GRPO~\citep{shao2024deepseekmathpushinglimitsmathematical}."
- HumanEval: A benchmark for assessing code generation accuracy on programming problems. "We evaluate code generation performance using widely studied benchmarks: HumanEval (Base and Plus)~\citep{chen2021evaluatinglargelanguagemodels, liu2023codegeneratedchatgptcorrect}, MBPP (Base and Plus)..."
- KL divergence: A measure of divergence between two probability distributions used to track exploration from a base model. "Figure~\ref {fig:training-dynamics}(c) measures exploration by tracking the KL divergence from the base model."
- KL regularization: A training constraint that penalizes deviation from a reference policy to prevent misalignment or collapse. "often necessitating additional constraints like KL regularization to avoid collapse."
- LiveCodeBench: A benchmark that evaluates code generation models in realistic, contamination-aware settings. "and LiveCodeBench (V4)~\citep{jain2024livecodebenchholisticcontamination}."
- LLM-as-judge: An approach where a LLM is prompted or trained to act as an evaluator of generated outputs. "RLHF-trained reward models or LLM-as-judge approaches~\citep{christiano2017deep,zheng2023judgingllmasajudgemtbenchchatbot} outsource the job of merging rubrics to a learned or prompted reward model"
- MBPP: The “Mostly Basic Programming Problems” benchmark for evaluating code synthesis. "MBPP (Base and Plus)~\citep{austin2021programsynthesislargelanguage, liu2023codegeneratedchatgptcorrect}"
- Min-max form: An optimization formulation where the generator maximizes performance against a minimizing critic. "Then we can rewrite Equation~\ref{eqn:minmax} into the equivalent min-max form:"
- On-policy: Training signals derived from the current model’s behavior rather than from an offline dataset. "it ensures that rewards are based on rubrics that are prompt-specific, adversarially chosen, and always on-policy."
- Pass@1: A code generation metric indicating the percentage of problems solved correctly by the first attempt. "We use Pass\@1 as a primary metric."
- PPO: Proximal Policy Optimization, an RL algorithm for policy gradient methods that stabilizes updates. "we can solve this opimization problem via standard RL algorithms like PPO~\citep{schulman2017proximalpolicyoptimizationalgorithms} or GRPO~\citep{shao2024deepseekmathpushinglimitsmathematical}."
- Preference-based optimization: RL training that optimizes models using pairwise or scalar preferences rather than explicit task rewards. "reinforcement learning (RL) methods that perform general preference-based optimization~\citep{christiano2017deep, ouyang2022training}"
- Reward hacking: Exploiting flaws in a reward signal to increase scores without genuinely improving output quality. "this often leads to reward hacking~\citep{ziegler2019finetuninglanguagemodelshuman, gao2023scaling, skalse2022defining, eisenstein2023helping}"
- Reward model: A learned function that predicts a scalar score for outputs, used as a proxy for true task rewards. "RLHF~\citep{christiano2017deep} trains a single proxy reward model from offline human preference data."
- RLHF: Reinforcement Learning from Human Feedback, a framework using human preference data to train reward models and policies. "RLHF~\citep{christiano2017deep} trains a single proxy reward model from offline human preference data."
- Rubric: A verifiable criterion or property that a generated output should satisfy. "outputs must satisfy many task-specific requirements, which we refer to as rubrics."
- Static critic: A fixed, non-adapting critic used during training that can be exploited by the generator over time. "we freeze the critic model, referred to as a {\em static} critic rather than training it adversarially with the generator, to evaluate the importance of adversarial joint training."
- Stochastic policy: A policy that outputs a distribution over actions (or rubrics), enabling randomized selection. "we introduce a critic , modeled as a stochastic policy that takes an instruction–generation pair (s,a) as input and outputs a rubric c"
Collections
Sign up for free to add this paper to one or more collections.