- The paper presents a unified framework with multi-granularity motion orchestration combining body, face, and hands for robust character animation.
- It leverages Diffusion Transformers to capture long-range spatiotemporal dependencies while ensuring expression accuracy and identity preservation.
- The framework achieves over 10× computational reduction through advanced acceleration techniques, outperforming both commercial and open-source baselines.
Technical Overview
Kling-MotionControl, as detailed in "Kling-MotionControl Technical Report" (2603.03160), presents a unified framework for image-based character animation leveraging Diffusion Transformers (DiTs). The core architectural innovation resides in its multi-granular motion orchestration, wherein heterogeneous motion representations for body, face, and hands are learned and fused within a progressive multi-stage training regime. This "divide-and-conquer" strategy allows for robust structural stability in large-scale movements (e.g., limbs and torso) while maintaining fine-grained articulatory expressiveness for facial micro-expressions and intricate finger gestures. The backbone adopts DiTs due to their scalability and ability to capture long-range spatiotemporal dependencies, conforming to the current paradigm shift in video diffusion models.

Figure 1: Kling-MotionControl produces high-fidelity videos with precise, multi-granular motion control and robust, natural cross-identity transfer—all while preserving reference appearance.
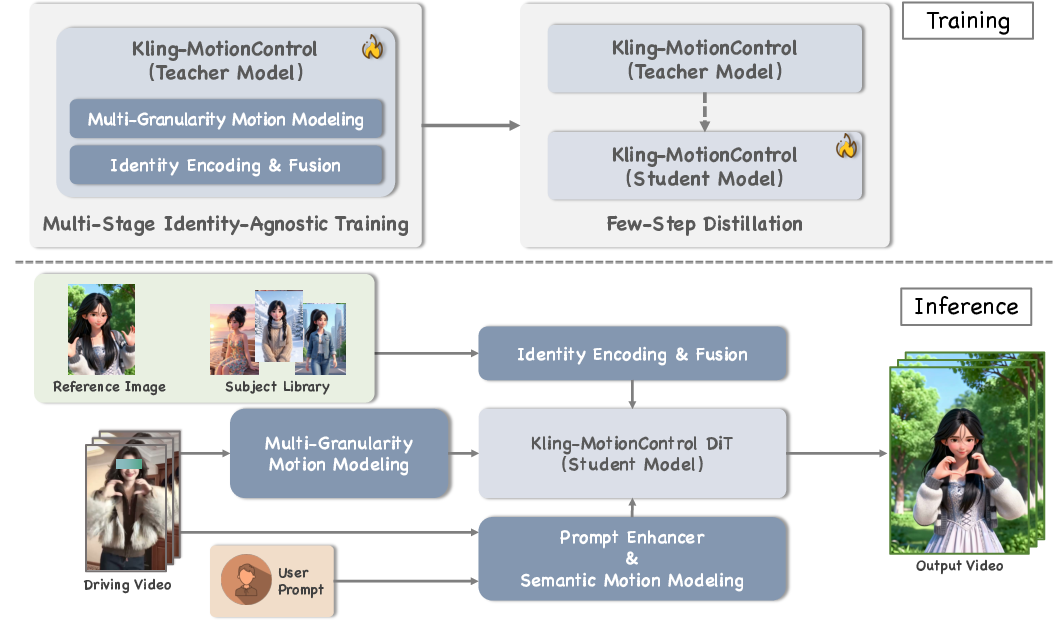
Figure 2: Training and inference pipeline overview, illustrating multi-granularity modeling, subject library integration, and acceleration components.
Adaptive cross-identity motion transfer is operationalized through identity-agnostic learning. By decoupling geometric motion patterns from driving subjects and injecting semantic motion modeling (e.g., intent labels such as "facepalm"), Kling-MotionControl achieves robust motion retargeting across identity and morphology domains. Identity preservation is addressed with explicit encoding and fusion mechanisms, complemented by a subject library which supports multi-view or video-based reference contexts, thus ensuring appearance fidelity during extreme poses and lengthy generations.
3D perception is embedded via large-scale multi-view supervision, supporting both flexible character re-orientation and cinematic camera control through native text descriptions. Intelligent prompt enhancement guarantees precise motion adherence and responsive text-based scene manipulation, spanning elements such as clothing and background.
Efficient inference is attained with advanced acceleration: dual-branch sampling, multi-stage distillation, and classifier-free guidance gradient merging yield over 10× reduction in computational overhead without sacrificing output quality. The framework is trained on a meticulously curated and annotated dataset comprising diverse character types, motion dynamics, and scene contexts, establishing professional-grade generation capabilities.
Comparative Evaluation and Results
The evaluation protocol utilizes a human-centric GSB (Good/Same/Bad) subjective scoring system over 150 test cases, allowing fine-grained assessment along visual quality, dynamic consistency, identity preservation, motion accuracy, and expression accuracy. Kling-MotionControl demonstrates superior or comparable performance over all leading commercial (Dreamina, Runway Act-Two) and state-of-the-art open-source (Wan-Animate) baselines.
Notably, Kling-MotionControl achieves marked improvements in overall preference and visual fidelity, with preference rates far exceeding the baselines in quantitative and qualitative measures. The model's strict preservation of subject identity, expressive motion reproduction, and robustness in dynamic scenarios are evidenced across both extreme and rapid motion sequences as well as cross-identity transfers, including child-to-adult and realistic-to-cartoon retargeting.
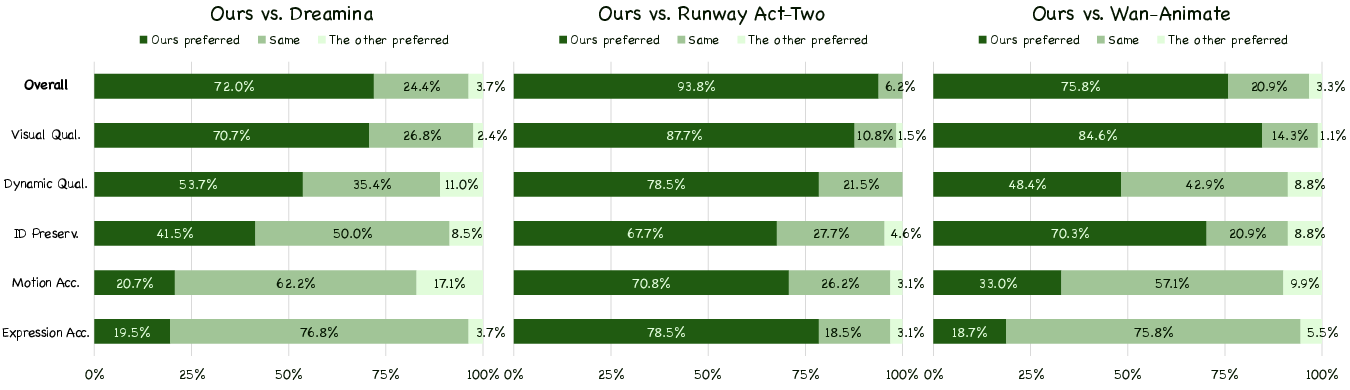
Figure 3: GSB evaluation preference rates, illustrating Kling-MotionControl's consistent advantage over Dreamina, Runway Act-Two, and Wan-Animate across all critical dimensions.

Figure 4: Qualitative comparisons: Kling-MotionControl distinctly outperforms baselines in facial expressiveness, hand gesture accuracy, and structural integrity during complex motion.
Objective results confirm the model's ability to generate high-fidelity holistic character animations with accurate imitation of both macro and micro motion cues, all the while strictly maintaining reference identity and offering robust text-based control for scene elements (e.g., clothing, background).

Figure 5: Kling-MotionControl delivers adaptive, high-quality motion transfer across various identity domains and animation scenarios, demonstrating excellent visual and semantic controllability.
Kling-MotionControl is situated at the forefront of full-body character animation. Earlier works bifurcated into body-only (e.g., Animate Anyone [animateanyone], MimicMotion [zhang2024mimicmotion], Champ [zhu2024champ]) and face-only (e.g., LivePortrait [guo2024liveportrait], XPortrait [xie2024xportrait], SkyReels-A1 [qiu2025skyreels], X-Nemo [zhao2025x]) paradigms, lacking coordination across granularities or robust cross-identity disentanglement. Recent holistic methods (Wan-Animate [cheng2025wananimate], DreamActor-M1 [luo2025dreamactor]) still manifest severe limitations in identity drift, artifact generation, and controllability. Kling-MotionControl addresses these deficits via architectural and training innovations, incorporating advanced motion retargeting and identity encoding, complemented by semantic and 3D supervision.
Practical and Theoretical Implications
The model's architecture and results directly enhance virtual avatar creation, animation pipelines, and controllable generative video synthesis. Its cross-identity robustness and 3D awareness extend applications into stylized and non-human domains (e.g., anime, animals). The efficient inference acceleration unlocks scalable deployment in commercial and consumer settings. Integrating prompt-driven control enriches creative workflows, providing granular manipulation with high-fidelity outputs.
From a theoretical perspective, Kling-MotionControl validates the efficacy of unified DiT-based frameworks for multi-granular character modeling. The divide-and-conquer schema, geometric abstraction, semantic guidance, and identity fusion techniques represent strong advances. The approach is extensible to multimodal generation, reinforcement-based animation editing, and ontology-driven semantic motion modeling.
Future developments may prioritize further objective benchmarking, extension to more generalized domains (e.g., open-world action and environment synthesis), integration with multimodal guidance (audio, text, depth), and refinement of ethical safeguards (watermarking, content filtering, provenance tracking).
Conclusion
Kling-MotionControl establishes a robust paradigm for adaptive, high-fidelity character animation, outperforming both commercial and open-source counterparts via unified multi-granular motion modeling, adaptive identity transfer, 3D awareness, and efficient inference strategies. The framework's strong numerical and qualitative results substantiate its practical utility, while its architecture and dataset innovations extend theoretical boundaries in generative video modeling. Ongoing research should address ethical considerations, further expand cross-domain capabilities, and explore deeper semantic control avenues.

