KlingAvatar 2.0 Technical Report
Abstract: Avatar video generation models have achieved remarkable progress in recent years. However, prior work exhibits limited efficiency in generating long-duration high-resolution videos, suffering from temporal drifting, quality degradation, and weak prompt following as video length increases. To address these challenges, we propose KlingAvatar 2.0, a spatio-temporal cascade framework that performs upscaling in both spatial resolution and temporal dimension. The framework first generates low-resolution blueprint video keyframes that capture global semantics and motion, and then refines them into high-resolution, temporally coherent sub-clips using a first-last frame strategy, while retaining smooth temporal transitions in long-form videos. To enhance cross-modal instruction fusion and alignment in extended videos, we introduce a Co-Reasoning Director composed of three modality-specific LLM experts. These experts reason about modality priorities and infer underlying user intent, converting inputs into detailed storylines through multi-turn dialogue. A Negative Director further refines negative prompts to improve instruction alignment. Building on these components, we extend the framework to support ID-specific multi-character control. Extensive experiments demonstrate that our model effectively addresses the challenges of efficient, multimodally aligned long-form high-resolution video generation, delivering enhanced visual clarity, realistic lip-teeth rendering with accurate lip synchronization, strong identity preservation, and coherent multimodal instruction following.
First 10 authors:




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper describes KlingAvatar 2.0, a system that creates realistic videos of digital humans (avatars) who talk, move, and show emotions that match an audio track, images, and written instructions. It focuses on making long, high‑resolution videos that stay consistent over time, follow the user’s instructions closely, and can handle multiple characters speaking in the same scene.
Key Questions and Goals
Here are the main things the paper aims to solve:
- How can we generate long, high‑quality avatar videos without the visuals getting messy or “drifting” over time?
- How can we make the avatar’s face, lips, body, camera movement, and emotions match the audio, images, and text instructions all at once?
- How can we control several characters in the same video, making sure each one moves and speaks correctly and keeps their identity visible and consistent?
- How can we do all this efficiently so long videos can be made faster?
Methods and Approach (Explained Simply)
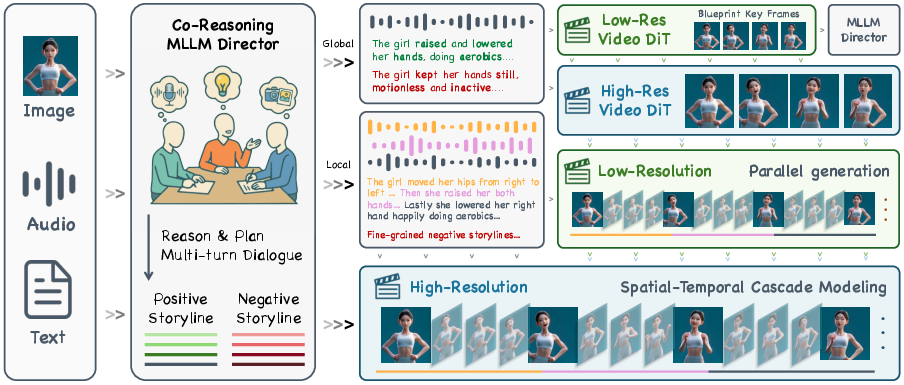
The authors combine smart planning (like a film director organizing scenes) with step‑by‑step video building (like sketching a storyboard and then adding detail). They also use AI models that understand different types of input (audio, images, text).
Spatial‑Temporal Cascade (building the video in layers)
Think of making a movie by first sketching rough scenes and then polishing them:
- Blueprint video (low‑resolution): The system first makes a small, rough version of the video that captures the overall story, motion, and scene layout. This is fast and helps plan the big picture.
- Keyframe upscaling: Important frames are sharpened into high‑resolution images so faces, clothes, and scenes look detailed and consistent with the character’s identity.
- Sub‑clip refinement with “first‑last frame” guidance: For each short piece of the video, the system locks in the beginning and ending frames and fills in the middle so the motion and expressions match the voice. This reduces “temporal drifting,” which is when the look or motion slowly slides off‑track in long videos.
- Audio‑aware transitions: The system uses the sound to shape how frames transition, improving lip sync and smooth movement.
- High‑res finishing: Finally, it upgrades the refined clips to full high resolution so the final video looks clean and sharp.
Technical terms explained:
- Diffusion models: Imagine starting with a noisy “snowy” picture and slowly clearing it up until a realistic image or video appears.
- DiT (Diffusion Transformer): A powerful brain for the diffusion process, based on transformers (the same kind of AI used in LLMs), tuned to work well on video.
Co‑Reasoning Director (a team of AI “assistants” planning the shots)
Picture a film director with three expert assistants:
- Audio expert: Listens to the speech, figures out what’s being said and how (tone, emotion, speed).
- Visual expert: Looks at the reference images and notes the person’s appearance and the scene.
- Text expert: Reads the instructions from the user and builds a clear plan.
These experts “talk” to each other in several rounds to resolve conflicts (like angry tone but a calm script) and fill in missing details (like camera moves or small gestures). They produce:
- Positive prompts: What the video should do (e.g., “smile gently, raise right hand, slow camera pan up”).
- Negative prompts: What the video should avoid (e.g., “no blur, no overly fast head turns, no sad expressions in a happy scene”).
This planning is organized shot‑by‑shot and aligned to the audio timeline so long videos stay logical and consistent.
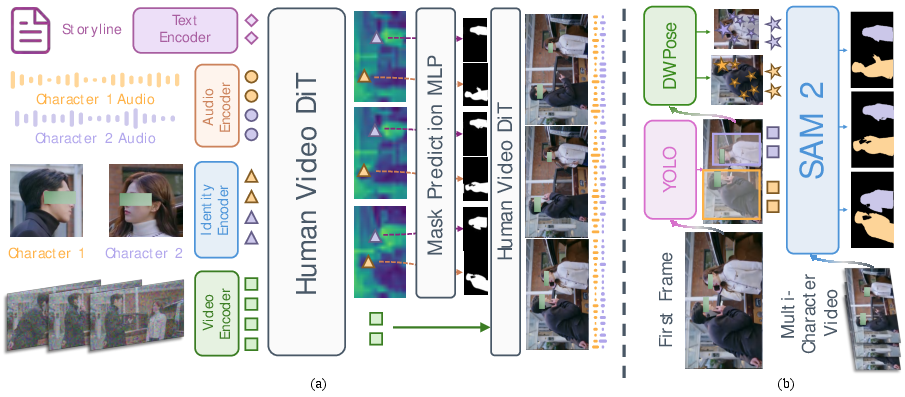
Multi‑Character Control (managing several people in one scene)
If multiple characters are talking:
- The system predicts a “mask” for each character (like tracing the outline of where each person is in the frame).
- It uses these masks to inject the correct audio into the right character’s area, so each person’s lips and expressions match their own voice.
- To train this, the authors built a large dataset and used automatic tools to detect people, their body points, and segment them across frames. This makes the model good at tracking identities and keeping everyone consistent.
Analogy: It’s like a coloring book where each person has their own outlined area; the system fills each area with the matching voice and motions without mixing them up.
Speed‑ups (making long videos faster to generate)
They use “distillation,” which is like training a faster student model to mimic a slower, very smart teacher model while keeping quality. They carefully pick time steps (like skipping ahead wisely) and combine multiple training tasks so the final system is both quick and good.
Main Findings and Why They Matter
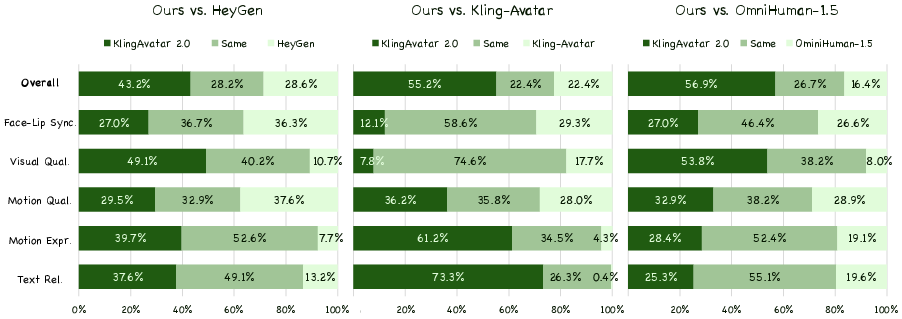
In tests comparing KlingAvatar 2.0 to other strong systems (HeyGen, Kling‑Avatar, OmniHuman‑1.5), human judges preferred KlingAvatar 2.0 more often across several aspects:
- Visual quality: Sharper details (hair, skin, teeth), stable lighting, and fewer artifacts.
- Lip sync and facial detail: Lips and teeth look real and move accurately with speech.
- Motion and camera control: Body and head movements are smooth and natural; camera paths follow instructions (like “bottom‑to‑top” moves) more precisely.
- Emotion and expressiveness: Emotions match the audio and text better, with richer, believable gestures and facial expressions.
- Instruction following: The system sticks to the user’s story and shot plan more closely, even for long videos.
- Efficiency and length: It can keep identity and story consistent for videos up to about 5 minutes, which is challenging.
Overall, the combination of shot planning, layered video construction, and multi‑character control makes the results more coherent and lifelike.
What This Means and Potential Impact
KlingAvatar 2.0 shows a practical path to making long, high‑resolution, realistic avatar videos that follow complex instructions across audio, images, and text. This could help:
- Education: Teachers or tutors create clear, engaging video lessons with personalized avatars.
- Training: Companies make realistic simulations for customer service or safety training.
- Entertainment and advertising: Creators produce character‑driven content (music videos, skits, ads) quickly and consistently.
- Personalized services: Assistants or hosts that speak in different languages with accurate lip sync and emotions.
As these systems get better, it will be important to use them responsibly—respecting privacy and consent, clearly labeling synthetic content, and avoiding misuse. Technically, the paper’s ideas (especially the co‑reasoning plan + cascade building) can guide future research on long, multimodal video generation beyond avatars, including more complex stories, environments, and interactions.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The following specific gaps and unresolved questions emerge from the paper and can guide future research:
- Objective evaluation is limited to subjective GSB; missing standardized quantitative metrics for lip-sync (e.g., LSE-C/LSE-D), identity preservation (face embedding similarity), motion fidelity (FVD/KVD), temporal stability (flicker/consistency scores), camera-path adherence (error vs. planned extrinsics), and audio–emotion alignment.
- Human evaluation details are under-specified: number and expertise of annotators, inter-annotator agreement, randomization, statistical significance, and reproducible protocols for GSB variants.
- Efficiency claims lack concrete numbers: runtime per minute of video at specific resolutions/frame rates, sampling steps, speedup ratios from distillation, memory footprint, and hardware configurations.
- Cascade design is underspecified: criteria to select blueprint keyframes, sub-clip length and overlap, first–last frame conditioning implementation, audio-aware interpolation algorithm, and strategies to avoid seams when stitching sub-clips.
- No ablation of the Co-Reasoning Director’s components (audio/visual/text experts), number of reasoning turns, chain-of-thought necessity, or contribution of the negative director beyond blueprint keyframes; sensitivity to conflicting modalities remains unclear.
- The LLM/MLLM stack is not disclosed: model identities, sizes, training/fine-tuning, inference cost/latency, caching/memory mechanisms across multi-turn planning, and reproducibility under resource constraints.
- Dataset composition and governance are unclear: scale, duration distribution, language diversity beyond Chinese/English/singing, scenario coverage (poses, occlusions, multi-person interactions), licensing/consent, privacy handling, and release plans.
- Multi-character mask annotations lack quality metrics: segmentation/tracking accuracy, failure rates of YOLO/DWPose/SAM2 under occlusion/crowding/fast motion, and how annotation errors affect training and inference.
- Multi-character audio control edge cases are not addressed: overlapping speech, cross-talk, diarization accuracy, turn-taking, dynamic entry/exit of speakers, and objective per-character synchronization metrics.
- Robustness to audio conditions is untested: background noise, reverberation, microphone variability, extreme prosody (very fast/slow speech), code-switching, accents, and diverse singing genres.
- Camera control is described textually but lacks formal parameterization: how numeric/extrinsic controls are supported, adherence under large viewpoint changes, 3D consistency, and editing interfaces for users.
- Claims of physically plausible hair/head motion are unsupported by modeling or metrics; failure modes (e.g., cloth/hair self-collisions, jitter) and their relationship to the cascade are not analyzed.
- Identity preservation is not quantified across large pose changes, side profiles, viewpoint changes, and long-horizon sequences (e.g., drift over 5 minutes).
- Human–object/environment interactions are mentioned but not evaluated; the system’s ability to follow object-level instructions and maintain contact plausibility is unclear.
- Mask-prediction head generalization is uncertain: performance on unseen identities, overlapping characters, partial occlusions, tracking drift across long clips, gating thresholds, and how errors propagate into audio injection.
- Audio feature pipeline is unspecified: feature types (mel/phoneme/prosody), temporal alignment to frames, modeling of prosody/emotion, latency, and how the negative director influences audio-to-motion mapping.
- Safety, misuse, and provenance are not addressed: deepfake risks, watermarking/detection, identity consent mechanisms, bias/fairness across demographics and languages, and content moderation safeguards.
- Long-context semantic continuity is unmeasured: mechanisms to maintain story arcs and references across shots, global memory/state representation, and metrics for narrative coherence over multi-minute videos.
- Parallel sub-clip generation introduces potential incoherence; scheduling, synchronization, and conflict resolution across concurrently generated segments are not detailed or evaluated.
- Domain generalization is claimed but uncharacterized: which styles/domains are covered, performance on stylized or non-photorealistic inputs, and adaptation methods for out-of-distribution conditions.
- Training details necessary for reproducibility are missing: DiT architectures, token compression ratios, frame rates, resolutions, batch sizes, training schedules, noise timesteps, and total compute.
- Comparative breadth is limited to three baselines; inclusion of recent SOTA methods, standardized benchmarks, and reproducible comparison settings (same prompts, seeds, lengths) is needed.
- Modality conflict resolution is described narratively; a formal algorithm for priority weighting, conflict detection, and resolution (with measurable outcomes) is not provided.
- Negative director generation is under-specified: how shot-specific negative prompts are produced/validated, risk of over-suppressing desirable diversity, and quantitative impact beyond illustrative visuals.
- Real-time/streaming use is unaddressed: online generation, latency budgets, incremental conditioning with live audio, and fallback behavior under network or compute constraints.
- User-in-the-loop controllability and post-editing are not supported: mechanisms for correcting camera paths, gestures, emotions, or lip-sync after generation, and workflows for interactive refinement.
- Multilingual coverage is narrow; generalization to additional languages, phoneme–viseme mapping differences, cross-lingual lip-sync accuracy, and data requirements for low-resource languages remain open.
Practical Applications
Based on the content of the KlingAvatar 2.0 technical report, the practical, real-world applications derived from its findings, methods, and innovations can be categorized as follows:
Immediate Applications
- Entertainment Industry
- Use Case: Creation of lifelike, high-resolution digital human avatars for movies and video games.
- Sector: Entertainment, Gaming
- Tools/Products: Enhanced CGI effects in films, interactive and immersive gaming experiences.
- Assumptions/Dependencies: Requires existing infrastructure for video production and animation.
- Advertising and Marketing
- Use Case: Personalized and engaging marketing campaigns using AI-generated avatars that align with brand identity.
- Sector: Marketing, Advertising
- Tools/Products: Targeted digital ads, interactive online commercials.
- Assumptions/Dependencies: Dependence on data-driven marketing strategies and audience engagement platforms.
- Education and Training
- Use Case: Virtual instructors for educational content delivery, enabling immersive learning experiences.
- Sector: Education, E-learning
- Tools/Products: Online education platforms, virtual training modules.
- Assumptions/Dependencies: Requires adaptation to different curricula and learning environments.
Long-Term Applications
- Healthcare and Therapy
- Use Case: Therapeutic virtual avatars for mental health and rehabilitation, providing patient-specific interactions.
- Sector: Healthcare
- Tools/Products: Virtual therapy sessions, personalized health communication tools.
- Assumptions/Dependencies: Requires extensive research into therapeutic efficacy and patient interaction quality.
- Robotics and Human-Computer Interaction
- Use Case: Real-time emotion and gesture-based control for humanoid robots in customer service applications.
- Sector: Robotics, AI
- Tools/Products: Customer service robots, interactive kiosks.
- Assumptions/Dependencies: Needs advancements in robotics interfaces and neural network integration.
- Policy and Governance
- Use Case: Digital public forums with avatar-driven interactions to engage communities in policy-making.
- Sector: Government, Public Policy
- Tools/Products: Virtual town hall meetings, digital citizen engagement platforms.
- Assumptions/Dependencies: Requires policy frameworks for digital and virtual governance.
- Daily Life and Personalization
- Use Case: Personalized avatars for virtual meetings and social interactions, enhancing remote communication.
- Sector: Social Media, Communication
- Tools/Products: Video conferencing apps, social media platforms.
- Assumptions/Dependencies: Relies on widespread adoption of virtual communication tools.
These applications emphasize the transformative potential of KlingAvatar 2.0 across various sectors, contingent upon technological integration and societal acceptance.
Glossary
- 3D convolutional VAEs: Variational autoencoders with 3D convolutions that compress video in space and time into latent representations for transformer-based diffusion. "These methods employ 3D convolutional VAEs to compress videos both temporally and spatially into compact tokens"
- Audio-aware interpolation: A synthesis technique that uses audio cues to generate intermediate frames, improving temporal smoothness and synchronization. "An audio-aware interpolation strategy synthesizes transition frames to enhance temporal connectivity, lip synchronization, and spatial consistency."
- Blueprint video: A low-resolution, globally coherent video used as a plan for subsequent high-resolution refinement. "First, a low-resolution diffusion model generates a blueprint video that captures global dynamics, content, and layout;"
- Cascaded super-resolution: A staged upsampling approach that progressively increases resolution using multiple models or steps. "unified multimodal conditioning with cascaded super-resolution for high-resolution synthesis"
- Chain-of-thought: A reasoning style where intermediate steps are explicitly articulated to resolve conflicts and fill missing details. "These experts engage in several rounds of co-reasoning with chain-of-thought, exposing intermediate thoughts to resolve conflicts"
- Co-Reasoning Director: A multi-expert controller that plans and aligns audio, visual, and text inputs via iterative dialogue to produce coherent storylines. "we introduce a Co-Reasoning Director composed of three modality-specific LLM experts."
- Cross-attention: An attention mechanism that aligns latent video features with identity tokens to compute character-specific masks or associations. "We then compute cross-attention between deep video latent tokens and these reference tokens for each identity,"
- Deep video latent tokens: High-level latent representations in deep transformer layers that capture semantically coherent spatial regions aligned with characters. "compute cross-attention between deep video latent tokens and these reference tokens"
- Denoising: The iterative process in diffusion models that transforms noisy latents into clean outputs during generation. "During denoising, the predicted masks are used to gate the identity-specific audio stream injection to corresponding regions."
- DiT (Diffusion Transformer): A transformer architecture specialized for diffusion-based generative modeling of images and videos. "KlingAvatar~2.0 adopts a spatial-temporal cascade of audio-driven DiTs built on top of pretrained video diffusion models,"
- Distribution Matching Distillation (DMD): A distillation method that trains a faster generator by matching the output distribution of a teacher diffusion model. "and distribution matching distillation exemplified by DMD"
- DWPose: A pose estimation model used to obtain keypoints for multi-character mask annotation and validation. "DWPose~\cite{yang2023effective} for keypoint estimation,"
- First-last-frame conditioned generation: A strategy that conditions clip synthesis on both the first and last frames to refine motion and expressions within sub-clips. "via first-last-frame conditioned generation,"
- GSB (Good/Same/Bad) metric: A human preference-based evaluation that compares methods via pairwise judgments aggregated as (G+S)/(B+S). "annotators perform Good/Same/Bad (GSB) pairwise comparisons between our results and those of baseline methods."
- ID-aware attention: Attention mechanisms that incorporate identity cues to focus generation or control on specific characters. "leverage deep DiT block features and ID-aware attention to realize mask-controlled audio injection"
- Identity-specific audio stream injection: Feeding the audio corresponding to each character only into the spatial regions associated with that identity. "the predicted masks are used to gate the identity-specific audio stream injection to corresponding regions."
- Mask-prediction head: A module attached to deep transformer features that predicts per-frame character masks for spatially targeted conditioning. "we attach a mask-prediction head to selected deep DiT blocks,"
- MLLM (Multimodal LLM): A LLM capable of processing and reasoning over multiple modalities (audio, image, text). "building on recent MLLM-based avatar planners"
- Multi-task distillation paradigm: A training setup that distills multiple tasks jointly to achieve synergistic improvements in speed and quality. "we introduced a multi-task distillation paradigm through a series of precisely designed configurations."
- Negative director: A component that generates shot-specific negative prompts to discourage undesired artifacts and emotions for better alignment. "Additionally, we also introduce a negative director, where positive prompts emphasize desired visual and behavioral attributes, and negative prompts explicitly down-weight implausible poses, artifacts, and fine-grained opposite emotions"
- Paralinguistic analysis: Analysis of non-verbal aspects of speech (e.g., emotion, prosody, intent) used to guide expressive avatar behavior. "an audio-centric expert performs transcription and paralinguistic analysis (emotion, prosody, speaking intent);"
- Patchification: Converting images into non-overlapping patches that are tokenized for transformer processing, used here for identity crops. "encode the reference identity crops using the same patchification scheme without adding noise to reference tokens."
- PCM: A trajectory-preserving distillation approach (e.g., Phased Consistency Model) used to accelerate diffusion inference while maintaining generation trajectories. "trajectory-preserving distillation exemplified by PCM"
- SAM2: A segmentation and temporal tracking model used to produce per-character video masks in the annotation pipeline. "SAM2~\cite{ravi2024sam2} for segmentation and temporal tracking."
- Shot-level storylines: Fine-grained plans that decompose a video into shots with specified actions, emotions, and camera movements. "generating coherent shot-level storylines."
- Spatial-temporal cascade framework: A hierarchical pipeline that progressively upsamples resolution and duration to produce long, high-quality videos. "We introduce a spatial-temporal cascade framework that enables efficient generation of long-duration, high-resolution videos"
- Super-resolution: The process of upscaling low-resolution clips to higher resolutions with improved visual fidelity. "a high-resolution video diffusion model performs super-resolution on the low-resolution sub-clips,"
- Temporal compression: Reducing the number of modeled frames or condensing temporal information to improve scalability and efficiency. "model all frames without temporal compression"
- Temporal drifting: Progressive misalignment or degradation of motion/identity coherence as video length increases. "suffering from temporal drifting, quality degradation"
- Time schedulers: Customized timesteps schedules for distilled diffusion processes to balance speed-up and quality. "we developed customized time schedulers by analyzing the performance of the base model across different timesteps,"
- Trajectory-preserving distillation: Distillation that preserves the generative trajectory of the teacher diffusion process for stable, fast inference. "trajectory-preserving distillation exemplified by PCM and DCM,"
- World modeling: Modeling environments and dynamics beyond single scenes to improve coherent, long-context video generation. "and world modeling"
- YOLO: A real-time object detector used here to find persons for initial mask prompts in multi-character annotation. "YOLO~\cite{yolo2023} for person detection,"
Collections
Sign up for free to add this paper to one or more collections.

