- The paper introduces a novel spatiotemporal in-context learning method to seamlessly blend appearance and motion for enhanced character animation.
- The paper employs a two-stage training approach with pose-based augmentation and end-to-end pseudo-pair synthesis, ensuring robust identity preservation and motion consistency.
- The paper validates its approach using AWBench, demonstrating superior imaging quality and temporal consistency over state-of-the-art methods.
DreamActor-M2: Universal Character Image Animation via Spatiotemporal In-Context Learning
Overview and Motivation
DreamActor-M2 (2601.21716) addresses the core challenges in universal character image animation, particularly the simultaneous achievement of strong identity preservation and motion consistency across diverse domains. Traditional motion injection techniques, including pose-based and cross-attention methods, present critical trade-offs: pose-based approaches can degrade identity preservation due to structural leakage, while cross-attention compresses temporal motion details, limiting fidelity. Furthermore, reliance on explicit pose priors constrains generalization, failing in scenarios with non-humanoid subjects and complex multi-agent dynamics. DreamActor-M2 reframes motion conditioning as a spatiotemporal in-context learning problem, inspired by ICL advances in LLMs and VLMs.

Figure 1: DreamActor-M2 demonstrates generalization by animating heterogeneous characters while maintaining consistent appearance.
Methodology
Spatiotemporal In-Context Learning
The architecture employs Seedance 1.0 as the video generation backbone (MMDiT), leveraging its multimodal generative priors. Motion control signals are concatenated spatiotemporally with the reference image to form a unified input sequence. The model receives composite input frames: (1) The first frame concatenates reference appearance and motion anchor, (2) Subsequent frames align motion frames with blank reference masks. Masking strategies distinguish identity and motion regions, facilitating robust context integration.
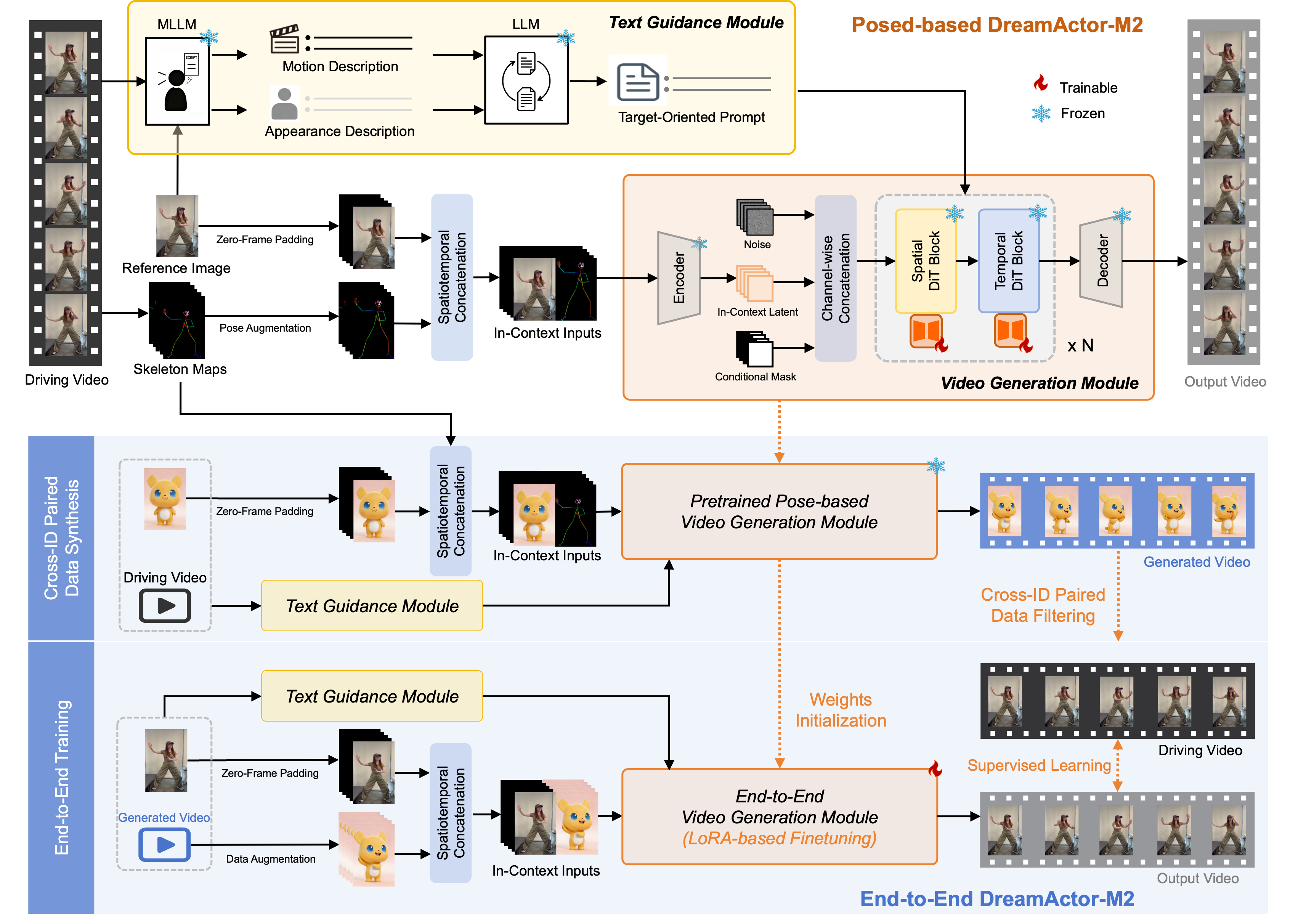
Figure 2: Schematic overview of the DreamActor-M2 pipeline illustrating unified spatial-temporal concatenation for motion transfer.
Pose-Based and End-to-End Training Paradigms
The two-stage training paradigm begins with a pose-based variant using augmented 2D skeletons, reinforcing motion context while damping semantic identity leakage via bone length scaling and box normalization. Semantic expressiveness is amplified by multimodal LLMs, parsing motion and appearance semantics and fusing them into target-oriented prompts for enhanced controllability.
Transitioning to the end-to-end variant, DreamActor-M2 leverages self-bootstrapped pseudo-pair synthesis. The pose-based model generates new high-quality videos which become supervision targets paired with original motion sources. Rigorous dual-stage quality filtering ensures only motion-consistent and identity-faithful samples are retained. The end-to-end model subsequently learns direct motion condition inference from RGB inputs, eliminating explicit pose requirements and expanding applicability to arbitrary subjects.
Benchmark: AWBench
DreamActor-M2 introduces AWBench, a comprehensive evaluation benchmark with 100 driving videos and 200 reference images, spanning humans, animals, animated/cartoon subjects, and multi-agent scenarios. It accommodates one-to-one, one-to-many, and many-to-many mappings—unaddressed in previous works—with rich intra- and cross-domain diversity. Examples illustrate diversity of reference and driving pairs.

Figure 3: Representative driving video and reference image examples from AWBench.
Experimental Results
Quantitative Evaluation
DreamActor-M2 surpasses state-of-the-art baselines (Animate-X++, MTVCrafter, DreamActor-M1, Wan2.2-Animate) in both automatic and human-aligned metrics as assessed by Video-Bench, with notable margins in imaging quality, motion smoothness, temporal consistency, and appearance consistency. For example, End-to-End DreamActor-M2 achieves 4.72 (quality), 4.56 (smoothness), 4.69 (consistency), and 4.35 (appearance) on Video-Bench automatic metrics.
Qualitative Comparison
Visual inspection on AWBench demonstrates DreamActor-M2's superior fidelity and robustness, even in challenging cross-domain and multi-person setups, where baselines suffer from blurring, artifacts, and structure collapse. The model accurately reproduces fine motion semantics, preserves body shape across identity transfers, and reliably synthesizes complex gestures. One-to-many and multi-to-multi mappings further validate scalability.

Figure 4: Qualitative comparison between DreamActor-M2 and SOTA methods on AWBench, emphasizing fidelity and identity preservation.
Generalization and Versatility
DreamActor-M2's architecture generalizes across various shot types, reference identities (humans, animals, cartoons, objects), driving domains, and multi-agent scenarios. The model extrapolates plausible motion for incomplete driving signals, adapts to non-human inputs, and consistently manages complex group dynamics.

Figure 5: Visualization of diverse shot types, demonstrating extrapolation when lower-body driving signals are absent.

Figure 6: Animation results for varied reference character types (rabbit, juice bottle, anime characters).

Figure 7: Animation results for diverse driving character types (Animal2Animal, Cartoon2Cartoon).

Figure 8: Robust multi-person character animation under one-to-many and many-to-many settings.
Ablation Analysis
Component-wise ablation studies confirm key architectural advantages:
Implications and Future Directions
Practically, DreamActor-M2 democratizes high-fidelity character animation across arbitrary domains, circumventing pose estimator bottlenecks and expansive manual curation. The end-to-end adaptation mechanism paves the way for cost-efficient, generalizable, and scalable animation pipelines for gaming, entertainment, AR/VR, and creative content synthesis. Theoretically, this work substantiates in-context learning as a robust mechanism for spatiotemporal reasoning in generative video models—a direction ripe for further exploration in vision foundation models and causal/invariant motion transfer.
Future research should address limitations in handling intricate subject interactions, such as trajectory crossing in multi-agent scenes, and further expand training diversity to fully exploit model extrapolation capabilities. Security and ethical risk mitigation remain active concerns given the framework's proficiency in realistic human and character video synthesis.
Conclusion
DreamActor-M2 sets a new standard for universal character image animation by integrating motion and identity conditions via spatiotemporal in-context learning, achieving high-fidelity, robust generalization across unprecedented subject diversity, and pioneering a practical end-to-end animation paradigm. The AWBench benchmark and ablation studies comprehensively validate its architecture, and its implications signal new possibilities for scalable, domain-agnostic animated content generation.


