Wan-Animate: Unified Character Animation and Replacement with Holistic Replication
Abstract: We introduce Wan-Animate, a unified framework for character animation and replacement. Given a character image and a reference video, Wan-Animate can animate the character by precisely replicating the expressions and movements of the character in the video to generate high-fidelity character videos. Alternatively, it can integrate the animated character into the reference video to replace the original character, replicating the scene's lighting and color tone to achieve seamless environmental integration. Wan-Animate is built upon the Wan model. To adapt it for character animation tasks, we employ a modified input paradigm to differentiate between reference conditions and regions for generation. This design unifies multiple tasks into a common symbolic representation. We use spatially-aligned skeleton signals to replicate body motion and implicit facial features extracted from source images to reenact expressions, enabling the generation of character videos with high controllability and expressiveness. Furthermore, to enhance environmental integration during character replacement, we develop an auxiliary Relighting LoRA. This module preserves the character's appearance consistency while applying the appropriate environmental lighting and color tone. Experimental results demonstrate that Wan-Animate achieves state-of-the-art performance. We are committed to open-sourcing the model weights and its source code.
First 10 authors:







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Wan‑Animate, an AI system that can turn a single picture of a character into a moving video. It can do two things:
- Animate a character so it copies the body movements and facial expressions from a reference video.
- Replace the person in a video with a new character, while matching the scene’s lighting and colors so it looks natural.
Think of it like high‑tech puppeteering: the reference video is the “puppet master,” and the still image is the “puppet.” Wan‑Animate learns to move the puppet’s body and face the same way the puppet master does, and if you want, it can place that puppet directly into the puppet master’s stage.
What questions did the researchers ask?
In simple terms, they wanted to know:
- Can one model handle both character animation (making a picture move) and character replacement (swapping someone in a video) well?
- Can it copy both body motion and subtle facial expressions accurately?
- Can it make the replaced character blend into the scene’s lighting and colors so it looks real, not pasted on?
How does Wan‑Animate work?
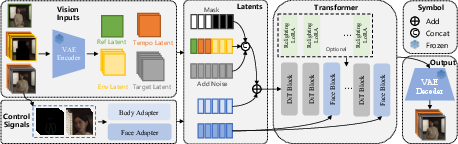
Wan‑Animate builds on a powerful video generator called Wan (a “Diffusion Transformer,” which is just a big model that learns to turn random noise into realistic video, step by step).
The two modes
- Animation Mode: It keeps the background from the input picture and moves the character to match the reference video’s motion and expressions.
- Replacement Mode: It keeps the background from the reference video but swaps in the new character, while adjusting light and color so the new character fits the scene.
You choose the mode by changing how you feed inputs into the model (like checking different boxes on a form). The team designed a unified “input setup” so the same model can do both tasks.
Driving the body: “stick‑figure” control
For body motion, Wan‑Animate uses a 2D skeleton (like a stick‑figure with joints). This is extracted from the reference video and aligned with the target character. The skeleton is robust for many character types (including stylized ones), and it tells the model where arms, legs, and torso should move.
Analogy: Imagine tracing a dancer’s pose as a stick figure frame by frame, then using that stick figure to guide your animated character.
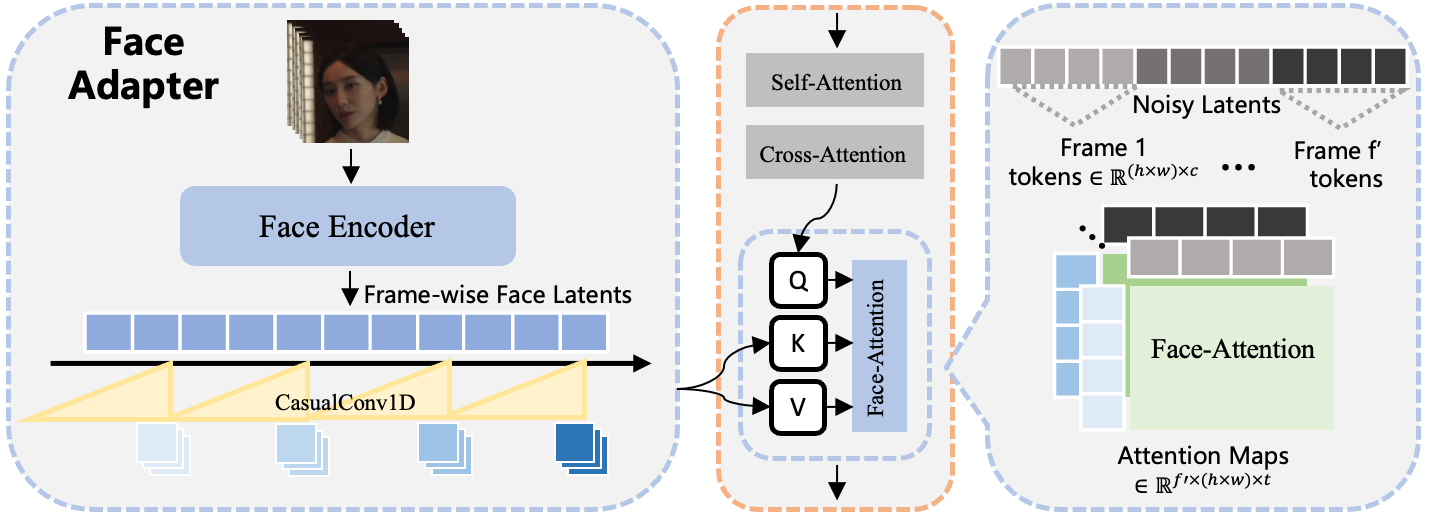
Reenacting the face: “expression signals,” not landmarks
Facial expressions are tricky—small details matter. Instead of using face landmarks (dots on eyes, nose, mouth), the model uses the actual cropped face images from the reference video. But it processes them to keep expression info while stripping away identity details, so it doesn’t accidentally make the target character look like the person in the video.
Two key tricks help:
- Compressing face images into a compact “latent” so low‑level identity traits don’t carry over.
- Random augmentations (like tiny color or scale changes) so the model learns expressions, not identity.
These face “expression signals” are injected into the model so that at each moment it knows exactly how the eyebrows, eyes, mouth, and cheeks should move.
Fitting into the scene: Relighting LoRA
When replacing a character in a video, the lighting on the new character might not match the room (too bright, wrong color, etc.). Wan‑Animate adds a small extra module (called a LoRA) that tweaks lighting and color tones on the character to match the environment.
Analogy: Think of it as automatic “makeup and lighting correction,” so the character doesn’t look out of place.
Training in stages
To make learning stable and fast, the team trains in steps:
- Learn body motion control.
- Add facial expression control on portrait‑focused data (so faces are clear and large).
- Train both together.
- Teach the model to handle both Animation and Replacement modes.
- Train the Relighting LoRA to match scene lighting.
Making it work in practice
- Pose retargeting: People have different body proportions. For animation mode, the system rescales bones (like adjusting a puppet’s limb lengths) so the motion fits the target character better.
- Long videos: It generates in chunks and uses the last frames as a guide for the next chunk, keeping motion smooth over time.
What did they find?
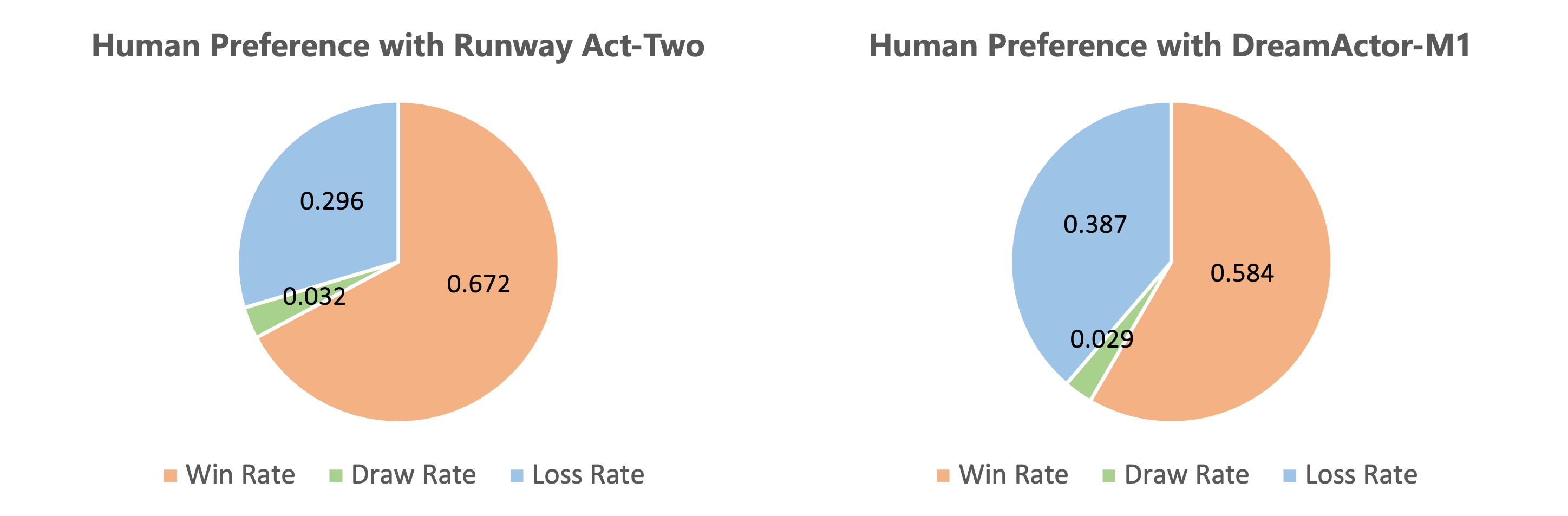
- Higher quality and more stable videos: Compared to many open‑source methods, Wan‑Animate makes characters look more realistic, keeps their identity consistent, and produces smoother motion over time.
- Better expressions: Using face images as expression signals captures subtle facial movements (like eye and mouth changes) more accurately than landmarks.
- Strong replacement results: With the Relighting LoRA, the swapped character matches the scene’s light and color better, so the final video looks more natural.
- User preference: In side‑by‑side comparisons against strong commercial systems, more people preferred Wan‑Animate’s results.
- Versatility: It works across portraits, half‑body, and full‑body shots, and even with different character styles.
Why this matters: It pushes open‑source character animation closer to the best commercial tools, making high‑quality video editing and animation more accessible.
Why it matters and what could happen next?
- Creative uses: Filmmakers, advertisers, and creators can quickly animate characters, recreate performances, or swap actors while keeping scenes believable.
- Faster workflows: A single, unified tool that handles both animation and replacement can save time and reduce complexity.
- Open source impact: The team plans to release the model and code, which can speed up research, lower costs for creators, and inspire new apps.
- Responsible use: Because this tech can change who appears in a video and how they move or emote, it should be used ethically—get consent, avoid deception, and consider watermarking or disclosure to prevent misuse.
In short, Wan‑Animate is like a Swiss Army knife for character video creation: it animates, replaces, and relights—with special care for realistic motion, expressive faces, and seamless scene blending.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, structured to guide concrete follow-up research:
- Data transparency and bias: the composition, size, licensing, demographics, and domain diversity of the training corpus are not disclosed; potential demographic and content biases remain uncharacterized.
- Generalization beyond humans: despite claiming robustness to “humanoid” characters, the model is trained on human-centric videos; performance on non-human, stylized (anime, cartoons), or 3D/CGI characters is untested and unevaluated.
- Multi-person scenarios: training explicitly assumes a single consistent character per clip; support for multi-subject scenes, identity disambiguation, and cross-subject occlusions is not addressed.
- Occlusion and interaction modeling: handling of self-occlusions, human–object contacts, inter-person occlusion ordering, and physically plausible interactions is not modeled or evaluated.
- Replacement segmentation robustness: character masks rely on SAM2 and skeleton tracking; robustness to motion blur, heavy occlusions, fast motion, complex clothing, and scene clutter is not quantified.
- 2D skeleton limitations: the known ambiguities and failure modes of 2D keypoints (missing joints, depth ambiguity, foreshortening) are acknowledged but not systematically mitigated or measured; no comparison to 3D motion representations (e.g., SMPL, 3D keypoints) is provided.
- Hand and finger articulation: control signals appear coarse (body joints only); explicit hand/finger keypoints and fine-grained gesture control are not covered.
- Pose retargeting constraints: retargeting is disabled in Replacement Mode to preserve interactions, causing deformation when source/target body shapes differ; no interaction-preserving retargeting or shape-aware adaptation is explored.
- T-pose canonicalization reliability: the proposed T-pose editing (via external image-editing models) used to compute limb-length ratios lacks reliability analysis, failure characterization, or alternatives that avoid external editing.
- Facial identity leakage: the paper proposes augmentations and feature orthogonalization to reduce identity leakage in face features, but does not quantify leakage risks (e.g., via face-recognition similarity across cross-ID reenactment).
- Expression controllability: there is no explicit control over expression intensity, style, or temporal dynamics beyond optional CFG; no “expression scale” or disentangled control interface is studied.
- Cross-modal control gaps: audio-driven lip synchronization, speech-driven facial dynamics, and language-conditioned expression/motion control are not supported or evaluated.
- Camera motion handling: the method claims to handle dynamic camera movement but lacks explicit modeling (e.g., camera trajectory estimation) and provides no targeted evaluation on large camera motion or zooms.
- Long-horizon stability: the iterative long-video scheme (segment stitching with 1–5-frame temporal guidance) is prone to drift or seam artifacts; no quantitative long-horizon stability/flicker metrics are reported.
- 3D/geometry awareness: the approach is purely 2D; view-consistent identity under large yaw/pitch rotations and multi-view geometric consistency are not addressed or assessed.
- Relighting scope limits: the Relighting LoRA is trained on IC-Light composites; generalization to dynamic lighting, multi-source/colored lights, hard cast shadows, interreflections, and environment-induced occlusions is untested.
- Scene–subject photometric coupling: beyond adjusting the subject’s tone/illumination, the method does not synthesize physically consistent cast shadows or reflected light onto the environment; no metrics/user studies specifically evaluate environmental photometric integration.
- Temporal consistency of relighting: potential frame-to-frame flicker introduced by the Relighting LoRA is not analyzed; no temporal photometric stability metrics are provided.
- Segmentation boundary quality: boundary artifacts at subject–background edges (haloing, color spill) are not discussed or evaluated, especially under fast motion and motion blur.
- Component-level ablations: only two ablations are shown (face training curriculum, relighting); missing ablations include face-injection layer schedule, injection frequency, pose vs no-pose, 2D vs 3D motion, temporal-latent count, and alternative fusion strategies.
- Error tolerance and robustness: failure modes under noisy/missing keypoints, poor face crops, extreme expressions, occluded faces, unusual clothing/hair, and low-resolution inputs are not systematically studied.
- Evaluation benchmarks: quantitative results rely on an internal benchmark; there is no evaluation on public, standardized datasets, nor a release of the internal test set to enable reproducible comparisons.
- Metrics for identity and motion fidelity: no identity-preservation metric (e.g., face embedding similarity), motion-following error (e.g., keypoint reprojection error), facial Action Unit accuracy, or lip-sync metrics are reported.
- Environmental integration metrics: no objective measures for photometric/illumination consistency (e.g., re-illumination error, shadow consistency) or perceptual realism focused on replacement quality are provided.
- User study design: the subjective study uses 20 participants and pairwise preferences but lacks details on sample size, statistical significance tests, inter-rater agreement, and task diversity.
- Efficiency and deployment: inference latency, throughput, GPU memory requirements, and scalability for real-time or streaming applications are not reported.
- CFG trade-offs: the impact of enabling CFG (global or face-only) on quality, adherence to control signals, and temporal stability is not analyzed.
- Text prompt influence: although text is supported, its effect on motion/expression or scene control and potential conflicts with motion signals are not studied.
- Multilingual and cross-domain robustness: robustness to varied cultural facial expressions, makeup, masks, headwear, and domain shifts (e.g., IR/night videos) is unreported.
- Multi-identity replacement: replacing multiple subjects in the same scene, identity assignment, and consistency maintenance across subjects and time are unaddressed.
- Provenance and safety: no discussion of consent, watermarking, detection of manipulated content, or safeguards against misuse (e.g., non-consensual identity swaps) is provided.
- Privacy and memorization: risks of training data memorization, identity/privacy leakage, and membership inference are not assessed.
- Reproducibility specifics: while code/weights are promised, concrete training hyperparameters, data preprocessing pipelines, and benchmark release timelines are unspecified.
Glossary
- Ablation study: A controlled experiment that removes or modifies components to assess their contribution. Example: The paper compares progressive face-adapter training against a joint baseline and shows the baseline struggles to converge.
- Binary mask: A tensor of 0/1 values indicating which regions or frames are preserved (1) or generated (0). Example: In Replacement Mode, the mask is 1 for environment regions and 0 for the subject to preserve the original background.
- Body Adapter: A lightweight module that encodes and injects pose (skeleton) signals into the generative model. Example: Pose frames are compressed by the Wan-VAE, patchified, and added to the patchified noise latents via the Body Adapter.
- Causal 1D convolutional layers: Sequence convolutions that only use current and past timesteps to produce outputs, preserving causality. Example: Used to temporally downsample face latents so their length matches DiT latents.
- Classifier-Free Guidance (CFG): A diffusion technique that balances conditional and unconditional predictions to control fidelity vs. diversity. Example: Disabled by default for efficiency; optionally enabled for face conditioning to fine-tune expression reenactment.
- Context Parallelism: A training strategy that partitions long sequences across devices to reduce memory and speed up training. Example: The DiT model is trained with Context Parallelism combining RingAttention and Ulysses.
- Cross-attention: An attention mechanism where query tokens attend to conditioning tokens from another source. Example: Implicit face latents are injected via temporally aligned cross-attention inside dedicated Face Blocks.
- Cross-identity (Cross-ID) animation: Driving one character’s image with another identity’s motion and expressions. Example: The user study evaluates cross-ID setups where Wan-Animate animates a target identity using a different driving video.
- Data Parallelism (DP): Training by replicating the model across GPUs and splitting the batch among them. Example: Non-memory-intensive models (VAE, CLIP) are trained with standard DP.
- Denoising Diffusion Probabilistic Models (DDPM): Generative models that learn to reverse a noise-adding process. Example: The paper contrasts older GAN/warping methods with diffusion-based approaches like DDPM that improved animation quality.
- Diffusion Transformer (DiT): A Transformer-based diffusion architecture for image/video generation. Example: Wan-Animate is built on the DiT-based Wan-I2V foundation, benefiting from strong temporal consistency.
- Face Adapter: An encoder module that extracts implicit facial features from raw face images for expression control. Example: Face images are encoded to 1D latents, augmented, and later injected via cross-attention.
- Face Blocks: Specific Transformer layers designated to receive and fuse face conditioning features. Example: The paper injects face information every 5 layers in the 40-layer Wan-14B network (total 8 Face Blocks).
- Fréchet Video Distance (FVD): A metric assessing video realism and temporal coherence via distributional distance. Example: FVD is reported in quantitative comparisons to demonstrate Wan-Animate’s state-of-the-art performance.
- Fully Sharded Data Parallelism (FSDP): A training approach that shards model parameters, gradients, and optimizer states across devices. Example: DiT and T5 are trained with FSDP to reduce per-GPU memory footprint.
- IC-Light: A relighting/compositing method that transfers lighting from a new background onto a subject. Example: IC-Light is used to create training pairs for the Relighting LoRA by placing segmented characters onto random backgrounds with new lighting.
- Image-to-Video (I2V): Generating a video conditioned on a single input image. Example: Animation Mode is analogous to I2V, preserving the source image’s background while driving motion and expressions from the reference video.
- Implicit facial features: Learned latent representations extracted directly from face images without manual landmarks. Example: The model encodes raw faces into latents that disentangle expressions from identity and injects them via attention.
- Latent: A compressed representation of images/videos used as model inputs or conditions. Example: Wan-Animate uses reference latents, conditional latents, and noise latents; pose and face latents are aligned and injected into DiT.
- Learned Perceptual Image Patch Similarity (LPIPS): A perceptual metric comparing image patches using deep features. Example: LPIPS is reported for reconstruction quality in the quantitative evaluation.
- Linear Motion Decomposition: A technique to orthogonalize feature components, separating motion-related signals. Example: Applied in the Face Adapter to better disentangle expression information from identity cues.
- Low-Rank Adaptation (LoRA): A parameter-efficient fine-tuning method that adds low-rank matrices to existing layers. Example: The Relighting LoRA is trained on attention layers to adjust a replaced character’s lighting and color tone.
- Patchifying: Converting continuous latent features into fixed-size patches (tokens) for Transformer processing. Example: Video latents are discretized by patchifying; pose latents are also patchified and added to noise tokens.
- Pose retargeting: Adjusting skeletal poses to match differences in limb proportions or position between identities. Example: During Animation Mode, limb lengths and positions are retargeted, optionally using T-pose edits to compute scale factors.
- ReferenceNet: A network component that injects appearance features from a reference image/video into the generator. Example: Prior work (Animate Anyone) uses ReferenceNet for consistency preservation; Wan-Animate adopts related ideas via reference latents.
- Relighting LoRA: A LoRA specialized for adapting the character’s lighting and color tone to the target environment. Example: Trained with IC-Light composites, it improves realism in Replacement Mode without breaking identity.
- RingAttention: An attention parallelization scheme enabling context-splitting across devices. Example: Combined with Ulysses in the paper’s Context Parallelism to train long sequence DiT models efficiently.
- SAM2 (Segment Anything Model v2): A segmentation model that produces masks for arbitrary objects. Example: Used to extract character masks from videos for Replacement Mode’s environment formulation.
- Skeleton-based representation: A 2D keypoint structure representing body poses over time. Example: Chosen over SMPL for generality; pose keypoints from VitPose are aligned and injected to control motion.
- Skinned Multi-Person Linear (SMPL): A parametric 3D human body model with shape and pose parameters. Example: Discussed as an alternative motion signal; rejected due to shape leakage and poorer generalization to non-humanoids.
- Structural Similarity Index (SSIM): A metric that quantifies perceptual image similarity using luminance, contrast, and structure. Example: Reported in quantitative comparisons alongside LPIPS and FVD.
- Temporal guidance: Conditioning generation on previously generated frames to maintain continuity. Example: The last 1 or 5 frames of a segment are reused as condition latents (mask=1) to drive the next segment.
- Three-dimensional VAE (3D VAE): A VAE that compresses video spatially and temporally before tokenization. Example: Used to reduce sequence length so DiT can process video tokens efficiently.
- Tokenization (video tokens): Representing compressed video as discrete patch tokens for Transformer input. Example: The paper selects output resolution based on a target token count after patchify.
- T-pose: A standard reference posture with arms outstretched used for measuring body proportions. Example: The authors edit images to T-pose to compute more accurate limb length scaling for retargeting.
- Ulysses: A sequence-parallel framework for splitting long sequences across devices. Example: Paired with RingAttention to implement Context Parallelism for training the DiT.
- Variational Autoencoder (VAE): A probabilistic encoder-decoder that learns low-dimensional latent representations. Example: Wan-VAE encodes reference images and compresses pose frames to align with target latents.
- Video-to-Video (V2V): Translating one video into another conditioned on content/motion. Example: Replacement Mode corresponds to V2V, integrating the source character into the reference video environment.
- VitPose: A high-accuracy 2D human pose estimation model. Example: Used to extract skeleton keypoints that drive body motion in Wan-Animate.
Collections
Sign up for free to add this paper to one or more collections.

