Wan-Move: Motion-controllable Video Generation via Latent Trajectory Guidance
Abstract: We present Wan-Move, a simple and scalable framework that brings motion control to video generative models. Existing motion-controllable methods typically suffer from coarse control granularity and limited scalability, leaving their outputs insufficient for practical use. We narrow this gap by achieving precise and high-quality motion control. Our core idea is to directly make the original condition features motion-aware for guiding video synthesis. To this end, we first represent object motions with dense point trajectories, allowing fine-grained control over the scene. We then project these trajectories into latent space and propagate the first frame's features along each trajectory, producing an aligned spatiotemporal feature map that tells how each scene element should move. This feature map serves as the updated latent condition, which is naturally integrated into the off-the-shelf image-to-video model, e.g., Wan-I2V-14B, as motion guidance without any architecture change. It removes the need for auxiliary motion encoders and makes fine-tuning base models easily scalable. Through scaled training, Wan-Move generates 5-second, 480p videos whose motion controllability rivals Kling 1.5 Pro's commercial Motion Brush, as indicated by user studies. To support comprehensive evaluation, we further design MoveBench, a rigorously curated benchmark featuring diverse content categories and hybrid-verified annotations. It is distinguished by larger data volume, longer video durations, and high-quality motion annotations. Extensive experiments on MoveBench and the public dataset consistently show Wan-Move's superior motion quality. Code, models, and benchmark data are made publicly available.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Wan-Move: Making AI Videos Move Exactly How You Want
What this paper is about
This paper introduces Wan-Move, a new way to make AI-generated videos that follow very specific motions you choose—like telling a bird exactly where to fly across the screen. It also presents MoveBench, a big, carefully built test set to measure how well different methods follow motion instructions.
What questions the paper tries to answer
The paper focuses on two simple questions:
- How can we tell a video-generating AI exactly how objects should move, not just roughly?
- Can we do this without making the model super complicated or slow?
How the method works (in everyday language)
Think of video generation like turning a picture into a short movie. The AI starts from the first frame (the starting image) and then creates the next frames.
Here’s the key idea using simple analogies:
- Motion as “connect-the-dots”: You give the AI a motion plan by placing dots on an object and drawing the path those dots should follow across time. These are called point trajectories.
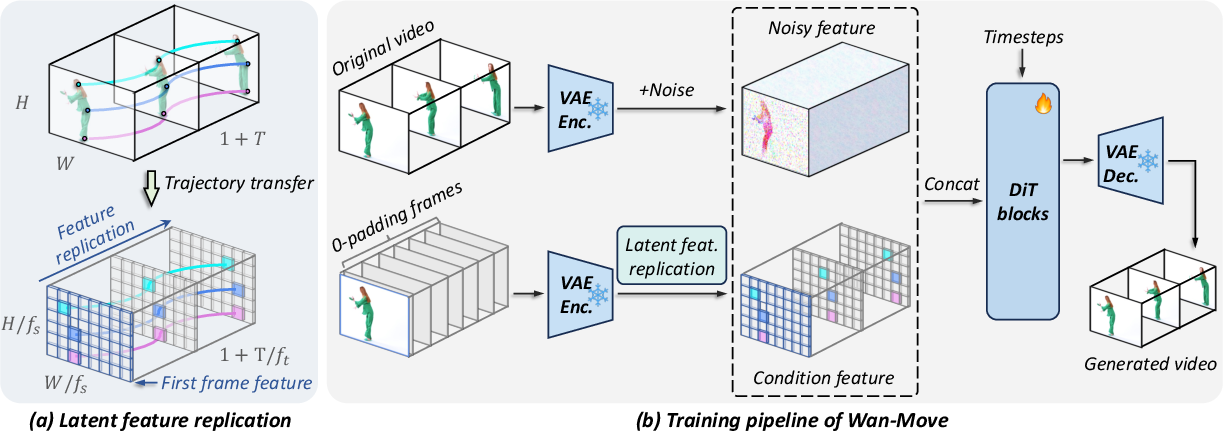
- The AI’s “thinking space”: Before generating a video, the model turns the picture into a smaller, compressed version called “latent space.” You can think of it like a mini-map where the model does its planning.
- Smart copy-and-move: Wan-Move takes the rich features (the “look and feel”) from the first frame at the dot you chose and “copies” that feature along the path of the dot in the mini-map. It’s like sticking a tiny patch from frame 1 onto the right spot in frame 2, frame 3, and so on, following your path. This tells the model: “Move this exact thing here, over time.”
- No extra gadgets: Many other methods bolt on extra motion encoders (extra boxes in the model). Wan-Move doesn’t. It edits the existing “condition features” directly. That keeps it simple, fast, and easier to train.
In more concrete terms:
- You draw point paths (where an object should go).
- The model maps those paths into its mini-map (latent space).
- It then propagates the first frame’s features along those paths.
- The model uses this as guidance to generate the video frames.
Training details in simple terms:
- They trained the system on millions of high-quality videos.
- They used a tracker (a tool that follows points in videos) to create training motion paths.
- Sometimes they trained without motion control so the model still works as a normal “image-to-video” generator.
- Because Wan-Move doesn’t add extra modules, training scales up more easily.
What they built to test it: MoveBench
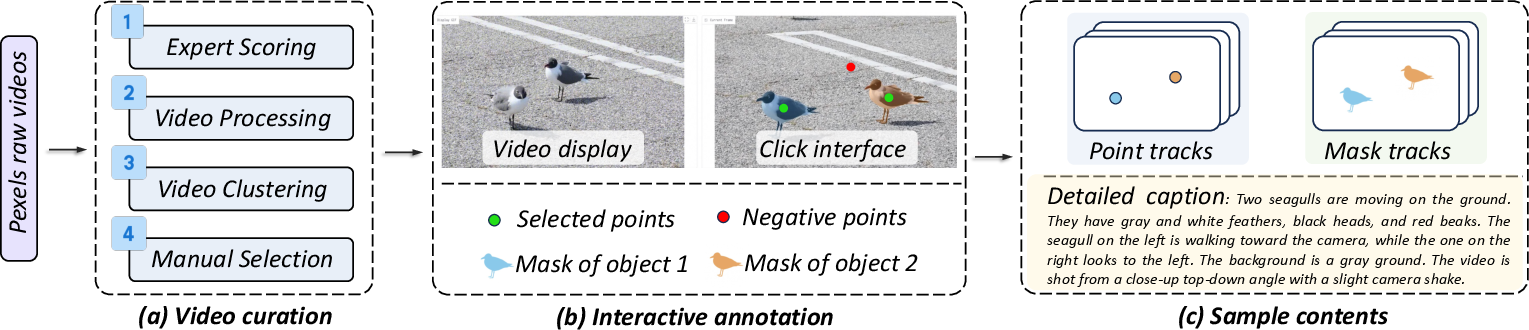
To fairly judge motion control, they created a new benchmark called MoveBench:
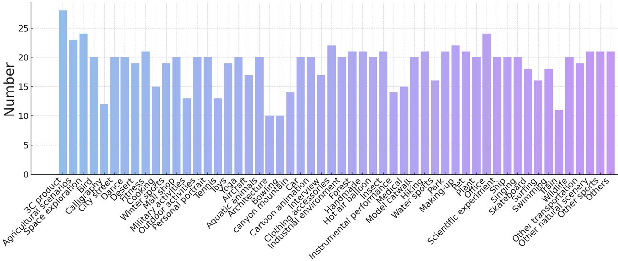
- 1,018 five-second videos across 54 categories (like sports, animals, vehicles), all 480p.
- Each video has precise motion annotations: both point paths and object masks.
- They combined human labeling with a smart tool (SAM) to keep labels accurate but efficient.
- The videos also include helpful captions that describe objects, actions, and camera motion.
What the results show and why it matters
Here’s what they found, in plain language:
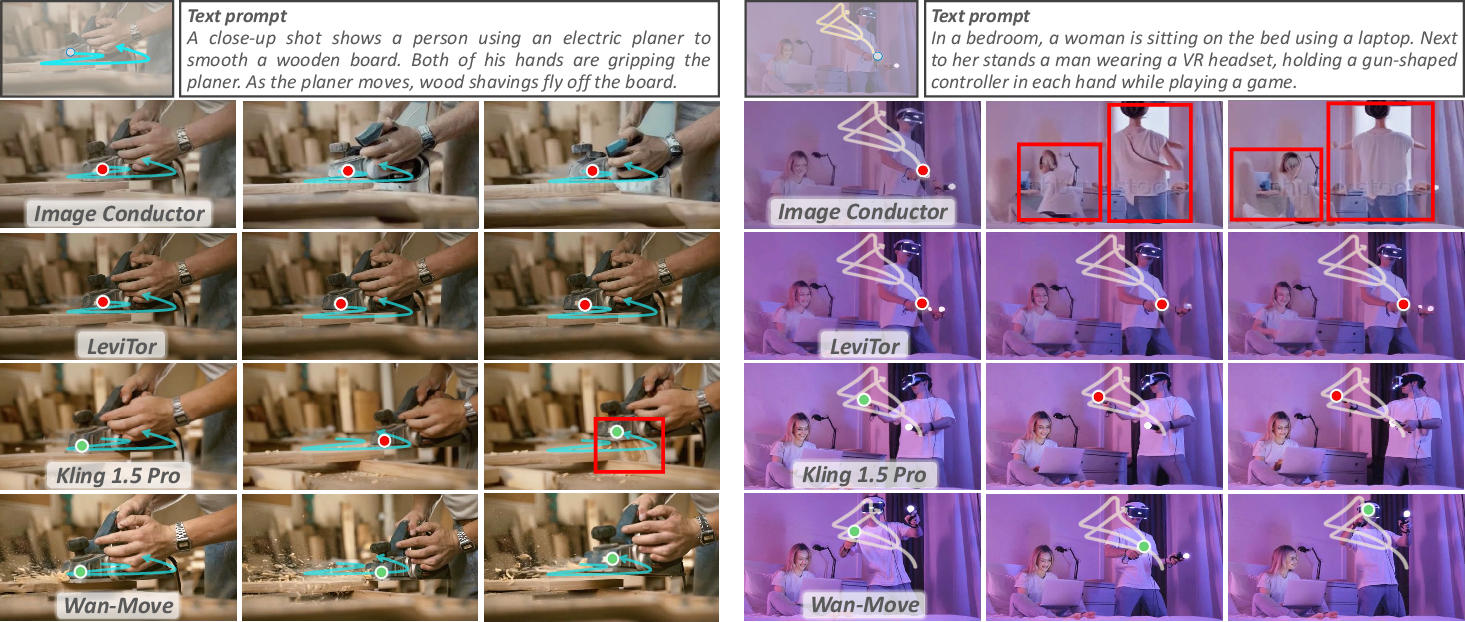
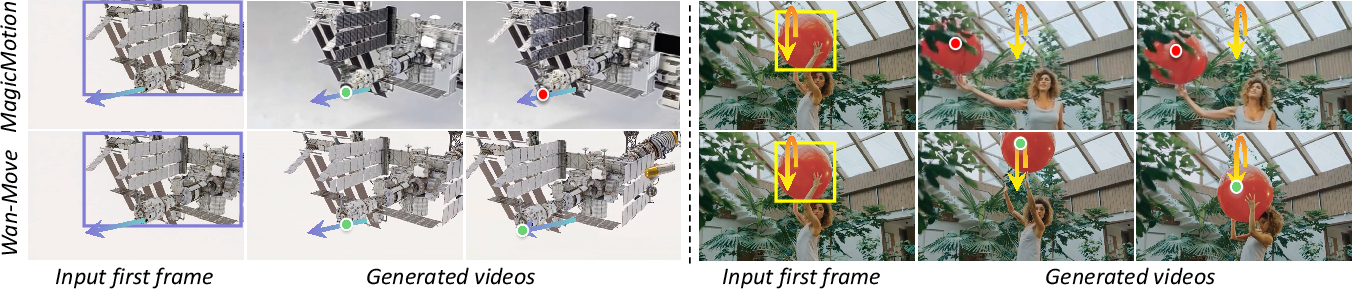
- Better control: Wan-Move followed motion paths more accurately than other research methods, and in user studies, it was competitive with a strong commercial tool (Kling 1.5 Pro’s Motion Brush).
- High visual quality: The videos looked sharp and consistent over time (not just moving correctly, but also looking good).
- Simple yet strong: Because it doesn’t add extra motion modules, it runs faster and is easier to scale and fine-tune than methods that require extra encoders.
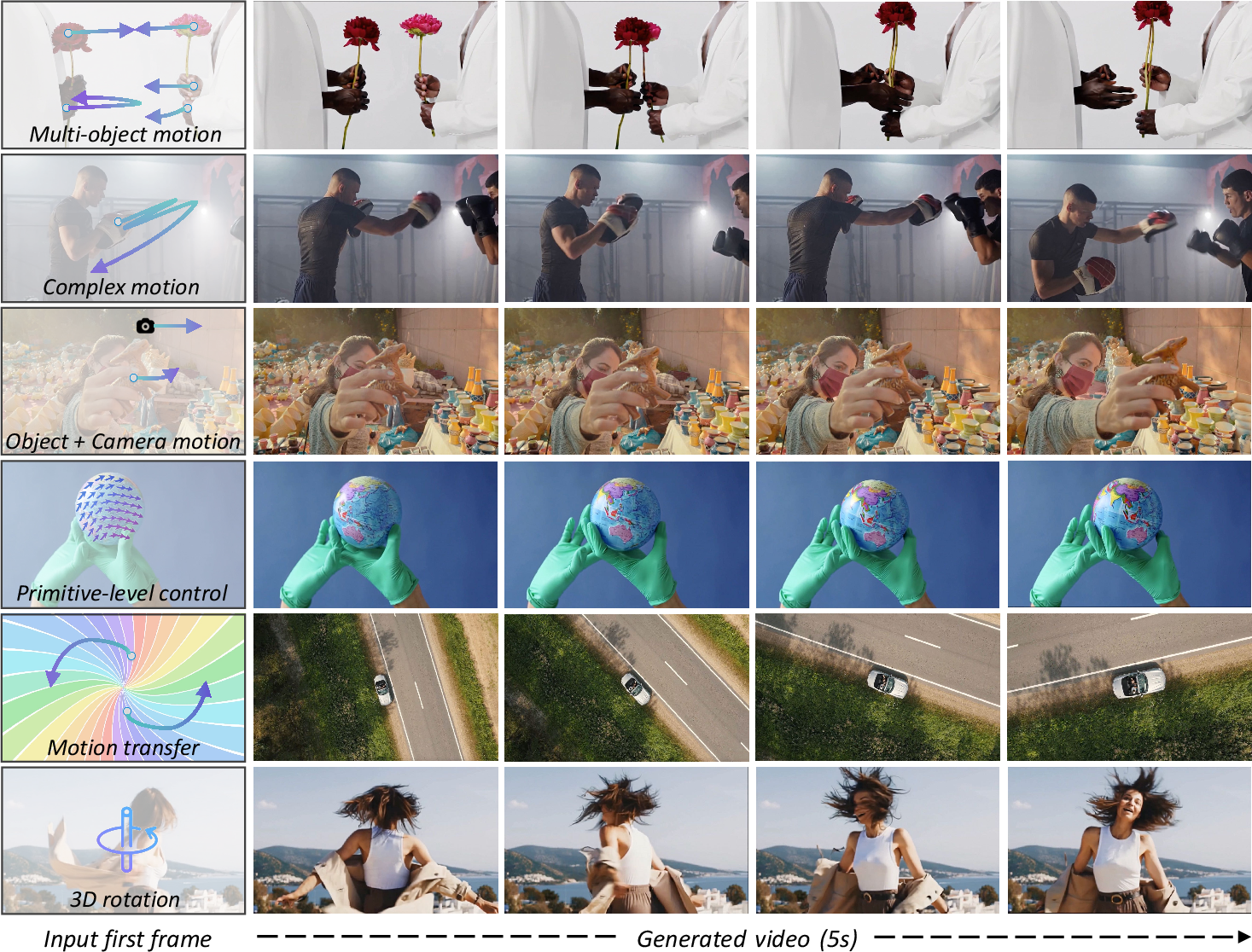
- Works for many cases: It handles single-object and multi-object motion, larger movements, and unusual motion patterns better than several baselines.
- Flexible applications: You can control objects, the camera, rotate things in 3D-like ways, and even transfer motion from one video to another.
Why this matters:
- Creators get precise, easy motion control without heavy tools.
- Researchers get a simpler, scalable method that plays nicely with strong image-to-video backbones.
- MoveBench provides a fair way to compare different motion-control methods.
Limitations and what’s next
- If an object disappears for too long (is occluded), the motion path can break and control may weaken until it reappears.
- Like other generative tools, this technology could be misused to make misleading content. Responsible use is important.
The big picture
Wan-Move shows that a simple idea—copy the first frame’s features along your chosen motion path in the model’s mini-map—can give precise, high-quality motion in AI-generated videos without complicating the model. MoveBench helps everyone measure progress in a clear, consistent way. Together, they bring motion-controlled video generation closer to practical, creative use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Based on the paper, the following issues remain unresolved and present actionable directions for future research:
- Robust occlusion handling: The method loses control when tracks disappear for prolonged periods; develop occlusion-aware propagation (e.g., layered depth/segmentation, visibility prediction, re-identification) to maintain motion continuity through occlusions.
- Overlapping trajectory conflicts: Current conflict resolution randomly selects a feature when trajectories coincide; investigate principled blending (weighted averaging, alpha compositing), learned priority/occlusion ordering, and layered latent representations to avoid artifacts.
- 3D-consistent camera/object motion: Camera control relies on monocular depth projection and z-buffering but is not rigorously evaluated; quantify parallax consistency, depth accuracy, and occlusion handling for real camera moves and complex scene geometry.
- Non-rigid and articulated motion: Copying first-frame latent features along point tracks may inadequately capture deformations (stretching, bending, articulation); explore region-wise warping, learned motion fields, and dynamic appearance updates that model local shape change.
- Trajectory-to-latent mapping: Averaging positions over frames may introduce temporal aliasing for fast motion; compare alternatives (interpolation, motion integration, velocity-aware mapping) and quantify their effects on timing and accuracy.
- Dependence on tracker quality: Training and evaluation rely on trackers (e.g., CoTracker, RAFT) that can drift or jitter; analyze sensitivity to tracking errors and develop robustness (confidence weighting, denoising, trajectory smoothing, uncertainty modeling).
- Training–inference track-density mismatch: Best performance with 200 tracks for training but evaluation benefits from up to 1024 tracks; design curricula or stochastic density schedules to reconcile this mismatch and study generalization across densities.
- Multi-object interactions and physical plausibility: No mechanism enforces collisions/contact dynamics or causal interactions; integrate physics constraints or simulators and evaluate with physical plausibility metrics beyond EPE.
- Duration and resolution scalability: Results are limited to 5-second, 480p videos; investigate extensions to minute-long sequences and 1080p/4K with stable motion control, including memory-efficient chunking/streaming and temporal consistency maintenance.
- Identity and texture preservation under large displacements: Copying first-frame features may degrade identity consistency and textures over long motions; develop appearance refresh mechanisms (e.g., texture synthesis, identity constraints) to preserve look and detail.
- Generalization across backbones/VAEs: The approach assumes translation equivariance of VAE latents; formally characterize and test this assumption across diverse VAEs/backbones, and identify conditions where latent replication breaks down.
- Fusion strategy analysis: While concatenation works, the comparative merits vs. gated, residual, or adapter-based fusion are not studied; analyze training stability, motion adherence, and visual quality across fusion schemes.
- Handling visibility labels: Training replicates features only on visible tracks; explore strategies to hallucinate motion through occlusion (predictive priors, temporal inpainting) and optimize reappearance behavior.
- Region-/semantic-level controls: Extend beyond single-pixel tracks to mask/part-level trajectories with scale/rotation control; combine segmentation and tracking to enable structured control of entire objects or articulated parts.
- Authoring tools and interfaces: Develop intuitive trajectory authoring (sketch-based, keyframe curves, language-to-trajectory) and error correction tools; evaluate usability and user error robustness.
- Evaluation metrics beyond EPE: EPE relies on tracker-estimated tracks from generated videos, introducing evaluation bias; add metrics for timing/velocity profiles, region adherence, identity preservation, and physical plausibility; incorporate human studies at larger scale.
- Benchmark coverage and bias: MoveBench’s 54 categories and 5s clips may underrepresent heavy camera motion, long-range dynamics, and complex multi-object interactions; expand categories, clip lengths, OOD cases, and motion types (e.g., rare dynamics, occlusion-heavy scenes).
- Annotation fidelity: Hybrid SAM+human masks and point tracks can contain errors; quantify annotation noise, its effect on training/evaluation, and establish verification/consensus protocols to improve label reliability.
- Safety and provenance: The model’s controllability raises dual-use risks; incorporate robust watermarking/provenance, usage policies, and defenses against watermark removal; study user misuse detection under motion control.
- Guidance scale and conditioning: Classifier-free guidance is fixed at ; systematically study its effect on motion adherence/visual artifacts and design adaptive guidance policies conditioned on scene content and trajectory characteristics.
- Neighborhood-aware latent copying: Current replication copies a single latent position; test copying local patches, learned kernels, or multi-scale feature blending to better align textures and motion in surrounding regions.
- Intersection ordering over time: Crossing trajectories can cause texture swaps; implement layered scene representations with depth ordering to manage temporal visibility and prevent identity confusion.
- Interactive and real-time control: Latency and responsiveness for on-the-fly trajectory edits are not addressed; explore incremental/streaming generation, partial re-synthesis, and low-latency pipelines for interactive editing.
- Robustness to noisy/sparse user inputs: Study tolerance to discontinuous, imprecise, or sparse trajectories; learn priors to infer plausible motion from minimal inputs and provide uncertainty-aware control.
- Motion transfer across domains: Transferring trajectories between disparate scenes can fail due to scale/perspective/domain gaps; develop normalization/alignment (scale, perspective, timing) and domain adaptation techniques for reliable transfer.
- Joint text–motion conditioning: Investigate mapping natural language (e.g., “move the cup left, then tilt”) to trajectories and ensure consistency between action semantics and resulting motion profiles.
- Theory of latent replication: Provide formal analysis of why latent feature replication outperforms random embeddings and pixel-level replication; study information propagation and controllability in DiT architectures.
- Data filtering bias: SigLIP-based stability filtering may bias toward low-variation videos, reducing training diversity; quantify impacts and design filtering that retains complex motion while preserving consistency.
- Motion-condition dropout schedule: The 5% probability of dropping motion conditions is heuristic; optimize dropout schedules (e.g., curriculum, scene-dependent) to balance I2V quality retention and motion adherence.
- Trajectory discontinuities and re-identification: Implement object ID continuity when tracks break or reinitialize; explore identity embeddings, long-term association, and visibility-informed re-linking without auxiliary encoders.
- Compute and energy reporting: Training/inference compute, energy, and latency are only partially reported; provide comprehensive efficiency analyses across backbones/resolutions/durations and study scalability to resource-constrained settings.
Practical Applications
Overview
Wan-Move introduces a motion-controllable, image-to-video generation framework that achieves fine-grained control by injecting point-trajectory guidance directly into latent image features—without auxiliary motion encoders. It scales to high-fidelity, 5-second 480p outputs and is benchmarked via MoveBench, a curated dataset with dense motion annotations. Below are practical, real-world applications enabled by Wan-Move’s findings and methods.
Immediate Applications
- Motion Brush–style video editing for creators and studios (Media, Advertising, Software)
- What: Integrate trajectory-based “drag-to-animate” into video editors to animate objects and backgrounds from a single image with precise control.
- Tools/products/workflows:
- Plugins for Adobe After Effects/Premiere, DaVinci Resolve, Blender: UI to draw trajectories; API to run Wan-Move inference.
- Web/mobile apps for “drag-to-animate” (image + points/paths → 5-second video).
- Assumptions/dependencies:
- 5-second, 480p outputs are acceptable; higher resolutions or longer durations may need scaling.
- Requires GPU inference and an I2V backbone (e.g., Wan-I2V-14B).
- Trajectories must be specified or extracted; occlusion can reduce control stability.
- Controlled motion transfer from reference videos (Media, Social, E-commerce)
- What: Extract point tracks from a reference video (e.g., fabric flutter, hair sway, camera pan) and apply to a new image/product shot.
- Tools/products/workflows: CoTracker for tracking → latent trajectory mapping → Wan-Move generation.
- Assumptions/dependencies:
- Motion transfer works best when scene semantics are compatible; large domain shifts can reduce realism.
- Tracking quality limits transfer fidelity.
- Camera path and background motion control (Media, Education)
- What: Programmatically control camera pans/zooms/dollies using background point tracks or depth-based projection to create consistent camera motion.
- Tools/products/workflows: Monocular depth (e.g., Depth-Anything-like models) → project paths → generate with Wan-Move.
- Assumptions/dependencies:
- Monocular depth errors may affect realism.
- Complex parallax/occlusions remain challenging.
- Previsualization and storyboarding (Film, Animation, VFX)
- What: Rapidly prototype motion beats (object motions, camera moves), iterate on timing and blocking without full 3D rigs.
- Tools/products/workflows: Image concept art + drawn trajectories → animatic clips; batch generation for alternative takes.
- Assumptions/dependencies:
- Suitable for short beats (5s), proof-of-concepts; full scenes still require longer duration support.
- Targeted social content and ads (Marketing, SMBs)
- What: Produce motion-consistent variants for A/B testing (e.g., different product spin paths or UI element motions).
- Tools/products/workflows: Template images + trajectories library; scripted batch generation pipeline.
- Assumptions/dependencies:
- Brand safety review needed; watermarking recommended for synthetic content policies.
- Educational visualizations and explainers (Education)
- What: Animate diagrams and processes by manually specifying motion (e.g., planetary orbits, mechanical linkages, biological processes).
- Tools/products/workflows: Slide/whiteboard image + trajectories → short video segments for lessons.
- Assumptions/dependencies:
- Requires careful trajectory authoring for scientific accuracy.
- Benchmarking and evaluation with MoveBench (Academia, Industry R&D, Policy)
- What: Use MoveBench to evaluate motion controllability, long-range dynamics, multi-object motion, and compare methods with reliable annotations.
- Tools/products/workflows: Adopt MoveBench dataset + EPE/FID/FVD metrics; integrate into model development pipelines.
- Assumptions/dependencies:
- Benchmark resolution/duration fixed (480×832, 5s); additional benchmarks may be required for other regimes (e.g., 4K, >30s).
- Synthetic datasets for perception and tracking (Academia, Computer Vision)
- What: Generate motion-controlled sequences to pre-train or test tracking, optical flow, and action recognition algorithms with precise ground-truth trajectories.
- Tools/products/workflows: Program motion scripts → Wan-Move generation → use known trajectories for supervision/evaluation.
- Assumptions/dependencies:
- Synthetic-to-real gap remains; careful curriculum or domain adaptation may be necessary.
- Rapid creation of training clips for UI/UX demos (Software)
- What: Animate UI states (transitions, tooltips, gestures) directly from design mockups for product demos and marketing.
- Tools/products/workflows: Figma/Sketch exports → trajectory annotations → Wan-Move video snippets.
- Assumptions/dependencies:
- Fine-grained UI element consistency depends on trajectory precision and first-frame fidelity.
- Annotation pipelines for motion benchmarks (Academia, Tools)
- What: Replicate the hybrid SAM + human annotation workflow to build internal motion datasets.
- Tools/products/workflows: SAM-based mask bootstrapping; interactive labeling interface; point/mask exports compatible with multiple methods.
- Assumptions/dependencies:
- Requires human-in-the-loop for quality; SAM performance varies with domain.
Long-Term Applications
- Real-time interactive motion editing and live content (Media, Streaming, AR)
- What: On-the-fly motion editing during streams or live productions; interactive AR filters where users “drag” elements to animate live.
- Tools/products/workflows: Low-latency inference; GPU-optimized pipelines; trajectory-aware UIs for touch/pen inputs.
- Assumptions/dependencies:
- Requires significant optimization to reduce latency, and robustness to occlusions and noisy inputs.
- 3D-consistent, longer, and higher-resolution controllable videos (Media, VFX, Gaming)
- What: Extend to minute-long 1080p/4K sequences with consistent object identities and camera geometry.
- Tools/products/workflows: Multi-shot stitching; temporal modules; integration with 3D asset pipelines (e.g., NeRFs, 3D Gaussians).
- Assumptions/dependencies:
- Demands model scaling, memory optimization, and improved 3D consistency mechanisms.
- Simulation and digital twins with controlled scenarios (Autonomy, Robotics, Urban Planning)
- What: Generate controlled edge-case videos (e.g., pedestrian trajectories, occlusions) for perception testing and operator training.
- Tools/products/workflows: Scenario libraries → trajectory scripts → synthetic validation suites.
- Assumptions/dependencies:
- Requires domain-specific realism (lighting, physics) and consistent camera models; regulatory acceptance for validation is nontrivial.
- Training data for robot policy learning and imitation (Robotics)
- What: Synthesize demonstration videos with controllable object motions to augment scarce real data for imitation learning.
- Tools/products/workflows: Coupling with vision-language-policy pipelines; curriculum of increasing motion complexity.
- Assumptions/dependencies:
- Bridging sim-to-real remains challenging; videos lack ground-truth 3D control unless augmented with depth/pose supervision.
- Sports analytics and tactical “what-if” generation (Sports, Broadcast)
- What: Generate plausible variations of player/ball movement to explore tactics, visualize strategies, or create training content.
- Tools/products/workflows: Tracking from match footage → trajectory edits → motion-transferred visualizations.
- Assumptions/dependencies:
- Requires high-fidelity identity preservation and domain-aware physics; IP and rights management for match footage.
- Personalized health and rehabilitation explainers (Healthcare, Patient Education)
- What: Generate personalized motion demos (e.g., exercise form) by transferring therapist-specified trajectories onto patient-specific imagery.
- Tools/products/workflows: Clinic-safe UIs with trajectory templates; privacy-preserving deployments.
- Assumptions/dependencies:
- Must ensure medical accuracy and safeguard patient data; requires clinician oversight.
- Curriculum datasets for action understanding and reasoning (Academia, AI Safety)
- What: Produce controlled sequences with compositional motion for testing causal/action reasoning in multimodal models.
- Tools/products/workflows: Programmatic trajectory grammars → diverse synthetic corpora → evaluation suites.
- Assumptions/dependencies:
- Ensuring that synthetic patterns reflect real-world statistics is critical for transferability.
- Regulatory evaluation suites for generative video controllability (Policy, Standards)
- What: Use MoveBench-like protocols to standardize controllability, safety, and transparency assessments before deployment.
- Tools/products/workflows: Test harnesses with EPE/FVD/FID; content watermarking and provenance infrastructure.
- Assumptions/dependencies:
- Requires cross-industry consensus and integration with content authenticity standards (e.g., C2PA).
Key Assumptions and Dependencies Across Applications
- Model and compute:
- Current capabilities target ~5-second 480p outputs; scaling to longer/higher-res requires more compute and potential model changes.
- Inference on large DiT backbones (e.g., Wan-I2V-14B) typically requires modern GPUs.
- Inputs and control signals:
- High-quality point trajectories (manual or via CoTracker) are critical; occlusions can degrade control (short-term recoverable, prolonged problematic).
- For camera control, monocular depth estimates introduce uncertainty.
- Ecosystem integration:
- Efficient UIs for trajectory authoring will drive usability (desktop and touch-first).
- Plugins/APIs for creative suites accelerate adoption.
- Data and legal:
- Training and content sources must be licensed appropriately; synthetic outputs should incorporate disclosure/watermarking where required.
- Use of MoveBench is governed by its license; ensure dataset separation to avoid leakage in evaluation.
- Ethics and misuse:
- As with all generative video tools, there’s dual-use risk. Deployments should include safeguards (watermarking, content provenance, and usage policies).
Overall, Wan-Move’s latent trajectory guidance and the MoveBench benchmark open immediate pathways for controllable video editing and evaluation, while laying the groundwork for longer, higher-resolution, 3D-consistent, and real-time applications across creative industries, robotics, simulation, and policy.
Glossary
- 3D U-Net: A convolutional neural network architecture with 3D operations designed to model spatiotemporal dependencies in video. "a 3D U-Net architecture."
- adaLN: An adaptive LayerNorm variant used for conditioning in transformer-based diffusion models. "Tora~\cite{zhang2024tora} adopts the lightweight adaLN~\cite{dit}."
- CLIP: A pretrained vision-LLM used here as an image encoder to provide global image context. "the CLIP~\cite{radford2021clip} image encoder"
- classifier-free guidance: A diffusion technique that mixes conditional and unconditional model predictions to strengthen adherence to conditioning. "Classifier-free guidance is applied to enhance alignment with conditional information."
- CoTracker: A video point-tracking model that provides dense trajectories and visibility states. "we use CoTracker~\cite{karaev2024cotracker} to track the trajectories of a dense 32Ã32 grid of points."
- ControlNet: An auxiliary network that injects external conditioning signals (e.g., motion cues) into diffusion backbones. "with ControlNet~\cite{controlnet} being a popular way to fuse motion cues."
- decoupled cross-attention: A mechanism to inject different condition embeddings (image/text) into the diffusion backbone via separate attention pathways. "injected into the DiT backbone via decoupled cross-attention~\cite{controlnet}."
- denoising diffusion probabilistic models (DDPMs): A generative framework that adds Gaussian noise to data and learns to reverse it for generation. "denoising diffusion probabilistic models (DDPMs)"
- DiT: Diffusion Transformer; a transformer backbone used for diffusion-based video generation. "Only the DiT backbone is trainable"
- DINOv2: A large pretrained vision transformer providing strong semantic features, sometimes used for correspondence but limited for fine motion. "rely on pretrained DINOv2 features~\cite{oquab2023dinov2}"
- end-point error (EPE): A trajectory accuracy metric measuring L2 distance between ground-truth and estimated tracks. "denoting this metric as end-point error (EPE)."
- FID: Fréchet Inception Distance; measures visual fidelity of generated frames. "including FID~\cite{heusel2017gans}"
- FVD: Fréchet Video Distance; evaluates temporal coherence and overall video quality. "FVD~\cite{2019FVD}"
- image-to-video (I2V): The task/model setup that animates a single input image into a multi-frame video. "image-to-video (I2V) generation model"
- latent feature replication: Propagating first-frame latent features along trajectories to encode motion directly in the conditioning. "which will be injected through latent feature replication (as detailed in Sec.~\ref{sec:latent_trajectory})."
- latent space: The compressed representational space produced by the VAE in which the model operates. "project these trajectories into latent space"
- monocular depth predictor: A model that estimates depth from a single RGB image to derive 3D structure. "a monocular depth predictor~\cite{yang2024depth}"
- optical flow: A dense, per-pixel motion field between frames used for fine-grained motion control/evaluation. "pixel-wise optical flow~\cite{yin2023dragnuwa, koroglu2024onlyflow,shi2024motioni2v,burgert2025gowiththeflow}"
- PSNR: Peak Signal-to-Noise Ratio; a reconstruction quality metric for generated frames. "PSNR"
- RAFT: A state-of-the-art optical flow network used to compute motion amplitude for subset curation. "extracted by RAFT~\cite{teed2020raft}"
- SAM: Segment Anything Model; an interactive segmentation tool used to produce precise masks. "prompting SAM~\cite{sam} to generate an initial mask."
- SigLIP: A vision-LLM whose image embeddings are used to filter videos by content stability. "extract SigLIP~\cite{zhai2023siglip} features"
- SSIM: Structural Similarity Index Measure; assesses perceptual similarity and structural fidelity. "SSIM~\cite{wang2004ssim}"
- translation equivariance: A property where spatial shifts in input lead to corresponding shifts in feature maps, enabling trajectory-based feature copying. "Given the translation equivariance of VAE models"
- umT5: A multilingual T5-based text encoder providing prompt conditioning. "umT5~\cite{chung2023umt5} text encoder"
- Variational Autoencoder (VAE): A latent-variable model with encoder/decoder used to compress videos into latent representations. "a pretrained VAE~\cite{kingma2013vae}"
- vector field: The velocity function predicted by the model to transport noisy samples toward the data distribution. "predict the vector field that transports samples from the noise distribution to the data distribution"
- z-buffering: A graphics technique for resolving occlusion during projection, used here to obtain camera-aligned trajectories. "applies z-buffering to obtain camera-aligned 2D trajectories."
Collections
Sign up for free to add this paper to one or more collections.

