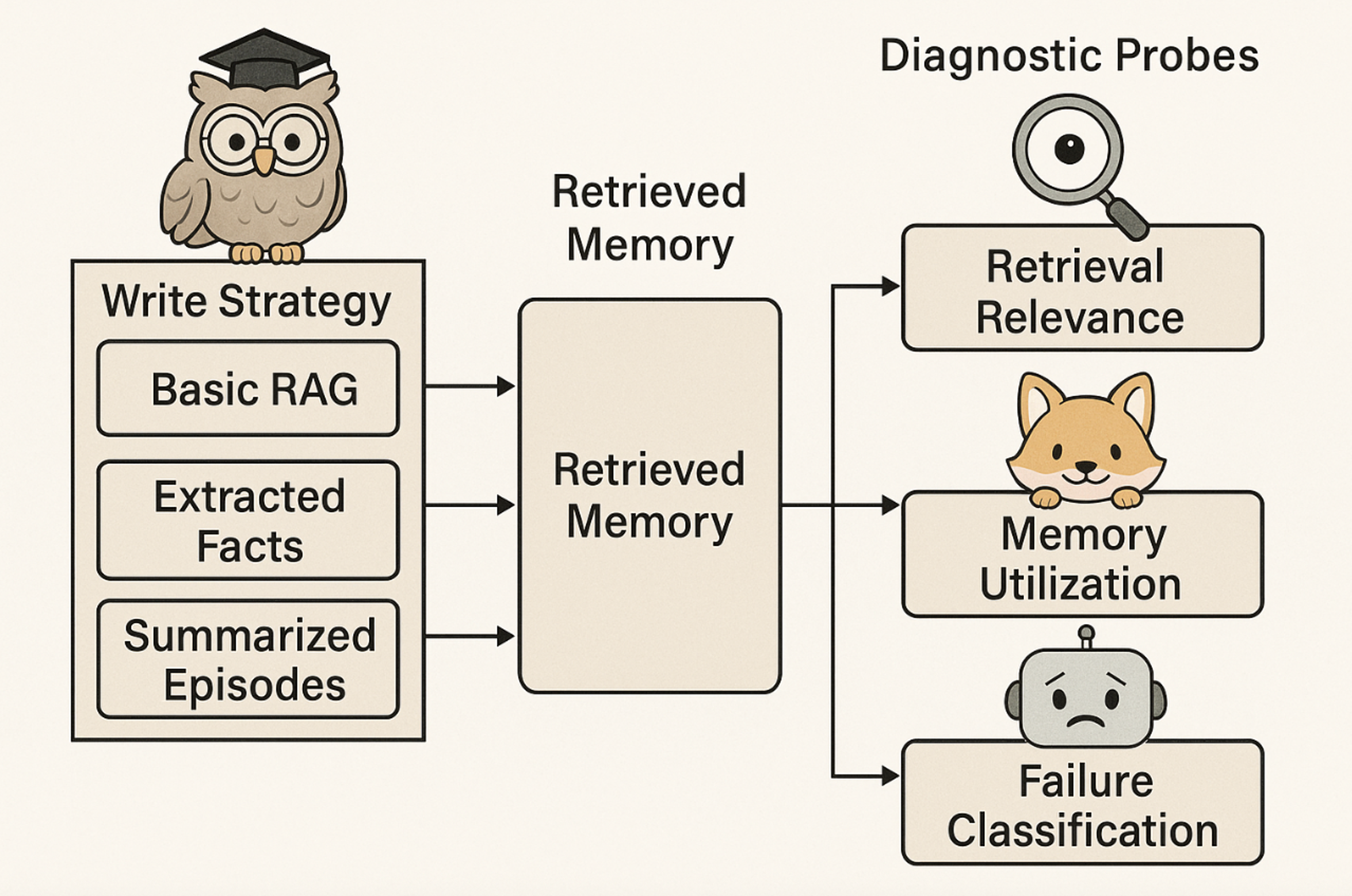
Diagnosing Retrieval vs. Utilization Bottlenecks in LLM Agent Memory
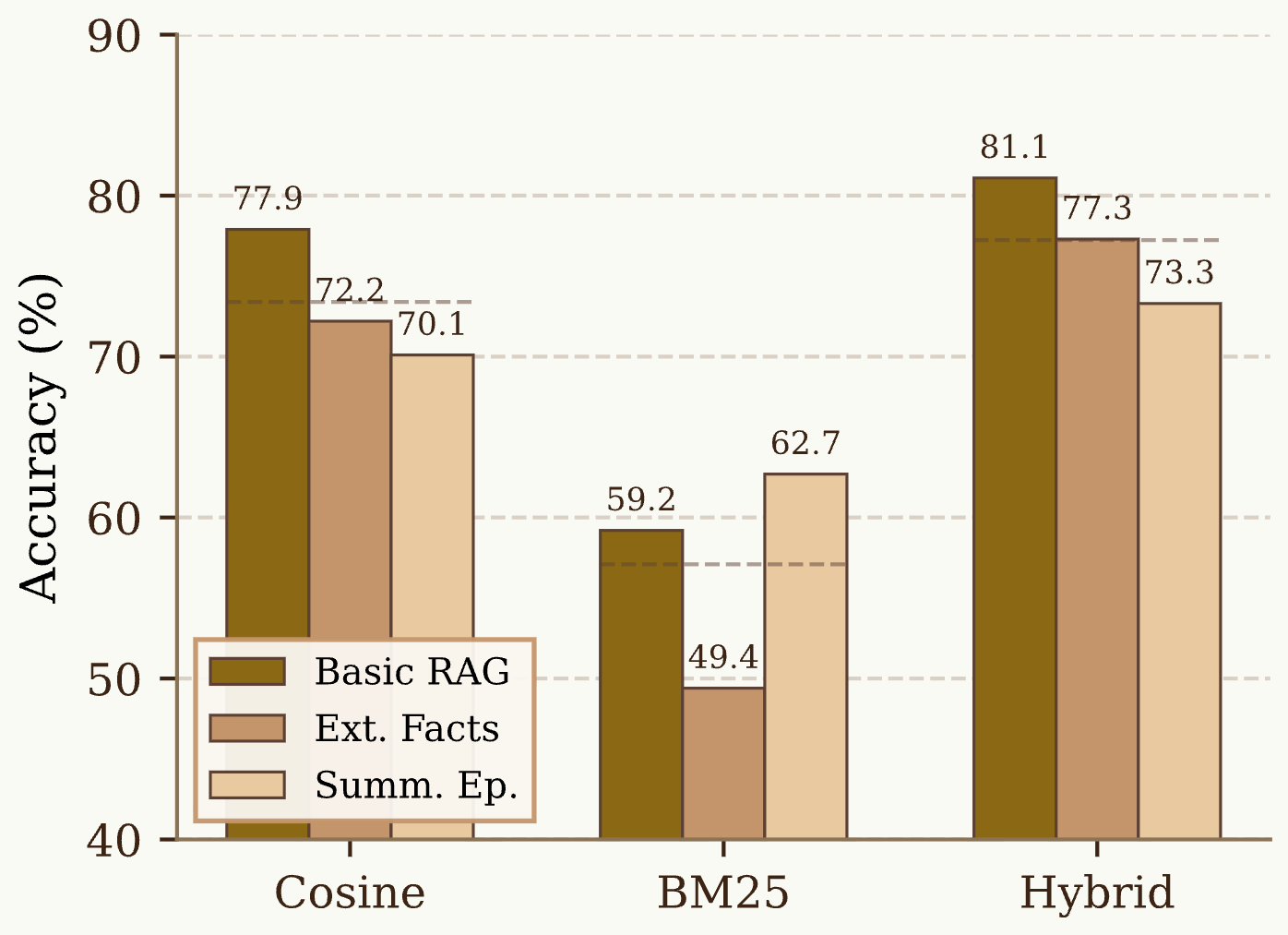
Abstract: Memory-augmented LLM agents store and retrieve information from prior interactions, yet the relative importance of how memories are written versus how they are retrieved remains unclear. We introduce a diagnostic framework that analyzes how performance differences manifest across write strategies, retrieval methods, and memory utilization behavior, and apply it to a 3x3 study crossing three write strategies (raw chunks, Mem0-style fact extraction, MemGPT-style summarization) with three retrieval methods (cosine, BM25, hybrid reranking). On LoCoMo, retrieval method is the dominant factor: average accuracy spans 20 points across retrieval methods (57.1% to 77.2%) but only 3-8 points across write strategies. Raw chunked storage, which requires zero LLM calls, matches or outperforms expensive lossy alternatives, suggesting that current memory pipelines may discard useful context that downstream retrieval mechanisms fail to compensate for. Failure analysis shows that performance breakdowns most often manifest at the retrieval stage rather than at utilization. We argue that, under current retrieval practices, improving retrieval quality yields larger gains than increasing write-time sophistication. Code is publicly available at https://github.com/boqiny/memory-probe.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper studies how AI chat assistants with “memory” should store and find information from past conversations. The big question: when these assistants answer questions about earlier chats, is success mostly about how memories are written down, or how well the system retrieves the right memories to use?
Key Questions
The authors ask three simple questions:
- Does the way we write memories (like raw notes vs. summaries) change how well the assistant answers questions?
- Does the method used to retrieve memories (how we search those notes) matter more?
- When the assistant gets an answer wrong, is the problem usually that it didn’t find the right memory, or that it didn’t use the memory correctly?
Methods, Explained Simply
Think of the assistant’s memory like a notebook full of past conversation notes. There are two main steps: writing notes and searching those notes later.
The team tested nine setups by mixing three ways to write notes with three ways to search them:
- How memories were written (stored):
- Raw chunks: Keep short blocks of the original conversation text. Like saving the actual chat messages.
- Extracted facts: Pull out key facts and store them as simple statements. Like making fact cards.
- Summaries: Write a short summary of each session. Like a paragraph that covers the main points.
- How memories were retrieved (searched):
- Meaning-based search (cosine similarity): Find notes that “mean” similar things to the question, even if the wording is different.
- Keyword search (BM25): Find notes with overlapping words. Great if the question and the notes use the same terms.
- Hybrid + reranking: Combine both searches, then ask a stronger AI to re-rank the results to pick the best ones. Like using both a word search and a meaning search, then asking a librarian to choose the top 5.
They ran these on a benchmark called LoCoMo, which has long, multi-session conversations and many questions about them. They also used three “probes” (tests) to diagnose what’s going on:
- Probe 1: Are the retrieved memories actually relevant to the question?
- Probe 2: Does giving the assistant those memories help its answer, hurt it, or make no difference?
- Probe 3: If the answer is wrong, is it because the system retrieved the wrong memories (retrieval failure), used the right memories badly (utilization failure), or contradicted the memories (hallucination)?
Main Findings and Why They Matter
- Retrieval method matters most. Switching the search method changed accuracy by about 20 percentage points. In contrast, changing how memories were written only changed accuracy by 3–8 points.
- The simplest write strategy (raw chunks) was as good as or better than fancy, expensive methods like extracting facts or writing summaries. Keeping the original details helps the assistant later.
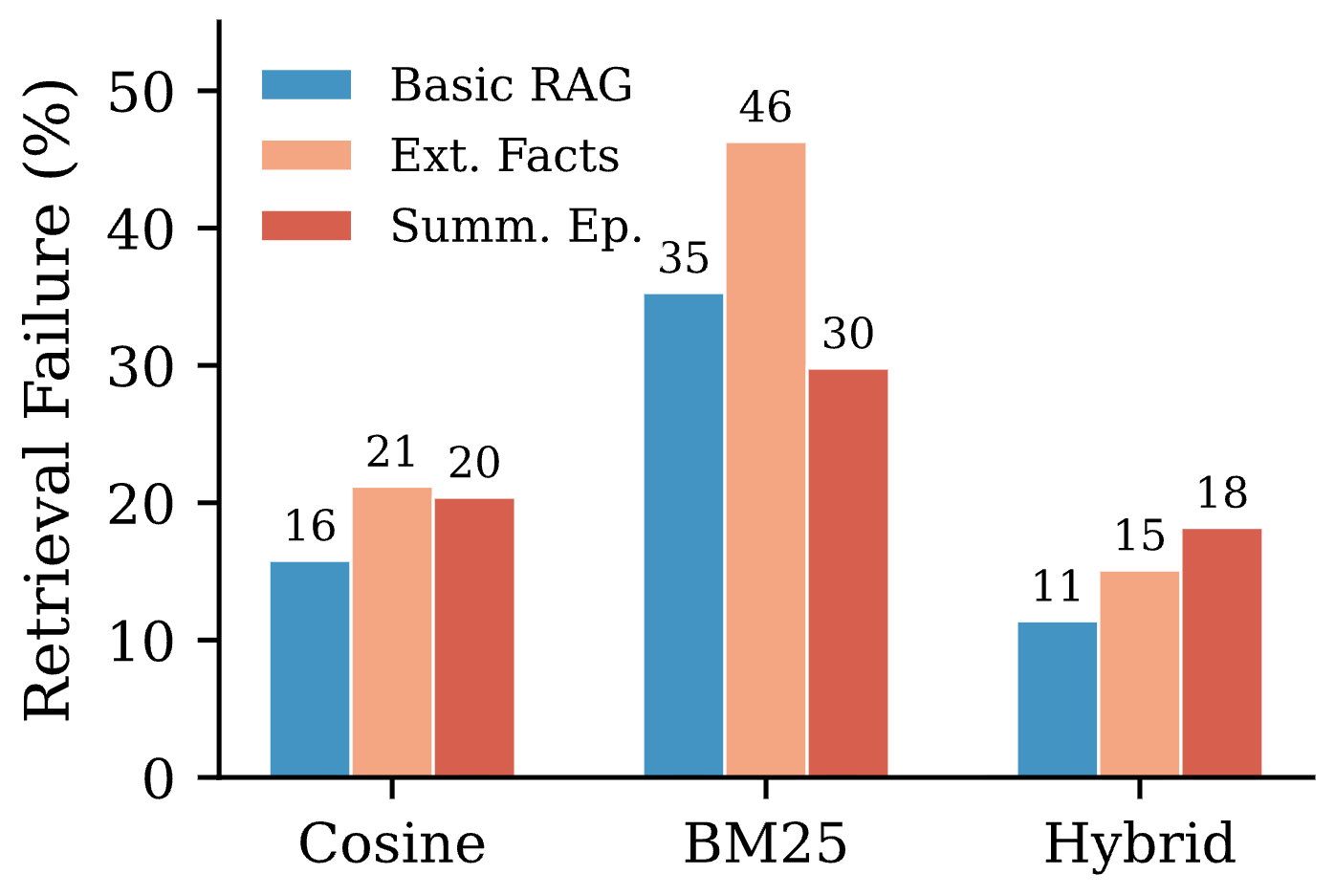
- Most errors are retrieval problems. In other words, the assistant fails more often because it didn’t find the right notes, not because it couldn’t reason with the notes it had.
- The hybrid search + reranking was best. Combining word matching and meaning matching, then letting a stronger AI re-rank the results, cut retrieval failures by roughly half in many cases.
- When relevant memories are found, the assistant usually uses them well. This suggests modern AI models are pretty good at using context if you give them the right pieces.
Why this matters: Many AI memory systems spend a lot of effort on “writing” sophisticated memories (like summaries or cleaned-up facts). This study shows that, with current tools, improving how we search and select the right memories has a bigger impact.
Implications and Impact
- Focus on better retrieval, not fancier writing. If you’re building a memory system for AI, invest first in high-quality search, reranking, and understanding the user’s question.
- Keep details when possible. Raw conversation chunks often work best because they preserve useful context that summaries or fact lists might throw away.
- Hybrid approaches are promising. Mixing keyword and meaning-based search, then reranking with a strong AI, can significantly boost accuracy.
- Practical takeaway: You can get strong performance with simple storage and smart retrieval, which can also save cost and complexity.
Note on limits: These results come from one model, one dataset, and a fixed setup, so they may not hold everywhere—especially when you have very tight input limits or use different learned memory systems. But the central lesson is clear: right now, finding the right memories matters more than how you write them.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the study, framed to guide actionable future work.
- Generalization across backbone models: Results are limited to GPT-5-mini; it is unknown whether stronger or weaker LLMs, or open-source models, shift the balance between write vs. retrieval importance.
- Embedding model dependence: Only text-embedding-3-small (1536-d) is used; the effect of different embedding models (sizes, architectures, domain-tuned embeddings) on retrieval precision and downstream accuracy is untested.
- Benchmark coverage: Findings are reported on LoCoMo (non-adversarial); performance and failure modes on other long-term memory datasets (LongMemEval, MemoryAgentBench, RealTalk) and adversarial splits remain unexplored.
- Retrieval budget sensitivity: The study fixes k=5 and pools top-2k from each retriever for hybrid; how accuracy and failure rates vary with k, pooling sizes, or dynamic budget allocation is not measured.
- Context window constraints: The benefits of raw chunking under tight input limits (smaller context windows or longer memory stores) and the compression trade-offs when fitting within model constraints are not quantified.
- Write-time information loss measurement: The framework does not directly measure what information is lost at write time; a methodology to quantify write-time preservation vs. loss (e.g., alignment against gold conversation facts) is missing.
- Learned memory systems: Prompt-based proxies for Mem0/MemGPT are evaluated; the behavior of learned or RL-optimized memory construction (Mem1, Mem-α) and their interactions with retrieval are not tested.
- Retrieval model variants: BM25, cosine, and LLM-based reranking are compared, but trained cross-encoders, dense–sparse fusion models, and supervised rerankers (fine-tuned on relevance labels) are not evaluated.
- Query understanding and expansion: The impact of query rewriting, query expansion (lexical or semantic), or multi-turn clarification on retrieval precision and utilization is not investigated.
- Chunking and indexing granularity: Only 3-turn chunks are stored; how chunk size, sliding windows, sentence-level indexing, or hierarchical/graph indexing affect retrieval precision is unknown.
- Temporal and entity-aware retrieval: The study does not assess specialized indexing (temporal anchors, entity coreference resolution, relationship graphs) that could improve multi-hop or temporal questions.
- Hybrid reranking design choices: The choice of pooling top-2k from each retriever and a single LLM judge is fixed; alternative fusion strategies, reranker prompts, judge models, and cost–quality trade-offs need ablation.
- Negative context effects: While “harmful” rates are reported, there is no analysis of which retrieval errors most degrade answers and how to mitigate harm (e.g., filtering, contradiction detection).
- Hallucination characterization: Hallucination is rare but underexplored; a deeper analysis of when and why answers contradict retrieved content, and interventions to prevent it, is missing.
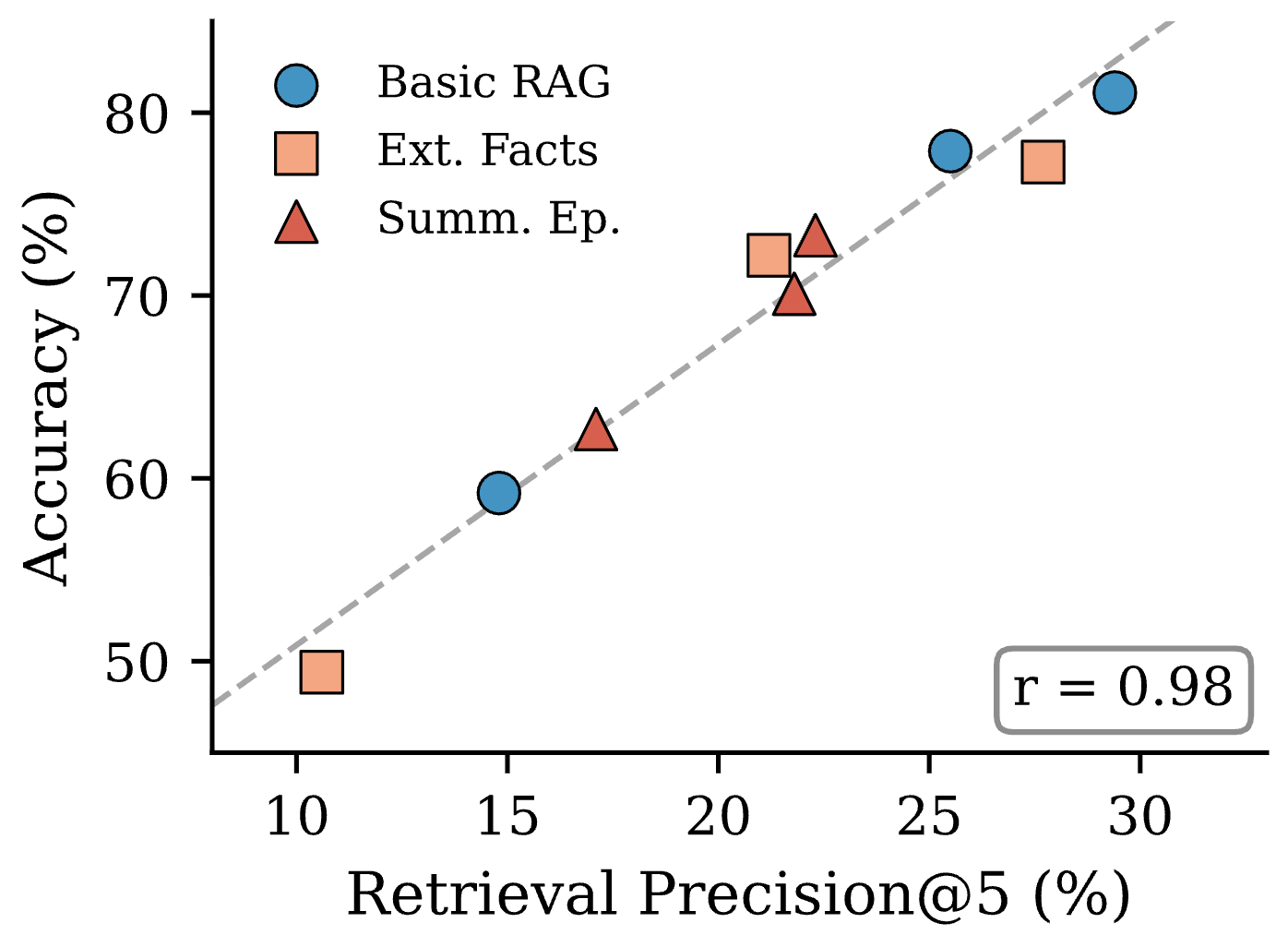
- Statistical robustness: Reported differences (e.g., r=0.98 correlation) are based on nine configurations; confidence intervals, significance testing, multiple seeds, and variance across conversations are not provided.
- LLM-as-judge reliability: Although partially validated, judge biases, sensitivity to prompt wording, and cross-judge consistency (different models, temperatures) need broader auditing, especially for failure categorization boundaries.
- Cost–benefit analysis: The operational cost trade-offs between raw chunking, fact extraction, summarization, and hybrid reranking (LLM calls per session/query) vs. accuracy gains are not quantified for realistic deployment scales.
- Memory growth and maintenance: Longitudinal effects (duplication, drift, forgetting policies, eviction strategies) and their interaction with retrieval precision over extended use are not studied.
- Conflict resolution efficacy: The Mem0-style update/noop logic is assumed but not evaluated for accuracy; how reliably conflict resolution preserves and updates facts—and its downstream impact—is unclear.
- Multilingual and domain transfer: Performance on multilingual conversations or specialized domains (clinical, legal, enterprise logs) and the need for domain-specific write/retrieval adaptations are open questions.
- Adversarial robustness: Retrieval resilience to paraphrase attacks, distractor memories, or misleading queries is not assessed; robust retrieval and anti-distractor mechanisms remain unexplored.
- Multi-hop reasoning with memory: The impact of retrieval strategies on multi-hop, cross-session reasoning (requiring multiple distinct memories) and whether rerankers can explicitly select complementary evidence is untested.
- End-to-end training: Whether jointly training retrieval, reranking, and utilization (e.g., contrastive supervision on relevance plus outcome-based reinforcement learning) outperforms modular pipelines remains unknown.
- Evaluation metrics: Token F1 misalignment with accuracy is noted; standardized, non-LLM metrics for relevance and utilization, or hybrid human–automatic protocols, need development to reduce reliance on LLM judges.
- Reproducibility artifacts: Detailed seeds, randomness controls, and implementation-level choices (indexing parameters, BM25 tuning) necessary for replicability and fair comparison are not reported.
- Privacy and safety: Storing raw chunks may retain sensitive details; strategies for privacy-preserving memory (redaction, differential privacy) and their impact on retrieval/utilization are not addressed.
Practical Applications
Overview
This paper introduces a diagnostic framework that disentangles where memory-augmented LLM agents fail—at writing (what is stored), at retrieval (what is surfaced), or at utilization (how the LLM uses retrieved context). Across a controlled 3×3 study on LoCoMo, the authors find that retrieval method dominates performance (14–23 point swings), while write strategy contributes little (3–8 points). Storing raw conversation chunks (zero LLM calls) matches or outperforms costly fact extraction and summarization. Hybrid retrieval (embedding + BM25 + LLM reranking) yields the highest accuracy and halves retrieval failures. The probes—retrieval relevance, memory utilization, and failure classification—provide actionable diagnostics to improve agent memory systems.
Below are practical applications grouped into what can be deployed now versus what will likely require further R&D, scaling, or validation.
Immediate Applications
These items can be deployable today with existing tooling and modest engineering effort.
- Software and enterprise AI assistants: Retrieval-centric optimization
- Replace or augment default embedding-only retrieval with hybrid retrieval (embedding + BM25 union, LLM reranker to top-k).
- Store raw conversation chunks instead of lossy summaries/facts to reduce write-time costs and preserve useful context.
- Embed the paper’s probes to monitor Retrieval Precision@k (as a leading indicator of accuracy), memory utilization (beneficial/ignored/harmful), and failure categories.
- Tools/workflows: “memory-probe” integration, retrieval A/B testing, dashboards tracking precision vs. accuracy, cached reranker decisions.
- Assumptions/dependencies: Costs for LLM reranking; context window sufficient to include retrieved chunks; index quality; privacy controls for raw logs.
- Customer support, sales, and CRM assistants (software, services)
- Improve case continuity by prioritizing hybrid reranking and raw logs across multi-session interactions.
- Use utilization probe to gate risky answers (e.g., answer only when retrieval is beneficial or precision exceeds a threshold; otherwise escalate or ask clarifying questions).
- Tools/workflows: “retrieval guardrail” policies, “not enough information” fallback, precision-triggered escalation.
- Assumptions/dependencies: Domain tuning of BM25 tokenization; acceptable latency for reranking; compliance with data retention policies.
- Healthcare contact centers and patient navigators (healthcare)
- Surface consistent patient histories across sessions using hybrid retrieval; prefer raw notes over aggressive summarization to avoid losing clinically relevant nuances.
- Add audit trails of retrieved memories to increase clinician trust; trigger “insufficient context” responses when retrieval precision is low.
- Tools/workflows: HIPAA-compliant memory stores, PII redaction, precision thresholds, human-in-the-loop review for critical tasks.
- Assumptions/dependencies: Strong privacy/security; institutional approval; careful handling of sensitive data; validated clinical workflows.
- Educational tutoring systems (education)
- Maintain student-specific raw logs (plans, misconceptions, preferences) and use hybrid retrieval to personalize feedback.
- Apply utilization probes to verify that memory actually improves answers; prompt for missing details when retrieval fails.
- Tools/workflows: per-student memory vaults, retrieval precision monitors, “context request” prompts.
- Assumptions/dependencies: Parental consent and data minimization; context budget management over long courses.
- Knowledge management and meeting assistants (software/productivity)
- Index raw meeting transcripts and notes; adopt hybrid retrieval for queries about decisions, owners, and deadlines.
- Add source transparency by showing retrieved snippets alongside answers; log failure modes to curate missing information.
- Tools/workflows: vector + BM25 hybrid indexes, LLM rerankers, “source panel” UI, failure-mode analytics.
- Assumptions/dependencies: Organizational adoption; storage costs; search latency; access control per team.
- Developer copilots and incident assistants (software/DevOps)
- Retrieve relevant commits, tickets, and incident postmortems using hybrid retrieval; avoid compressive write strategies that drop technical context.
- Guardrail answers when retrieval precision is low (e.g., require source evidence before code suggestions).
- Tools/workflows: repo and ticket indexing, reranker caching, evidence-linked suggestions.
- Assumptions/dependencies: Scaling indexes to large codebases; cost management; developer trust in sources.
- Financial research and compliance assistants (finance)
- Retrieve prior analyses, assumptions, and decisions; attach retrieved excerpts to outputs for auditability.
- Use failure diagnostics to identify gaps in coverage (e.g., missing notes) and guide curation.
- Tools/workflows: compliance logs, evidence panels, retrieval failure → curation tasks.
- Assumptions/dependencies: Regulatory requirements for record-keeping; confidential data handling; latency budgets.
- Legal practice management (legal)
- Index raw filings, briefs, and correspondence; employ hybrid retrieval to locate relevant precedent and case details.
- Display retrieved sources with citations; halt or flag analysis when retrieval precision falls below threshold.
- Tools/workflows: secure case memory stores, explainable retrieval UI, guardrail thresholds.
- Assumptions/dependencies: Privilege protection; accurate tokenization of legal text; acceptance by practitioners.
- Human–robot interaction and smart devices (robotics/consumer)
- Improve recall of user preferences and routines via hybrid retrieval over raw interaction logs.
- Prompt users for clarifications when relevant memory cannot be retrieved (reducing erroneous behaviors).
- Tools/workflows: on-device hybrid indexes, privacy-preserving logs, “clarify intent” interactions.
- Assumptions/dependencies: Edge compute constraints; privacy regulations; limited context windows.
- LLMOps/MLOps observability (software/infrastructure)
- Treat Retrieval Precision@k as a core KPI; alert when precision dips; run periodic retrieval audits.
- Introduce dynamic fallback (e.g., switch to hybrid when cosine precision degrades; cache frequent reranker outcomes).
- Tools/workflows: precision dashboards, automated probes on canary queries, cost–accuracy tradeoff policies.
- Assumptions/dependencies: Monitoring stack integration; reproducible judgments; budget limits for LLM calls.
- Policy and governance for memory-augmented AI (policy)
- Require retrieval provenance and precision reporting for high-stakes applications; log failure classifications for audits.
- Prefer raw storage only with strong minimization/redaction practices; document retention windows explicitly.
- Tools/workflows: audit logs of retrieved sources, precision thresholds in compliance checklists, PII redaction pipelines.
- Assumptions/dependencies: Sector-specific regulations; enforceable standards; stakeholder buy-in.
Long-Term Applications
These require further research, cross-domain validation, scaling, or standardization before routine deployment.
- End-to-end learned memory systems (software/AI)
- Couple write and retrieval via reinforcement learning to optimize what and how to store for downstream retrieval success.
- Dynamically compress or expand memory conditioned on query type, context budget, and usage patterns.
- Assumptions/dependencies: Broad benchmarking beyond LoCoMo; reliable offline-reward proxies; safety constraints.
- Adaptive retrieval budgets and query understanding (software)
- Automatically classify question types (temporal, multi-hop, open-ended) and allocate k, sources, and reranker strategy accordingly.
- Assumptions/dependencies: Robust query classifiers; latency tolerances; orchestration frameworks.
- Cost-efficient reranking models
- Replace LLM rerankers with distilled or specialized lightweight rerankers (cross-encoders or listwise models) that approximate LLM judgments at lower cost.
- Assumptions/dependencies: High-quality distillation datasets; generalization across domains; explainability and fairness testing.
- Multimodal memory retrieval (software/robotics/healthcare)
- Extend hybrid retrieval to audio, images, and video (e.g., meeting recordings, medical imaging) with unified sparse+dense indexes and reranking.
- Assumptions/dependencies: Multimodal embeddings and tokenization; storage and privacy for large media; latency.
- Privacy-preserving memory systems (policy/healthcare/finance)
- On-device or federated indexes, encrypted retrieval, differential privacy for logs; adaptive redaction guided by retrieval diagnostics.
- Assumptions/dependencies: Hardware capabilities; legal acceptance of privacy techniques; performance overhead.
- Sector standards for memory observability (policy/industry)
- Establish common metrics (e.g., Retrieval Precision@k, utilization rates) and audit procedures for regulated sectors (healthcare, finance, legal).
- Assumptions/dependencies: Multi-stakeholder standard-setting; harmonization across jurisdictions; certification bodies.
- Organizational “MemoryOps” platforms (software/enterprise)
- Products that unify storage (raw + structured), hybrid indexing, reranking, and diagnostic probes, with governance and access control.
- Assumptions/dependencies: Vendor ecosystem; integration with existing data lakes; data lineage tracking.
- Continuous memory curation via probes (software/data)
- Use retrieval failure signals to trigger targeted write updates (e.g., add missing facts, link sessions), active learning for query rewriting, and corpus cleanup.
- Assumptions/dependencies: Human-in-the-loop workflows; quality assurance; versioning of memory stores.
- Hardware and infrastructure for hybrid retrieval (infrastructure/edge)
- Accelerators and libraries optimized for combined vector and sparse search, plus fast reranking pipelines.
- Assumptions/dependencies: Ecosystem support; cost–benefit over cloud-only solutions; developer tooling.
- Robust benchmarking and generalization studies (academia)
- Expand the diagnostic framework across models, datasets, and tasks; include adversarial queries, different k budgets, and learned memory systems.
- Assumptions/dependencies: Community datasets, reproducible evaluation, agreement on LLM-as-judge reliability or human labels.
- Guardrailed answering policies (cross-sector)
- Formalize policies that block or defer answers when retrieval precision or probe signals fall below thresholds; integrate uncertainty communication.
- Assumptions/dependencies: User experience design; acceptance of “I don’t have enough information” responses; calibrated thresholds.
- Cross-system interoperability for memory (software)
- Standard schemas/APIs to exchange memory entries, relevance judgments, and failure classifications among tools.
- Assumptions/dependencies: Open standards; vendor participation; security models.
Notes on Assumptions and Dependencies
- The findings are based on one model (GPT-5-mini), one benchmark (LoCoMo), k=5 retrieval budget, and LLM-as-judge evaluations; results may vary across models, tasks, and domains.
- Raw chunking’s advantage may diminish under tight context windows; compression may be necessary and should be query-aware.
- Hybrid reranking increases per-query cost and latency; organizations must balance accuracy gains against budgets and SLAs.
- Privacy, security, and compliance requirements can constrain storing raw conversation logs; redaction, minimization, and on-device indexing become critical.
- Retrieval precision correlates strongly with accuracy in the reported setup; validate this relationship on your data before operationalizing thresholds.
Glossary
- A-MEM: An agent memory framework that augments LLM agents with structured, linked memories. "A-MEM~\citep{xu2025amem} adds inter-memory linking;"
- Basic RAG: A simple retrieval-augmented generation setup that stores and retrieves raw conversation chunks without LLM processing at write time. "Basic RAG stores raw 3-turn conversation chunks with speaker names and timestamps, requiring zero LLM calls at write time."
- BM25: A classic term-frequency–based ranking function for keyword retrieval that emphasizes exact term overlap. "BM25 scores entries by term-frequency-based keyword overlap, complementing embedding-based retrieval by surfacing entries that share exact terms with the query;"
- Cohen's kappa: A statistic measuring inter-annotator agreement beyond chance. "Cohen's indicates substantial agreement."
- conflict resolution (memory): A policy for deciding whether to add, update, or ignore newly extracted facts relative to existing memories. "followed by embedding-based matching and LLM conflict resolution (add/update/noop)."
- Extracted Facts: A write strategy that converts sessions into self-contained factual statements using an LLM, with subsequent deduplication/updates. "Extracted Facts follows Mem0~\citep{chhikara2025mem0}: an LLM extracts self-contained facts per session, followed by embedding-based matching and LLM conflict resolution (add/update/noop)."
- forgetting curves: A mechanism modeling memory decay over time to prioritize or prune stored information. "MemoryBank combines raw logs with hierarchical summaries and forgetting curves."
- Hallucination: An error where the model’s answer contradicts information in its own retrieved memories. "and Hallucination captures the rare cases where the model's answer directly contradicts the content of its own retrieved memories."
- Hybrid reranking: A retrieval strategy that combines multiple retrieval signals and uses an LLM to rerank candidates, often improving relevance. "Hybrid reranking cuts retrieval failures by half or more across all write strategies."
- Hybrid+Rerank: The specific method that unions cosine and BM25 candidates and applies an LLM judge to rerank down to top-k. "Hybrid+Rerank first pools the top-$2k$ candidates from both cosine and BM25, then uses GPT-5.2 as an LLM judge to rerank the union down to top-;"
- inter-memory linking: Explicit connections between memory items to capture relationships and improve retrieval/navigation. "A-MEM adds inter-memory linking;"
- LLM-as-judge: Using a LLM as an automatic evaluator for relevance, correctness, or error categorization. "Token F1 and LLM-as-Judge accuracy across all nine configurations (, 1,540 non-adversarial questions)."
- LoCoMo: A long-context conversational memory benchmark used to evaluate memory-augmented agents. "Evaluating on LoCoMo (1,540 non-adversarial questions),"
- MEM1: A learned memory-management approach that uses reinforcement learning to optimize writing/retrieval jointly. "MEM1~\citep{zhou2025mem1learningsynergizememory} and Mem-~\citep{wang2025memalphalearningmemoryconstruction} learn memory management via reinforcement learning,"
- Mem-: A reinforcement-learning–based method for constructing and managing agent memory. "MEM1~\citep{zhou2025mem1learningsynergizememory} and Mem-~\citep{wang2025memalphalearningmemoryconstruction} learn memory management via reinforcement learning,"
- Mem0: A production-oriented memory system emphasizing scalable fact extraction and conflict resolution. "Mem0~\citep{chhikara2025mem0} extracts facts with conflict resolution;"
- MemGPT: A memory framework that uses recursive summarization to maintain long-term context for agents. "MemGPT~\citep{packer2023memgpt} uses recursive summarization;"
- MemoryBank: A memory architecture combining raw logs and hierarchical summaries with decay mechanisms. "MemoryBank~\citep{zhong2023memorybankenhancinglargelanguage} combines raw logs with hierarchical summaries and forgetting curves."
- Precision@k: The fraction of retrieved items among the top k that are relevant to the query. "We report Retrieval Precision@ = ."
- reranker: A model (often an LLM) that reorders candidate retrievals using richer signals than the initial retrievers. "with the reranker resolving disagreements between the two retrieval sources."
- retrieval budget: The maximum number of memory items (k) retrieved for inclusion in the model’s context. "with a default retrieval budget of ."
- retrieval failure: An error category where relevant information is not surfaced at inference time, either due to missing storage or poor ranking. "Retrieval failure is the dominant error mode,"
- retrieval-to-generation boundary: The interface point in the pipeline where retrieved context is handed off to the LLM for answer generation. "sits at the retrieval-to-generation boundary"
- Token F1: A token-level overlap metric measuring similarity between a system’s answer and the gold answer. "Token F1 and LLM-as-Judge accuracy across all nine configurations"
- top-k: Selecting the k highest-scoring items from a ranked list for downstream use. "Cosine similarity returns the top- memory entries by cosine distance between the query embedding and each stored entry's embedding;"
- utilization failure: An error where relevant memories were retrieved but the model failed to use them correctly in generating the answer. "Utilization failure applies when at least one relevant memory was retrieved but the model still produced an incorrect answer,"
Collections
Sign up for free to add this paper to one or more collections.