GenDB: The Next Generation of Query Processing -- Synthesized, Not Engineered
Abstract: Traditional query processing relies on engines that are carefully optimized and engineered by many experts. However, new techniques and user requirements evolve rapidly, and existing systems often cannot keep pace. At the same time, these systems are difficult to extend due to their internal complexity, and developing new systems requires substantial engineering effort and cost. In this paper, we argue that recent advances in LLMs are starting to shape the next generation of query processing systems. We propose using LLMs to synthesize execution code for each incoming query, instead of continuously building, extending, and maintaining complex query processing engines. As a proof of concept, we present GenDB, an LLM-powered agentic system that generates instance-optimized and customized query execution code tailored to specific data, workloads, and hardware resources. We implemented an early prototype of GenDB that uses Claude Code Agent as the underlying component in the multi-agent system, and we evaluate it on OLAP workloads. We use queries from the well-known TPC-H benchmark and also construct a new benchmark designed to reduce potential data leakage from LLM training data. We compare GenDB with state-of-the-art query engines, including DuckDB, Umbra, MonetDB, ClickHouse, and PostgreSQL. GenDB achieves significantly better performance than these systems. Finally, we discuss the current limitations of GenDB and outline future extensions and related research challenges.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces GenDB, a new way to run database queries. Instead of relying on one large, hand‑built database engine, GenDB uses an AI (a LLM, or LLM) to write a tiny, custom program for each query. That program is tailored to the exact data, the kind of questions people ask, and the computer it runs on. The goal is to make queries run much faster and to make it easier to add new features without rebuilding an entire system.
Think of it like this: instead of using a Swiss‑army knife for every job, GenDB 3D‑prints the perfect tool for the task right when you need it.
What questions were the researchers asking?
They focused on a few simple questions:
- Can an AI automatically write fast, correct code to answer database questions?
- Is this “custom code per query” approach faster than today’s best database systems?
- How should a system like this be organized so it can analyze data, plan, write, test, and improve code automatically?
- Where does this approach shine, and what are its limits?
How did they do it?
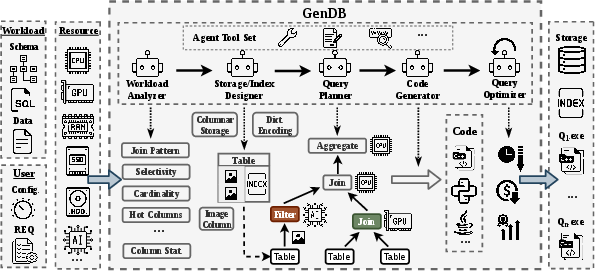
GenDB works like a team of specialized AI assistants (agents) that cooperate:
- Understand the situation It reads the database layout (like a very big, organized spreadsheet), the queries (in SQL or plain English), and the computer’s hardware. It summarizes key facts, like which columns get filtered, how big the tables are, and what the machine can do (for example, does it have fast special instructions or a big cache).
- Design the storage and indexes Storage is how data is physically laid out; an index is like a book’s index that helps you jump straight to what you need. GenDB can reorganize data (for example, column‑by‑column for analytics) and build helpful indexes automatically.
- Plan the query It picks the best way to answer the question—what to filter first, how to join tables, and how to group and aggregate results—based on the earlier analysis.
- Generate code It writes executable code (often in C++ for speed) that implements the plan and uses tricks the computer is good at. Then it runs the code and checks the results by comparing them to a traditional database system to make sure the answers match.
- Improve with feedback It times the code, spots slow parts, and rewrites them—iterating until it meets the user’s goals or runs out of budget (like a limit on how many attempts it can make).
They tested GenDB on two analytics workloads (these are read‑heavy tasks that summarize large amounts of data, often used for reports):
- TPC‑H: a well‑known benchmark used by many researchers.
- SEC‑EDGAR: a new, real‑world financial dataset they built to avoid the chance the AI had seen similar queries during training.
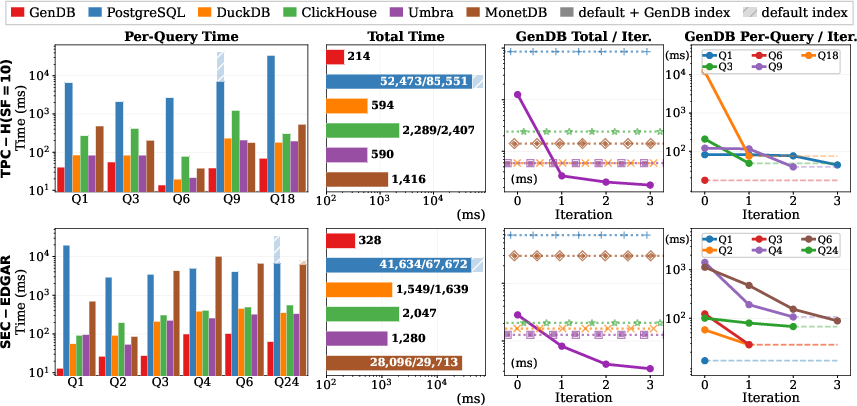
GenDB’s results were compared to top database systems: DuckDB, Umbra, MonetDB, ClickHouse, and PostgreSQL. All tests ran on the same server, and they measured “hot runs” (re‑runs after the data is already in memory) to focus on computation speed.
Quick glossary:
- LLM: an advanced AI that can understand and generate text and code.
- OLAP (analytics): reading and summarizing large data for insights, rather than updating lots of small records.
- Index: a shortcut to find relevant rows quickly.
- Hot run: measuring speed after the data is already cached in memory.
What did they find, and why is it important?
Main results:
- GenDB was significantly faster than all comparison systems on every query they tested.
- On a subset of TPC‑H queries, GenDB ran about 2.8× faster than the fastest traditional systems.
- On the SEC‑EDGAR tasks, it was about 5× faster than DuckDB and about 3.9× faster than Umbra.
- The more complex the query, the bigger the speed‑ups. In some cases, after a few rounds of improvement, GenDB reduced a query from many seconds to a tiny fraction of a second.
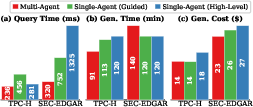
- A “multi‑agent” design (specialists for analysis, storage, planning, code, and optimization) worked better and cost less than using a single, general‑purpose AI agent.
Why it works:
- Tailor‑made code avoids general‑purpose “one size fits all” overheads.
- It picks strategies that match the actual data and the computer hardware (for example, choosing different methods if there are only a few groups vs. millions, so results fit better in fast CPU caches).
- It can build small, custom data structures just for the queries you actually run.
Why it matters:
- Faster analytics means quicker answers to business questions.
- New techniques (like working with images or using GPUs) can be adopted without redesigning a big system.
- For companies that repeat the same queries often, the one‑time cost of generating code can be shared over many runs, making it very efficient.
What does this mean for the future?
Potential impact:
- How databases are built may change: instead of spending years engineering a single huge engine, AI could generate the right code at the right time.
- It could make it easier to support new data types (like images or audio) and to use specialized hardware (like GPUs) where it helps most.
- A hybrid setup makes sense: a traditional database for one‑off or ad‑hoc queries, and GenDB for frequent or heavy queries that deserve custom code.
Current limits and next steps:
- Correctness checks: Today, GenDB compares its answers to a known database. If that “ground truth” isn’t available, a human expert should review the code. There are no formal guarantees for answers generated from plain‑English questions without SQL.
- Cost and speed of code generation: They plan to reduce cost by using smaller AIs for simpler steps, reusing pieces of code across queries, and trimming the AI’s inputs to cut “token” usage.
- Reliability: They want to handle cases where AI‑generated code gets stuck or is inefficient, improve how the AI agents talk to each other, and add stronger verification.
- Learning over time: The system could keep an “experience” memory of what worked and what failed to improve future generations automatically.
In one sentence
GenDB shows that having an AI write a tiny, custom program for each database query can make analytics much faster and more flexible, hinting at a future where databases are synthesized on demand instead of painstakingly engineered by hand.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of unresolved issues that are either missing, uncertain, or left unexplored in the paper; each item is phrased to be actionable for future research.
- Lack of formal correctness guarantees for generated code beyond result comparison to a reference DBMS; investigate automated test generation, property-based/metamorphic testing, and formal verification for common query templates.
- No strategy to guarantee SQL standard compliance across edge cases (NULLs, collations, outer joins, window functions, time zones, numeric overflow/underflow, complex types); evaluate coverage and correctness across the full SQL surface.
- Correctness for natural-language-driven queries is explicitly unspecified; design guardrails and validation techniques for NL-to-code paths to bound semantic drift and hallucination.
- Reliance on a ground-truth engine (e.g., DuckDB) for correctness checking limits deployment where no trusted reference exists; develop reference-free validation methods (e.g., equivalence rewriting, randomized differential testing).
- Floating-point determinism and parallel reduction non-associativity are not addressed; define acceptable numerical tolerances and reproducible reduction strategies for consistent results.
- Only hot-run latencies on in-memory datasets (TPC-H SF=10 and SEC-EDGAR ~5 GB) are reported; evaluate cold-cache performance, disk I/O-bound scenarios, and larger-than-memory datasets.
- End-to-end amortized performance is not quantified; measure total wall-clock time including storage/index build, code synthesis/compilation, and iterative optimization to establish break-even points versus traditional engines as a function of query repetition.
- Concurrency and throughput are untested; assess performance under multi-tenant workloads, simultaneous queries, and cross-query interference on shared caches and memory bandwidth.
- Update-heavy or mixed OLTP/OLAP workloads are out of scope; design and evaluate incremental maintenance of generated storage/index structures and incremental regeneration of code when data or schema change.
- Distributed or multi-node execution is not considered; explore code synthesis for distributed joins/aggregations, data partitioning strategies, and coordination protocols.
- Generality across diverse schemas and complex join graphs is unproven; systematically test on varied join topologies, high skew, heavy LIKE patterns, and extreme cardinalities beyond TPC-H/SEC-EDGAR subsets.
- Portability and robustness of hardware-specialized code are unclear; study how generated code adapts to different CPU microarchitectures, NUMA topologies, and varying cache hierarchies without manual retuning.
- GPU/accelerator support is proposed but not implemented; quantify benefits and trade-offs of GPU-native operator generation (e.g., libcudf, RMM), including data transfer orchestration and hybrid CPU–GPU execution.
- Multi-objective or constrained optimization (e.g., latency under memory caps or cost budgets) is not realized; implement optimization algorithms that handle SLAs and cost–performance trade-offs with formal objective definitions.
- The optimizer’s search procedure is not specified (beyond iterative refinement and early stopping); formalize the optimization loop (search space, acquisition functions, stopping rules) and report convergence properties.
- Silent failure modes (non-terminating probes, load-factor blowups, LLM output truncation) are only mitigated with timeouts; develop static analyses, runtime watchdogs, and synthesized “safe” data structures (e.g., capped-load-factor hash tables) and prove liveness properties.
- Generated C++ raises memory-safety and concurrency risks; evaluate safe-by-construction approaches (e.g., Rust, sanitizers, formal contracts), sandboxing (e.g., seccomp, WASM), and automated static/dynamic analysis gates before execution.
- Inter-agent misalignment (e.g., DECIMAL scale handling) reveals missing type-checked IR; introduce a strongly-typed intermediate representation and schema-aware codegen that enforces type/scale rules across agents.
- Inter-agent communication is JSON/template-based but not enforced; assess typed protocols (e.g., MCP, A2A) with schema validation, budget/constraint enforcement across dynamically spawned sub-agents, and failure-recovery policies.
- External domain knowledge is not integrated; design a curated, verifiable knowledge base and retrieval pipeline (with source attribution and trust scoring) to augment parametric knowledge without introducing noise.
- Security and privacy of LLM-in-the-loop synthesis are unaddressed; define data minimization policies, redaction for schema/data prompts, network egress controls, and code provenance scanning when agents use web tools.
- Legal/licensing implications of synthesized code are not discussed; add license compliance checks and provenance tracking to ensure outputs don’t inadvertently replicate restricted training data.
- Reproducibility is fragile given LLM non-determinism and model drift (e.g., Claude Sonnet 4.6); provide deterministic seeds, prompt/version pinning, cached intermediate artifacts, and replayable execution traces.
- Cost accounting is partial (ablation includes $ costs but main results do not); standardize reporting of LLM/API costs, token usage, compilation time, and runtime to compare total cost of ownership with baselines.
- Adaptive model selection policies are unimplemented; design and evaluate controllers that route steps/queries to small vs. large models based on estimated complexity and target confidence.
- Token reduction techniques (compression of schema/queries/messages) are only suggested; measure their accuracy impact and define thresholds where compression degrades code quality.
- Reuse is minimal (only utility functions); build libraries of parameterized, validated operator templates (e.g., cache-adaptive aggregations) and assess reuse benefits across query sets and schemas.
- Lifecycle management of per-query executables is unspecified; design caching, versioning, and eviction policies for generated binaries and derived structures, with dependency tracking on schema/data changes.
- Hybrid deployment with a traditional DBMS is only conceptual; implement a router that selects between GenDB and a baseline DBMS based on estimated amortization, correctness confidence, and SLAs, with failover paths.
- Benchmark fairness and completeness can be improved; include full TPC-H and other benchmarks (e.g., TPC-DS), measure index/materialized view build times, and compare against fully tuned baselines, not just automatic defaults.
- Storage/index build time, memory footprint, and space amplification of generated structures (e.g., nibble-packed lookups, zone maps) are not reported; quantify build cost and runtime overheads under varying data distributions.
- Stability of performance across runs and sensitivity to LLM stochasticity are not analyzed; report variance, worst-case slowdowns, and mechanisms to detect/regress anomalous outputs.
- Governance for code updates (CI/CD of generated code, audit logs, rollback) is not addressed; define deployment pipelines and operational safety checks for production use.
- Extension to semantic/multimodal queries is future work; specify how to jointly optimize runtime cost and quality metrics (e.g., accuracy, recall) for model-in-the-loop operators, with reproducible quality evaluations.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that organizations can implement with the paper’s methods today. Each item includes sectors, potential tools/products/workflows, and key assumptions or dependencies.
- Accelerate recurring analytics queries in data warehouses and lakehouses
- Sectors: Software, Retail, Finance, Media, Telecom
- What: Identify high-frequency SQL (scheduled BI dashboards, ELT jobs, monthly closes), synthesize per-query C++ executables and tailored storage/indexes, then cache and reuse them; route ad-hoc queries to a standard DBMS
- Tools/products/workflows: “Query Accelerator” sidecar for Snowflake/BigQuery/Databricks-lakehouse via external tables/Parquet; Airflow/dbt node that compiles and dispatches executables; per-query binary cache + validation against a reference engine (e.g., DuckDB)
- Assumptions/dependencies: Significant query repetition; stable schemas; build toolchain and sandboxing for native code; governance approval for hybrid architecture; correctness checks against a ground-truth system or manual review for critical workloads
- Cloud cost and energy reduction for analytics
- Sectors: Cloud, Finance, Energy/Sustainability
- What: Replace long-running/expensive OLAP queries with synthesized executables to cut runtime and instance-hours; quantify carbon reduction via fewer CPU-hours
- Tools/products/workflows: “QCaaS” (Query-Compiler-as-a-Service) with cost dashboards; FinOps integration to recommend candidates based on spend; carbon accounting hooks
- Assumptions/dependencies: Reliable cost/telemetry baselines; organizational tolerance for per-query binaries; fallback to baseline DBMS in case of failures
- Automated storage layout and index design for static and semi-static datasets
- Sectors: Software, Media, Public Data Portals
- What: Generate columnar encodings, compression, zone maps/dictionary indexes customized to value distributions and hardware cache hierarchy
- Tools/products/workflows: “Storage Designer” that outputs Parquet/Arrow-with-encodings plus build scripts for auxiliary indexes; one-time migration step in data lakes
- Assumptions/dependencies: Read-heavy workloads; ability to transform data formats; stable data distribution statistics
- Hybrid DBMS deployment for mixed ad-hoc and repeated workloads
- Sectors: Enterprise IT, BI/Analytics
- What: A router that sends one-off queries to the existing engine and frequent queries to synthesized code; automatic identification of repeating patterns
- Tools/products/workflows: Query router + “frequent-query detector”; CI/CD to promote synthesized code from staging to production after validation
- Assumptions/dependencies: Query logging and fingerprinting; operational guardrails (timeouts, rollback); integration with access control/auditing
- Developer productivity and performance engineering in academia and industry
- Sectors: Academia, Software/SRE/DevOps
- What: Rapid prototyping of operator implementations and join orders; auto-generation of realistic microbenchmarks for cache/NUMA stress testing
- Tools/products/workflows: Reproducible harness using the paper’s multi-agent pipeline; structured JSON for inter-agent plans; automated join-order sampling and timing
- Assumptions/dependencies: Access to representative data; hardware performance counters or profilers; safe execution environment for generated code
- BI for non-SQL users via a natural-language interface (with guardrails)
- Sectors: BI/Analytics, Education, SMBs
- What: Add NL-to-SQL with synthesized execution for common dashboards; clearly communicate that NL mode lacks formal correctness guarantees; enforce output validation against small samples or a reference engine where feasible
- Tools/products/workflows: Conversational analytics UI; validation hooks (sample-based, golden queries); opt-in approval for new NL-generated pipelines
- Assumptions/dependencies: Risk management acceptance of weaker guarantees; strong observability and human-in-the-loop approval for promoted jobs
- On-prem/air-gapped analytics in regulated environments
- Sectors: Healthcare, Government, Defense
- What: Use local LLMs or offline prompts to synthesize code and avoid sending sensitive data to external APIs; validate against an on-prem reference DBMS
- Tools/products/workflows: Containerized codegen toolchain; offline model serving; secured build/exec pipeline with SBOM
- Assumptions/dependencies: Adequate local model capability; security reviews for native code execution; performance competitive with baseline systems
- Edge and gateway analytics for simple aggregations and filtering
- Sectors: IoT, Manufacturing, Logistics
- What: Compile small, fixed analytics workloads (e.g., rolling counts, QA metrics) into native binaries for gateways/smart devices to reduce backhaul and latency
- Tools/products/workflows: Cross-compilation pipeline (e.g., ARM/x86); minimal runtime footprint; periodic refresh when data characteristics drift
- Assumptions/dependencies: Stable, simple queries; limited memory/CPU; secure update channels; careful correctness validation without a heavy DBMS
Long-Term Applications
These applications require further research, scaling, or maturation of the approach (robustness, verification, cost control, interoperability).
- Synthesized, zero-knob analytical databases for domain-specific workloads
- Sectors: Software, Enterprise IT
- What: Replace parts of general engines with per-workload codegen pipelines that handle storage, execution, and optimization end-to-end
- Tools/products/workflows: “Self-assembling DB” that emits a binary per query/template plus shared components; multi-query optimization to co-generate shared operators
- Assumptions/dependencies: Strong correctness guarantees; robust failure handling; concurrency/resource isolation; efficient regeneration when schemas evolve
- Unified semantic/multimodal query processing (text, images, audio) alongside relational data
- Sectors: E-commerce (search/reco), Media, Healthcare (imaging), Security
- What: Generate pipelines that call ML/LLM models for semantic predicates (e.g., similarity search, caption filters) with cost-quality trade-offs
- Tools/products/workflows: Python bridges to model inference, prompt/model selection, RAG; caching of embeddings; hybrid operators that mix symbolic and neural logic
- Assumptions/dependencies: Model inference dominates cost; evaluation metrics for “semantic correctness”; privacy/compliance for model use
- GPU-native code synthesis for analytics kernels
- Sectors: Software/Analytics, HPC
- What: Autogenerate CUDA/C++ pipelines that leverage libcudf/RMM and kernel fusion to outperform CPU-based paths on large scans and joins
- Tools/products/workflows: GPU-aware planner; PCIe/NVLink-aware data movement strategies; autotuning of block/grid sizes
- Assumptions/dependencies: GPU availability and ROI; data locality; specialized debugging and profiling support
- SLA-aware, multi-objective optimizers balancing performance, cost, and memory
- Sectors: Cloud Platforms, Managed Data Services
- What: Optimizers that navigate latency SLOs, budget constraints, and memory/disk limits while generating query code
- Tools/products/workflows: Cost models + online telemetry; constrained or multi-objective search; adaptive model selection per query and per pipeline stage
- Assumptions/dependencies: Accurate telemetry; robust, low-cost model orchestration; guardrails for overfitting to transient conditions
- Self-evolving experience stores for cross-query and cross-tenant learning
- Sectors: SaaS Data Platforms, Enterprise IT
- What: Persist and reuse successful patterns (e.g., cache-adaptive aggregation) and anti-patterns; share safely across tenants/domains
- Tools/products/workflows: Experience memory with safety filters; retrieval-augmented prompting for codegen; federated learning across organizations
- Assumptions/dependencies: Privacy isolation; governance for knowledge promotion/demotion; evaluation harnesses to validate reuse
- Formal verification and safety certification for generated query code
- Sectors: Healthcare, Finance, Public Sector (procurement)
- What: Verified-by-construction templates for common query patterns; proof artifacts (e.g., proof-carrying code) for compliance audits
- Tools/products/workflows: Restricted DSLs for safety-critical patterns; SMT-based checks; CI gates that require proofs before deployment
- Assumptions/dependencies: Performance overheads acceptable; limits on expressiveness for verifiable subsets; specialized verification expertise
- Interoperable agent protocols for data systems (MCP/TOON/A2A) and auditability
- Sectors: Software/Standards, Policy
- What: Standardize structured inter-agent communication and tool-use to reduce misalignment and improve reproducibility; comprehensive audit logs
- Tools/products/workflows: Protocol-compliant agents; message schema registries; signed artifacts and SBOM/SLSA compliance for generated code
- Assumptions/dependencies: Community/vendor adoption; governance for protocol evolution; secure key management
- Leakage-resistant benchmarking and procurement practices
- Sectors: Academia, Public Sector, Enterprise Procurement
- What: Suite of “unseen” benchmarks (like SEC-EDGAR) to evaluate LLM-driven systems fairly; guidance for RFPs that test robustness beyond memorized workloads
- Tools/products/workflows: Curated datasets with freshness guarantees; benchmark generators; reporting standards for LLM involvement and prompt budgets
- Assumptions/dependencies: Licensing for datasets; sustained curation; community consensus on fairness criteria
- Serverless “SQL-as-functions” with precompiled, per-query binaries
- Sectors: Cloud, Edge/Mobile, SaaS
- What: Deploy compiled query functions as low-latency serverless endpoints; cache warm binaries for popular analytics
- Tools/products/workflows: Binary artifact registry; cold-start mitigation (provisioned concurrency); per-tenant isolation and sandboxing
- Assumptions/dependencies: Secure native execution in FaaS; packaging constraints; strong observability and throttling
- Carbon-aware query planning and execution via specialization
- Sectors: Energy, Sustainability/ESG, Cloud
- What: Schedule and specialize heavy queries to minimize energy/carbon (e.g., off-peak, green regions) while preserving SLAs
- Tools/products/workflows: Carbon-intensity signals; variant selection (CPU/GPU, kernel fusion, encoding choice) guided by carbon/performance curves
- Assumptions/dependencies: Accurate carbon telemetry; policy/SLAs allowing flexible timing/placement; mature multi-objective optimizers
- Automated data-governance hooks for generated analytics code
- Sectors: Compliance, Enterprise IT
- What: Embed lineage, PII-access checks, and policy enforcement in generated code; generate auditable descriptions of operator choices
- Tools/products/workflows: Policy-as-code injection; lineage capture at operator boundaries; automated documentation of codegen decisions
- Assumptions/dependencies: Up-to-date data catalogs/classifiers; policy engines (e.g., OPA) integration; performance overhead acceptance
These applications leverage the paper’s core innovations—per-query code synthesis, workload/hardware-aware planning, iterative runtime feedback, and agentic decomposition—and translate them into deployable products and roadmaps. Feasibility depends most on the presence of repeat queries, robust correctness validation, secure native execution environments, and clear governance around LLM-assisted generation.
Glossary
- ablation study: A controlled analysis in which components of a system are systematically removed or altered to assess their impact. Example: "an ablation study of GenDB"
- Agent Skills: Predefined tool-use capabilities or modules that can be plugged into agents to extend their functionality. Example: "integrating Agent Skills"
- agentic system: A system composed of autonomous LLM-driven agents that plan, reason, and use tools to complete complex tasks. Example: "GenDB is an LLM-powered agentic system"
- aggregation operator: A database operator that computes summaries over groups of rows (e.g., sums, counts) during query execution. Example: "the aggregation operator adapts its strategy to the hardware cache hierarchy"
- batched-prefetch: A technique that issues memory prefetches in batches to hide latency during repeated probe or scan patterns. Example: "batched-prefetch probe patterns"
- branchless scan: A scan implementation that avoids conditional branches to improve pipeline efficiency and reduce misprediction costs. Example: "a branchless scan"
- cache-adaptive aggregation: Choosing aggregation strategies based on cache sizes and group counts to keep state in the fastest cache levels. Example: "cache-adaptive aggregation"
- cache-thrashing: Performance degradation caused by frequent cache evictions when working sets exceed cache capacity or conflict heavily. Example: "cache-thrashing hash aggregation"
- columnar storage: A storage layout that organizes data by columns rather than rows to improve compression and analytical scan performance. Example: "columnar storage with encoding and compression"
- compare-and-swap (CAS): An atomic instruction that conditionally updates a memory location if it matches an expected value, enabling lock-free synchronization. Example: "lock-free compare-and-swap (CAS)"
- constrained optimization: Optimization under explicit limits or requirements on resources or performance metrics. Example: "constrained optimization"
- false sharing: Cache-line contention that occurs when multiple threads update different variables that reside on the same cache line. Example: "to prevent false sharing"
- GPU-native analytical processing: Query processing techniques and systems designed to run directly and efficiently on GPUs. Example: "GPU-native analytical processing"
- hot runs: Performance measurements taken after data and code are warmed in caches/buffers, reflecting steady-state execution. Example: "hot runs"
- index-aware sequential scan: A scan strategy that leverages index properties or layout to make sequential access more efficient. Example: "index-aware sequential scan"
- join orders: The sequence in which tables are joined in a multi-table query, which can significantly affect performance. Example: "candidate join orders"
- L1 cache: The smallest and fastest CPU cache close to each core, used to minimize memory access latency. Example: "fits entirely in L1 cache"
- LIKE filter: A SQL predicate that performs pattern matching on strings using the LIKE operator. Example: "a five-way join with a LIKE filter"
- load factor: The fraction of a hash table’s capacity that is occupied, influencing collision rates and probe length. Example: "let the load factor approach 100%"
- mmap: A POSIX system call that maps files or devices into memory for efficient I/O. Example: "mmap"
- Model Context Protocol (MCP): A protocol for standardizing tool and context integration with agentic or LLM systems. Example: "Model Context Protocol (MCP)"
- multi-objective optimization: Simultaneously optimizing multiple objectives (e.g., speed and cost), often requiring trade-offs. Example: "multi-objective optimization"
- multi-query optimization: Planning or generating code to share work or structures across multiple queries to reduce total cost. Example: "multi-query optimization"
- nibble-packed: A compact representation that packs values into 4-bit units to reduce memory footprint. Example: "nibble-packed lookup files"
- OLAP: Online Analytical Processing; workloads focused on large-scale analytical queries over historical data. Example: "OLAP workloads"
- OLTP: Online Transaction Processing; workloads emphasizing many concurrent, short, transactional operations. Example: "OLTP"
- open addressing: A collision resolution technique for hash tables where probing continues within the table to find an empty slot. Example: "open addressing"
- OpenMP: A parallel programming model for shared-memory multiprocessing, providing compiler directives for threading. Example: "OpenMP parallel region"
- parametric knowledge: Knowledge stored within the parameters of a trained model rather than in an external database. Example: "the LLM's parametric knowledge"
- scale factor: A benchmark parameter specifying dataset size relative to a baseline. Example: "scale factor 10"
- semantic query processing: Query processing that incorporates meaning and ML/LLM-driven semantics over unstructured or multimodal data. Example: "semantic query processing"
- Service Level Agreement (SLA): A formal commitment specifying performance or reliability guarantees. Example: "Service Level Agreement (SLA)"
- SIMD: Single Instruction, Multiple Data; CPU instructions that apply the same operation to multiple data elements in parallel. Example: "SIMD support"
- TOON: A communication or compression approach used to make LLM/agent messaging more efficient. Example: "TOON"
- TPC-H: A standard decision support benchmark for evaluating analytic database performance. Example: "TPC-H"
- vector embedding: A numerical representation of objects (e.g., text, images) in a vector space for similarity search or ML operations. Example: "vector embedding"
- workload-specific derived data structures: Auxiliary structures created for a particular workload to accelerate queries. Example: "workload-specific derived data structures"
- zone-map pruning: Skipping data ranges during scans using per-block min/max metadata to avoid unnecessary reads. Example: "zone-map pruning"
Collections
Sign up for free to add this paper to one or more collections.

