- The paper introduces an autonomous synthesis pipeline that generates workload-specific OLAP engines to eliminate the overhead of general-purpose systems.
- It employs incremental stages including storage planning, code generation, and iterative optimization to achieve drastic performance improvements.
- Experimental results demonstrate up to 11.78× speedup on TPC-H benchmarks, underscoring the cost-efficient benefits of targeted specialization.
Bespoke OLAP: Synthesizing Workload-Specific Database Engines
Motivation and Problem Statement
General-purpose OLAP engines incur unavoidable performance losses due to structural overhead—schema interpretation, abstraction layers, generic data structures—that are mandated by their flexibility to support arbitrary workloads. Although specialized systems already outperform traditional row-stores by optimizing for OLAP workload classes, these systems still implement a refined “one-size-fits-all” paradigm. The performance overhead persists even in state-of-the-art engines such as DuckDB and HyPer. In practice, many enterprise OLAP deployments involve stable, repetitive workloads where maximum flexibility is almost never exercised, yet its cost is paid continuously.
Historically, constructing bespoke, workload-specialized OLAP engines has been economically infeasible due to the prohibitive manual engineering effort required. System-level design decisions—storage layout, indexing, execution logic—are deeply interdependent and require years of expert engineering. As a consequence, organizations tolerate significant performance loss for practicality, and systems are optimized for generality rather than specificity.
Recent advances in LLM-based code synthesis have changed this tradeoff, enabling automated, cost-efficient generation of non-trivial system software. However, naively prompting LLMs does not produce correct or efficiently optimized database systems due to the need for systematic performance feedback, architectural validation, and incremental refinement.
Synthesis Pipeline Design
The Bespoke OLAP framework introduces a fully autonomous agent-based synthesis pipeline that produces workload-specific OLAP engines without human intervention. The process is guided by a DBMS “contract,” which specifies:
- Database schema and query templates (with parameterization ranges)
- Dataset (provided as Parquet files)
This contract bounds the scope of synthesis, enabling aggressive specialization and eliminating abstractions required only by generic workloads.
The pipeline operates through incremental stages:
- Storage Layout Planning: Before any execution code is written, the agent inspects the dataset and workload specification, determining optimal physical organization—sort orders, encodings, and auxiliary structures—based on observed access patterns and predicate columns. Storage planning is committed as a foundation to localize complexity.
- Storage and Ingestion Code Generation: C++ structs, ingestion code, and any auxiliary structures are synthesized to materialize the workload-optimized storage layout.
- Correctness First Query Implementation: Execution logic for each query template is generated and strictly validated against DuckDB results for a wide range of parameter instantiations. This establishes a correctness baseline.
- Optimization Loop: The agent executes a four-stage empirical optimization process:
- Cardinality-guided operator selection and join ordering
- Self-profiling with agent-injected tracing and bottleneck identification
- Application of distilled expert knowledge (e.g., cache-aware access, SIMD, branch minimization)
- Holistic review with a human reference persona to exploit aggressive low-level optimizations and cross-query opportunities
Changes are tested via hotpatching for rapid feedback, rollback on performance regressions, and snapshot-based versioning for reproducibility and monotonic progress.
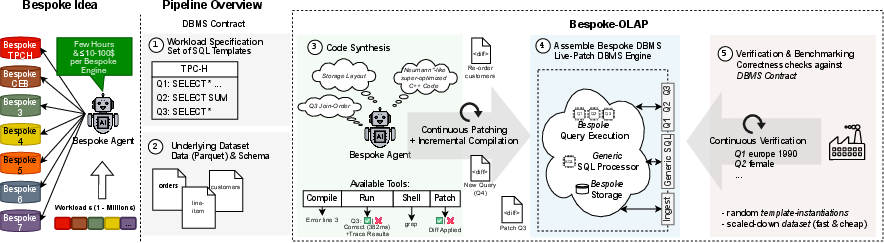
Figure 1: Overview of Bespoke OLAP synthesis: engine generation per workload, with pipeline stages grounded in DBMS contract specification and benchmarking/validation feedback.
Infrastructure and Conversation Management
A dedicated infrastructure underpins the agent-driven synthesis loop:
- Hotpatching: Components are incrementally recompiled and swapped into the running process, preserving state and in-memory storage across iterations. This enables rapid testing without full restarts.
- Fuzzy Testing & Benchmarking: Correctness is validated for query templates across diverse parameter instantiations, preventing overfitting to single cases and ensuring generalizability, all benchmarked against DuckDB.
- External Regression Tracking and Rollback: An external monitor ensures monotonic optimization—regressions are detected and reverted automatically.
- Snapshot Versioning: All code and process states are tracked and can be replayed or modified for recovery or prompt engineering.
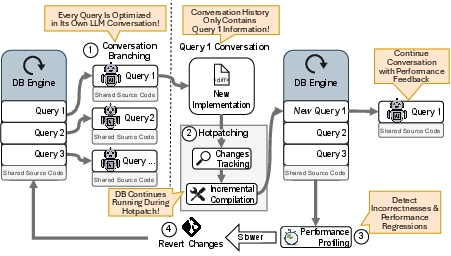
Figure 2: Infrastructure supporting LLM-driven synthesis, highlighting hotpatching, per-query agent branching, validation, and regression tracking for rapid, correct, recoverable development.
Experimental Evaluation
Workloads and Metrics
The Bespoke OLAP pipeline was evaluated on TPC-H (SF=20) and CEB (SF=2), benchmarks with established industrial relevance. Engines were synthesized autonomously for each workload and compared against DuckDB (v1.1.4), both running single-threaded, in-memory, pinned to equivalent hardware.
Numerical Results
Strong empirical findings:
- Overall speedups: Bespoke-TPCH completed TPC-H in 4.6 seconds (DuckDB: 54.4s), achieving a speedup of 11.78×. Bespoke-CEB completed CEB in 2.3 seconds (DuckDB: 22.1s), corresponding to 9.76× speedup.
- Per-query speedups: Every query in both benchmarks outperformed DuckDB, with per-query speedups ranging from 13× to 104× (TPC-H) and 1.5× to 1466× (CEB).
- Scalability: Speedups persisted as data sizes increased; on TPC-H, speedups remained stable at 10–12× across scale factors. On CEB, the gap grew with scale due to algorithmic and storage layout advantages.
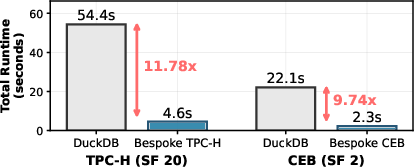
Figure 3: Synthesized Bespoke engines exceed the performance of a decade of engineering, achieving 11.78× and 9.76× lower total runtime and 16.40× and 4.66× median per-query speedups on TPC-H and CEB, respectively.
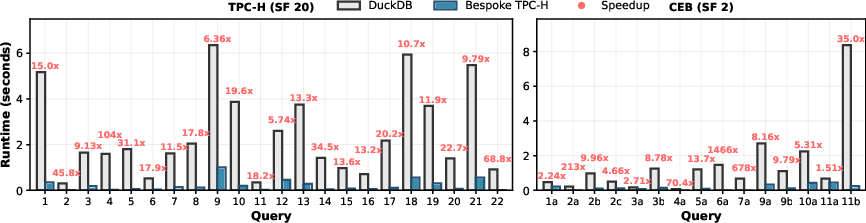
Figure 4: Per-query runtimes for TPC-H (SF=20) and CEB (SF=2), showing consistent outperformance of DuckDB by Bespoke-TPCH/CEB for every query.
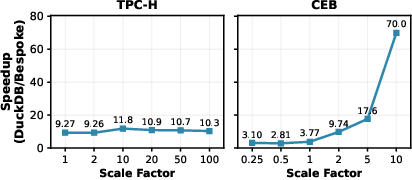
Figure 5: Speedups over DuckDB at different scale factors; Bespoke-OLAP maintains stable speedups on TPC-H and achieves dramatically increasing speedups on CEB as data size grows.
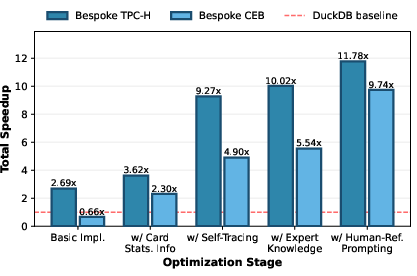
Optimization Ablation
Decomposition shows every optimization stage contributes:
Analysis of Code and Strategies
Comprehensive code analysis reveals:
- Systematic application of workload-specific strategies: dictionary encoding, physical sort orders, bitmap semi-joins, fused aggregation, and pointer aliasing hints.
- Classical and exotic strategies are chosen per query and per column, optimized for actual data distributions and access patterns rather than generic case handling.
- Cross-layer optimization—storage, execution, low-level hardware hints—is enabled only by the bounded scope of the workload contract.
Synthesis Process Insights
- Rapid synthesis: Entire engines generated in 6–12 hours, API costs under $125, with zero manual intervention.
- High correctness: Most queries correct in the first synthesis attempt, rare regressions are quickly detected and rolled back.
- Deliberate tool usage: The agent employs search/filtering tools rather than loading full context, exploiting limited token budgets efficiently.
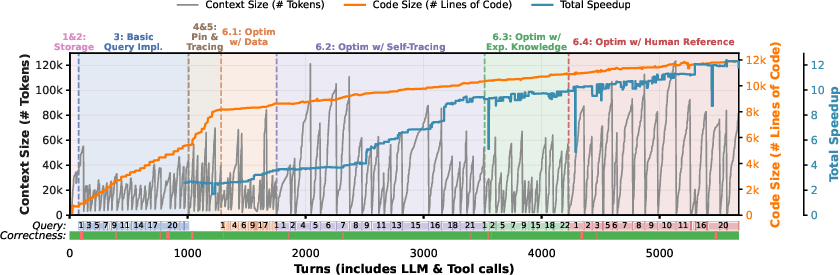
Figure 7: Development timeline of Bespoke-TPCH synthesis, tracking context and code growth over agent turns, correctness status per query, and compaction stages for context management.
Practical and Theoretical Implications
Practical implications:
Workload-specialized engines, historically out of reach, can be synthesized at low marginal cost for specific deployments, making “one-size-fits-one” DBMS architectures routinely viable. This alters the economics of OLAP system deployment—bespoke engines can be produced per workload and per update cycle (e.g., nightly batch ingestion).
Theoretical implications:
The results reveal that a significant fraction of performance overhead in modern analytical engines arises not from incremental implementation choices, but fundamentally from their general-purpose design paradigm. Aggressive specialization—removal of abstraction layers, tailored data layouts, hyper-optimized execution paths—substantially lowers complexity and achieves algorithmically superior scaling in real benchmarks.
Resynthesis is routine for changing workloads, and ad-hoc query support can be handled via fallback paths that do not degrade engine performance for contract-bound queries.
Future Directions
Unanswered questions include synthesizing disk-resident engines (bespoke file formats, access paths), supporting multi-threaded execution (parallelism, synchronization, NUMA optimizations), and extending beyond OLAP to OLTP workloads. Incorporating lightweight cost modeling into the pipeline could further improve synthesis efficiency. Scaling agent synthesis to complex concurrent code and reasoning about consistency and isolation are open challenges.
Conclusion
Bespoke OLAP introduces an autonomous pipeline for workload-specific database engine synthesis, systematically eliminating generality overhead and achieving order-of-magnitude speedups over highly optimized general-purpose systems across industrial benchmarks. The approach demonstrates that LLM-driven system synthesis, grounded in structured validation and empirical optimization, fundamentally changes the deployment paradigm of analytical DBMSs, making bespoke specialization practical and routine for real-world workloads. This work opens new directions for revisiting database system architecture design, cost modeling, and deployment workflows in the era of agentic software synthesis.