- The paper proposes Booster, a framework that leverages LLMs and prior query-level history to accelerate automatic database tuning.
- It extracts QConfigs from historical artifacts, enriches LLM prompts, and composes candidate configurations via beam search for improved performance.
- Empirical results demonstrate up to 74% improvement and 3.6–4.7× faster convergence compared to retraining from scratch.
Booster: Leveraging LLMs and Query-Level History for Accelerated Automatic Database Tuning
Introduction and Motivation
The paper introduces Booster, a framework designed to enhance the adaptivity of automatic database tuning algorithms by leveraging prior query-level history and LLMs. The motivation stems from the limitations of existing tuners—cost-based, ML-based, and LLM-based—which struggle to efficiently adapt to environment changes such as workload drift, schema transfer, hardware upgrades, and dataset growth. These tuners typically operate at the workload granularity, lack mechanisms to exploit historical query-level insights, and are often rigid or brittle when faced with new scenarios. Booster addresses these deficiencies by structuring historical artifacts into query-configuration contexts (QConfigs), using LLMs to suggest per-query configurations, and composing these into holistic configurations via beam search.
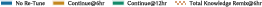
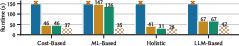
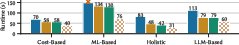
Figure 1: Transfer scenario from TPC-H to DSB, illustrating the performance gap between continuing from history and total knowledge remix via Booster.
Booster Framework Architecture
Booster operates in three distinct phases:
- Experience Analysis: Historical tuning artifacts are parsed into QConfigs, which encapsulate query semantics, configuration details, and performance metrics. These are embedded into fixed-length vectors using state-of-the-art embedders and stored in a vector database for efficient retrieval.
- Guided Recommendation: For each query in the target workload, Booster retrieves relevant QConfigs based on semantic similarity, enriches LLM prompts with these references, and generates candidate configurations (seeds). A sanitizer module ensures validity and diversity of these seeds by permuting query knobs and repairing plans.
- Constrained Composition: Booster ranks seeds by executing them or estimating their quality, then composes them into holistic configurations using a beam search algorithm. This process resolves conflicts in system knobs and physical design structures, iteratively refining the configuration to maximize workload performance.
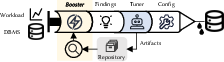
Figure 2: Booster overview, showing integration with existing tuners and the flow from artifact analysis to configuration injection.
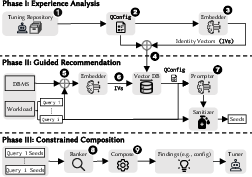
Figure 3: Booster architecture, detailing the three-phase pipeline from artifact mining to composition and injection.
Implementation Details
QConfig Construction and Embedding
QConfigs are constructed from historical artifacts by extracting query text, execution plans, configuration parameters, and performance outcomes. Multiple schematics (e.g., anonymized SQL, query plan, schema) are generated per QConfig and embedded using models such as Voyage 3 Large. These embeddings facilitate efficient similarity search and retrieval during adaptation.
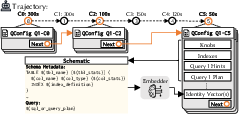
Figure 4: QConfig construction, showing linkage between configurations and embedding generation for semantic search.
Prompt Augmentation and LLM Query Adaptation
Booster augments LLM prompts with the top-k most relevant QConfigs for each query, enabling the LLM to reason over historical context and generate more effective configurations. The sanitizer module further diversifies seeds by permuting query knobs (join types, access methods, sorting) and repairing plans to match historical performance.
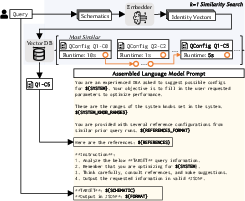
Figure 5: Prompt augmentation with k=1 relevant QConfig, illustrating the enrichment of LLM input for improved configuration suggestions.
Composition and Beam Search
Seeds are ranked by executing them with alternate indexes to estimate performance. The beam search algorithm merges seeds into holistic configurations, resolves conflicts, and iteratively refines the solution by rolling out alternate seeds for degraded queries. The rollout policy includes query knob permutation, plan repair, hidden index exploration, and ranked seed selection.


Figure 6: Query knob permutation strategy, demonstrating the impact of diverse knob settings on configuration quality.
Figure 7: Search time sensitivity, showing diminishing returns with increased composition time.
Experimental Evaluation
Booster was evaluated on PostgreSQL v15.1 using OLAP workloads (JOB, TPC-H, DSB) and compared against state-of-the-art tuners: PGTune+DTA+AutoSteer, UniTune, Proto-X, and LambdaTune+AutoSteer. Key scenarios included exact transfer, parameter drift, template drift, machine transfer, dataset growth, and cross-schema transfer.
- Exact Transfer: Booster enabled tuners to find configurations with mean improvements of 16–51% (Proto-X), 22–40% (DTA), 49–62% (UniTune), and 34–50% (LambdaTune+AutoSteer) over tuning from scratch.
- Parameter Drift: Booster achieved 23–64% improvement and up to 3.6× faster convergence.
- Template Drift: Booster delivered 12–63% improvement and up to 4.7× faster adaptation.
- Machine Transfer and Dataset Growth: Booster consistently outperformed historical tuning, with improvements up to 62% and faster convergence.
- Cross-Schema Transfer: Booster enabled transfer of query-level insights across different schemas, yielding up to 74% improvement.

Figure 8: Dataset growth sensitivity, highlighting the impact of historical scale factor on adaptation quality.


Figure 9: Embedder-prompter model sensitivity, showing the effect of model choice on configuration performance.
Trade-offs and Limitations
Booster's efficacy depends on the quality and diversity of historical artifacts, the choice of embedder and prompter LLM, and the granularity of query knob permutations. While enriching prompts with historical QConfigs outperforms fine-tuning alone, the approach incurs additional inference costs and may be limited by LLM context window size. The framework is tuner-agnostic but requires integration via API commands (Parse, Link, Digest) to reconcile differences in artifact formats and tunable granularity.
Implications and Future Directions
Booster demonstrates that query-level adaptation using LLMs and historical artifacts can significantly accelerate and improve automatic database tuning across diverse scenarios. The framework's modularity allows integration with existing tuners, extending their adaptivity and breaking out of local optima. Future research may focus on optimizing embedder/prompter selection for generalizability and cost, developing tuners with explicit generalizability objectives, and refining prompt enrichment strategies based on query diversity.
Conclusion
Booster advances the state of automatic database tuning by leveraging LLMs and structured query-level history to assist tuners in adapting to environment changes. By organizing historical artifacts, enriching LLM prompts, and composing configurations via beam search, Booster enables tuners to discover superior configurations more rapidly than retraining from scratch. The framework's empirical results substantiate its effectiveness, with up to 74% performance improvement and 4.7× faster convergence across a range of adaptation scenarios. Booster sets a new direction for adaptive, history-aware database tuning systems.