- The paper demonstrates that LLMs and agentic systems can automatically synthesize and optimize high-performance compute kernels.
- The methodology combines supervised fine-tuning, reinforcement learning, and hardware profiling to achieve near-peak hardware efficiency.
- The study highlights challenges such as data scarcity and evaluation generalization while proposing scalable, agent-driven workflows.
Towards Automated Kernel Generation in the Era of LLMs
Introduction
The paper "Towards Automated Kernel Generation in the Era of LLMs" (2601.15727) provides a comprehensive synthesis of the rapidly evolving field wherein LLMs and agentic systems are repurposed for the automatic synthesis and optimization of high-performance compute kernels. The central motivation is rooted in the observation that the efficiency and cost-effectiveness of LLM-centric AI infrastructure is increasingly bottlenecked not by hardware peak capacities, but by the quality and adaptability of operator kernels underpinning core workload primitives (e.g., matrix multiplication, attention). Traditional kernel engineering is domain-expertise-intensive, non-scalable, and hardware-coupled, posing significant barriers to progress as the diversity and complexity of hardware accelerators increase.
In response, the surveyed body of research leverages LLMs' ability to encode both explicit and tacit programming knowledge, as well as the iterative, feedback-driven optimization affordances of agentic approaches. The review positions itself as the first systematic survey of LLM-driven kernel code generation, offering taxonomies of methods, annotated corpora and knowledge bases, modern benchmarks, and an exposition of technical bottlenecks and future directions.
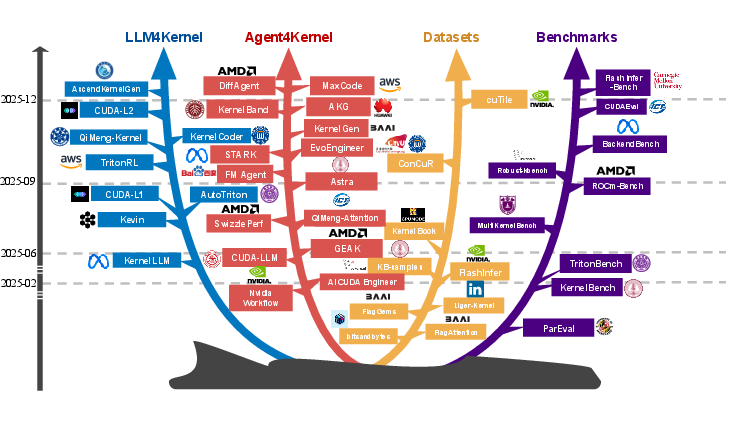
Figure 1: The chronological and domain-based evolution of research in LLM-driven kernel generation illustrates the sharp increase and diversification in methodologies and application domains.
Foundations: LLMs, Agents, and Kernel Programming
The basis for LLM-driven kernel synthesis is rooted in the Transformer architecture, where LLMs are trained on vast corpora to learn probabilistic next-token prediction and, by extension, domain reasoning and system knowledge. Autonomous agent frameworks extend LLMs with capabilities for planning, persistent memory, and interaction with external environments, thus realizing closed-loop workflows that can adaptively optimize code through iterative, feedback-based cycles.
Unlike standard code generation, kernel synthesis imposes dual requirements of semantic-correct hardware mapping and near-peak hardware efficiency. This positions kernel generation more closely with program synthesis and compiler optimization than with classical software engineering, necessitating purpose-designed datasets, reward signals, and benchmark protocols.
Methodological Advances in LLM-Driven Kernel Generation
Post-Training LLM Specialization
Supervised fine-tuning has emerged as a primary technique for aligning LLMs with the specifics of kernel code generation. Efforts such as KernelCoder, based on the ConCuR dataset, demonstrate that reasoning-centric instruction tuning (with attention to concise logic, empirical speedup, and task diversity) directs LLMs towards robust CUDA synthesis with high success rates. Compiler-aligned corpora, such as in KernelLLM, harness automatic translation of operator behavior to kernel structure, emphasizing the importance of paired high-level intent and low-level implementation training signals.
Reinforcement learning (RL) further augments post-training alignment. Notable approaches such as Kevin, QiMeng-Kernel, AutoTriton, TritonRL, and CUDA-L1/CUDA-L2 deploy RL with long-horizon credit assignment, hierarchical reward decompositions, and LLM-as-judge frameworks to bridge gaps in reward sparsity and verification. These works demonstrate that reward attribution over both structural and empirical code evaluation—fused with preference learning—can yield models matching or surpassing highly-optimized baseline libraries such as cuBLAS.
Agentic Kernel Synthesis Workflows
LLM-based agents introduce autonomy and adaptivity, orchestrating workflows that continuously refine, rewrite, and validate kernels via feedback from both simulation and real hardware execution. The paper organizes agentic innovations into four axes:
- Learning Mechanisms: Progression from single-shot generation to iterative search, population-based evolution, and max-reward RL (e.g., MaxCode, FM Agent, EvoEngineer). Methods leverage critique and diagnostic feedback, supporting “escape” from local optima and accelerating convergence.
- External Memory Management: Augmenting LLMs with retrieval-augmented generation (RAG) over curated codebases or structured reasoning graphs to ground kernel generation in canonical low-level API usage and hardware-specific insights (e.g., AI CUDA Engineer, KernelEvolve, ReGraphT).
- Hardware Profiling Integration: Systematic injection of hardware meta-data and dynamic profiling (e.g., runtime performance, cache statistics) enables prompt adaptation and specialized tuning. Agents such as CUDA-LLM, TritonForge, SwizzlePerf, and KERNELBAND couple prompt engineering with profiling-feedback loops to drive hardware-aware code synthesis.
- Multi-Agent Orchestration: Modular agent teams partition kernel tasks into functional roles (planning, coding, debugging, evaluation), facilitating cross-platform generalization and division of labor (e.g., STARK, AKG, Astra, CudaForge, KernelFalcon, GEAK).
Data, Benchmarks, and Systematic Resources
The survey systematically catalogues datasets, open-source repositories, and domain knowledge bases that underwrite progress in LLM-driven kernel generation. Structured training corpora (e.g., The Stack v2, HPC-Instruct, KernelBook, KernelBench samples) and highly optimized operator libraries (e.g., CUTLASS, FlashAttention, FlagAttention, FlagGems) provide critical supervision, while community-maintained guides and benchmarks (e.g., Awesome-CUDA, BackendBench, FlashInfer-Bench) are indispensable for scaling learning and robust evaluation.
Benchmarking has advanced substantially: from early correctness and speedup metrics (ParEval, KernelBench) towards comprehensive evaluations on real-world, cross-platform traces emphasizing efficiency, functional robustness, and generalizability (e.g., MultiKernel-Bench, TritonBench-revised, BackendBench, Robust-kbench, FlashInfer-Bench). The adoption of metrics such as pass@k, speedup@k, efficiency@k, and task-specific composite measures (e.g., fastp) provides a nuanced, repeatable basis for comparative assessment.
Outstanding Challenges and Future Directions
The review identifies several persistent challenges and outlines corresponding research opportunities:
- Data Scarcity and Synthetic Generation: The paucity of representative, trajectory-rich, and hardware-diverse kernel datasets limits both pretraining and fine-tuning. Future progress will require systematic construction, large-scale synthesis, and logging of kernel optimization processes to expand the coverage and granularity of supervision.
- Agent Autonomy, Reasoning, and Reliability: There is a critical need to transition agentic methods from rigid, hand-crafted workflows to self-directed planning augmented by dynamic memory, formalized knowledge bases, and rigorous engineering standards, including provable correctness and formal verification where feasible.
- Scalable Infrastructure: The latency imbalance between model inference and environment-driven empirical evaluation (compilation, profiling) constrains throughput and learning efficiency. There is a demand for standardized, distributed "gym-like" environments capable of asynchronous, scalable kernel synthesis and evaluation.
- Evaluation Generalization: Most benchmarks and protocols are limited to NVIDIA-centric, forward-pass primitives with static shapes. Robust assessments must expand across input distributions, hardware backends, and exploit functional and performance edge cases.
- Human-AI Interaction: Exploiting mixed-initiative and explainable AI—where domain experts provide high-level constraints and rationale, and agents conduct iterative implementation and tuning—remains underexplored and vital for scaling kernel engineering.
Conclusion
This survey provides a consolidated and authoritative reference for the state of LLM-driven kernel generation, covering algorithmic innovations, agentic workflows, dataset and benchmark resources, as well as critical research bottlenecks. The field is coalescing around workflows that integrate LLMs, agent autonomy, externalized domain knowledge, and empirical feedback. Future systems must address data scarcity and scalability to sustainably automate kernel optimization as AI infrastructure continues to scale. The development of robust, explainable, and generalizable agentic systems for code synthesis not only promises to alleviate the expert-heavy burdens of kernel engineering but also establishes a blueprint for similar automation in other high-performance, hardware-coupled domains.

