- The paper identifies agentic speculation as a dominant workload and empirically demonstrates its potential to improve task success rates by 14–70%.
- The paper proposes an agent-first data system architecture featuring novel probes, an agentic interpreter, and a persistent memory store to optimize query execution.
- The paper outlines key challenges in scaling, redundancy exploitation, and ensuring security in shared agentic memory, driving future multi-agent system research.
Redesigning Data Systems for Agentic Workloads: An Expert Analysis
Introduction
The paper "Supporting Our AI Overlords: Redesigning Data Systems to be Agent-First" (2509.00997) presents a comprehensive research agenda for rearchitecting data systems to natively support agentic workloads driven by LLM agents. The authors identify agentic speculation—a high-throughput, exploratory querying paradigm—as the dominant future workload for data systems, and argue that current architectures are fundamentally misaligned with the requirements of LLM agents. The work systematically analyzes the characteristics of agentic workloads, provides empirical evidence for their scale, redundancy, heterogeneity, and steerability, and proposes a novel agent-first data system architecture with new abstractions and optimization strategies.
Characterization of Agentic Workloads
Agentic speculation is defined as the process by which LLM agents, acting on behalf of users, issue large volumes of exploratory and solution-formulating queries to backend data systems. The paper identifies four key properties:
- Scale: Agents can issue hundreds to thousands of requests per second, far exceeding human-driven workloads.
- Heterogeneity: Requests span metadata exploration, partial solution attempts, and validation, with overlapping phases.
- Redundancy: Many queries are similar or overlapping, enabling opportunities for computation sharing.
- Steerability: Agents can be guided via grounding hints and feedback, reducing inefficiency.
Empirical studies on the BIRD text2SQL benchmark demonstrate that increasing the number of agentic requests—either in parallel or sequentially—substantially improves task success rates, with observed gains of 14–70%.
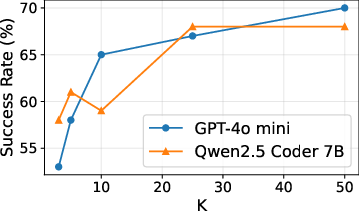
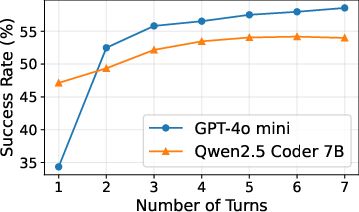
Figure 1: Success@K curves on the BIRD dataset, showing accuracy improvements as the number of agentic attempts increases.
Analysis of subexpression redundancy across agentic queries reveals that the number of unique sub-plans is often less than 10–20% of the total, indicating significant potential for multi-query optimization and result caching.
Phases of Agentic Speculation
A detailed trace analysis of LLM agents performing multi-database tasks reveals that agentic activity is not strictly sequential; metadata exploration, statistics gathering, and query formulation phases overlap and recur throughout the agent's interaction.
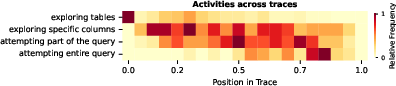
Figure 2: Heatmap of labeled agent activities, showing normalized trace positions and overlapping phases of exploration and query formulation.
The injection of grounding hints—metadata or schema information—into agent prompts reduces the number of required queries by over 20%, demonstrating the steerability of agentic workloads and the value of proactive system feedback.
Agent-First Data System Architecture
The proposed architecture introduces several new abstractions:
- Probes: Generalized requests from agents that go beyond SQL, including natural language briefs specifying goals, phases, and approximation needs.
- Agentic Interpreter: In-database agent that parses and interprets probes, leveraging semantic understanding to optimize execution.
- Probe Optimizer: Component that satisfices agentic requests, balancing accuracy and computational cost, and exploiting redundancy.
- Agentic Memory Store: Persistent, queryable cache of grounding information, partial solutions, and metadata, supporting semantic search and efficient reuse.
- Shared Transaction Manager: Mechanism for efficient state sharing and isolation across speculative branches, supporting massive parallel forking and rollbacks.
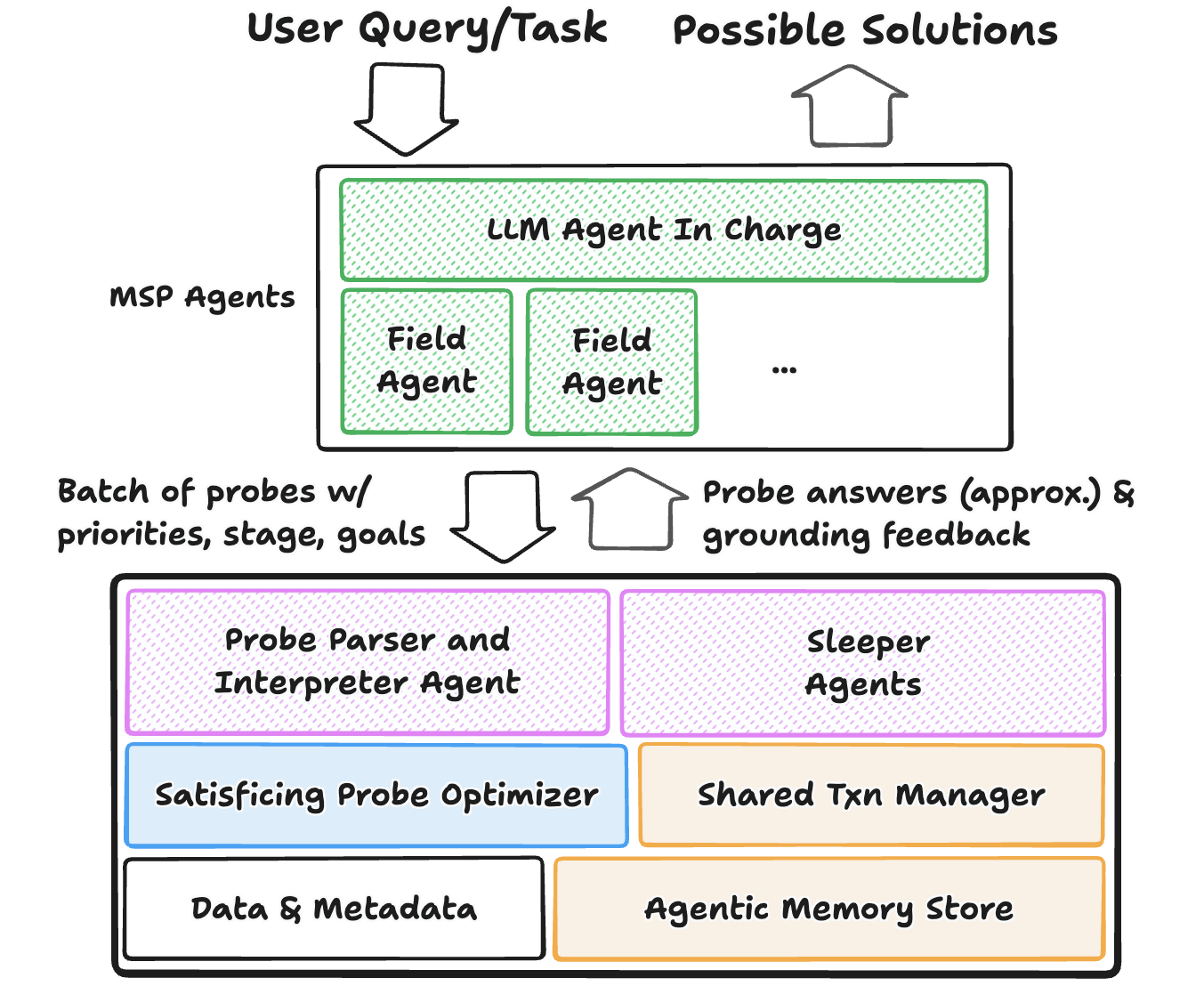
Figure 3: Agent-First Data Systems Architecture, highlighting new components for probe interpretation, optimization, and agentic memory.
Query Interface Innovations
The paper advocates for interfaces that allow agents to specify not only queries but also background information, intent, and approximation requirements. Probes may include natural language briefs, semantic similarity operators, and open-ended goals. The system is expected to interpret these briefs to guide query planning, execution order, and degree of approximation.
On the output side, the system should proactively provide auxiliary information (e.g., related tables, cost estimates, provenance feedback) to steer agents toward more efficient exploration and solution formulation. Sleeper agents within the database can be invoked to gather and return such information in parallel with probe answers.
Probe Processing and Optimization
The probe optimizer must orchestrate both NL and SQL queries, prioritize based on agentic phase, and leverage agentic memory to avoid redundant work. Optimization objectives shift from maximizing throughput to minimizing total agent decision time, balancing cost and accuracy across batches of probes.
- Intra-Probe Optimization: Prune semantically irrelevant queries, prioritize based on information gain and cost, and incrementally evaluate queries with termination criteria.
- Inter-Probe Optimization: Leverage sequential agent interactions to avoid redundant computation, materialize and cache answers based on anticipated future probes, and adapt execution strategies dynamically.
Multi-query optimization, approximate query processing, and incremental evaluation are central, but must be extended to handle heterogeneous approximation requirements and agent-driven termination criteria.
Storage, Indexing, and Transactional Challenges
Agentic workloads challenge the static and independent assumptions of traditional storage engines. The agentic memory store acts as a semantic cache, storing probe results, metadata, and grounding information for efficient reuse and semantic search. Maintaining consistency, privacy, and access control in this store is nontrivial, especially as agents acting on behalf of different users may benefit from shared knowledge.
Transactional support must enable efficient forking and rollback of speculative branches, with logical isolation but physical sharing of near-identical state. Existing copy-on-write and MVCC techniques are insufficient for the scale and frequency of agentic speculation; new concurrency control and recovery mechanisms are required.
Implications and Future Directions
The agent-first paradigm necessitates a fundamental rethinking of data system architecture, interfaces, and optimization strategies. Practical implications include:
- Scalability: Systems must handle orders-of-magnitude higher request rates and speculative branches.
- Efficiency: Redundancy and steerability must be exploited to minimize computational cost and agent decision latency.
- Security and Privacy: Shared agentic memory raises new challenges for access control and information leakage.
- Interoperability: Flexible probe interfaces and semantic search capabilities are required to support heterogeneous agentic tasks.
Theoretically, the work opens new research directions in multi-agent, multi-version isolation, semantic query optimization, and agent-system co-design. Future developments may include standardized probe languages, agentic memory protocols, and adaptive optimization frameworks that learn from agent interactions.
Conclusion
This paper provides a rigorous analysis and forward-looking vision for agent-first data systems, grounded in empirical evidence and architectural innovation. By identifying the unique characteristics of agentic speculation and proposing concrete system abstractions, the work lays a foundation for the next generation of data systems optimized for LLM-driven workloads. The challenges outlined—scalability, efficiency, privacy, and semantic interoperability—will drive future research in both systems and AI, with broad implications for the deployment of autonomous agents in data-centric environments.

