- The paper presents a memory-driven self-improvement framework that combines LLMs with a memory system to enhance sequential decision-making.
- It employs memory-driven value estimation by retrieving and updating Q-values from state-action pairs to refine decision policies.
- Experimental results demonstrate over 40% improvement in in-distribution tasks and 75% in generalized tasks, boosting sample efficiency.
Memory-Driven Self-Improvement for Decision Making with LLMs
The paper "Memory-Driven Self-Improvement for Decision Making with LLMs" presents a framework that integrates LLMs with memory-driven strategies to enhance sequential decision-making tasks. This approach addresses the limitations of LLMs in adapting to specialized domains by augmenting their general knowledge with domain-specific experiences.
Introduction
Sequential decision-making (SDM) in fields like robotics and human-AI interaction often involves complex strategies that require more than just broad knowledge. While LLMs offer valuable zero-shot reasoning capabilities, they often struggle with domain-specific decision-making due to limited task-related data. To overcome this, the authors propose a memory-driven self-improvement framework that combines the generalized knowledge of LLMs with a memory system that retains domain-specific interactions and Q-values.
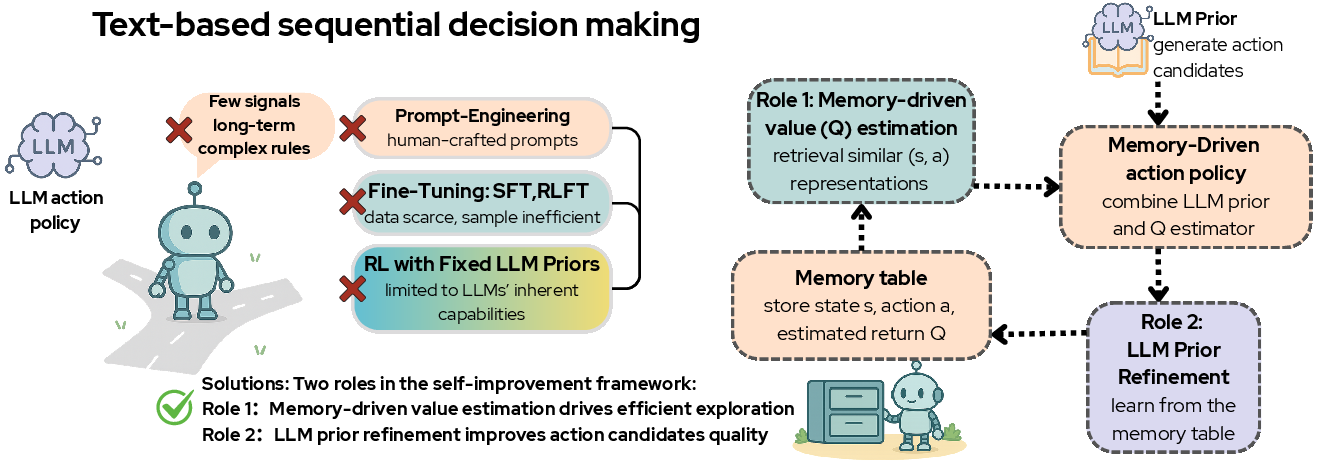
Figure 1: The framework involves memory-driven value estimation and LLM prior refinement, which mutually reinforce each other, forming a closed-loop system.
Proposed Framework
Memory-Driven Value Estimation
This component utilizes the semantic representation power of LLMs to estimate Q-values via retrieval techniques, thus facilitating non-parametric value estimation. The memory system stores historical state-action pairs and updates Q-values based on the most recent interactions, enhancing decision accuracy through informed exploration choices.
Memory-Driven LLM Prior Refinement
This mechanism periodically updates the LLM's decision-making policy by leveraging high-value trajectories stored in memory. Such refinement aims to bias the LLM towards generating high-quality actions, thus narrowing the search space and improving the model's convergence rate.
Experimental Results
The proposed framework was tested on ALFWorld and Overcooked environments. The results indicate significant improvements over traditional RL and LLM-based baselines. Specifically, the memory-driven approach enhanced performance by over 40% in in-distribution tasks and over 75% for generalized tasks in ALFWorld.

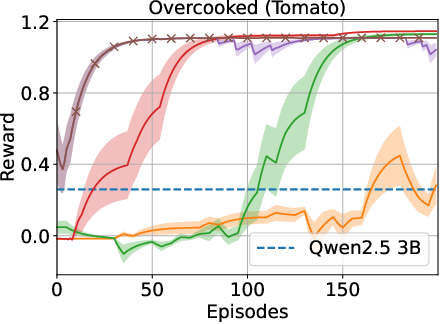
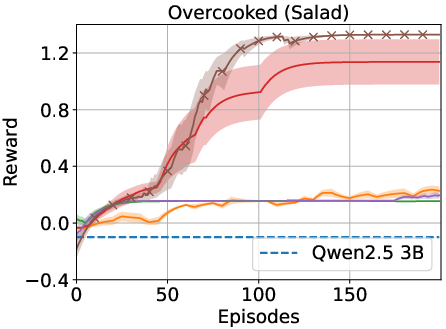
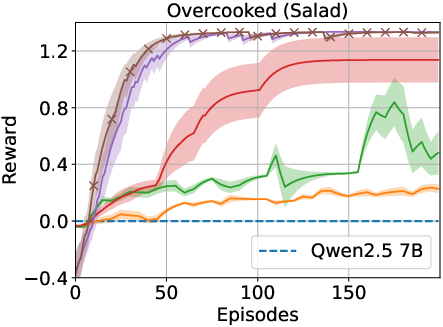
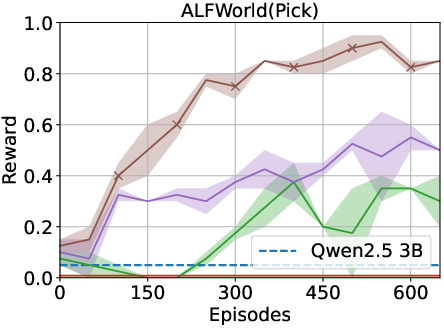
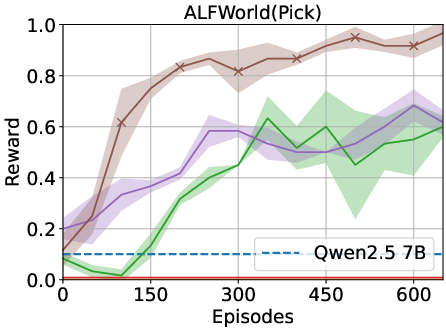
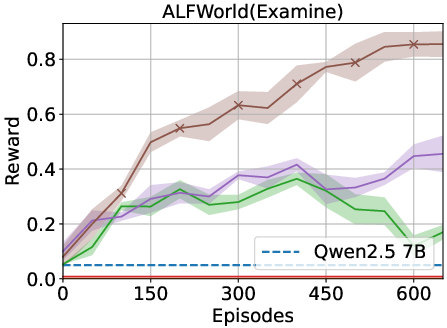
Figure 2: Results indicate that the memory-driven framework consistently outperforms baselines across various tasks.
Ablation Studies
The study explored the impact of variables such as the number of action candidates, fine-tuning intervals, and memory capacity. Findings showed robustness across these parameters, with the mutual reinforcement between memory-based value estimation and policy refinement contributing significantly to sample efficiency and decision-making capability.
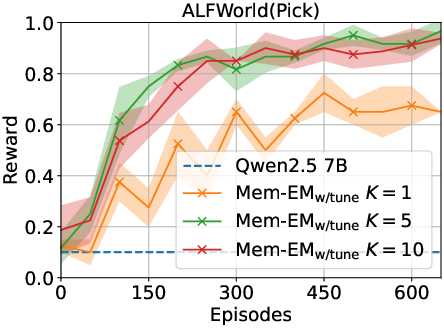
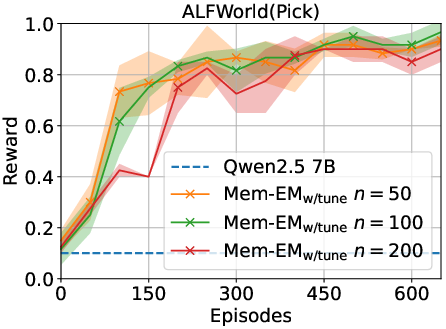
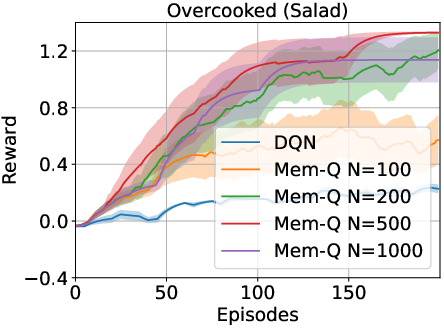
Figure 3: Ablation study highlighting the effects of candidate numbers, tuning intervals, and memory capacity on performance.
Discussion
The incorporation of memory with LLMs addresses inherent challenges in SDM tasks that require task-specific adaptation. By leveraging experiences stored in memory, the framework significantly enhances the policy optimization of LLMs, demonstrating improved sample efficiency and robustness.
Future Directions
The framework sets a precedent for further research into LLM-based decision-making systems. Future work could explore its application to environments with continuous or more complex action spaces, as well as integrating vision-LLMs for broader applications.
Conclusion
This paper introduces a robust framework that combines the strengths of LLMs with memory-driven decision-making to efficiently adapt to specific SDM tasks. It highlights the potential of memory augmentation in refining LLM priors, significantly enhancing task performance while maintaining computational efficiency.

