MemSearcher: Training LLMs to Reason, Search and Manage Memory via End-to-End Reinforcement Learning
Abstract: Typical search agents concatenate the entire interaction history into the LLM context, preserving information integrity but producing long, noisy contexts, resulting in high computation and memory costs. In contrast, using only the current turn avoids this overhead but discards essential information. This trade-off limits the scalability of search agents. To address this challenge, we propose MemSearcher, an agent workflow that iteratively maintains a compact memory and combines the current turn with it. At each turn, MemSearcher fuses the user's question with the memory to generate reasoning traces, perform search actions, and update memory to retain only information essential for solving the task. This design stabilizes context length across multi-turn interactions, improving efficiency without sacrificing accuracy. To optimize this workflow, we introduce multi-context GRPO, an end-to-end RL framework that jointly optimize reasoning, search strategies, and memory management of MemSearcher Agents. Specifically, multi-context GRPO samples groups of trajectories under different contexts and propagates trajectory-level advantages across all conversations within them. Trained on the same dataset as Search-R1, MemSearcher achieves significant improvements over strong baselines on seven public benchmarks: +11% on Qwen2.5-3B-Instruct and +12% on Qwen2.5-7B-Instruct relative average gains. Notably, the 3B-based MemSearcher even outperforms 7B-based baselines, demonstrating that striking a balance between information integrity and efficiency yields both higher accuracy and lower computational overhead. The code and models will be publicly available at https://github.com/icip-cas/MemSearcher
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces MemSearcher, a smarter way for AI assistants to look up information on the internet and remember only what matters. Instead of stuffing the AI’s “short-term memory” with everything from a long conversation, MemSearcher keeps a small, tidy memory that gets updated each turn. This helps the AI stay accurate while using less computing power and time.
Key Objectives
The paper focuses on three big goals, explained simply:
- Teach AI to reason step by step, search the web when needed, and remember only the useful parts.
- Keep the AI’s “context” (what it reads before answering) short and stable, even across many turns.
- Train the AI to do all of this end-to-end using reinforcement learning, so it improves by practicing.
Methods and Approach
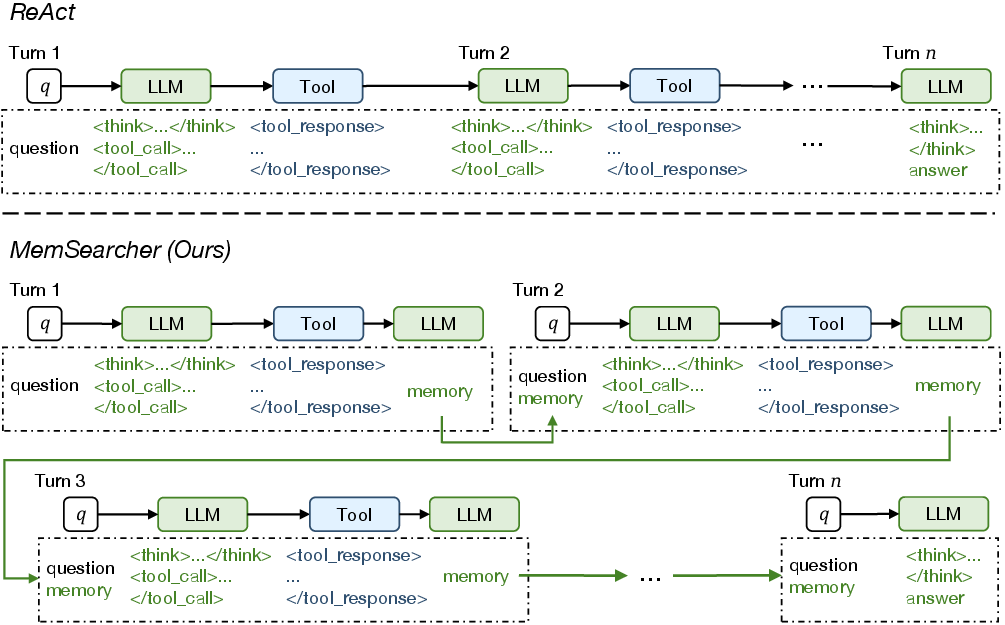
To understand the approach, imagine two study styles:
- ReAct (the old way): You keep every note you’ve written since the beginning. Your notebook gets huge, slow to search, and full of noise.
- MemSearcher (the new way): You keep a small index card. After each step, you rewrite the card to keep only the most important facts. It stays short and helpful.
How MemSearcher works each turn
Here’s what happens each time the AI takes a step:
- Input: It sees the user’s question and a short “memory” (a summary of useful facts so far).
- Reason and act: It thinks about the next step and either answers or searches the web.
- Update memory: After seeing new information, it rewrites the memory to keep only what’s essential.
Because the memory has a fixed size, the AI’s context doesn’t grow longer and longer like before. That keeps it fast and efficient.
How the AI learns this behavior (reinforcement learning)
The authors train the AI with a method called reinforcement learning (RL), which is like practice with a coach:
- The AI tries to answer questions by reasoning, searching, and updating memory.
- It gets a reward based on whether it followed the format and gave the right answer.
- Over time, it learns better strategies.
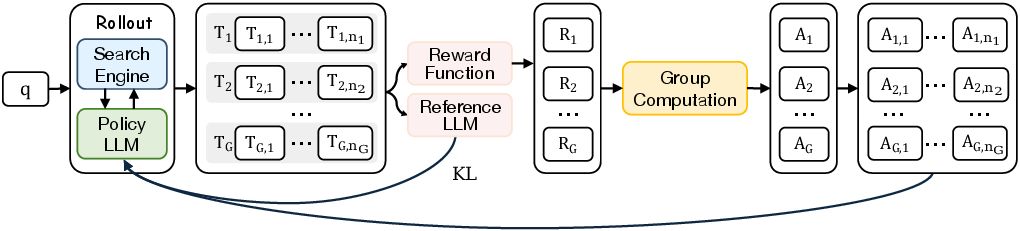
They use a training method called GRPO (Group Relative Policy Optimization):
- Think of running several practice attempts for the same question.
- Each attempt gets a score. The model compares attempts and learns from what worked better.
- In MemSearcher, each attempt actually includes several “mini-conversations” (because the memory changes). The authors extend GRPO to “multi-context GRPO,” which gives credit to all parts of a good attempt, helping the model learn stable behavior across different memory states.
Rewards (how the coach scores the model)
To keep it simple and reliable, the reward includes:
- Format reward: Did the AI follow the required structure (tags, final boxed answer)?
- Answer reward: How close is the final answer to the correct one (measured by F1 score, which checks word overlap)?
Main Findings
The authors trained MemSearcher on two sizes of the Qwen2.5 model (a 3B and a 7B version) using the same training data as a strong baseline (Search-R1). Then they tested on seven popular question-answering benchmarks that require both searching and reasoning, like NQ, TriviaQA, PopQA, HotpotQA, and others.
Key results:
- Higher accuracy: MemSearcher improved average scores by about 11% (3B model) and 12% (7B model) over strong baselines.
- Small beats big: The 3B MemSearcher even outperformed some 7B baselines, showing that good memory management can make smaller models act “bigger.”
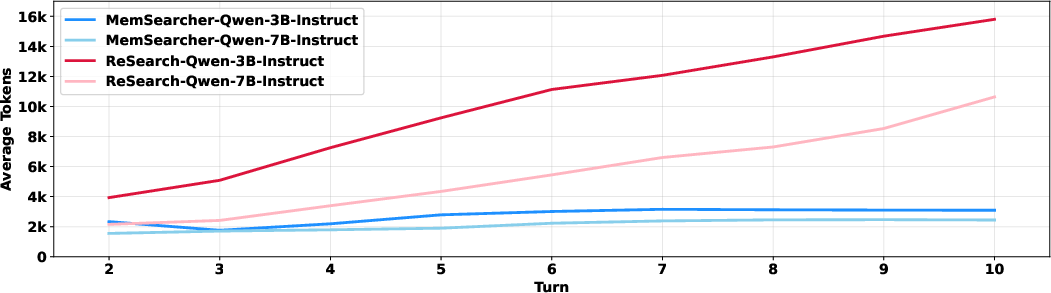
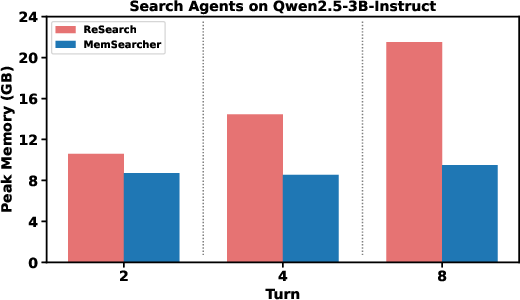
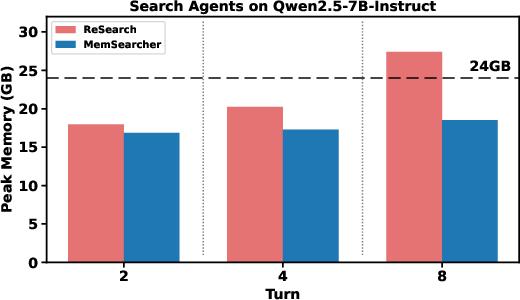
- More efficient: Unlike older methods that keep adding to the context every turn, MemSearcher keeps the context size steady. This reduces token usage and GPU memory, which means faster and cheaper runs.
- Competitive with live web tools: Even compared to methods that use real-time Google search during testing, MemSearcher performed better on average while using a local knowledge base.
Why this matters: Long, noisy contexts often confuse models and slow them down. MemSearcher proves you can keep information short and sharp without losing accuracy—actually gaining it.
Implications and Impact
MemSearcher shows a practical path to building AI assistants that:
- Reason clearly across many steps without drowning in their own notes.
- Search the web effectively and keep only the key facts.
- Run faster and cheaper, making them easier to scale and deploy.
- Let smaller models compete with larger ones by being smarter about memory.
In short, this research suggests that balancing information quality (what to keep) with efficiency (how much to keep) leads to better, more scalable AI search agents. This could improve everything from homework helpers to professional research tools.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable future work.
- Memory fidelity and loss: No quantitative assessment of how accurately the compact memory preserves salient facts across turns or how often critical information is dropped; define and track memory faithfulness/coverage metrics and conduct error analyses.
- Hallucination propagation: The model updates memory in natural language without verification; analyze and mitigate cases where incorrect intermediate statements are written into memory and later amplified.
- Credit assignment in multi-context GRPO: The same trajectory-level advantage is uniformly propagated to every conversation (turn), ignoring per-step contribution; investigate per-turn rewards, learned value functions, or counterfactual credit assignment to improve granularity and stability.
- Reward sparsity and myopia: The reward only checks final format and string-level answer F1; incorporate rewards for intermediate behaviors (retrieval quality, reasoning validity, memory quality, search efficiency) and evaluate the impact of reward shaping.
- Efficiency not explicitly optimized: Token efficiency improvements stem from design, not the RL objective; add explicit penalties or rewards for memory length, tool-call counts, or overall tokens to validate controllable efficiency–accuracy trade-offs.
- Missing ablations on memory capacity: No study of how the maximum memory size (fixed at 1,024 tokens) affects performance, stability, token usage, or forgetting; run size–performance and size–efficiency curves.
- No oracle or supervised memory baselines: Lacks comparison to memory created by (a) oracles, (b) supervised summarization, or (c) extractive note-taking, to quantify the headroom and the contribution of the learned memory manager.
- Limited retrieval setup: Only E5 embeddings over 2018 Wikipedia (no reranking, no multi-stage retrieval) were used; test stronger retrievers (e.g., Contriever/ColBERTv2), rerankers, hybrid sparse–dense retrieval, and different corpora to isolate retrieval vs. policy contributions.
- Live web robustness: Evaluation is confined to a local knowledge base; measure robustness with live web search (latency, noise, domain drift, adversarial pages) to enable fair, in-situ comparisons to web-based baselines.
- Domain and task breadth: Experiments focus on English open-domain QA; evaluate transfer to other domains (biomedical, legal), other languages, and other agentic tasks (planning, coding, tool orchestration) to test generality.
- Long-horizon interactions: No stress tests on tasks requiring many more turns than the reported benchmarks; evaluate stability and accuracy under long-horizon reasoning and deep search chains.
- Latency and cost reporting: Token counts and peak GPU memory are reported, but not wall-clock latency, throughput, or cost-per-answer; provide runtime and dollar-cost metrics to substantiate efficiency claims.
- Training stability and sensitivity: No analysis of sensitivity to key RL hyperparameters (KL coefficient, clip ratio, group size, temperature) or convergence properties of multi-context GRPO; report variance across seeds and training runs.
- Comparative training controls: No controlled comparison of RL-trained ReAct vs RL-trained MemSearcher under the same GRPO data and settings to isolate the net effect of the memory workflow.
- Memory update strategy alternatives: Only natural-language free-form memory is explored; compare to structured memories (triples, graphs), hybrid notes+citations, or token-level learned memory controllers to test fidelity and editability.
- Consistency and contradiction checks: No mechanisms to detect conflicts within memory or between memory and new observations; evaluate consistency checking and corrective updates (e.g., retrieval-augmented verification).
- Search efficiency metrics: The number of tool calls, search depth, and query refinement quality are not reported; measure and optimize search-step efficiency and path optimality under accuracy constraints.
- Answer faithfulness and attribution: EM is the sole evaluation metric; add span-level support verification, calibrated confidence, and source attribution to measure groundedness and trustworthiness of final answers.
- Fairness of cross-environment baselines: Some baselines use live web while MemSearcher uses an offline wiki; rerun baselines in the same environment or run MemSearcher on web to ensure apples-to-apples comparisons.
- Lifelong and cross-episode memory: Memory is reset per task; explore persistent, cross-task memory and its governance (retention, privacy, update policies) for continual agents.
- Robustness to retrieval errors: No analysis of behavior under noisy/irrelevant retrievals or retriever failures; test and develop fallback strategies (self-checks, query reformulation, uncertainty-aware stopping).
- Data/time coverage limitations: Using 2018 Wikipedia limits recency; evaluate on time-sensitive questions and newer corpora to assess temporal robustness.
- Process-level evaluation: Beyond final EM, there is no systematic evaluation of reasoning steps, memory edits, or search decisions for correctness; develop process-based audits and benchmarks to diagnose where gains originate.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s released code/models and the proposed MemSearcher workflow, which stabilizes context length and reduces compute/memory costs while improving accuracy in search-and-reason tasks.
- Customer support search agents (Software; Contact Centers)
- Use case: Multi-turn troubleshooting assistants that retrieve internal KB articles and iteratively retain only salient facts to resolve tickets faster.
- Tools/Products/Workflows: Integrate MemSearcher with existing RAG stacks; index support KBs; fine-tune via multi-context GRPO on historical chat logs; enforce formatting and answer extraction (boxed answers).
- Assumptions/Dependencies: High-quality retriever/indexing; domain-specific RL data; guardrails for hallucination and compliance; private deployment for sensitive content.
- Enterprise knowledge assistants (Finance, Legal, HR, IT)
- Use case: Answer complex, multi-hop questions about policies, procedures, and archival documents without exploding context windows.
- Tools/Products/Workflows: MemSearcher-backed internal search portal; compact-memory summaries per query; RL training on enterprise QA pairs; memory length budget (e.g., 1,024 tokens).
- Assumptions/Dependencies: Document ingestion and access control; reproducible rewards/metrics (Exact Match, F1); audit logging for answers and memory updates.
- Academic literature review assistants (Academia; Research)
- Use case: Query scholarly databases, track key claims/citations across iterations, and output concise, source-grounded syntheses.
- Tools/Products/Workflows: Connect MemSearcher to APIs (e.g., Crossref, Semantic Scholar), store memory traces of hypotheses and evidence; export structured summaries.
- Assumptions/Dependencies: Up-to-date bibliographic search; domain-specific evaluation (precision/coverage); policies for citation fidelity and anti-plagiarism.
- Clinical guideline retrieval (Healthcare; Non-diagnostic support)
- Use case: Fetch and reason over clinical practice guidelines for pathway and policy questions (e.g., dosing schedules, indications), maintaining an audit-friendly memory of relevant passages.
- Tools/Products/Workflows: Local guideline/document KB; conservative deployment as decision support; MemSearcher memory snapshots in clinical workflows; RL with synthetic clinical QA.
- Assumptions/Dependencies: Medical oversight; regulatory constraints; rigorous validation; curated, current clinical content; strict safety guardrails.
- Educational study assistants (Education; EdTech)
- Use case: Tutors that solve multi-step history/science questions by retrieving textbook sections and condensing essential facts into stable memory for successive turns.
- Tools/Products/Workflows: On-device or small-model (3B) deployments enabled by compact contexts; school-specific KBs; formative assessment with EM/F1; memory visualization for students.
- Assumptions/Dependencies: High-quality curricular indexing; content moderation; parental/teacher controls; local caching for low-latency.
- Web research for content teams (Marketing; Media)
- Use case: Produce source-linked briefs for trend reports, FAQs, and SEO content by iteratively searching the web and pruning irrelevant information.
- Tools/Products/Workflows: MemSearcher integrated with Google/Bing APIs; deduplication and citation extraction; memory constrained to key facts and quotes; editorial review queue.
- Assumptions/Dependencies: Web API quotas; robust de-noising; link rot handling; compliance with platform terms.
- Developer documentation search (Software Engineering)
- Use case: Agent that answers multi-step API usage questions by pulling docs, changelogs, and examples while keeping only pertinent snippets in memory.
- Tools/Products/Workflows: Index internal/external docs; RL fine-tuning on programming QAs; memory diff view to inspect what was retained across turns; IDE plugin.
- Assumptions/Dependencies: Retriever tuned for code/doc text; disambiguation among versions; license-aware content handling.
- Citizen policy Q&A (Public Sector; E-Government)
- Use case: Multi-turn assistants answering complex questions about services, benefits, and regulation, with compact memory enhancing cost-efficiency.
- Tools/Products/Workflows: Government portal integration; regular content updates; transparent memory snapshots for accountability; multilingual support.
- Assumptions/Dependencies: Accessibility and equity concerns; source of truth management; audit requirements; privacy protections.
- Personal knowledge retrievers (Daily Life; Productivity)
- Use case: Search across personal notes, bookmarks, and articles, summarizing essential insights as memory for subsequent follow-ups.
- Tools/Products/Workflows: Local indexing of notes (e.g., Markdown, PDFs); on-device small LLM deployments; memory export or pinning; private-by-default mode.
- Assumptions/Dependencies: User consent and data privacy; device resource constraints; efficient embedding/retrieval on edge.
- RL training for memory-managed agents (Academia; ML Ops)
- Use case: Researchers/teams training LLMs to reason, search, and manage memory end-to-end using multi-context GRPO on tasks with trajectory-level rewards.
- Tools/Products/Workflows: Use the open-source MemSearcher and verl-based pipelines; trajectory grouping; loss masking of tool tokens; standardized format/answer rewards.
- Assumptions/Dependencies: Stable RL runs; appropriate reward shaping; reproducible evaluation; compatible hardware for rollouts.
Long-Term Applications
These applications require further research, scaling, tooling, or validation beyond the current MemSearcher setup (e.g., more tools than search, stronger reward models, safety/regulatory approvals).
- General multi-tool agents with dynamic memory (Software; Robotics; Automation)
- Use case: Agents that orchestrate browsing, code execution, databases, and planning tools while maintaining a compact, selective memory across long workflows.
- Tools/Products/Workflows: Extend action space beyond search; hierarchical memory managers; tool-quality-aware rewards; multi-context GRPO across heterogeneous tools.
- Assumptions/Dependencies: Robust tool integration; compositional reward functions; safety policies for execution; failure recovery.
- Lifelong personal memory OS (Daily Life; Productivity)
- Use case: Persistent, cross-session memory consolidation for a “second brain” that learns long-term preferences, projects, and knowledge.
- Tools/Products/Workflows: Memory persistence, consolidation and decay policies; cross-device synchronization; privacy-preserving indexing; memory inspection UI.
- Assumptions/Dependencies: Trust, consent, and governance; secure key management; explainability for retained/dropped information.
- Clinical decision-making assistants with regulatory approval (Healthcare)
- Use case: At-the-point-of-care agents that retrieve evidence, reason across multi-hop sources, and maintain auditable memory of derivations and citations.
- Tools/Products/Workflows: Intensive validation trials; human-in-the-loop oversight; risk-based deployment; domain-adapted rewards (fidelity, safety).
- Assumptions/Dependencies: FDA/EMA-like approvals; indemnity frameworks; contamination and bias mitigation; continuous model monitoring.
- Scientific discovery copilots (Academia; Pharma; Materials)
- Use case: Hypothesis generation and iterative evidence synthesis across papers, datasets, and lab notes, with memory tracking of assumptions and contradictions.
- Tools/Products/Workflows: Integrate with data repositories (e.g., GEO, arXiv), simulation tools; multi-objective RL (novelty, rigor, reproducibility); provenance tracking.
- Assumptions/Dependencies: Domain-grounded reward models; expert evaluation loops; handling of conflicting sources; long-horizon planning.
- Legal research and drafting agents (Legal; Compliance)
- Use case: Multi-issue legal queries requiring cross-citation, precedent tracking, and selective memory of authoritative passages.
- Tools/Products/Workflows: Citational reliability scoring; court-specific corpora; redlining/drafting integrations; memory audit trails.
- Assumptions/Dependencies: Jurisdictional variation; hallucination penalties; explainability; human review mandates.
- Enterprise-scale RL pipelines for agent training (Software; ML Ops)
- Use case: Organization-wide frameworks for training memory-managed search agents on millions of trajectories from logs and documents.
- Tools/Products/Workflows: Data pipelines for trajectory grouping; offline evaluation harnesses; reward simulations; A/B deployment; cost/carbon budgeting.
- Assumptions/Dependencies: Robust data governance; observability on memory behavior; reproducibility; continuous retriever/model updates.
- Energy-efficient AI deployments and policy (Energy; Public Policy)
- Use case: Adopt memory-stabilized agent workflows to reduce quadratic token-compute growth, lowering energy bills and emissions in public/enterprise deployments.
- Tools/Products/Workflows: Carbon tracking dashboards; procurement policies favoring token-efficient agent architectures; standardized efficiency benchmarks.
- Assumptions/Dependencies: Reliable metering; cross-model comparison standards; incentives for green AI; stakeholder alignment.
- Edge and embedded assistants (IoT; Mobile)
- Use case: On-device assistants performing multi-hop retrieval from local content stores with compact memory to fit small models and limited RAM.
- Tools/Products/Workflows: Lightweight retrievers; adaptive memory budgets; binary quantization; offline-first designs.
- Assumptions/Dependencies: Hardware constraints; latency-SLA balancing; secure local storage; battery implications.
- Multi-agent systems with shared memory (Software; Collaboration)
- Use case: Teams of agents with a structured, conflict-resilient shared memory (e.g., CRDT-based) to coordinate research, planning, and execution.
- Tools/Products/Workflows: Memory graphs or atomic memory units; role-based memory access; inter-agent reward propagation; conflict resolution protocols.
- Assumptions/Dependencies: Communication overhead; consistency models; privacy segmentation; governance of shared memory edits.
- Productized modules and developer tooling (Software; Platforms)
- Use case: SaaS “Memory-Managed Search Agent” components, plus UI for memory inspection (“memory diff”), token budget controls, and RL training services.
- Tools/Products/Workflows: SDKs to wrap MemSearcher; observability for memory retention/forgetting; configurable reward models; integration templates for major RAG stacks.
- Assumptions/Dependencies: Vendor-neutral APIs; compliance with data residency; support for multiple LLM backbones; user education on memory controls.
Glossary
- Advantage (RL): A scalar estimate of how much better a trajectory (or action) performs compared to a baseline, used to weight policy gradient updates. "We propagate trajectory-level advantages to each conversation within them, i.e. , and treat each conversation as an independent optimization target to update the policy LLM."
- Chain-of-Thought (CoT): A prompting technique that elicits step-by-step reasoning traces from an LLM to solve problems. "Chain-of-Thought (CoT) reasoning"
- Context window: The maximum number of tokens an LLM can attend to in its input at once. "constrain the model to an 8K context window"
- Exact Match (EM): An evaluation metric that counts a prediction as correct only if it exactly matches the reference answer. "Exact Match (EM) is used as the evaluation metric."
- Gradient checkpointing: A memory-saving training technique that recomputes intermediate activations during backpropagation to reduce GPU memory usage. "We train MemSearcher agents with full parameter optimization and gradient checkpointing."
- Group Relative Policy Optimization (GRPO): A policy-gradient RL algorithm that normalizes rewards within groups of trajectories to stabilize updates, offering a memory-efficient alternative to PPO. "Group Relative Policy Optimization (GRPO) has recently emerged as the most widely adopted method"
- Kullback–Leibler (KL) divergence: A measure of how one probability distribution diverges from a reference distribution; used as a regularization penalty in RL fine-tuning. ""
- Loss masking: An RL/SFT training practice where gradients are disabled for certain tokens (e.g., tool outputs) so only model-generated tokens affect the objective. "we use loss masking for the tokens from the search engine"
- MemSearcher: The proposed agent workflow that maintains and updates a compact memory instead of concatenating full histories into the LLM context. "we propose MemSearcher, an agent workflow that iteratively maintains a compact memory"
- Multi-context GRPO: An extension of GRPO for trajectories containing multiple conversations under different contexts, propagating a trajectory-level advantage to each conversation. "we introduce multi-context GRPO, an end-to-end RL framework"
- Multi-hop question answering (QA): Tasks that require reasoning over multiple pieces of evidence or documents to arrive at an answer. "while HotpotQA is a multi-hop question answering dataset."
- Policy model: The parameterized model that defines the policy (distribution over actions/tokens) to be optimized in RL. "use each conversation as an independent target to optimize the policy model."
- Proximal Policy Optimization (PPO): A popular clipped policy-gradient RL algorithm for stabilizing policy updates. "Proximal Policy Optimization (PPO)"
- ReAct: An agent paradigm that interleaves reasoning (thoughts) with tool-using actions in multi-turn trajectories. "ReAct~\citep{yao2023react}, which integrates reasoning and acting, has become the most popular paradigm for building LLM-based agents"
- Reinforcement Learning (RL): A learning paradigm where an agent optimizes its behavior via reward signals obtained from interactions with an environment. "We employ Reinforcement Learning (RL) to train MemSearcher agents"
- Reinforcement Learning from Verifiable Rewards (RLVR): An RL setting where rewards are derived from verifiable signals (e.g., rule-based or programmatic checks) rather than human labels. "has recently become the most widely adopted RL algorithm for RLVR due to its effectiveness"
- Retrieval-Augmented Generation (RAG): A method that augments LLM generation with retrieved external documents to improve factuality and coverage. "Retrieval-Augmented Generation (RAG) integrates search engines with LLMs to provide relevant external information."
- Rollout: The process of sampling trajectories by interacting with the environment using the current policy. "In rollout, we sample a group of trajectories for question ."
- Trajectory: The sequence of states/contexts, actions, observations (and possibly rewards) generated during an episode of interaction. "Vanilla GRPO samples a group of trajectories for each question "
Collections
Sign up for free to add this paper to one or more collections.