dLLM: Simple Diffusion Language Modeling
Abstract: Although diffusion LLMs (DLMs) are evolving quickly, many recent models converge on a set of shared components. These components, however, are distributed across ad-hoc research codebases or lack transparent implementations, making them difficult to reproduce or extend. As the field accelerates, there is a clear need for a unified framework that standardizes these common components while remaining flexible enough to support new methods and architectures. To address this gap, we introduce dLLM, an open-source framework that unifies the core components of diffusion language modeling -- training, inference, and evaluation -- and makes them easy to customize for new designs. With dLLM, users can reproduce, finetune, deploy, and evaluate open-source large DLMs such as LLaDA and Dream through a standardized pipeline. The framework also provides minimal, reproducible recipes for building small DLMs from scratch with accessible compute, including converting any BERT-style encoder or autoregressive LM into a DLM. We also release the checkpoints of these small DLMs to make DLMs more accessible and accelerate future research.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces dLLM, a simple, open-source toolkit for building and testing “diffusion LLMs” (DLMs). Think of DLMs as text generators that write by filling in blanks across a sentence over several passes, instead of writing strictly left-to-right like most chatbots. The toolkit puts the most common pieces—training, generating text (inference), and measuring performance (evaluation)—into one easy-to-use, plug-and-play framework. It also gives step-by-step recipes and ready-to-use small models so more people can try DLMs without huge computers.
What the authors set out to do
In plain terms, the paper aims to:
- Make it easy to train, run, and evaluate many kinds of diffusion-based text models in one place.
- Standardize how different DLMs are compared, since tiny setting changes can drastically change scores.
- Show that you can turn existing models (like BERT or normal left-to-right LMs) into DLMs with small changes and modest compute.
- Speed up DLM text generation so it’s more practical.
How it works (methods and approach)
To follow the paper, it helps to know what diffusion for text means:
- Imagine a jigsaw puzzle that starts complete and gets some pieces covered up (masked). A diffusion model learns to uncover those pieces step by step until the full picture is back. For text, the “pieces” are tokens (words or subwords).
The framework supports two popular flavors of diffusion for text:
- Masked Diffusion (MDLM)
- Idea: Randomly replace some tokens with a special “mask” token (like blank spaces). The model learns to fill in those blanks.
- Analogy: A teacher gives you a sentence with some words blanked out. Your job is to guess the missing words.
- Block Diffusion (BD3LM)
- Idea: Split a long sequence into blocks. Write (and refine) one block at a time while using what’s already written as context, reusing cached computations to be faster.
- Analogy: Writing an essay in paragraphs: finish and polish paragraph 1, then move to paragraph 2 with paragraph 1 fixed.
What dLLM (the toolkit) provides:
- Trainer: Ready-made training modules for MDLM and BD3LM. You can swap a trainer with a one-line change to try a different learning style. It works with popular tools like Hugging Face to scale up training.
- Sampler: A simple, unified way to run inference (generate text). You can plug in different decoding strategies without changing your model’s code. It includes a fast sampler that enables caching and parallel token updates to speed up generation.
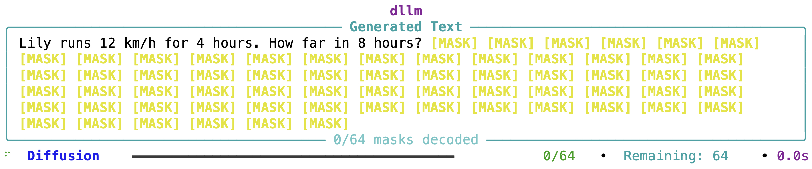
- Visualizer: A terminal tool that shows how the model fills in blanks over steps, so you can see the “thinking” order.
- Evaluation: A unified evaluation pipeline that carefully matches the settings used in prior papers, because DLMs are very sensitive to decoding choices (like temperature or maximum output length). This makes comparisons fair.
- Recipes and checkpoints: Clear, minimal examples for:
- Turning a BERT-style model (normally used for understanding text) into a diffusion chatbot.
- Converting a standard left-to-right LLM into a DLM.
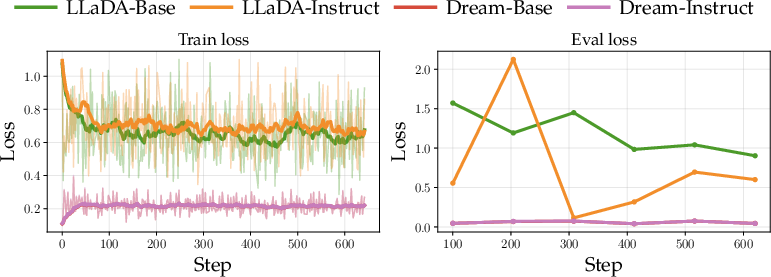
- Finetuning existing large DLMs (like LLaDA and Dream) to improve reasoning.
Main findings and why they matter
Here are the main takeaways the authors show with examples and experiments:
- One framework, many models: With the same codebase, you can train, finetune, run, and evaluate different DLMs (like LLaDA and Dream). Swapping training styles (MDLM ↔ BD3LM) or inference samplers is quick and easy.
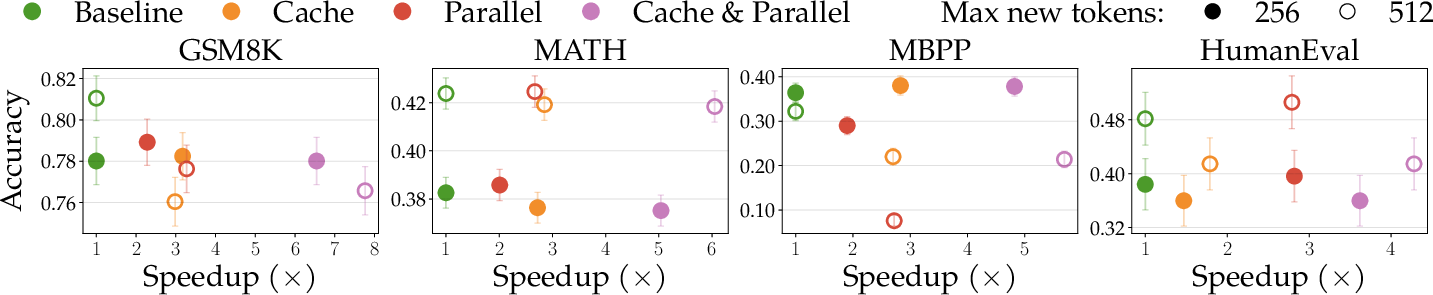
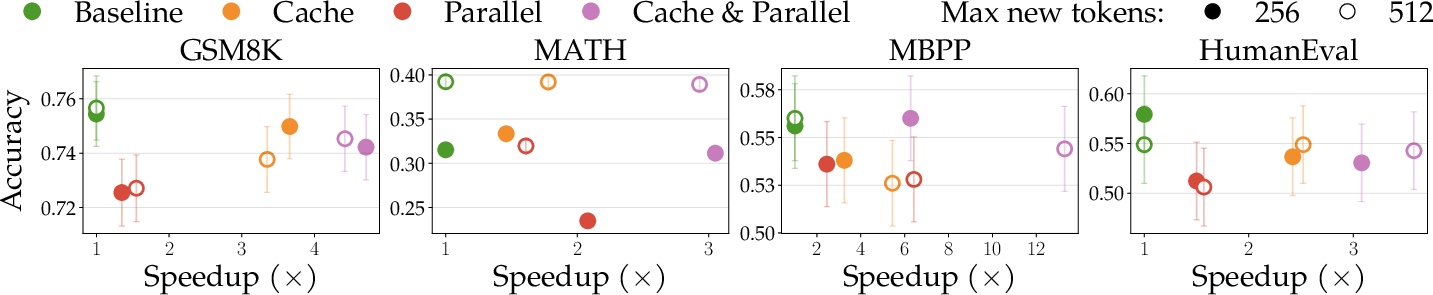
- Faster text generation: Using the Fast-dLLM sampler speeds up DLM decoding by allowing key-value caching and updating multiple tokens in parallel. This tackles a common complaint that DLMs are slow.
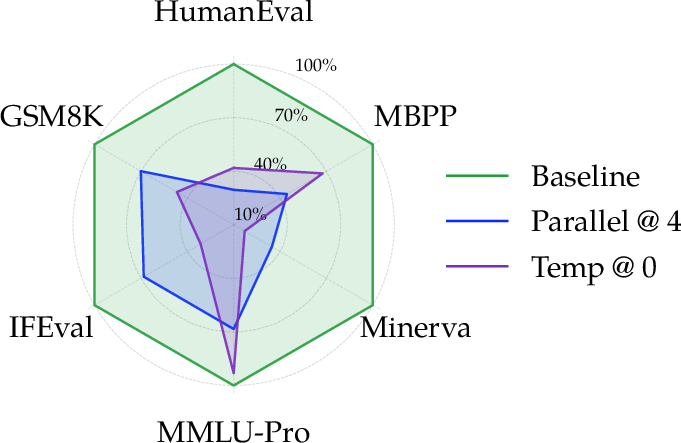
- Fairer, more reproducible evaluation: The evaluation pipeline matches the exact inference settings used by original papers. The authors show that changing just one setting (e.g., temperature, number of tokens to generate, or how early to allow the end-of-sentence token) can greatly change scores. Their unified setup avoids apples-to-oranges comparisons.
- Reasoning improves with simple finetuning: When they finetune open DLMs on reasoning data (think math, planning, coding), “Instruct” versions tend to improve across several benchmarks. This suggests DLMs can be coached to reason better without fancy tricks.
- Build DLMs from existing models with modest compute:
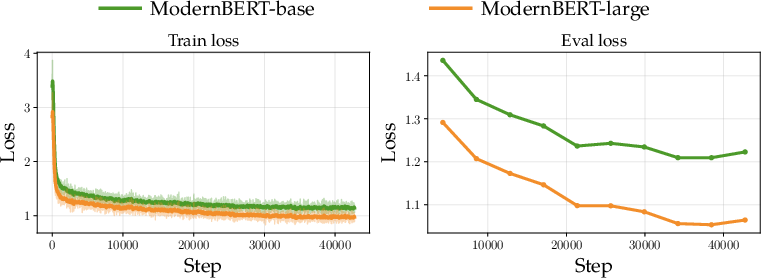
- BERT → DLM chatbot: By finetuning a strong BERT backbone with a diffusion objective, they get a working chatbot without changing the architecture. It doesn’t beat top autoregressive models but performs respectably for its size and simplicity.
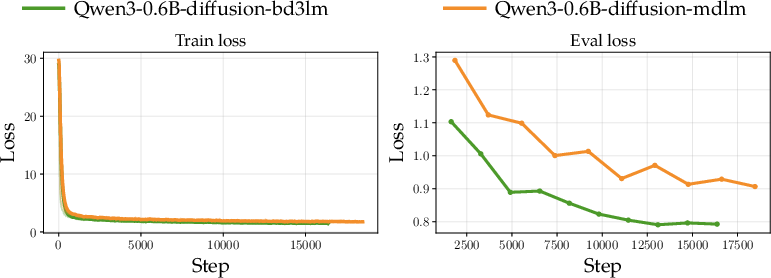
- Autoregressive LM → DLM: They convert a small Qwen model into DLM variants (both MDLM and BD3LM) using only supervised finetuning. One variant does especially well on coding tasks, even beating the original base model on those, showing conversion can be practical and effective.
Why these results matter:
- Standard tools and recipes reduce guesswork and save time.
- Faster inference and fairer evaluations make DLMs more practical and credible.
- Showing that you can build decent DLMs from existing models lowers the barrier for students, startups, and researchers with limited compute.
What this could change (implications)
- Lower entry barrier: More people can try DLMs thanks to unified trainers, samplers, evaluation scripts, and public checkpoints.
- Faster progress: Researchers can test new ideas quickly (swap trainers/samplers, try new objectives) and compare fairly across models.
- Practical deployment: Speed-ups and block-wise methods make DLMs closer to real-world use.
- New directions: The success of converting BERTs and autoregressive LMs into DLMs hints that many existing models can be repurposed to explore parallel decoding and iterative refinement, possibly leading to smarter, more controllable text generation.
In short, this paper is about turning DLM research from scattered, one-off projects into a clean, shared toolbox—so building, improving, and fairly testing diffusion-based text models becomes much easier for everyone.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide follow-up research and development.
- Limited objective coverage: the framework primarily supports MDLM and BD3LM (with a reference EditFlow trainer), but lacks end-to-end recipes and benchmarks for alternative discrete/continuous objectives (e.g., multinomial diffusion, ratio/score-based objectives, embedding-space diffusion, discrete flow matching), preventing apples-to-apples comparisons across these families.
- No systematic ablations on diffusion design choices: the paper does not study how mask rate schedules, time-weighting (e.g., 1/t), corruption policies, or denoising target parameterizations impact downstream quality, stability, and speed across tasks.
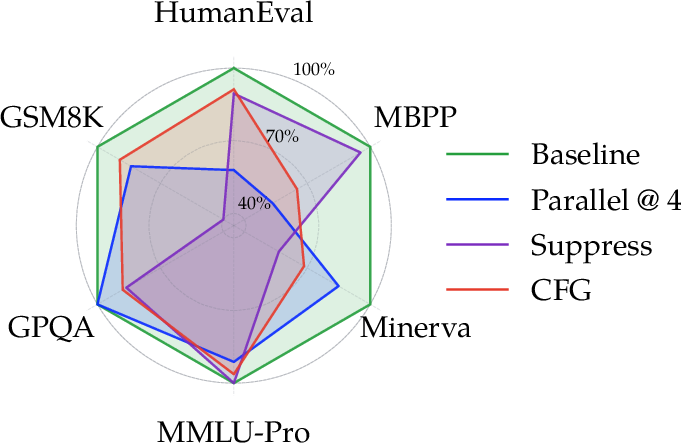
- Sparse guidance/control support: beyond a hyperparameter sensitivity vignette (CFG=0.5) there is no standardized implementation, evaluation, or best-practice guidance for guidance methods (e.g., classifier-free guidance, constraint decoding, edit-operator guidance), nor analysis of their quality–speed trade-offs.
- Incomplete acceleration coverage: Fast-dLLM is integrated for MDLM, but there is no systematic evaluation of acceleration for BD3LM (e.g., Fast-dLLM v2, dKV-cache) across block sizes, long contexts, and hardware; memory footprint and throughput/latency trade-offs are also not reported.
- Lack of robust default inference settings: while hyperparameter sensitivity is highlighted, the paper does not propose robust, model-agnostic defaults, automated tuning strategies, or task-conditional policies that maintain quality across diverse benchmarks.
- Missing evaluation of decoding-order policies: the terminal visualizer exposes token update order, but there is no quantitative study of scheduling strategies (e.g., confidence-based, left-to-right, block-wise) on quality, stability, and speed across tasks.
- Conversion recipes need deeper analysis: AR-to-DLM results exclude the right-shift logits trick (reported as harmful) without controlled ablations, error analyses, or exploration of when/why it fails or succeeds; other adaptation variants (e.g., BOS handling, teacher-forcing, schedule mixing) remain unexplored.
- Limited pretraining investigations for small DLMs: small-model recipes rely on SFT-only conversion (BERT → DLM, ARLM → DLM); the paper does not examine continual pretraining or truly from-scratch DLM pretraining (data scales, objectives, curricula) and their cost–benefit relative to SFT-only conversion.
- Scaling behavior is unstudied: there are no scaling-law analyses for DLMs under unified training (quality vs. tokens vs. parameters vs. compute) or comparisons to AR scaling at matched budgets.
- Narrow benchmark breadth and comparability: evaluations cover a subset of general benchmarks; multilingual, long-context, instruction-following, safety/alignment, and domain-specific tasks (e.g., legal/medical) are not included; several baselines are taken from reported numbers rather than re-evaluated with the same pipeline.
- Reproducibility dependence on model-specific quirks: the evaluation framework relies on manual matching of preprocessing/decoding/postprocessing per model–task pair; the fragility and portability of these configurations across new releases or datasets are not assessed.
- Metrics for DLMs remain under-specified: there is no unified metric suite addressing DLM-specific aspects (e.g., iterative refinement quality, calibration/probability surrogates without AR perplexity, partial-output fidelity, edit distance to references over steps).
- Limited analysis of failure modes: the paper notes regressions on out-of-distribution planning/coding for some SFT settings but does not diagnose error patterns (e.g., reasoning depth, tool-use, compositionality) or propose mitigation strategies.
- Safety and bias are not evaluated: toxicity, bias, prompt-injection resilience, jailbreak robustness, and hallucination control for DLMs (and how iterative refinement affects them) are omitted.
- Long-context behavior and length generalization: aside from fixed max-new-token settings (which affect compute), there is no study of length generalization, truncation effects, or dynamic allocation of bidirectional context windows for variable-length generation.
- KV-cache and memory–quality trade-offs: while acceleration is shown, the paper does not quantify memory savings, cache-accuracy impacts on output quality, or degradation across cache approximations in long sequences.
- PEFT choices not explored: LoRA is used for large-model SFT, but alternative parameter-efficient strategies (e.g., IA3, adapters, LoRA rank/alpha sweeps) and their quality–compute trade-offs are not evaluated.
- Multimodal extensibility is untested: despite claims of modularity, there is no demonstration of extending the framework to multimodal DLMs (e.g., interleaved text+image or code+natural language) or edit-flow multi-operation pipelines.
- Data curation and contamination controls are unspecified: dataset filtering, deduplication, contamination checks (especially for reasoning/code sets), and licensing constraints are not discussed, limiting the reliability of reported gains.
- Determinism and reproducibility across hardware/backends: the framework builds on Accelerate/DeepSpeed/FSDP but does not report determinism, seed control, or cross-backend reproducibility guarantees for training and inference.
- Usability and maintenance claims are unmeasured: there is no user study or empirical evidence quantifying reduced implementation time, ease of integrating new objectives, or maintenance overhead compared to ad-hoc codebases.
- Generalization of sampler abstraction: while a plug-and-play sampler is proposed, API overhead, compatibility limits with diverse model heads/tokenizers, and extension paths for complex samplers (e.g., edit operations, speculative diffusion) are not benchmarked.
- Open integration with RL and preference optimization: reinforcement learning for DLMs is named as future work; there is no prototype API or experiment showing how RL/PPO/DPO-style methods could be attached to diffusion objectives and samplers in this framework.
- Programmatic diagnostics of decoding: the visualizer is useful for humans, but there is no standardized logging schema or metrics for decoding trajectories (e.g., confidence evolution, token revision frequency) to enable large-scale comparative studies.
Practical Applications
Immediate Applications
Below are actionable, near-term use cases that can be deployed with the framework and released checkpoints as they are today.
- Industry (Software/Cloud): Standardized DLM R&D and model lifecycle
- What: Use the unified MDLM/BD3LM trainers and sampler abstraction to reproduce, finetune, A/B test, and deploy open-weight DLMs (e.g., LLaDA, Dream) through a single, HuggingFace-native workflow.
- How: MDLMTrainer/BD3LMTrainer + accelerate + DeepSpeed/FSDP + PEFT/LoRA; Sampler(model).sample() for plug-and-play decoders.
- Value: Faster iteration and fairer comparisons across models/algorithms; lowers infra and engineering overhead.
- Assumptions/dependencies: HF stack and GPUs; correct preprocessing/postprocessing; careful management of hyperparameter sensitivity during evaluation.
- Industry (Software/DevTools): Lower-latency DLM serving with Fast-dLLM
- What: Swap in MDLMFastdLLMSampler to enable KV-cache reuse and parallel token updates for MDLMs; reduce latency and increase throughput.
- How: Drop-in sampler replacement; combine cache and parallel decoding for speedups consistent with Fast-dLLM reports.
- Value: Makes DLM inference more cost-effective for interactive applications (chat, code assistants).
- Assumptions/dependencies: Model compatibility (MDLM or compatible variants), memory budget for block-wise caches, decoding hyperparameter tuning (notably sensitive).
- Academia/Industry: Reproducible evaluation and audit-ready benchmarking
- What: A unified evaluation pipeline extending lm-eval-harness that reproduces official model–task results with matched preprocessing/decoding/postprocessing.
- How: Task- and model-specific configs checked against official pipelines; supports systematic hyperparameter sweeps.
- Value: Fair comparisons across DLMs/algorithms; enables A/B testing and procurement-style assessments.
- Assumptions/dependencies: Public datasets/licenses; strict configuration control; disclosure of decoding parameters (critical due to sensitivity).
- Industry (Customer Support/Internal IT) and Daily Life/SMBs: Build domain chatbots with minimal compute
- What: Convert existing models into DLMs via SFT-only recipes (BERT-Chat, Tiny A2D) or finetune open-weight DLMs with LoRA for domain tasks.
- How: Use released checkpoints and scripts (ModernBERT-Chat; Qwen3-0.6B diffusion via MDLM/BD3LM); apply MDLM SFT on curated instruction data.
- Value: Cost-effective assistants that run on modest hardware or on-prem; privacy-preserving deployments.
- Assumptions/dependencies: High-quality, domain-relevant SFT data; acceptable performance vs AR baselines for the target task; licensing compliance.
- Software Engineering (IDEs/Code Assistants): Parallel code completion and multi-hole editing
- What: Use BD3LM block-wise decoding to fill multiple code spans in parallel with KV-cache reuse.
- How: Integrate BD3LM sampler into editor plugins for speculative and section-wise completions.
- Value: Lower latency in IDEs; better support for non-left-to-right editing patterns.
- Assumptions/dependencies: Integration effort; tuning block sizes and decoding steps; training on code-specific SFT.
- Academia (Research/Teaching): Rapid prototyping and instruction
- What: Experiment with new diffusion objectives (e.g., EditFlow), conduct ablations, and run classroom labs contrasting diffusion vs autoregressive decoding.
- How: Plug-in trainer abstractions and terminal visualizer for decoding order.
- Value: Low-friction research and pedagogy; accelerates idea–to–result cycle.
- Assumptions/dependencies: Compute access; familiarity with HF ecosystem; availability of relevant datasets.
- Product/UX and Debugging: Decoding-order interpretability
- What: Use the terminal visualizer to reveal token update order and the sample’s evolution for debugging or user-facing “explain my generation” features.
- How: Integrate visualization outputs into developer consoles or user interfaces.
- Value: Easier diagnosis of failure modes; improves trust and transparency in generation workflows.
- Assumptions/dependencies: Tokenization alignment; UI work to present intermediate states meaningfully.
- Regulated Sectors (Healthcare/Finance/Legal): Data-efficient domain adaptation with LoRA
- What: Apply parameter-efficient MDLM SFT (loss on response tokens only) to adapt an existing DLM to in-domain text on secured infrastructure.
- How: Use PEFT/LoRA to keep base weights fixed; run on on-prem GPUs with DeepSpeed ZeRO-2.
- Value: Reduces compute and data footprint; maintains privacy/control.
- Assumptions/dependencies: Carefully curated in-domain data; rigorous red-teaming and compliance checks; recognition of current performance gaps in some reasoning/knowledge tasks.
- Daily Life/On-device: Local assistants on modest hardware
- What: Deploy smaller diffusion chatbots (e.g., ModernBERT-Chat) for offline note-taking, drafting, or Q&A.
- How: Quantize and serve with efficient samplers; cap max new tokens to control compute and latency.
- Value: Privacy and cost control for individuals and small teams.
- Assumptions/dependencies: Acceptable quality for use case; memory constraints; careful hyperparameter selection due to sensitivity.
Long-Term Applications
These applications are feasible with further research, scaling, productization, or ecosystem maturation.
- Software/Productivity: Diffusion LLMs as primary decoders for interactive editing
- What: Replace or complement AR decoding in writing/coding/design tools where iterative refinement and non-left-to-right edits are beneficial.
- Potential tools/workflows: Document and code editors that “diffuse” multiple regions simultaneously, outline-then-diffuse pipelines, draft-and-verify flows.
- Dependencies: Additional speedups (e.g., Fast-dLLM v2, specialized kernels), robust quality parity with AR on broad tasks, UX validation.
- Policy/Standards: Benchmarking and disclosure standards for DLM evaluation
- What: Formalize requirements to report inference hyperparameters/postprocessing and provide evaluation-as-code artifacts in model cards and procurement.
- Potential outcomes: Sector-wide reproducibility norms; comparable leaderboards across DLMs.
- Dependencies: Community and vendor buy-in; dataset licensing clarity; governance frameworks.
- Robotics/Autonomy: Diffusion-based planning with parallel/iterative refinement
- What: Generate and refine multi-step plans with flexible decoding orders; better re-planning when constraints change.
- Potential tools: Planning modules that propose/edit action sequences in parallel; hybrid AR–diffusion planners.
- Dependencies: Grounding to perception/control, safety assurances, real-time constraints and hardware acceleration.
- Healthcare: Auditable clinical text generation and summarization
- What: Iterative, revision-transparent generation (e.g., clinical notes, discharge summaries) where intermediate steps can be reviewed.
- Potential workflows: Human-in-the-loop pipelines that accept/reject/refine diffusion steps; compliance logging.
- Dependencies: Strict clinical validation, privacy and security, bias/hallucination mitigation, regulatory approval.
- Finance/Legal: Template- and constraint-aware document automation
- What: Use guided/block diffusion to enforce structural constraints across sections (e.g., contracts, reports) and refine sections in parallel.
- Potential workflows: Section-wise generation with cross-section consistency checks and constraint guidance.
- Dependencies: Reliable constraint/guidance mechanisms, high precision requirements, auditable intermediate states.
- Energy/Edge/IoT: Energy-efficient on-device DLMs
- What: Optimize blockwise KV caching and parallel decoding for edge accelerators to reduce energy per token.
- Potential products: On-device assistants for wearables, vehicles, or kiosks with low latency and privacy.
- Dependencies: Hardware-aware kernels, quantization/pruning for DLMs, memory footprint control.
- Multi-modal and Edit-Flow Systems: Concurrent, interleaved generation and editing
- What: Extend trainer/sampler to flow-matching/edit flows for insert/delete/substitute operations across modalities (text + layout/code/comments).
- Potential tools: Multi-modal editors that revise structure and content jointly in a few steps.
- Dependencies: Mature datasets for edit operations, stable training for edit flows, integration with existing toolchains.
- RL-enhanced Reasoning and Tool Use
- What: Incorporate reinforcement learning (e.g., d1-style) into DLM training to improve long-horizon reasoning and external tool calls.
- Potential products: Planning, math, and coding assistants with stronger reasoning traces and verifiable intermediate steps.
- Dependencies: Stable RL recipes for DLMs, compute budgets, safety and alignment methods for non-left-to-right decoders.
- Enterprise MLOps: DLM-native CI/CD and observability
- What: Build CI pipelines around the unified trainer/sampler/eval to gate model promotions on reproducible metrics and decoding configs.
- Potential workflows: Automated hyperparameter sweeps, regression detection on decoding-sensitive metrics, versioned inference configs.
- Dependencies: MLOps integration, org-wide standards for reproducibility, dataset/version governance.
Glossary
- Absorbing-state masking process: A corruption process where tokens transition to a special absorbing mask state, simplifying discrete diffusion. "simplifies the forward process as an absorbing-state masking process."
- AR-to-diffusion conversion: Converting pretrained autoregressive models into diffusion LLMs to reuse training artifacts. "AR-to-diffusion conversion to bootstrap ARLM training artifacts into DLMs"
- AR-to-MDLM adaptation: A procedure to adapt an autoregressive LM to a masked diffusion objective with minimal changes. "Changes for AR-to-MDLM adaptation."
- Autoregressive LLM (ARLM): A model that generates text strictly left-to-right by predicting the next token given previous ones. "Autoregressive LLMs (ARLMs) dominate open-ended text generation"
- BD3LM (Block Diffusion): A hybrid approach that generates text in blocks by combining autoregression (across blocks) with diffusion (within blocks). "Block Diffusion (BD3LM) combines autoregression with diffusion."
- BF16 precision: A half-precision (16-bit) floating-point format that saves memory and speeds training/inference relative to FP32. "bf16 precision"
- Bidirectional context window: A decoding context that allows conditioning on both left and right tokens, typical in diffusion-style generation. "pre-allocated padding tokens in the bidirectional context window"
- Block-wise approximate KV caching: Reusing approximate key–value attention states within decoding blocks to accelerate diffusion inference. "block-wise approximate KV caching within each decoding block"
- BOS token: A special begin-of-sequence symbol used to start generation or align predictions. "PrependBOSWrapper prepends BOS to provide the predictions for the first mask token."
- Cosine learning-rate schedule: A training schedule that decays the learning rate following a cosine curve, often with warmup. "a cosine learning-rate schedule"
- DeepSpeed ZeRO-2: A distributed optimization strategy that partitions optimizer states/gradients to train larger models efficiently. "DeepSpeed ZeRO-2"
- Diffusion LLMs (DLMs): Text generators that iteratively denoise corrupted sequences instead of predicting left-to-right. "Diffusion LLMs (DLMs) have emerged as a promising alternative"
- Discrete diffusion: A generative framework that models token sequences by reversing a discrete noising process. "Discrete diffusion models generate data by reversing a forward process that progressively destroys information."
- EditFlow: A diffusion/flow-matching method that edits sequences via insertion, substitution, and deletion operations. "EditFlow trainer"
- FSDP (Fully Sharded Data Parallel): A training approach that shards model parameters, gradients, and optimizer states across devices. "FSDP and DeepSpeed for distributed training"
- Gradient accumulation: Technique that simulates larger batch sizes by accumulating gradients over multiple steps before an optimizer update. "gradient accumulation steps of $4$"
- Inference hyperparameters: Generation-time settings (e.g., temperature, steps, suppression) that strongly affect model outputs and scores. "DLMs are especially sensitive to inference hyperparameters"
- Key-value (KV) cache: Stored attention keys and values reused across steps to avoid recomputation and speed decoding. "cached key-values"
- lm-evaluation-harness: A standardized framework for evaluating LLMs on a wide suite of benchmarks. "lm-evaluation-harness"
- LoRA (Low-Rank Adaptation): A parameter-efficient finetuning method that injects low-rank adapters into weight matrices. "We apply LoRA adaptation with "
- Mask token: A special symbol representing a hidden/unknown token during diffusion training and inference. "a special mask token "
- Masked Diffusion (MDLM): A discrete diffusion objective that corrupts tokens by masking and trains a model to recover the original sequence. "Masked Diffusion (MDLM) simplifies the forward process"
- Negative log-likelihood: A loss function measuring how improbable the true tokens are under the model, minimized during training. "minimizes the negative log-likelihood of the clean tokens"
- Parameter-efficient finetuning (PEFT): Methods that adapt large models by training small additional modules instead of all parameters. "peft for parameter-efficient finetuning"
- Parallel token updates: Updating multiple token positions per decoding step based on confidence to accelerate diffusion sampling. "confidence-based parallel token updates"
- Right-shifted logits: A training trick that offsets predictions by one position to reuse next-token prediction heads. "right_shift_logits reuses next-token prediction"
- Sampler (inference abstraction): A pluggable interface that decouples model architectures from decoding strategies. "Sampler(model).sample()"
- SFT (supervised fine-tuning): Finetuning on labeled instruction–response pairs to align or improve model capabilities. "MDLM SFT"
- Temperature (sampling): A scaling factor on logits that controls randomness—lower values make outputs more deterministic. "Temp @ $0$ sets temperature=0.0."
- Terminal visualizer: A debugging tool that shows token reveal order and the evolution from masked to decoded text. "Terminal Visualizer showing transition from masked to decoded tokens."
- Time-dependent reweighting: Weighting training losses according to the diffusion time step to balance contributions across noise levels. "with a time-dependent reweighting (e.g., 1/t assuming linear schedule)"
- Transformers Trainer: The HuggingFace training engine used as a base wrapper for the paper’s custom trainers. "transformers Trainer"
- Unified evaluation pipeline: A standardized setup that reproduces model-specific preprocessing, decoding, and scoring for fair comparisons. "A unified evaluation pipeline must therefore be flexible enough to support customization"
Collections
Sign up for free to add this paper to one or more collections.

