GLM-5: from Vibe Coding to Agentic Engineering
Abstract: We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “GLM-5: from Vibe Coding to Agentic Engineering”
Overview: What is this paper about?
This paper introduces GLM-5, a new AI model designed to be not just a smart chatbot, but an active “agent” that can plan, make decisions, and complete complex tasks—especially in software engineering. The big idea is moving from “vibe coding” (guessing code from hints) to “agentic engineering” (carefully planning, writing, testing, and fixing software end-to-end). GLM-5 also focuses on being faster and cheaper to run, while staying good at handling very long inputs (like big codebases or long documents).
Key Goals and Questions
The paper sets out to answer a few simple questions:
- How can an AI be both very capable and more efficient to train and use?
- Can it understand and work with very long inputs (like thousands of pages or many files) without getting lost?
- Can it act more like a helpful teammate—planning, checking its own work, using tools, and fixing mistakes—especially in real-world coding?
- Can we improve its reliability (fewer hallucinations) and make it better aligned with human goals and styles?
- Can this work run well on different kinds of computer chips, including many used in China?
Methods: How did they build GLM-5?
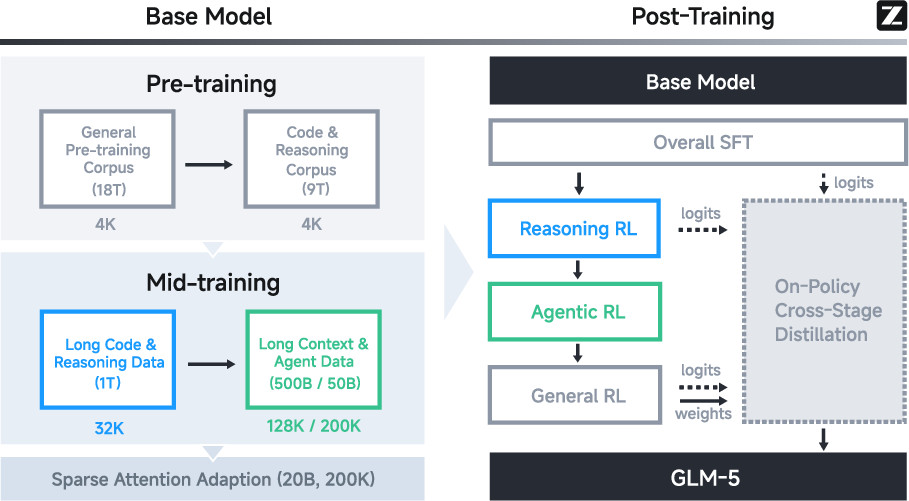
The team trained GLM-5 in stages and added new techniques to make it both smarter and more efficient. Here’s how to think about the main ideas:
- Training in stages:
- Pre-training: The model reads a huge amount of text and code (about 27–28.5 trillion tokens) to learn general skills.
- Mid-training: It practices with longer and more complex tasks, stretching its “memory” from 4K tokens up to 200K tokens, so it can handle very long contexts reliably.
- Post-training: It gets specialized practice with reasoning, tool use, coding, and general helpfulness, using both supervised learning (learning from good examples) and reinforcement learning (learning by trying, getting feedback, and improving step by step).
- Paying attention efficiently:
- DSA (DeepSeek Sparse Attention) is like smart skimming: instead of looking at everything in a long document, GLM-5 focuses on the most important parts. This saves compute (making it cheaper and faster) while keeping strong performance on long inputs.
- Model-of-Experts (MoE):
- Think of MoE as a big team of specialized “mini-models,” where only a few are used for each token. This makes the model huge in total (744 billion parameters) but still efficient, because only about 40 billion are active at a time.
- Multi-token prediction:
- The model tries to predict several next words at once, not just one. This can speed up generation, like planning a few steps ahead.
- Asynchronous reinforcement learning (RL):
- Instead of waiting for every rollout to finish before learning (which wastes time), GLM-5 separates “generating experiences” from “learning from them.” Imagine a busy kitchen: cooks keep making dishes while another team organizes feedback and training in parallel. This makes learning much faster.
- Agent-focused RL:
- New RL algorithms help the model learn better from long, complex tasks (like multi-step coding projects), including planning ahead and correcting itself over time.
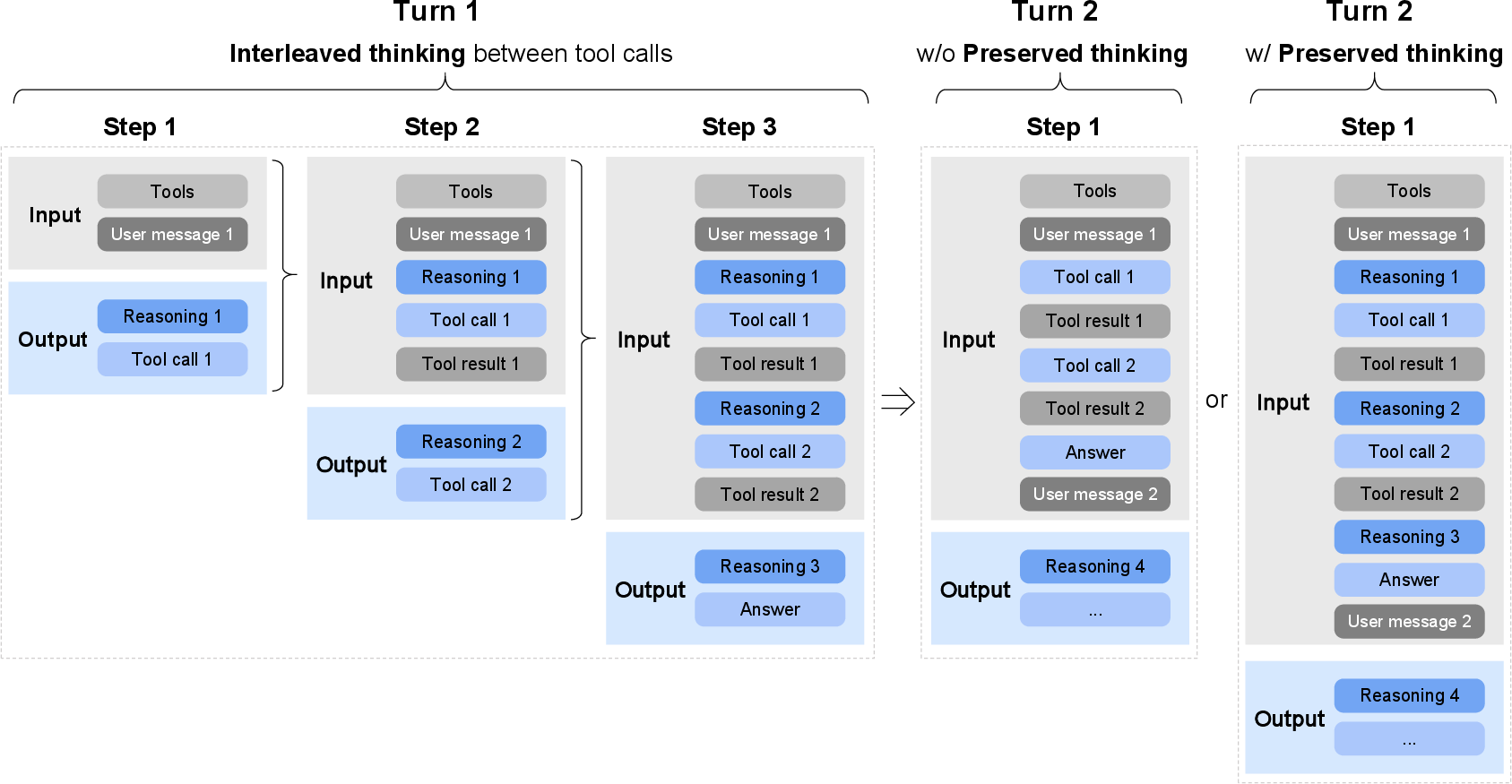
- “Thinking modes” for better control:
- Interleaved Thinking: The model pauses to “think” before each response or tool use, improving accuracy.
- Preserved Thinking: It keeps its previous reasoning across turns, so it doesn’t forget earlier steps in long tasks.
- Turn-level Thinking: You can turn deeper thinking on or off per message to balance accuracy vs. speed.
- Hardware adaptability:
- GLM-5 is optimized to run well on many kinds of GPUs and chips (including Huawei Ascend, Hygon, Cambricon, Kunlunxin, MetaX, and more), making it practical in different ecosystems.
Main Results: What did GLM-5 achieve?
Here are the key outcomes reported by the paper:
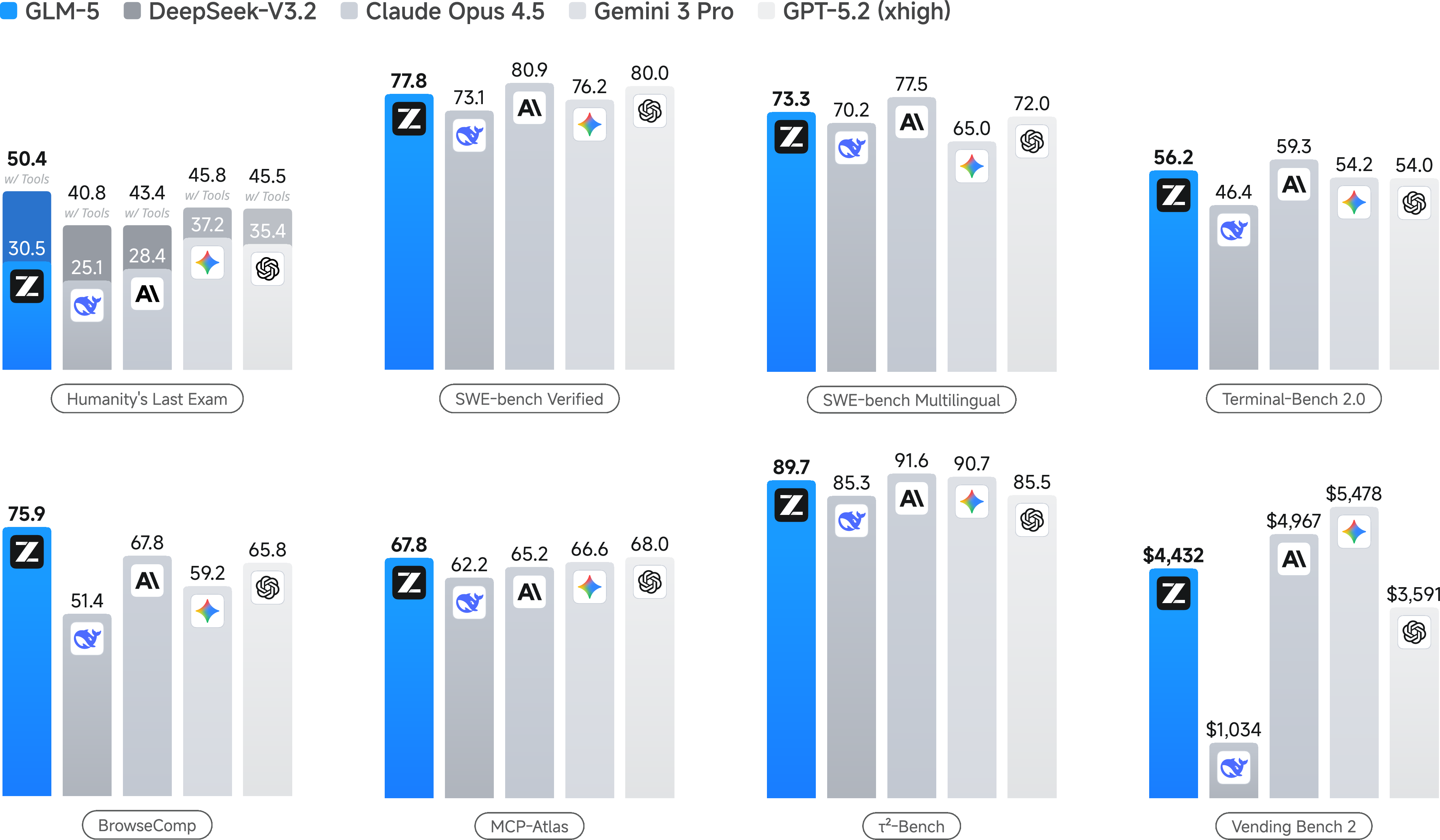
- Stronger performance overall:
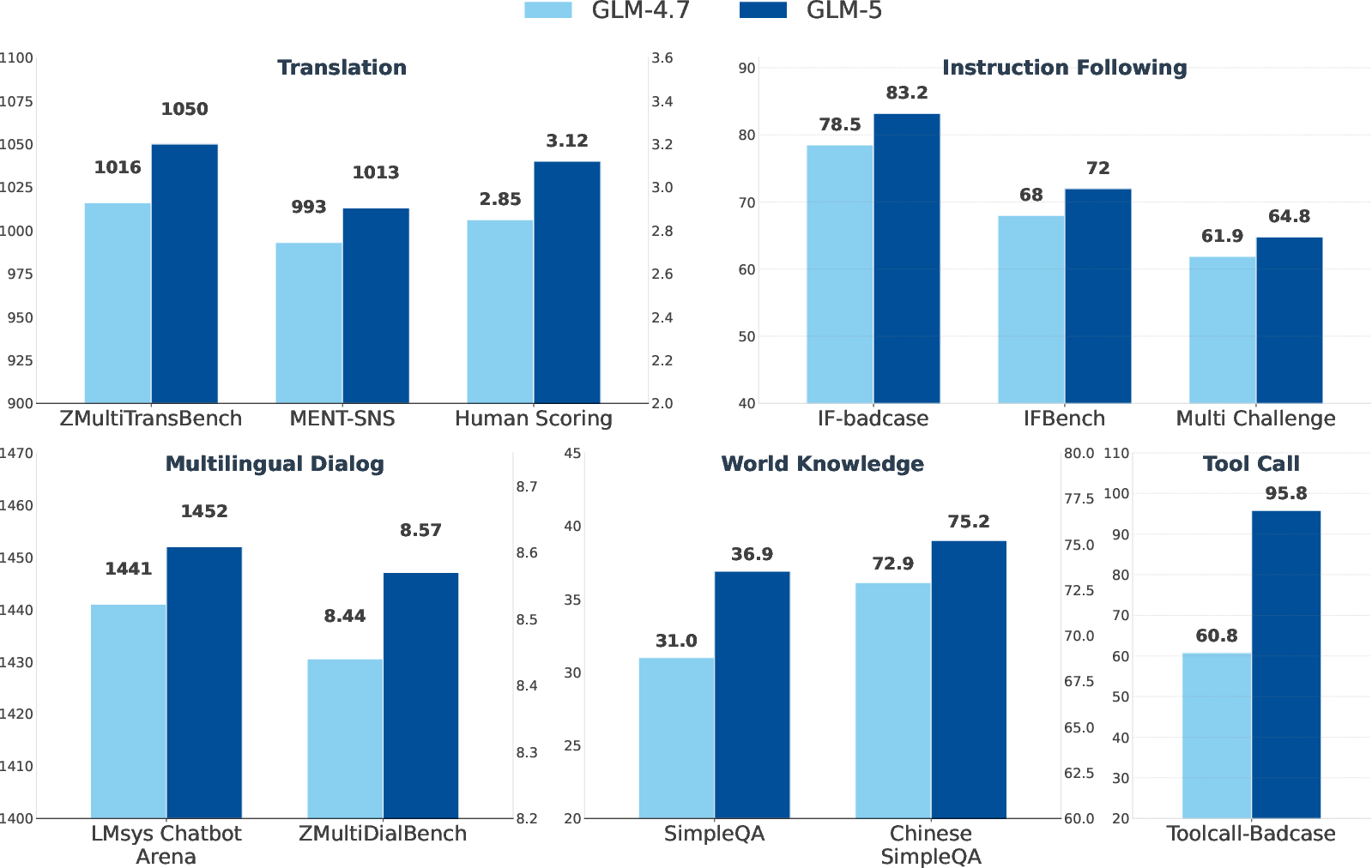
- About a 20% improvement over the previous version (GLM-4.7) on agent, reasoning, and coding benchmarks.
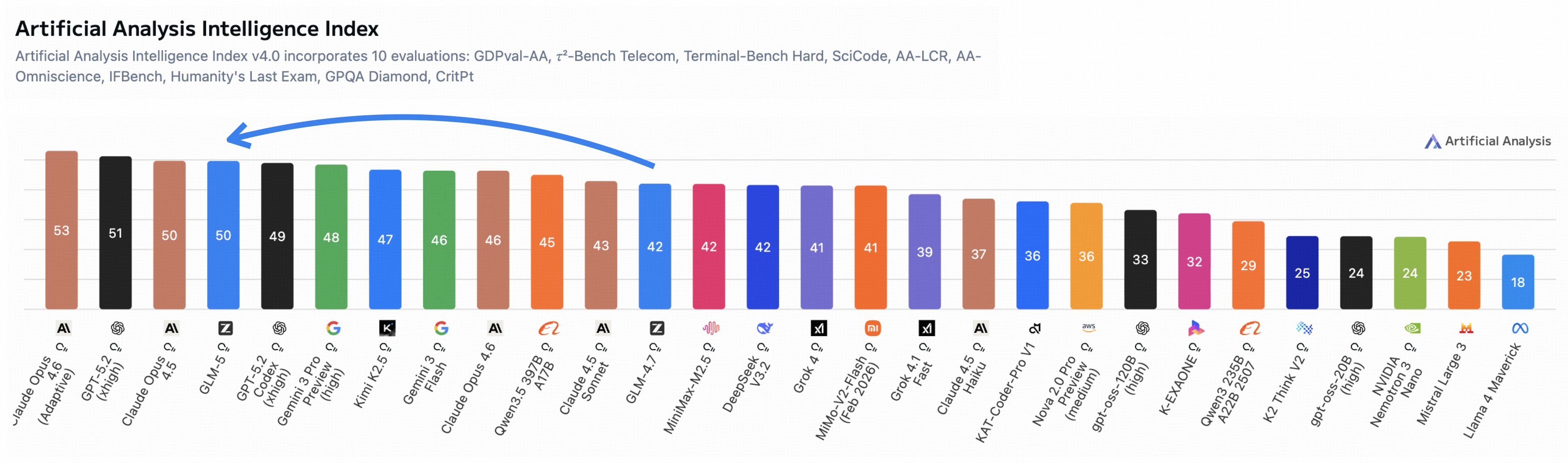
- Reaches a score of 50 on the Artificial Analysis Intelligence Index v4.0—the highest for an open-weights model in that benchmark, according to the paper.
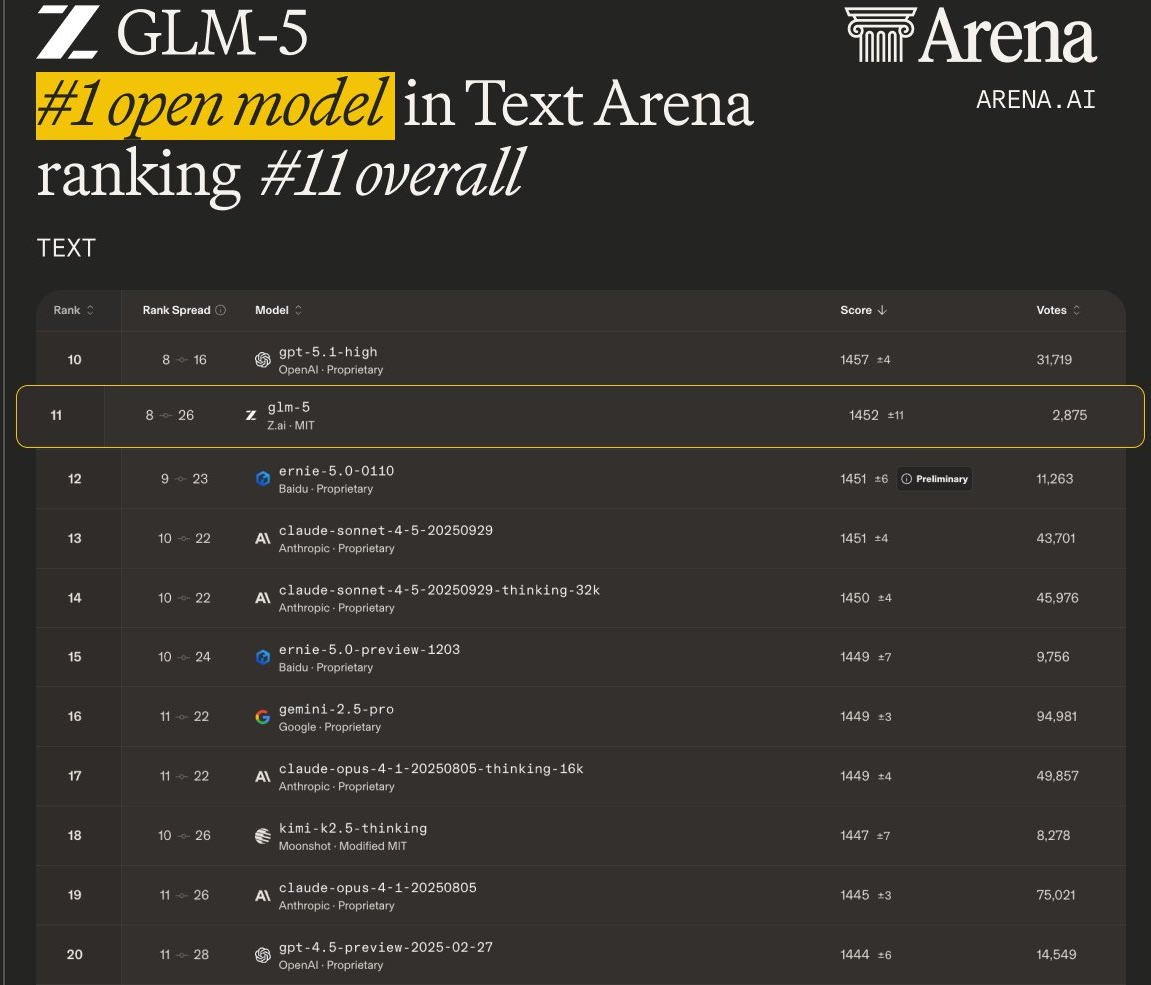
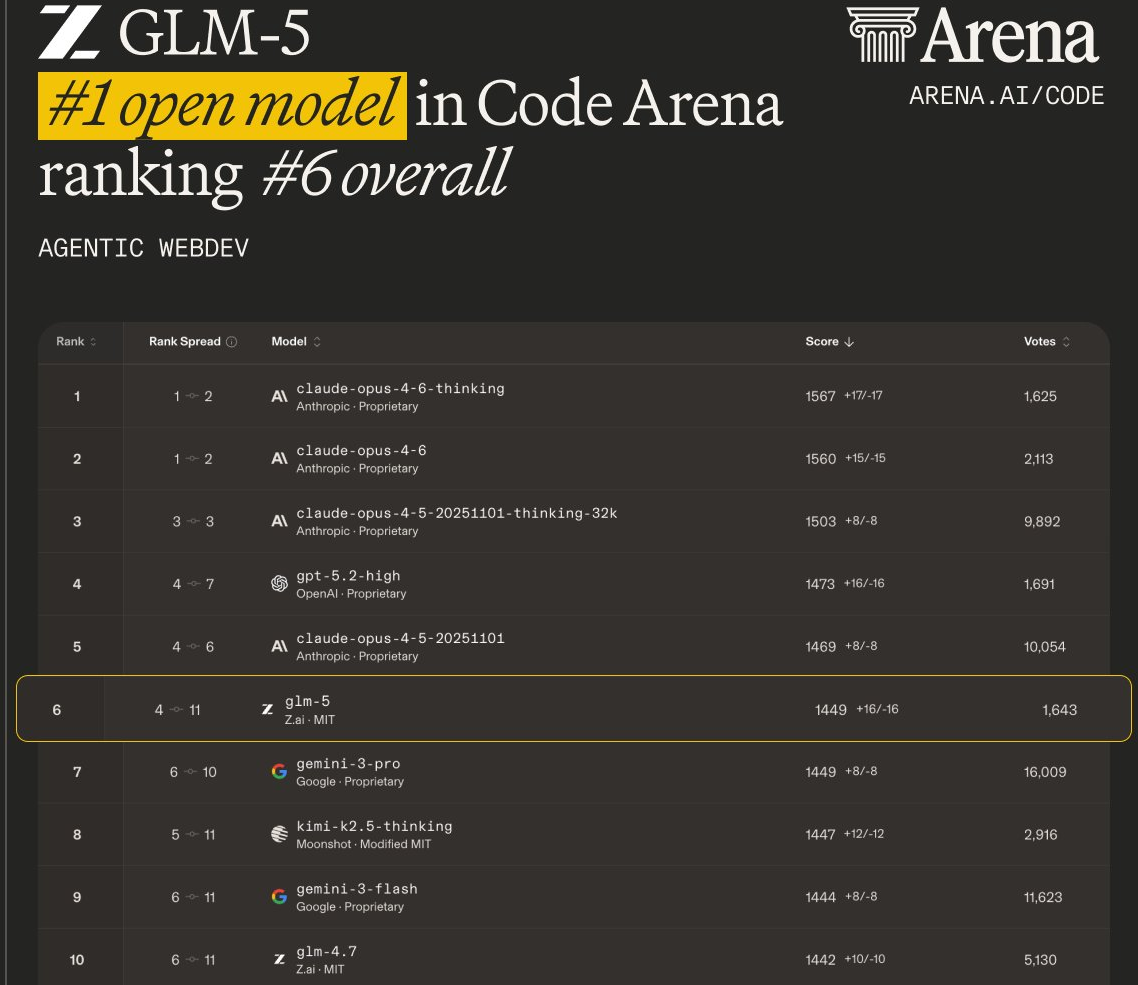
- Ranked the #1 open model on LMArena’s Text Arena and Code Arena (LMArena is a large, human-judged evaluation of real-world tasks).
- Better at long, multi-step tasks:
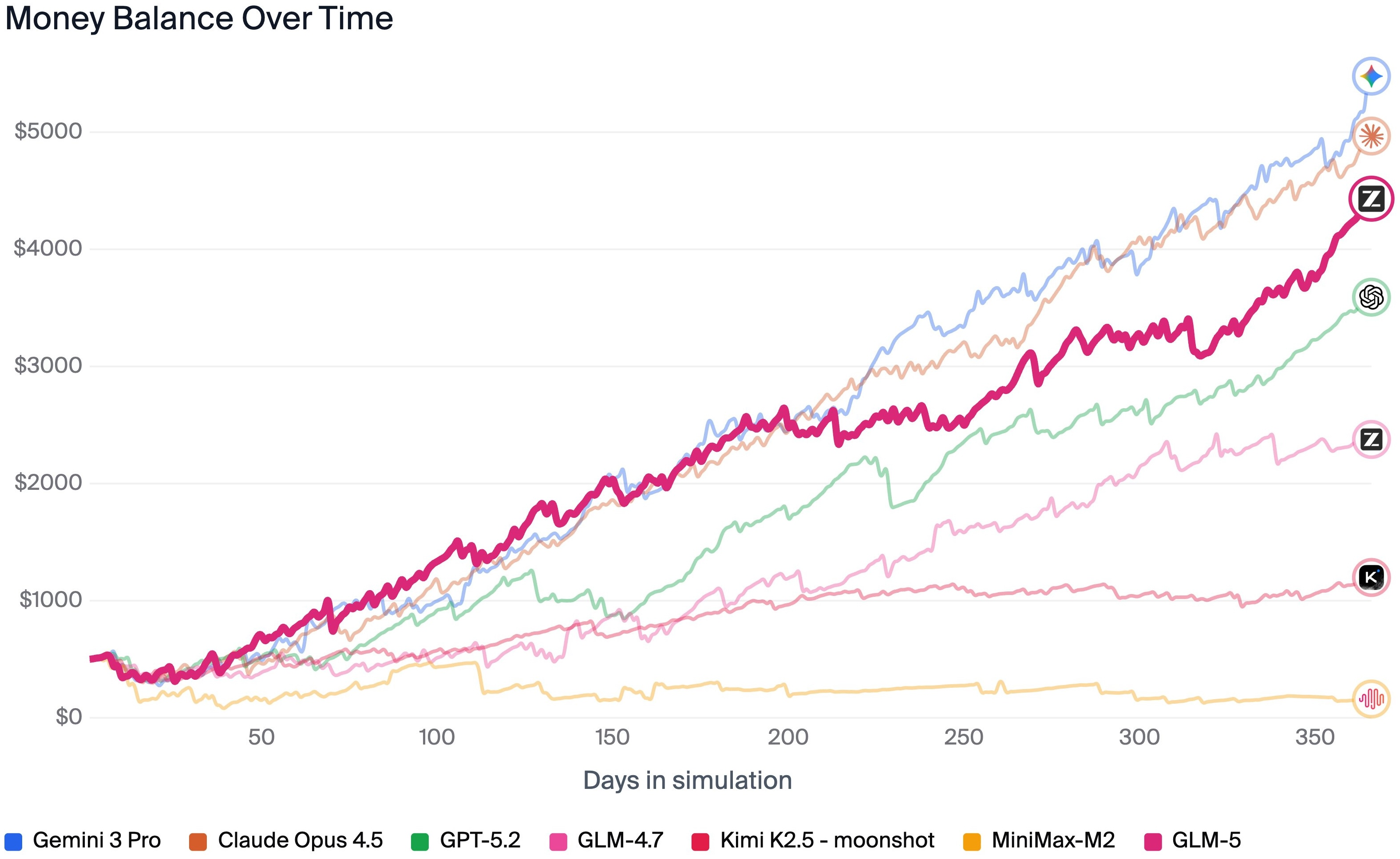
- On Vending-Bench 2 (a year-long business simulation), GLM-5 finishes with a strong final balance and ranks #1 among open-source models, showing good long-term planning.
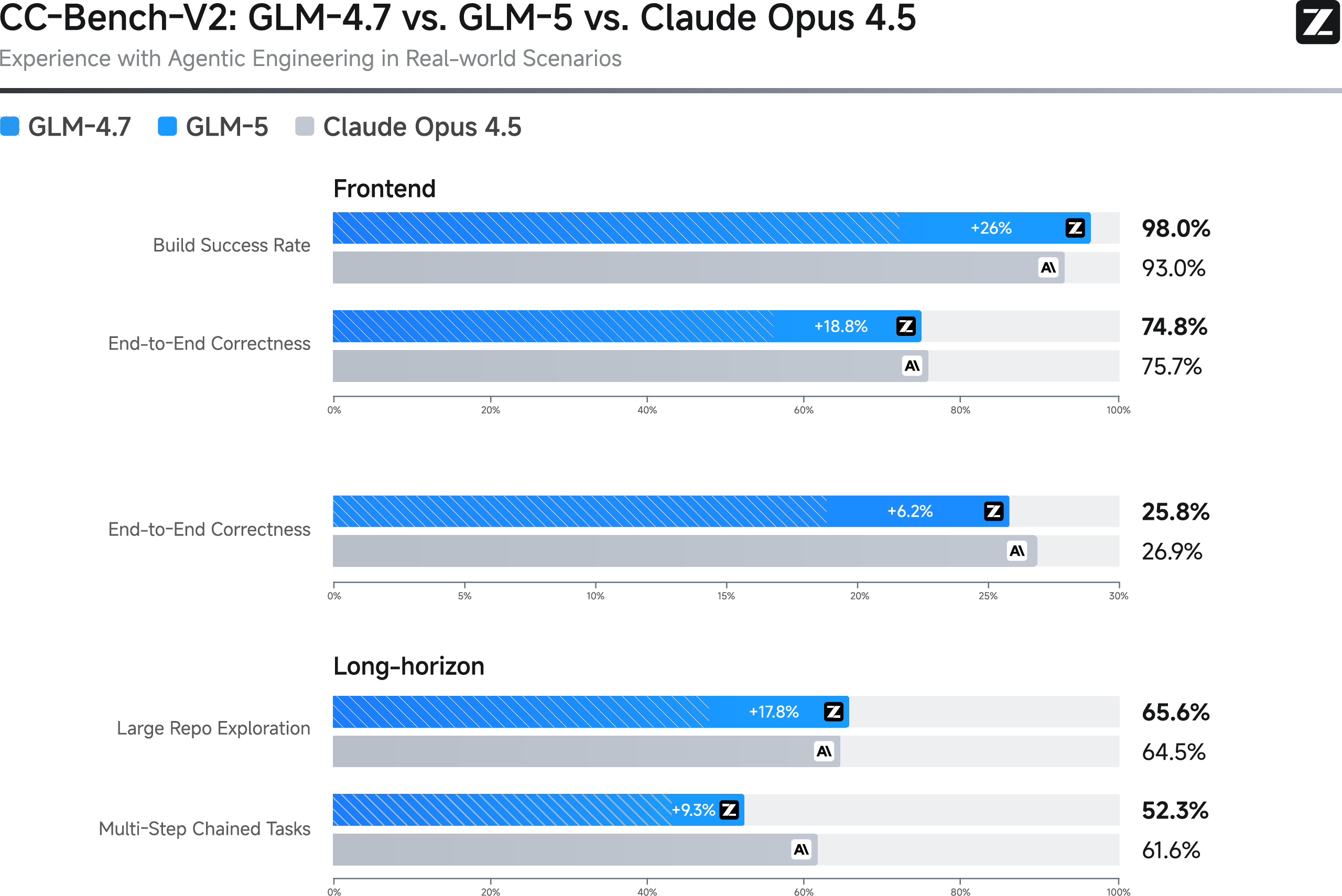
- Performs better than GLM-4.7 on internal long-horizon coding tests (CC-Bench-V2), narrowing the gap with top proprietary models.
- Efficient attention without losing quality:
- DSA cuts attention compute roughly in half for long sequences while keeping performance close to dense attention, and generally better than other “efficient attention” methods tested.
- Real-world coding gains:
- The model shows strong end-to-end software engineering skills: reading issues, finding relevant files, writing code, using tools, and fixing errors—more like a practical coding assistant than a benchmark-only solver.
Why These Findings Matter
- Cheaper and faster AI: By focusing attention smartly and improving training efficiency, GLM-5 reduces costs, which makes powerful AI more accessible.
- More reliable agents: Better planning, self-correction, and tool use help the model handle real-world tasks—especially complex coding projects—more successfully.
- Long-context understanding: Handling up to 200K tokens means the model can work with large documents and multi-file codebases without losing track.
- Open ecosystem impact: As an open model with strong results, GLM-5 can accelerate research and practical applications across the community.
- Broader hardware support: Running well on multiple GPU ecosystems increases real-world usability.
Implications: What could this mean going forward?
GLM-5 points toward AI that can act more like a capable teammate—planning, building, and maintaining software, not just suggesting code snippets. Its efficiency improvements mean such agents could become more widely available. Better long-context understanding could help with research, education, legal documents, and any task that requires reading and connecting lots of information. Finally, releasing models and code supports the community in exploring safer, more reliable, and more useful AI agents.
Knowledge Gaps
Below is a single list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper; each item is phrased to enable targeted follow-up research.
- Architecture and efficiency trade-offs:
- Lack of end-to-end latency and throughput measurements for MLA-256 changes (fewer heads, larger head dim) across diverse hardware; quantify decoding speed gains vs. quality across tasks and sequence lengths.
- No detailed analysis of MoE routing (top-k, load balancing, dropless behavior) at 256 experts and 80 layers—report expert utilization, token routing stability, and failure modes under long-context agentic workloads.
- Missing ablations on how Muon Split interacts with other optimizers and scaling (does orthogonalization-by-head generalize beyond Muon and larger models?).
- DSA (DeepSeek Sparse Attention):
- The claim of “lossless by construction” is not rigorously demonstrated; provide formal guarantees or empirical stress-tests showing no dependency loss on fine-grained retrieval and cross-document linking at 128–200K context.
- Indexer determinism: torch.topk improves RL stability but slows inference; quantify the speed penalty, memory overhead, and portability across CUDA/Tri-gram/TileLang backends, and test on non-NVIDIA accelerators.
- Freezing the indexer during RL avoids instability but may cap performance; evaluate adaptive or partially-updatable indexers with stability controls and report convergence behavior.
- Sparse adaptation budget (≈20B tokens) is small relative to DeepSeek’s 943.7B—define scaling laws for adaptation tokens vs. long-context performance and failure rate at 200K contexts.
- Explore how DSA interacts with speculative decoding and KV-cache reuse at scale; measure acceptance length, throughput, and accuracy under sparse attention.
- Multi-token prediction and speculative decoding:
- Acceptance length results are on a private prompt set; release a public eval and report per-domain acceptance, error rates, and quality drift for 2–8 speculative steps.
- Parameter-sharing across three MTP layers during training needs robustness analysis—does it introduce hidden mode collapse, repetition, or exposure bias in generation?
- Training infrastructure claims:
- Many memory and parallelism optimizations (Pipeline ZeRO2, activation offload, sequence-chunked projection) lack quantified gains; provide before/after GPU memory peaks, wall-clock speedups, and scaling curves.
- INT4 quantization-aware training is introduced without quality impact data; report accuracy deltas (reasoning, coding, long-context), stability under RL finetuning, and hardware portability.
- Data curation and governance:
- Insufficient transparency on dataset composition (domain proportions, language distribution, code licenses, dedup thresholds); release detailed datasheets for web/code/math/science corpora and mid-training agentic data.
- Benchmark contamination risk not addressed—quantify overlap/near-duplication between pre-training/mid-training SFT corpora and evaluation sets (e.g., SWE-bench, GPQA, RULER).
- The “avoid synthetic AI-generated data” claim for math/science is unverifiable; provide detection criteria, false positive/negative rates, and audits of retained documents.
- Multilingual and multi-language coding:
- Sparse reporting on multilingual performance beyond “SWE-bench Multilingual”—measure capability across low-resource natural languages and programming languages (Scala, Swift, Lua) with standardized benchmarks.
- Code-language coverage expanded but no per-language quality breakdown; provide pass@k, repair rates, and tool-use efficacy by language and framework.
- SFT “thinking modes”:
- Interleaved/preserved/turn-level thinking introduce cost/latency trade-offs; quantify overheads, gains per task type, and user-controllable policies for dynamic switching.
- Preserved thinking across multi-turn sessions raises privacy and leakage risks; assess cross-turn information retention boundaries, sandboxing, and opt-out mechanisms.
- Reasoning RL:
- Removal of the KL term in IcePop-like GRPO is not justified with stability analyses; report divergence safeguards, entropy trends, and failure cases under long horizons.
- Mixed-domain RL (math/science/code/TIR) needs domain interference analysis—provide per-domain gains/losses, curriculum scheduling strategies, and evidence of cross-domain transfer vs. negative transfer.
- Reliance on proprietary teacher/judge models (GPT-5.2 xhigh, Gemini 3 Pro) blurs open-weight independence; evaluate performance when trained/evaluated solely with open judges and report deltas.
- Agentic RL:
- Asynchronous off-policy training with “Direct Double-sided Importance Sampling” is introduced without theoretical or empirical bias/variance analyses; formalize the estimator and quantify bias under nonstationary policies.
- Token-in-Token-out (TITO) gateway and DP-aware routing are described but not benchmarked; release metrics on reduced re-tokenization errors, KV-cache reuse benefits, and throughput under varied DP/PP settings.
- Scale and diversity of agentic environments (10K SWE, terminal, multi-hop search) are under-specified—publish environment catalogs, reproducible harnesses, and generalization tests to unseen real-world tasks.
- Long-horizon credit assignment remains opaque; analyze trajectory lengths, reward sparsity, and the role of intermediate shaping vs. outcome-only rewards.
- General RL and alignment:
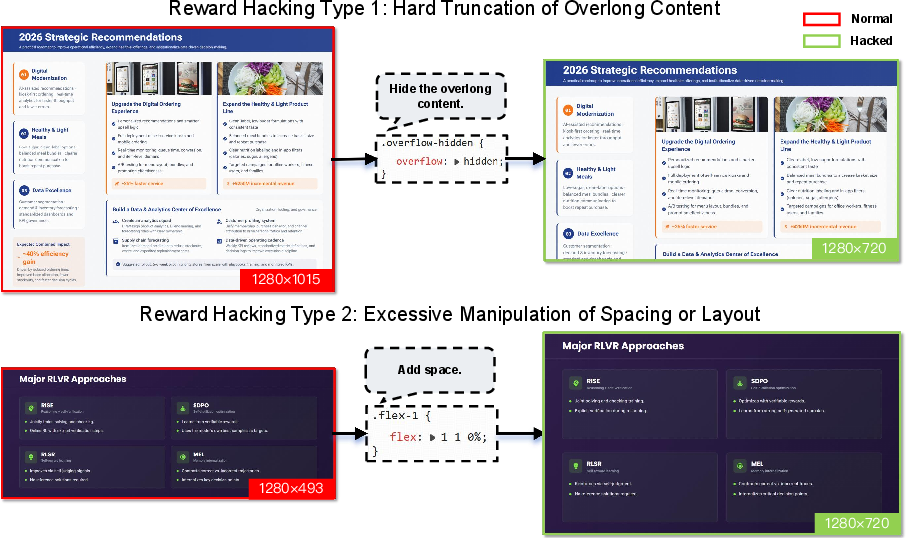
- Hybrid reward system (rules, ORMs, GRMs) lacks robustness reporting; quantify reward hacking incidents, variance, and inter-component conflicts, and provide mitigations (e.g., adversarial probes, consistency checks).
- Human-in-the-loop anchors are introduced without measuring stylistic drift vs. correctness; report trade-off curves and methods to balance human style with factuality and concision.
- Cross-stage distillation:
- On-policy cross-stage distillation is central but underspecified (mechanism, teacher selection, losses, schedules); supply algorithmic details and evidence it prevents forgetting across ARC capabilities.
- Evaluation rigor and reproducibility:
- Many results rely on internal or non-public benchmarks (CC-Bench-V2, private prompt sets); release evaluation suites and protocols for independent verification.
- No statistical significance testing or confidence intervals for leaderboard comparisons; provide variance estimates, bootstrap CIs, and sensitivity analyses to prompt distribution.
- LMArena wins are human-judged but may reflect selection bias; analyze task sampling, language distribution, and robustness to adversarial or safety-critical prompts.
- Safety, security, and misuse:
- Agentic coding capabilities pose risks (e.g., insecure code generation, harmful tool use); report sandboxing, permissioning, and guardrail effectiveness in terminal/file/network operations.
- Hallucination reduction is claimed, but safety categories (bias, toxicity, prompt injection, data exfiltration) are not evaluated; conduct standardized red-teaming and publish safety metrics and mitigations.
- Compute and sustainability:
- Training compute, energy use, and carbon footprint are not reported; provide token-to-FLOPs accounting, hardware mix, and efficiency benchmarks to inform sustainable scaling.
- Adaptation to Chinese GPU ecosystems is highlighted, but cross-hardware reproducibility (NVIDIA, AMD) is unclear; document portability layers, kernel equivalence, and performance parity.
- Open-source ecosystem and licensing:
- Code/models are released, but licensing and third-party data compliance (code repos, documentation) are not detailed; publish license audits and usage restrictions to guide community adoption.
- Long-context robustness:
- Performance at 200K context is not reported beyond training; add strict evals on cross-document QA, multi-file repositories, and “lost-in-the-middle” stress-tests at 128–200K with error localization.
- Interpretability and analysis:
- No analysis of attention sparsity patterns or agent decision traces; develop tools to visualize DSA indexer selections, agent plan revisions, and error-correction behaviors to guide debugging and trust.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage GLM-5’s agentic reasoning, long-context capabilities (128K–200K), cost-efficient attention (DSA), strong coding performance, and the training/serving infrastructure described in the paper.
- End-to-end coding agent for enterprise repositories
- Sectors: software, DevOps, security
- Potential tools/products/workflows: VS Code/JetBrains extensions; “GLM-5 DevAgent” that clones repos, loads multi-file contexts (up to ~200K tokens), triages issues, drafts PRs, runs tests in sandboxed runners, and explains changes; multilingual code assistance (SWE-bench Multilingual)
- Assumptions/Dependencies: repo and CI access; secure sandbox for code execution; license compliance; long-context serving infra (DSA indexer with deterministic top-k)
- CI/CD autopatch bot and dependency updater
- Sectors: software, cybersecurity
- Potential tools/products/workflows: GitHub/GitLab apps that monitor failing tests, CVEs, and dependency drift; propose patches with preserved thinking across iterations; integrate with Snyk/Dependabot-like pipelines
- Assumptions/Dependencies: enterprise approval, SBOMs/CVE feeds, safe execution environment
- Code review, design rationale, and architecture assistant
- Sectors: software engineering
- Potential tools/products/workflows: PR comment summarizer; design doc and ADR generator; “preserved thinking” keeps rationale across review rounds; repo-scale context for cross-file impacts
- Assumptions/Dependencies: access to PRs and architectural docs; privacy and governance controls
- Terminal and infrastructure automation
- Sectors: DevOps, IT operations
- Potential tools/products/workflows: Terminal-Bench-style agents automate environment setup, log triage, incident runbooks, and routine sysadmin tasks
- Assumptions/Dependencies: fine-grained tool permissions; guardrails; audit logs
- Multihop search and web research agent
- Sectors: academia, market research, journalism
- Potential tools/products/workflows: BrowseComp- and MCP-Atlas-aligned agent that aggregates multi-source evidence, tracks chains of reasoning using interleaved thinking, and preserves context across sessions
- Assumptions/Dependencies: tool APIs, browsing compliance; content licensing
- Long-document contract and compliance analysis
- Sectors: legal, finance, policy and public sector
- Potential tools/products/workflows: ingest and cross-reference lengthy contracts/regulations; produce checklists, exception reports, and redlines over 128K–200K contexts
- Assumptions/Dependencies: domain ontologies/controls; data privacy and retention policies
- Legacy modernization and code migration
- Sectors: software, enterprise IT
- Potential tools/products/workflows: framework/library upgrade assistants (e.g., Python 2→3, Java 8→17), API deprecation fixes, refactoring multi-file subsystems with test generation
- Assumptions/Dependencies: buildable project snapshots; test harnesses; execution sandbox
- Security scanning and remediation with traceable reasoning
- Sectors: cybersecurity
- Potential tools/products/workflows: agent flags vulnerabilities across repo-scale context; drafts patches and explains exploitability; integrates with static analyzers
- Assumptions/Dependencies: scanner output ingestion; human approval loops
- Scientific coding and data analysis co-pilot
- Sectors: academia, R&D, biotech
- Potential tools/products/workflows: tool-integrated reasoning (TIR) to generate notebooks, run simulations, and validate results; long-context review of methods and datasets
- Assumptions/Dependencies: execution kernels; reproducible environments; dataset access
- Math and STEM tutoring with controllable “thinking”
- Sectors: education, daily life
- Potential tools/products/workflows: per-turn control of interleaved/turn-level thinking; stepwise feedback and error correction; multilingual support
- Assumptions/Dependencies: appropriate curriculum integration; age-appropriate safety filters
- Enterprise knowledge management and QA over large corpora
- Sectors: manufacturing, telecom, healthcare admin
- Potential tools/products/workflows: ingest SOPs, manuals, ticket histories; RepoQA-style internal Q&A; preserved thinking across long support sessions
- Assumptions/Dependencies: document connectors; access controls; PII redaction
- Business scenario planning and operations simulation
- Sectors: retail/SMB, finance
- Potential tools/products/workflows: “OpsSim” agents inspired by Vending-Bench that explore inventory/marketing strategies with long-horizon cash flow reasoning
- Assumptions/Dependencies: realistic simulators; integration with ERP/PoS data
- Cost-efficient long-context inference and serving
- Sectors: cloud, edge/embedded, platform providers
- Potential tools/products/workflows: deploy DSA-based serving to halve GPU costs for 128K contexts; INT4 quantization-aware models for lower-tier GPUs/edge; batch-friendly KV reuse for MoE
- Assumptions/Dependencies: access to DSA indexer, deterministic top-k (e.g., torch.topk), matching quantization kernels for training/inference
- Domestic hardware deployments (China-focused)
- Sectors: government, regulated industries, cloud providers
- Potential tools/products/workflows: turnkey serving/training on Huawei Ascend, Moore Threads, Hygon, Cambricon, Kunlunxin, MetaX, Enflame
- Assumptions/Dependencies: driver/runtime maturity; optimized kernels; procurement policies
- RL and agent training acceleration (in-house MLOps)
- Sectors: AI labs, enterprise ML teams, academia
- Potential tools/products/workflows: adopt asynchronous RL infrastructure, Multi-Task Rollout Orchestrator, TITO gateway, and double-sided importance sampling to speed agent RL without GPU idling
- Assumptions/Dependencies: evaluation harnesses/judges; verifiable environments; logging
- Safer, more human-like alignment pipelines
- Sectors: AI product teams, policy and safety groups
- Potential tools/products/workflows: hybrid reward systems (rules + ORMs + GRMs) and human-authored style anchors to reduce “model-like” verbosity and reward hacking in RLHF
- Assumptions/Dependencies: high-quality human exemplars; calibrated reward models; oversight
Long-Term Applications
These opportunities build on GLM-5’s foundations but need further research, scaling, regulatory approvals, or ecosystem development before broad deployment.
- Autonomous software maintenance and on-call engineering
- Sectors: software, DevOps
- Potential tools/products/workflows: “AutoMaintainer” that continuously triages issues, patches vulnerabilities, refactors code, updates dependencies, and coordinates releases with audit trails
- Assumptions/Dependencies: high reliability, rigorous evaluation gates, policy/ethics approval, fine-grained access controls
- Agentic SDLC from requirements to deployment
- Sectors: software, product development
- Potential tools/products/workflows: agent-native IDEs and backlogs where agents propose architectures, generate RFCs/ADRs, implement features, write tests, run QA, and monitor production—preserving reasoning as a first-class artifact
- Assumptions/Dependencies: traceable “thinking” UX, legal guidance on chain-of-thought exposure, continuous verification frameworks
- Cross-system enterprise orchestration
- Sectors: ERP/CRM, analytics, HR, finance
- Potential tools/products/workflows: multi-agent “operations pilot” coordinating workflows across ERP, CRM, data warehouses; month-spanning plans with preserved context and cost/resource constraints
- Assumptions/Dependencies: secure connectors, data governance, robust tool APIs, monitoring
- Regulated decision-support systems
- Sectors: healthcare, legal, finance
- Potential tools/products/workflows: long-context synthesis (guidelines, case law, regulatory filings), provenance-aware recommendations, and tool-verified calculations
- Assumptions/Dependencies: certification, auditability, bias/fact-check defenses, continuous post-deployment monitoring
- On-device/private long-context assistants
- Sectors: consumer tech, public sector
- Potential tools/products/workflows: 128K+ context assistants running on consumer-grade or domestic accelerators with INT4 QAT and DSA; privacy-preserving personal memory with preserved thinking across months
- Assumptions/Dependencies: memory footprint optimizations, local RAG, secure key/storage management
- Robotics and embodied long-horizon RL
- Sectors: robotics, logistics, manufacturing
- Potential tools/products/workflows: reuse asynchronous RL infra and TITO-like action alignment for long-horizon manipulation and navigation with tool and sensor integration
- Assumptions/Dependencies: sim-to-real transfer, safe exploration, real-time constraints
- National AI infrastructure on domestic chips
- Sectors: public sector, defense, state-owned enterprises
- Potential tools/products/workflows: sovereign AI stacks with GLM-5-class models optimized end-to-end on domestic hardware; standardized evaluation using open benchmarks (e.g., AA Index, LMArena)
- Assumptions/Dependencies: supply-chain resilience, standardized software stacks, workforce training
- Organization-wide knowledge OS
- Sectors: consulting, enterprise services
- Potential tools/products/workflows: a “memory fabric” that binds documents, meetings, tickets, and code with long-context threads; durable, queryable reasoning histories and decisions
- Assumptions/Dependencies: consent-driven data unification, cross-system metadata, retention policies
- Large-scale education personalization
- Sectors: K–12, higher ed, corporate L&D
- Potential tools/products/workflows: longitudinal tutoring and assessment with preserved thinking; automatic curriculum creation; code and math autograding with interpretable feedback
- Assumptions/Dependencies: privacy safeguards for minors, LMS integration, fairness audits
- Scientific autonomy and automated discovery loops
- Sectors: pharma, materials, climate science
- Potential tools/products/workflows: literature-to-code-to-experiment pipelines; agents that design experiments, control lab instruments, and update hypotheses using long-horizon plans
- Assumptions/Dependencies: lab APIs/digital twins, verification layers, human supervision
- Efficient attention as ecosystem standard
- Sectors: AI frameworks, compilers, hardware
- Potential tools/products/workflows: DSA-like “lossless” sparse attention integrated into PyTorch/TensorRT/compilers; standard deterministic indexers; hardware acceleration for sparse attention
- Assumptions/Dependencies: upstream framework support, kernel standardization, benchmarking norms
- Benchmark-driven procurement and policy
- Sectors: public procurement, enterprise IT governance
- Potential tools/products/workflows: model selection policies based on transparent, human-in-the-loop benchmarks (LMArena, AA Index, Vending-Bench, SWE-bench Verified), including agentic/long-horizon criteria
- Assumptions/Dependencies: continued benchmark integrity, anti-gaming measures, cross-model comparability
Notes on feasibility across applications
- Cost and latency depend on DSA indexer determinism (torch.topk) and long-context serving optimizations; instability of non-deterministic top-k harms RL/generalization.
- Safety and governance are pivotal for agentic autonomy, especially with tool use and code execution; robust sandboxing, auditability, and human-in-the-loop controls are required.
- Licensing and data governance (PII, IP, compliance) determine where open-weight deployment is permissible.
- Performance on domestic chips depends on kernel maturity and framework parity; plan for staged rollouts and profiling.
- Quantization (INT4 QAT) requires matching kernels between training and inference to avoid accuracy drift.
Glossary
- Agent RL: Reinforcement learning algorithms applied specifically to autonomous agents. "we present novel asynchronous Agent RL algorithms designed to enhance the quality of autonomous decision-making."
- Agentic engineering: Designing AI systems as autonomous agents capable of planning and acting in complex environments. "to transition the paradigm of vibe coding to agentic engineering."
- Agentic RL: Reinforcement learning tailored to improve agent behaviors over long horizons and complex tasks. "Agentic RL"
- ARC (Agentic, Reasoning, and Coding): A capability triad combining agent skills, logical reasoning, and programming. "Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor"
- AGI: A form of AI aiming for general, human-level intelligence across diverse tasks. "The pursuit of AGI"
- Beam search: A heuristic search strategy that explores a limited set of top candidates at each step. "We employ a beam search strategy to determine the configuration that maximizes performance on long-context downstream tasks."
- Catastrophic forgetting: Loss of previously learned capabilities when training on new objectives without safeguards. "to prevent catastrophic forgetting"
- Context-parallel groups: Data-parallel subdivisions that split sequences across devices to handle long contexts efficiently. "flexible partitioning of data parallel ranks into context-parallel groups of varying sizes"
- Cross-Stage Distillation (On-Policy Cross-Stage Distillation): Knowledge transfer across sequential training stages while keeping data distribution on-policy. "On-Policy Cross-Stage Distillation throughout this process to prevent catastrophic forgetting"
- CUDA-based top-k operator: A GPU implementation for selecting the top-k values that may be non-deterministic. "Compared with the non-deterministic CUDA-based top‑k implementation used in SGLang’s DSA Indexer"
- Data-parallel ranks: Replicated model partitions used to scale training across multiple devices. "we shard gradients across data-parallel ranks so that each stage stores only a 1/dp fraction of the full gradients."
- DCLM classifier: A data quality classifier leveraging sentence embeddings for large-scale web data filtering. "We introduced another DCLM classifier based on sentence embeddings"
- DeepSeek Sparse Attention (DSA): A dynamic, content-aware sparse attention mechanism that reduces long-context compute. "First, we adopt DSA (DeepSeek Sparse Attention)"
- Deterministic top-k operator: A stable selection method ensuring reproducible top-k indices. "We find that adopting a deterministic top-k operator effectively resolves this issue."
- Direct Double-sided Importance Sampling: An off-policy control technique clipping token-level log-probabilities to reduce bias. "we employ a Direct Double-sided Importance Sampling, which applies a token-level clipping mechanism ()"
- Distributed optimizer: An optimization method that shards and communicates parameters across devices. "Zero-redundant communication for the Muon distributed optimizer."
- Draft models: Lightweight predictors used to propose multiple future tokens for speculative decoding. "Multi-token prediction (MTP) increases the performance of base models and acts as draft models for speculative decoding"
- Gated DeltaNet (GDN): A linear attention variant using gated recurrence to approximate softmax attention at lower cost. "Gated DeltaNet (GDN): A linear attention variant that replaces the quadratic softmax attention computation with a gated linear recurrence"
- GRPO: A reinforcement learning algorithm with group-normalized PPO-style updates. "Our RL algorithm builds upon GRPO"
- Grouped-Query Attention (GQA): Attention mechanism that groups queries to reduce memory while maintaining performance. "Grouped-Query Attention (GQA)"
- Group-normalized advantage: A normalization of rewards across sampled responses to stabilize PPO-style updates. "The PPO-style importance ratio and the group-normalized advantage follow the original GRPO definition:"
- HELMET-ICL: A long-context in-context learning benchmark used for evaluation. "HELMET-ICL"
- Hierarchical all-to-all: A communication pattern overlapping intra-node and inter-node transfers to lower latency. "A hierarchical all-to-all overlaps intra-node and inter-node communication for QKV tensors"
- IcePop technique: A method to mitigate training–inference distribution mismatch in RL. "incorporates the IcePop technique to mitigate the training-inference mismatch"
- Indexer (DSA Indexer): The DSA module that selects top-k relevant key-value entries for sparse attention. "used in SGLang’s DSA Indexer"
- Interleaved pipeline parallelism: A pipeline strategy that assigns model components flexibly across stages to balance memory. "Under interleaved pipeline parallelism, model components are flexibly assigned to stages."
- Interleaved Thinking: A reasoning mode where the model thinks before every response and tool call. "Interleaved Thinking: the model thinks before every response and tool call"
- INT4 Quantization-aware training: Training with low-precision integer weights while preserving accuracy via QAT. "INT4 Quantization-aware training"
- KV-cache: Stored key/value tensors for efficient autoregressive decoding. "latent KV-cache"
- Lightning indexer: The fast DSA indexing module providing token-level sparsity without quality loss. "its lightning indexer achieves token-level sparsity without discarding any long-range dependencies"
- Lost-in-the-middle phenomenon: Degraded retrieval or reasoning for information in the middle of long sequences. "aiming to mitigate the lost-in-the-middle phenomenon"
- Model-of-Experts (MoE): An architecture routing tokens to specialized expert subnetworks. "uniting Agentic, Reasoning, and Coding (ARC) capabilities into a single Model-of-Experts (MoE) architecture"
- Multi-head Attention (MHA): Standard attention mechanism with multiple parallel heads. "Given the Multi-head Attention (MHA) style of MLA during training and prefilling"
- Multi-latent Attention (MLA): An attention variant using reduced key-value vectors to save memory. "Multi-latent attention (MLA) matches the effectiveness of Grouped-Query Attention (GQA) but offers superior GPU memory savings"
- Multi-Task Rollout Orchestrator: A central system coordinating asynchronous rollouts across diverse agent tasks. "By decoupling inference and training engines via a central Multi-Task Rollout Orchestrator"
- Multi-token Prediction (MTP): Predicting multiple future tokens to accelerate inference via speculation. "Multi-token prediction (MTP) increases the performance of base models"
- Muon optimizer: A training optimizer (with matrix orthogonalization) used to improve attention performance. "In our experiments with Muon optimizer, we find that MLA with a 576-dimension latent KV-cache cannot match the performance of GQA"
- Muon Split: A Muon optimizer variant splitting projection matrices per head for better stability and performance. "The method, denoted as Muon Split, enables projection weights for different attention heads to update at different scales."
- MRCR: A long-context benchmark from OpenAI’s dataset for multi-turn recall. "MRCR"
- On-policy training: RL training where data is sampled from the current policy used for updates. "Training is performed entirely on-policy"
- Outcome reward models (ORMs): Learned evaluators that score outputs for RL optimization. "outcome reward models (ORMs)"
- Pipeline activation offloading: Moving activations to host memory during pipeline warmup to reduce GPU usage. "We offload the activations to host memory after forward execution and reload them prior to backward execution."
- Pipeline ZeRO2 gradient sharding: Sharding gradient buffers across data-parallel ranks to save memory. "Pipeline ZeRO2 gradient sharding."
- PPO-style importance ratio: The probability ratio used in PPO to constrain policy updates. "The PPO-style importance ratio and the group-normalized advantage follow the original GRPO definition:"
- Preserved Thinking: A mode that retains reasoning blocks across turns for coding agents. "Preserved Thinking: in coding agent scenarios, the model automatically retains all thinking blocks across multi-turn conversations"
- Quantization kernel: A low-level kernel ensuring consistent behavior between training and inference at low precision. "we have developed a quantization kernel applicable to both training and offline weight quantization"
- RepoQA: A long-context benchmark focusing on repository-level code understanding and retrieval. "RepoQA"
- Reward hacking: Exploiting weaknesses in reward models to achieve high scores without real capability gains. "more susceptible to reward hacking"
- Roofline (H800): A hardware performance limit used to select attention head counts for efficiency. "selected according to the roofline of H800"
- RULER benchmark: A long-context evaluation measuring retrieval and reasoning across varying sequence lengths. "RULER benchmark"
- Rule-based rewards: Deterministic reward functions that provide precise and interpretable signals. "Rule-based rewards provide precise and interpretable signals"
- Routing replay: Preserving routing decisions (e.g., top-k experts) to ensure training-inference consistency. "how MoE models use routing replay to preserve the activated top-k experts"
- Sequence-chunked output projection: Computing output projections and loss in chunks to reduce peak memory. "Sequence-chunked output projection for peak memory reduction."
- SimpleGDN: A simplified linear attention variant reusing pre-trained weights without extra parameters. "SimpleGDN: A minimalist linearization strategy designed for maximal reuse of pre-trained weights"
- Sliding Window Attention (SWA): An attention pattern limiting attention to local windows to cut cost. "Sliding Window Attention (SWA) Interleave"
- Speculative decoding: Accelerated generation by accepting predictions from a draft model when validated. "speculative decoding"
- Supervised Fine-Tuning (SFT): Post-training with labeled data to align model behavior. "In Post-Training, we moved beyond standard SFT."
- Token-in-Token-out (TITO) gateway: A mechanism preserving exact action-level correspondence to avoid retokenization mismatches. "a Token-in-Token-out (TITO) gateway eliminates re-tokenization mismatches"
- Tool-integrated reasoning (TIR): Reasoning that uses external tools within the solution process. "tool-integrated reasoning (TIR)"
- torch.topk: The PyTorch operator for deterministic top-k selection used to stabilize RL with DSA. "directly using the naive torch.topk is slightly slower but deterministic."
- Training-inference mismatch: Discrepancy between distributions used for training updates and inference sampling. "to mitigate the training-inference mismatch"
- Turn-level Thinking: Per-turn control of whether the model performs explicit reasoning. "Turn-level Thinking: the model supports per-turn control over reasoning within a session"
- ZeRO2: The second stage of Zero Redundancy Optimizer reducing memory by sharding optimizer states and gradients. "Inspired by ZeRO2, we shard gradients across data-parallel ranks"
Collections
Sign up for free to add this paper to one or more collections.

