STATe-of-Thoughts: Structured Action Templates for Tree-of-Thoughts
Abstract: Inference-Time-Compute (ITC) methods like Best-of-N and Tree-of-Thoughts are meant to produce output candidates that are both high-quality and diverse, but their use of high-temperature sampling often fails to achieve meaningful output diversity. Moreover, existing ITC methods offer limited control over how to perform reasoning, which in turn limits their explainability. We present STATe-of-Thoughts (STATe), an interpretable ITC method that searches over high-level reasoning patterns. STATe replaces stochastic sampling with discrete and interpretable textual interventions: a controller selects actions encoding high-level reasoning choices, a generator produces reasoning steps conditioned on those choices, and an evaluator scores candidates to guide search. This structured approach yields three main advantages. First, action-guided textual interventions produce greater response diversity than temperature-based sampling. Second, in a case study on argument generation, STATe's explicit action sequences capture interpretable features that are highly predictive of output quality. Third, estimating the association between performance and action choices allows us to identify promising yet unexplored regions of the action space and steer generation directly toward them. Together, these results establish STATe as a practical framework for generating high-quality, diverse, and interpretable text. Our framework is available at https://github.com/zbambergerNLP/state-of-thoughts.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to guide how AI writes and reasons, called STATe-of-Thoughts (STAT). The main idea is to make AI’s thinking process more structured, controllable, and understandable. Instead of just “turning up the randomness” to get different answers, STAT asks the AI to follow different high-level plans (like choosing a writing style or a theme) and then searches through those plans to find the best results.
What questions does the paper ask?
The authors focus on three simple questions:
- How can we get AI to produce responses that are both high-quality and truly different from each other?
- How can we control the AI’s reasoning in a clear, step-by-step way, instead of letting it make hidden, token-by-token choices?
- Can we learn which reasoning patterns lead to better results, and then steer the AI toward those patterns on purpose?
How does the method work?
Think of AI writing like a “choose-your-own-adventure” story. At each step, the AI can pick a different strategy. STAT organizes this process into three parts:
- Controller: Like a coach choosing a play, it picks high-level “actions” (for example, “use a cause-and-effect structure” or “focus on environmental risks”).
- Generator: Like the player on the field, it writes the next part conditioned on that chosen action. The action is added as a small, explicit instruction at the start of the step, so we know what plan it’s following.
- Evaluator: Like a judge, it scores each step and final answer, helping keep the best paths and drop the weaker ones.
The system explores multiple branches (different action choices) and keeps the top ones, a process called “beam search.” It also supports early stopping, so if a path has already reached a good answer, it doesn’t waste time overthinking.
Two kinds of judges help:
- Process judge: Evaluates the reasoning steps as they unfold (are they coherent, on track?).
- Outcome judge: Evaluates the final answer (is it persuasive, clear, and well-structured?).
Instead of relying on randomness (“temperature”) to create variety, STAT uses discrete action templates—plain-text mini-plans—so we can see and control what changes from one branch to the next.
What did the researchers find, and why is it important?
They ran two main tests:
- Diverse creative outputs (NoveltyBench):
- Goal: Produce multiple responses to the same prompt that are meaningfully different, not just tiny wording changes.
- Result: STAT often produced roughly twice as many distinct answers compared to standard methods that increase randomness.
- Why it matters: If you want different ideas or styles, STAT gives you real diversity without sacrificing quality.
- Persuasive argument generation (case study: banning single-use plastics):
- Goal: See if the sequence of actions (the actual reasoning plan) predicts which arguments are rated as better by an AI judge.
- Result: The order and pattern of actions were highly predictive of argument quality—more than just “which actions appeared.” In other words, not only what you do matters, but when you do it and in what sequence.
- Bonus: By analyzing action patterns tied to good outcomes, they could steer the system toward promising, previously unexplored strategies.
Why these findings matter:
- Diversity: Changing the plan changes the result in meaningful ways—like choosing different recipes, not just sprinkling more salt.
- Interpretability: Because actions are explicit text, you can audit the reasoning plan and understand why an answer turned out a certain way.
- Control: You can aim the system toward strategies that work better, making AI writing more reliable and adaptable.
What’s the impact?
This research shows a practical path to AI that is:
- More controllable: You can pick which high-level reasoning strategies to try.
- More transparent: You can see the exact sequence of actions that led to an answer.
- More diverse: You get genuinely different outputs without just relying on randomness.
- More learnable: By tracking which actions work best, you can improve future generations and target new, promising strategies.
This can help:
- Creative work: Generate varied stories, poems, or ideas tailored to different styles and audiences.
- Persuasion and social science: Study which argument structures and content themes actually influence people, and systematically test them.
- Safer, more reliable AI: Use judges and clear plans to avoid messy or off-track reasoning and to stop overthinking when a good answer is ready.
In short, STAT moves AI from “guess and sample” to “plan and search,” making it easier to produce high-quality, diverse, and understandable text.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what the paper leaves uncertain or unexplored, intended to guide future research.
- Causal inference from action sequences is not established: the paper explicitly focuses on associations due to sequential decision confounding. Methods for causal estimation (e.g., randomized controllers, off-policy correction, inverse propensity weighting, or sequential doubly robust estimators) are needed to determine the effects of actions on outcomes.
- Reliability and calibration of LLM-as-a-Judge evaluators (PRMs/ORMs) are untested: the paper does not quantify evaluator bias, variance, robustness, or susceptibility to reward hacking. Human evaluation and multi-judge aggregation are needed to validate evaluator reliability.
- Generality beyond two tasks is unclear: results are limited to NoveltyBench (mostly depth-1 trees) and a single argument topic (ban single-use plastics). Extend evaluations to more domains (e.g., math, coding, planning), tasks (objective and subjective), and prompts to test robustness.
- Effect of tree depth and multi-step branching on diversity/quality is not studied: NoveltyBench experiments use depth-1 trees; the diversity–quality trade-offs as depth increases and the role of intermediate pruning remain open.
- Automated design and learning of action spaces are not addressed: current action templates (personas, audience, discourse relations, stock-topics) are handcrafted. Investigate methods to learn, adapt, or optimize action spaces (e.g., via meta-learning, program synthesis, or unsupervised discovery).
- Sensitivity to action-space choices and coverage is unknown: the paper does not analyze how outcomes change with different granularity, balance, or completeness of action dimensions; ablations on action-space content are needed.
- Controller policies are heuristic: only generative and reranker controllers are explored. Policy learning (e.g., bandits/RL over the action space, MCTS/UCT, value-guided search) and theoretical guarantees for search efficiency remain open.
- Early stopping (FINISH action) lacks principled criteria: no formal termination condition or learned stopping policy is evaluated. Study termination prediction, overthinking vs premature stopping, and performance impact.
- Synthesis-mode fidelity vs quality trade-offs are not quantified: strict, faithful, restructured, and conclusion synthesis are defined but not systematically compared for faithfulness, coherence, and attribution fidelity. Develop metrics and audits for how well final outputs reflect the action trace.
- Diversity measurement is tied to NoveltyBench’s classifier: reliance on a single functional-equivalence classifier raises questions about external validity. Compare against human diversity judgments and alternative semantic metrics (e.g., embedding clustering, task-specific novelty).
- Judge dependence and evaluator–generator interaction are not analyzed: how outcomes change with different evaluators (models, prompts) and whether generators overfit to judges (reward hacking) is untested.
- Computational cost and scaling trade-offs are undercharacterized: STAT uses multiple GPUs (generator + reranker). Provide latency, throughput, and cost analyses as branching factor, beam width, depth, and action-space size scale.
- Cross-model generalization is partial: tests cover specific open-source families (Qwen3, Nemotron-3, Ministral-3). Broader coverage (e.g., different architectures, proprietary models) and explanations for cases where baselines outperform STAT are needed.
- Cross-language and cultural generalization are unknown: experiments are in English with assumed audiences; evaluate multilingual settings and culturally diverse contexts to assess action-space portability.
- Robustness to prompt injection or prefix conflicts is unexamined: prefix-based interventions may interact with user prompts, system prompts, or model safety filters in unintended ways. Analyze failure modes and develop guardrails.
- Verifiable evaluators are not integrated in complex tasks: while programmatic verifiers are mentioned, applications beyond simple checks (e.g., mathematical proofs, code correctness) are not presented. Demonstrate verifiable PRMs/ORMs where feasible.
- Attribution fidelity is assumed, not verified: the paper presumes that action sequences map onto final outputs, especially under strict synthesis. Empirically validate attribution (e.g., with faithfulness checks, edit-distance to action-derived content).
- Feature-space limitations in sequential models: only bi-gram within-dimension transitions are explored; cross-dimension transitions, higher-order n-grams, or sequence models (HMMs, CRFs, neural sequence encoders) may capture richer patterns.
- Sample efficiency and generalization of attribution models are unclear: LASSO-based associations are trained on one topic. Test transfer to new topics/audiences and quantify sample requirements for reliable feature selection.
- Length and stylistic confounds persist: although a length ablation is noted in the appendix, comprehensive controls (style, formality, tone) are needed to isolate the effect of action choices on quality.
- Safety and ethics of persuasive generation are not deeply addressed: study misuse risks (e.g., manipulation, targeted persuasion), develop constraints in action spaces, and integrate safety evaluators.
- Interaction with latent feature steering is not compared: the benefits/trade-offs of explicit prefixes vs latent interventions (activation steering, concept vectors) remain unexplored.
- Hyperparameter sensitivity is unreported: systematic sweeps for temperature, beam width, branching factor, and depth—and their interactions with action guidance—are needed to map performance landscapes.
- Theoretical explanation for diversity gains is missing: provide formal or empirical analyses (e.g., coverage of action-induced subspaces, reduced correlation across branches) to explain why discrete actions outperform temperature sampling.
- Real-world outcome validation for argument quality is absent: LLM-judge rankings are proxies; measure human persuasion effectiveness (e.g., user studies, field experiments) to validate practical impact.
- Open-source reproducibility details are partial: prompts and action templates are in appendices, but reliance on proprietary judges (e.g., GPT-5-mini) and pending patent raise barriers. Provide fully open evaluation pipelines and alternatives.
Practical Applications
Overview
Below are actionable, real-world applications that follow directly from the paper’s findings and methods on STATe-of-Thoughts (STAT): an interpretable, controller-driven framework for inference-time compute that uses structured action templates, tree search, LLM-as-a-Judge evaluators, early stopping, and logged action traces to deliver diverse, high-quality, and auditable text generation. Applications are grouped into Immediate and Long-Term, and each lists relevant sectors, potential tools/products/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
These can be deployed now using existing LLMs, STAT’s open-source framework, and standard MLOps stacks.
- Industry — Marketing and Content Studios (Advertising, Software)
- Use case: Generate diverse ad copy, landing-page variants, product descriptions, and social posts with controlled tone, audience targeting, and rhetorical structure for A/B testing.
- Tools/workflows: Plan→Generate→Evaluate→Select; action spaces for tone/persona/audience; beam search with reranker controller; ORM selection; action-trace logging for audits.
- Assumptions/dependencies: Quality of LLM-as-a-Judge correlates with business metrics; domain-specific action templates are curated; access to GPU for generator + reranker; respect brand and legal guidelines.
- Industry — Creative Writing Platforms (Media/Entertainment, Software)
- Use case: Produce diverse story outlines, character arcs, and plot variants while maintaining coherence and style; personalize outputs to reader preferences.
- Tools/workflows: Structured action spaces for plot devices and narrative discourse; synthesis modes (faithful/restructured) to balance attribution and quality; beam search for diverse options.
- Assumptions/dependencies: IP/copyright considerations; model choice affects style quality; user-in-the-loop selection.
- Industry — Customer Support and UX Writing (Software, Consumer Services)
- Use case: Draft support replies with structured patterns (apology→solution→reassurance), adjust reading level, and prune low-quality branches with process evaluators.
- Tools/workflows: PRM scoring for intermediate steps; early FINISH action to cut “overthinking”; deterministic verifiers for schema adherence and tone guidelines.
- Assumptions/dependencies: Integration with CRM; guardrails for misinformation; human review on sensitive cases.
- Policy and Public Sector — Transparent Policy Briefs and Advocacy Messaging
- Use case: Generate persuasive but auditable arguments for public communication (e.g., environmental policy) with explicit action traces and strict synthesis for transparency.
- Tools/workflows: Strict synthesis to preserve traceability; action logs for audits; ORM tuned to persuasiveness + readability; beam selection to avoid biased branches.
- Assumptions/dependencies: Ethical constraints to avoid manipulative content; external validation beyond LLM judges; public disclosure norms.
- Education — Writing Tutors and Rhetoric Scaffolding
- Use case: Teach discourse relations, argument composition, and topic development; provide feedback based on logged action sequences; generate diverse essay exemplars.
- Tools/workflows: Action spaces aligned to curricula; PRM for formative feedback; faithful synthesis to preserve structure while allowing rephrasing.
- Assumptions/dependencies: Academic integrity safeguards; teacher oversight; adaptation to age/reading level.
- Academia — Experimental Social Science on Persuasion and Style
- Use case: Run controlled studies varying rhetorical structures and content themes; attribute outcomes to action sequences; identify effective patterns via LASSO.
- Tools/workflows: Library of action templates (content + structure); pairwise evaluation with Bradley–Terry ranking; statistical attribution on logged trajectories.
- Assumptions/dependencies: LLM-judge biases monitored; IRB/ethics approvals; supplement with human evaluation.
- Industry/Regulated Domains — Explainable Content Pipelines (Finance, Legal, Healthcare Communications)
- Use case: Produce traceable memos, disclosures, and patient-facing materials with auditable reasoning steps and verifiable adherence to style/compliance rules.
- Tools/workflows: Strict/faithful synthesis modes; deterministic verifiers (schema, citations, readability); action-trace audit trail.
- Assumptions/dependencies: Not for clinical/legal decision-making; compliance sign-off; model calibration to domain language.
- Software Engineering — Structured Text Artifacts
- Use case: Generate test plans, changelogs, risk registers, and design rationales with controlled structure; verify format and coverage deterministically.
- Tools/workflows: Programmatic evaluators to enforce templates; early stopping to reduce compute; reranker evaluators to pick the most relevant variant.
- Assumptions/dependencies: Scope limited to textual artifacts; integration with CI/CD and documentation systems.
- Product Management — Structured Brainstorming and Scenario Generation
- Use case: Produce diverse product ideas and scenario narratives using persona + audience action spaces; select high-utility variants for ideation workshops.
- Tools/workflows: Depth-1 wide branching for fast diversity; ORM tuned to novelty/usefulness; action library for market segments and tone.
- Assumptions/dependencies: Utility metrics aligned with team goals; human curation; avoid homogenization from single evaluator.
- Daily Life — Personal Writing Assistant (Email, Resume, Social Posts)
- Use case: Draft messages with explicit control over tone (e.g., confident, empathetic), structure (e.g., request→context→call-to-action), and audience (e.g., recruiter, friend).
- Tools/workflows: Lightweight action templates; simple beam search; early FINISH for brevity; on-device or private deployments where feasible.
- Assumptions/dependencies: Privacy protections; user selects actions; default guardrails to prevent inappropriate persuasion.
Long-Term Applications
These require further research, scaling, rigorous validation, standardization, or integration into high-stakes workflows.
- High-Stakes Decision Support with Certified Verifiers (Healthcare, Legal, Finance)
- Vision: Domain-specific action spaces and deterministic/verifiable PRMs/ORMs (e.g., guideline adherence, risk communication standards) to support expert workflows.
- Tools/workflows: Programmatic evaluators with formal checks; strict synthesis for auditable trace; human-in-the-loop review with sign-off.
- Assumptions/dependencies: Regulatory approval; comprehensive domain validation; clear liability and governance; not a replacement for experts.
- Causal Optimization of Action Policies (Academia, Software Platforms)
- Vision: Move beyond association to learn causally optimal action sequences via randomized experiments and reinforcement learning with verifiable rewards.
- Tools/workflows: Closed-loop A/B testing; PRM/ORM optimization; policy learning over action spaces; safety and ethics guardrails.
- Assumptions/dependencies: Large-scale data; robust counterfactual designs; fairness monitoring; compute budgets.
- Standardized Action-Space Taxonomies and Tooling Ecosystem
- Vision: Shared libraries, editors, and marketplaces for action templates (e.g., rhetorical structures, domain schemas) with versioning and interoperability.
- Tools/workflows: Authoring tools; validation suites; community-curated repositories; integration SDKs.
- Assumptions/dependencies: Consensus across stakeholders; licensing and patent considerations; maintenance and governance.
- Multi-Agent Structured Reasoning and Collaboration (Software, Robotics Planning)
- Vision: Agents coordinate via explicit action templates and shared traces, enabling compositional team-of-thought workflows and auditable decision trails.
- Tools/workflows: Cross-agent action protocol; reranker-mediated coordination; joint beam search; verifiable handoffs.
- Assumptions/dependencies: Robust coordination interfaces; safety under adversarial actions; scalability.
- Participatory Policy Platforms and Democratic Deliberation
- Vision: Public-facing systems that generate multiple transparent perspectives with action traces, enabling citizens to audit reasoning and compare alternatives.
- Tools/workflows: Strict synthesis for traceability; pluralistic action libraries; user feedback loops; moderation.
- Assumptions/dependencies: Safeguards against manipulation; inclusivity and fairness; civic oversight.
- Cross-Modal Action Templates (Media/Design)
- Vision: Extend action-space control to images, audio, and video (e.g., narrative beats, visual styles) for diverse but coherent multimodal outputs.
- Tools/workflows: Multimodal generators with prefix-like interventions; evaluators for coherence and utility; synthesis across modalities.
- Assumptions/dependencies: Availability of robust multimodal models; design of interpretable interventions; evaluation benchmarks.
- Private/Edge Deployments and Cost-Aware Reasoning
- Vision: Optimize STAT for on-device or private-cloud use by leveraging early stopping, efficient rerankers, and parallelization (e.g., vLLM).
- Tools/workflows: Resource-aware controller; adaptive beam width; caching; secure logging of action traces.
- Assumptions/dependencies: Hardware constraints; privacy-by-design; latency requirements.
- Safety and Persuasion Governance Frameworks
- Vision: Standards for permissible action templates, auditing practices, and disclosures for persuasive generation in commercial and civic contexts.
- Tools/workflows: Policy registries; automated compliance checks; third-party audits; certification schemes.
- Assumptions/dependencies: Multi-stakeholder standards; regulatory buy-in; continuous monitoring.
- Scientific Writing and Peer Review Assistance (Academia)
- Vision: Structured authoring for methods/results sections with action templates; evaluators for reporting completeness, clarity, and citation compliance.
- Tools/workflows: Domain-specific actions (e.g., experimental design, limitations); deterministic verifiers; audit logs for transparency.
- Assumptions/dependencies: Field-specific standards; avoidance of bias or ghostwriting concerns; editorial policies.
- Scenario Planning and Risk Narratives (Finance, Energy, Supply Chain)
- Vision: Generate diverse, causally-structured scenario narratives with clear action traces; select high-quality variants with verifiers for consistency and coverage.
- Tools/workflows: Action spaces for causal/contrastive discourse; ORM tuned to clarity and decision relevance; integration with risk dashboards.
- Assumptions/dependencies: Domain-tailored evaluators; human validation; linkage to quantitative models.
Cross-Cutting Assumptions and Dependencies
- Model and evaluator reliability: LLM-as-a-Judge and reranker scores can be biased; domains may require deterministic or domain-verified checks.
- Action-space design: Utility depends on well-crafted, domain-relevant templates; maintenance and versioning are essential.
- Compute and infrastructure: Parallelized tree search (e.g., vLLM), access to generator + reranker models, and logging pipelines are needed.
- Ethics and compliance: Persuasion use cases require guardrails, disclosures, and adherence to regulatory and institutional standards.
- Patent and licensing: The framework is subject to a pending patent; commercial use may require licensing or legal review.
Glossary
- Action-guided textual interventions: Discrete, controllable text prefixes that steer generation along high-level reasoning choices to induce meaningful diversity. "action-guided textual interventions produce greater response diversity than temperature-based sampling."
- Action space: The set of possible controllable actions (and their argument values) the controller can choose from during search. "identify promising yet unexplored regions of the action space"
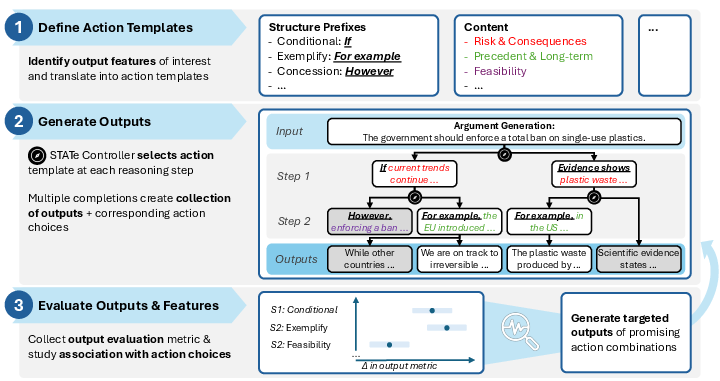
- Action templates: Predefined, structured choices that encode high-level reasoning decisions (e.g., structure or content) and are executed as textual interventions. "Define action templates that control output features of interest, such as structural prefixes and content themes."
- Action traces: Logged sequences of selected actions along a trajectory, enabling analysis of which decisions relate to outcomes. "uses action traces to predict output quality"
- Attribution framework: An analysis approach that relates logged action choices to downstream performance to identify effective patterns. "An attribution framework that uses action traces to predict output quality, identify promising unexplored regions of the action space, and steer generation toward them."
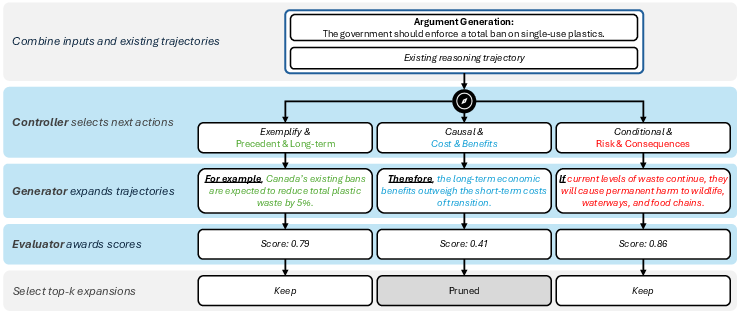
- Beam search: A heuristic search that expands multiple candidate states and retains the top-scoring subset at each step. "An evaluator scores both intermediate and final states to guide beam search"
- Beam width: The number of states kept per layer in beam search. "branching factor , beam width , maximum depth , temperature temp"
- Best-of-N: An inference-time method that samples N independent outputs and selects the best according to a scoring criterion. "Inference-Time-Compute (ITC) methods like Best-of-N and Tree-of-Thoughts are meant to produce output candidates that are both high-quality and diverse"
- Big Five model: A personality framework (OCEAN) used to define persona-based action dimensions. "The first dimension, personality traits, follows the Big Five model"
- Bradley-Terry (BT) model: A pairwise-comparison model used to infer latent quality ranks from judge preferences. "We then fit a Bradley-Terry (BT) model to these judgments and use the resulting standardized ranks as the outcome variable "
- Branching: Sampling more than one completion at a step to explore multiple reasoning paths in parallel. "When sampling more than one completion from an LLM, we refer to this operation as branching"
- Branching factor: The number of actions/children explored per state in tree or beam search. "branching factor , beam width , maximum depth , temperature temp"
- Chain-of-Thought (CoT): A prompting approach that elicits intermediate reasoning steps before the final answer. "Chain-of-Thought (CoT) reasoning scales depth by enabling models to generate intermediate reasoning steps before arriving at a final answer."
- Conclusion synthesis: A synthesis mode that uses the trace as internal guidance without constraints on the final output. "Conclusion synthesis treats the trace as internal guidance only, with no constraints on the final output."
- Controller: The component that selects which actions to take from the current state, guiding exploration. "a controller selects actions encoding high-level reasoning choices"
- DeBERTa-v3-large: A transformer model used here as a classifier for grouping generations into equivalence classes. "using a fine-tuned DeBERTa-v3-large classifier"
- Deterministic verifier: A non-generative, programmatic evaluator that checks verifiable criteria. "and a deterministic verifier"
- Discourse-relations: Structured relations (e.g., contrast, cause) used as action dimensions to control argument structure. "we operationalize content interventions as stock-topics to discuss, and structure interventions as discourse-relations to use"
- DSPy: A framework of modular prompting and programmatic orchestration for LLM pipelines. "STAT's components correspond to DSPy Modules"
- Early stopping: A mechanism that terminates reasoning when sufficient progress has been made to prevent overthinking. "Additionally, we introduce early stopping."
- Evaluator: The component that scores intermediate states or final outputs to guide pruning and selection. "an evaluator scores candidates to guide search."
- Faithful synthesis: A mode that rephrases the trace while preserving its order and structure. "Faithful synthesis permits rephrasing while preserving order and structure."
- Functional equivalence classes: Groups of outputs that provide similar user value, used to measure semantic diversity. "which are then partitioned into functional equivalence classes"
- Generator: The component that produces reasoning steps or final answers, conditioned on selected actions. "a generator produces reasoning steps conditioned on those choices"
- Hallucinations: Fabricated or incorrect outputs produced by an LLM, a common failure mode. "limited robustness to common failure modes such as hallucinations"
- Inference-Time-Compute (ITC): Methods that allocate extra tokens and parallel attempts at generation to improve quality and robustness. "Inference-Time-Compute (ITC) methods like Best-of-N and Tree-of-Thoughts are meant to produce output candidates that are both high-quality and diverse"
- LASSO regression: A regularized linear model that performs feature selection via L1 penalty to avoid overfitting. "We address these issues using LASSO regression"
- LLM-as-a-Judge: Using an LLM to score or compare candidates against a rubric as a proxy evaluator. "To evaluate intermediate and final reasoning steps, ToT methods use LLM-as-a-Judge"
- Mean Distinct: A diversity metric counting unique functional equivalence classes among generations. "Mean Distinct counts the number of unique equivalence classes across the 10 generations, quantifying semantic diversity."
- Mean Utility: A benchmark metric assessing the average value or quality of generated outputs. "NoveltyBench also includes a Mean Utility metric"
- NoveltyBench: A benchmark that tests whether methods increase diversity without collapsing quality. "NoveltyBench measures whether methods can increase diversity without collapsing quality."
- Outcome Reward Model (ORM): A scorer of final outputs that maps an answer to a quality score. "Outcome Reward Models (ORMs) are defined as ."
- Prefill: Injecting fixed text at the start of the next generation to bias the model’s continuation. "We append these to the LLM's assistant message as a prefill"
- Process Reward Model (PRM): A scorer of intermediate reasoning chains to enable early pruning. "Process Reward Models (PRMs) ... are defined as "
- Pruning: Removing unpromising branches during search based on evaluator scores. "branching on intermediate thoughts and pruning less-promising reasoning trajectories."
- ReAct: A tool-use prompting paradigm that alternates reasoning and tool execution. "This mirrors the iterative tool-use paradigm in ReAct"
- Reasoning breadth: Parallel attempts or branches that increase robustness across diverse strategies. "permit parallel reasoning attempts (reasoning breadth"
- Reasoning depth: Additional tokens or steps devoted to reasoning before answering. "provide LLMs with additional 'reasoning' tokens (reasoning depth"
- Reranker LLM: A model that assigns relevance scores to candidates to select among alternatives. "uses a reranker LLM to pick among all possible tool calls"
- Restructured synthesis: A mode that freely reorganizes the trace, using it as source material. "Restructured synthesis allows free reorganization using the trace as source material."
- Self-Consistency: A method that samples multiple CoT paths and selects answers via majority voting. "Self-Consistency addresses CoT's brittleness by sampling multiple CoT reasoning paths"
- Strict synthesis: A mode that concatenates reasoning steps with minimal connective text. "Strict synthesis concatenates reasoning steps verbatim with minimal connectives."
- Sycophancy: A failure mode where the model agrees excessively with perceived user preferences. "sycophancy"
- Temperature-based sampling: Adjusting sampling randomness (temperature) to induce diversity at the token level. "these methods rely primarily on temperature-based sampling for diversity"
- Tool call: Treating each action selection as invoking a tool with named arguments to produce an intervention. "We treat each action as a tool call."
- Tree of Thoughts (ToT): A search framework over partial thoughts with branching and pruning to improve reasoning. "Tree of Thoughts (ToT) combines both strategies: scaling depth through multi-step reasoning ... and scaling breadth through branching at intermediate points"
- vLLM: A system for efficient, parallelized LLM inference used to scale calls across nodes. "we parallelize LLM calls ... with vLLM"
- Verifiable rewards: Evaluators that check deterministic criteria (e.g., programmatically verifiable success) rather than subjective rubrics. "using either score-based LLM-as-a-Judge models ... or verifiable rewards"
Collections
Sign up for free to add this paper to one or more collections.