Tree of Thoughts: Deliberate Problem Solving with Large Language Models
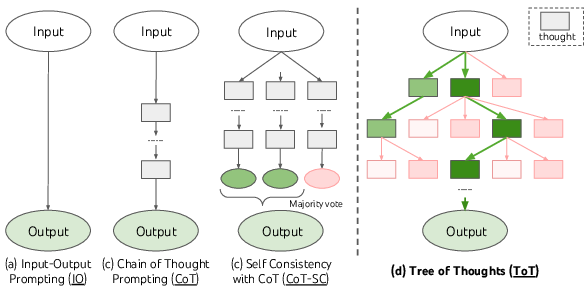
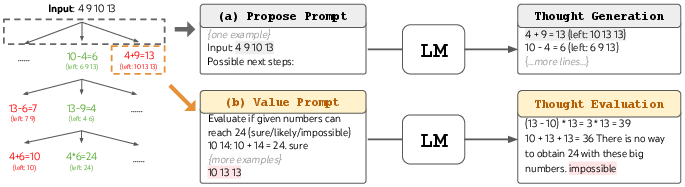
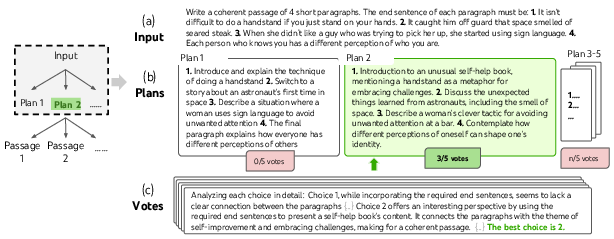
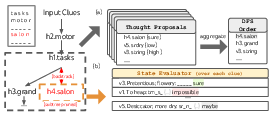
Abstract: LLMs are increasingly being deployed for general problem solving across a wide range of tasks, but are still confined to token-level, left-to-right decision-making processes during inference. This means they can fall short in tasks that require exploration, strategic lookahead, or where initial decisions play a pivotal role. To surmount these challenges, we introduce a new framework for LLM inference, Tree of Thoughts (ToT), which generalizes over the popular Chain of Thought approach to prompting LLMs, and enables exploration over coherent units of text (thoughts) that serve as intermediate steps toward problem solving. ToT allows LMs to perform deliberate decision making by considering multiple different reasoning paths and self-evaluating choices to decide the next course of action, as well as looking ahead or backtracking when necessary to make global choices. Our experiments show that ToT significantly enhances LLMs' problem-solving abilities on three novel tasks requiring non-trivial planning or search: Game of 24, Creative Writing, and Mini Crosswords. For instance, in Game of 24, while GPT-4 with chain-of-thought prompting only solved 4% of tasks, our method achieved a success rate of 74%. Code repo with all prompts: https://github.com/princeton-nlp/tree-of-thought-LLM.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- A survey of monte carlo tree search methods. IEEE Transactions on Computational Intelligence and AI in Games, 4:1–43, 2012.
- Deep blue. Artificial intelligence, 134(1-2):57–83, 2002.
- Teaching large language models to self-debug, 2023.
- Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- A. Creswell and M. Shanahan. Faithful reasoning using large language models. arXiv preprint arXiv:2208.14271, 2022.
- Uncertainty-based competition between prefrontal and dorsolateral striatal systems for behavioral control. Nature neuroscience, 8(12):1704–1711, 2005.
- Pal: Program-aided language models, 2023.
- Reasoning with language model is planning with world model. arXiv preprint arXiv:2305.14992, 2023.
- A formal basis for the heuristic determination of minimum cost paths. IEEE Transactions on Systems Science and Cybernetics, 4(2):100–107, 1968a. doi: 10.1109/TSSC.1968.300136.
- A formal basis for the heuristic determination of minimum cost paths. IEEE transactions on Systems Science and Cybernetics, 4(2):100–107, 1968b.
- Language models as zero-shot planners: Extracting actionable knowledge for embodied agents, 2022a.
- Inner monologue: Embodied reasoning through planning with language models. arXiv preprint arXiv:2207.05608, 2022b.
- Maieutic prompting: Logically consistent reasoning with recursive explanations. arXiv preprint arXiv:2205.11822, 2022.
- D. Kahneman. Thinking, fast and slow. Macmillan, 2011.
- Representativeness revisited: Attribute substitution in intuitive judgment. Heuristics and biases: The psychology of intuitive judgment, 49(49-81):74, 2002.
- Language models can solve computer tasks, 2023.
- Llm+p: Empowering large language models with optimal planning proficiency, 2023.
- Neurologic a*esque decoding: Constrained text generation with lookahead heuristics. In North American Chapter of the Association for Computational Linguistics, 2021.
- Self-refine: Iterative refinement with self-feedback, 2023.
- Report on a general problem solving program. In IFIP congress, volume 256, page 64. Pittsburgh, PA, 1959.
- Human problem solving. Prentice-Hall, 1972.
- OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023.
- Refiner: Reasoning feedback on intermediate representations, 2023.
- Improving language understanding by generative pre-training. OpenAI blog, 2018.
- Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Large language model programs, 2023.
- Reflexion: an autonomous agent with dynamic memory and self-reflection, 2023.
- Mastering the game of go without human knowledge. nature, 550(7676):354–359, 2017.
- S. A. Sloman. The empirical case for two systems of reasoning. Psychological bulletin, 119(1):3, 1996.
- K. E. Stanovich. Who is rational? Studies of individual differences in reasoning. Psychology Press, 1999.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Chai: A chatbot ai for task-oriented dialogue with offline reinforcement learning. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4471–4491, 2022.
- Automated crossword solving. arXiv preprint arXiv:2205.09665, 2022.
- Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models, 2023a.
- Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022.
- Describe, explain, plan and select: Interactive planning with large language models enables open-world multi-task agents, 2023b.
- Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903, 2022.
- Decomposition enhances reasoning via self-evaluation guided decoding, 2023.
- Foundation models for decision making: Problems, methods, and opportunities, 2023.
- ReAct: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022.
- Planning with large language models for code generation. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=Lr8cOOtYbfL.
- Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625, 2022.
- Solving math word problem via cooperative reasoning induced language models. arXiv preprint arXiv:2210.16257, 2022.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.