When to Think and When to Look: Uncertainty-Guided Lookback
Abstract: Test-time thinking (that is, generating explicit intermediate reasoning chains) is known to boost performance in LLMs and has recently shown strong gains for large vision LLMs (LVLMs). However, despite these promising results, there is still no systematic analysis of how thinking actually affects visual reasoning. We provide the first such analysis with a large scale, controlled comparison of thinking for LVLMs, evaluating ten variants from the InternVL3.5 and Qwen3-VL families on MMMU-val under generous token budgets and multi pass decoding. We show that more thinking is not always better; long chains often yield long wrong trajectories that ignore the image and underperform the same models run in standard instruct mode. A deeper analysis reveals that certain short lookback phrases, which explicitly refer back to the image, are strongly enriched in successful trajectories and correlate with better visual grounding. Building on this insight, we propose uncertainty guided lookback, a training free decoding strategy that combines an uncertainty signal with adaptive lookback prompts and breadth search. Our method improves overall MMMU performance, delivers the largest gains in categories where standard thinking is weak, and outperforms several strong decoding baselines, setting a new state of the art under fixed model families and token budgets. We further show that this decoding strategy generalizes, yielding consistent improvements on five additional benchmarks, including two broad multimodal suites and math focused visual reasoning datasets.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of “When to Think and When to Look: Uncertainty-Guided Lookback”
What is this paper about?
This paper studies how AI models that understand both pictures and text (called “vision–LLMs,” or VLMs) should reason when answering questions about images. The authors ask a simple but important question: when should a model spend time “thinking” step-by-step, and when should it stop and “look” back at the image to avoid making things up?
What were the main questions?
The researchers focused on three easy-to-understand questions:
- When does step-by-step thinking actually help on image-based questions?
- Is it better to try more short answers (breadth) or to write longer, detailed thoughts (depth)?
- Can we guide a model to look back at the image when it seems unsure, instead of always thinking more?
How did they study it?
Think of the model like a student taking a test with pictures:
- The “student” can write out long reasoning steps (called “chain-of-thought”) or give a short answer.
- The student can also try several times per question, like getting multiple attempts.
Here’s how the researchers tested things:
- Big exam, many subjects: They used a tough test called MMMU, which covers 30+ subjects (like physics, biology, history, etc.), plus five other benchmarks (including math-heavy ones).
- Several “students”: They evaluated 10 versions of two top open-source model families (InternVL3.5 and Qwen3-VL), from small to large.
- Multiple attempts: For each question, they sometimes let the model try many times (like letting a student submit up to 10 attempts) to see how accuracy changes.
- Word budgets: They gave the models generous room to write, so the results wouldn’t be affected by answers being cut off.
Key idea explained with an analogy:
- Perplexity as “surprise meter”: The team measured how much the actual image helps the model feel less “surprised” about what to write next. If the real image makes the next words much easier to predict than a nonsense image, that means the model is truly using the picture.
- “Lookback phrases”: They found short phrases like “Looking back at the image…” that often appear before correct answers. These phrases act like reminders to actually check the picture.
What they built (no retraining needed):
- Uncertainty-guided lookback: A smart, training-free way of decoding answers that watches for signs the model is drifting or unsure (for example, using filler phrases like “hmm” or “wait”). When that happens, the system inserts a short “look back at the image” prompt to refocus on the picture. In some cases, it briefly explores a few alternative, more image-grounded continuations in parallel and picks the best one. Think of it as a GPS that says, “You might be off—recheck the map,” before you take a wrong turn.
What did they find, and why does it matter?
Here are the main takeaways, explained simply:
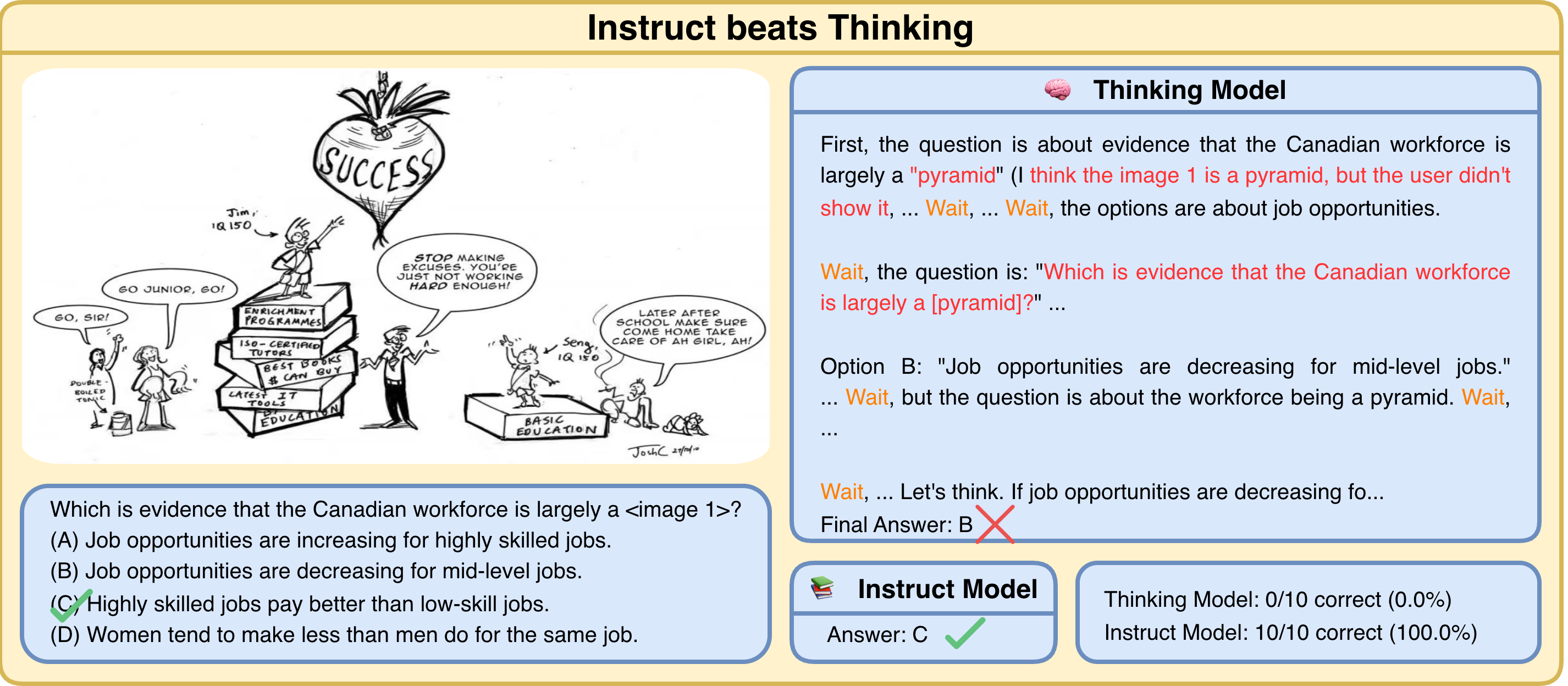
- More thinking isn’t always better. Long reasoning can lead to “long-wrong” answers that ignore the image. Sometimes a short, clear answer is better.
- Trying a few times helps a lot early on. Letting the model try multiple short answers quickly boosts accuracy, especially for smaller models, but the gains level off after a point.
- The benefits of thinking depend on the subject. For problem-solving fields like math, physics, or engineering, step-by-step thinking often helps. For recognition-heavy areas (like art identification or history questions based on the image), long chains can add noise.
- “Look back at the image” moments are key. Short lookback phrases strongly correlate with correct answers because they anchor the model’s reasoning to what’s actually in the picture.
- Their method boosts accuracy while often using fewer words. The uncertainty-guided lookback approach:
- Improved scores on MMMU (a broad benchmark),
- Worked well on five more benchmarks (including math-focused tests),
- Helped the most where regular thinking was weak,
- Often cut down the number of tokens (words/pieces) used, saving time and cost.
Why it matters:
- This approach sets a new state of the art for these model families under the same compute limits. It’s a practical, low-cost way to make models both smarter and more efficient at visual reasoning.
What are the bigger implications?
- Smarter use of compute: Instead of always thinking more (which is slow and expensive), models can think only when needed and look back at the image when they’re unsure. That means faster, cheaper, and more accurate visual assistants.
- Better grounding, fewer make-believe answers: By nudging the model to recheck the picture, we reduce “hallucinations” (made-up details) and improve trustworthiness.
- Easy to adopt: Because this is a decoding strategy (how the model generates words), it doesn’t require retraining the model. It can be plugged into existing systems right away.
- Guidance for future design: The paper shows when to invest in detailed reasoning and when to keep things short, helping developers build better workflows for AI that sees and thinks.
In short
The paper shows that “thinking more” isn’t a silver bullet for image-based questions. Instead, the best results come from knowing when to think deeply and when to look back at the picture. Their simple, training-free method watches for uncertainty and inserts quick “lookback” prompts at the right moments—leading to stronger, more reliable answers across many tests.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to be actionable for future research.
- Generalization beyond two model families: The study focuses on Qwen3-VL and InternVL3.5; it remains unknown whether uncertainty-guided lookback transfers to other LVLMs (e.g., LLaVA, Idefics, Gemini/GPT-4V-class models) and different visual encoders/connectors.
- Reliance on “thinking mode”: The controller is designed for models with explicit thinking traces; it is unclear how well the approach works for instruct-only LVLMs or models that do not expose a formal thinking token.
- Token budget realism: Experiments use very large output-token budgets (16k–32k). The benefits and trade-offs under realistic, latency-constrained budgets (e.g., 512–2k tokens) are not established.
- Breadth–depth auto-allocation: While the paper analyzes breadth vs depth, it does not propose or evaluate an automatic policy that optimally allocates passes and reasoning length per instance within a fixed compute budget.
- Probe design robustness: The token-level probe uses synthetic noise and “no image” controls; the stability of the Δpresence/Δcontent signals under alternative controls (e.g., distractor real images, blurred/cropped originals, varied noise types) is not validated.
- Confounds from vision token presence: The Δpresence measure may conflate generic visual-token presence with positional encoding and connector artifacts; an ablation isolating these factors is missing.
- Phrase mining portability: Lookback/pause phrases are mined on MMMUval; it is unclear how portable the vocabulary is across domains, datasets, and languages, or how often re-mining is required to retain gains.
- False-trigger analysis: The work does not quantify the false-positive and false-negative rates of the pause-phrase detector, nor the impact of mis-triggers on accuracy and token usage.
- Sensitivity to controller hyperparameters: There is no systematic ablation of key knobs (e.g., suffix length L, trigger cooldown, horizon H, number of branches M, phrase list size) on accuracy, latency, and stability.
- When lookback hurts: Although occasional harms are noted, there is no category-wise or difficulty-wise analysis isolating failure modes caused by lookback (e.g., distraction on recognition-heavy tasks).
- Visual grounding metrics: Improvements are reported in accuracy, but objective grounding metrics (e.g., pointing/attention alignment, localization success, rationale-image consistency) are not measured to confirm better image use.
- Faithfulness of reasoning: The paper highlights long-wrong vs quiet-wrong, but does not evaluate whether inserted lookbacks yield more faithful, causally linked rationales rather than post hoc justifications.
- Category coverage gaps: Results emphasize MMMU and math benchmarks; broader evaluation on OCR-heavy, chart/diagram reasoning, dense text-in-image, medical imaging, and embodied/3D tasks is absent.
- Multi-image/video scenarios: The controller is not studied in multi-image or video contexts; how to trigger and route lookbacks across frames or multiple visuals remains open.
- Multilingual robustness: Phrase-based triggers are English-centric; performance and adaptation strategies for multilingual prompts and diverse scripts are untested.
- Instructional and dialog settings: The method is not evaluated in interactive, multi-turn dialogue or tool-augmented settings (e.g., retrieval, calculators), where uncertainty and lookback dynamics differ.
- Comparison to vision-specific CoT tools: The approach is not compared against visual scratchpad methods (e.g., drawing/sketchpad, diagram edits) under equal compute budgets to assess relative gains and trade-offs.
- Attention/representation signals: Alternative drift signals (e.g., image-token attention concentration, cross-modal similarity, connector-feature entropy) are not explored as potential triggers instead of lexical cues.
- Early-exit synergy: The interaction between lookback and early-exit policies (from DEER/DeepConf/REFRAIN) is not systematically characterized; a combined controller could further optimize compute.
- Training-time integration: It remains unknown whether fine-tuning with lookback templates or RL from the uncertainty signal improves performance beyond decoding-only control.
- Distribution shift robustness: The stability of gains under domain shift, adversarial visuals, noisy annotations, or prompt paraphrases is not assessed.
- Safety and misuse: The effect of lookback prompts on susceptibility to prompt injection, jailbreaks, or hallucinations in safety-critical contexts is unstudied.
- Cost accounting and throughput: While appendices mention compute, a rigorous wall-clock, memory, and throughput analysis across hardware profiles and batch sizes is missing for deployment planning.
- Per-instance compute routing: The paper does not propose a learned or heuristic policy to choose between instruct vs thinking vs lookback vs parallel sampling per instance given a target SLA.
- Effect of image resolution/tokenization: The dependence of gains on image resolution, tiling, token merging, and visual token counts is not disentangled; an encoder-level ablation is needed.
- Connector architecture impact: The controller’s effectiveness across different connectors (MLP vs DeepStack) is not deeply analyzed; connector-specific tuning may be required.
- Pass@k practicality: Many results rely on multiple passes (up to 10); guidance on choosing k under real-time constraints and the marginal benefit curve per category is lacking.
- Test set choice: The phrase mining and analyses rely on MMMUval; evaluating on held-out test sets without phrase re-mining would better quantify potential overfitting.
- Open-source reproducibility: Details on releasing mined phrase lists, probe code, and evaluation seeds/configs are limited; full reproducibility materials would enable independent validation.
- Formalization of failure taxonomy: “Long-wrong” vs “quiet-wrong” is described qualitatively; a formal, detectable taxonomy with metrics would enable algorithmic routing and benchmarking.
Practical Applications
Overview
This paper shows that “more thinking” (long chain-of-thought decoding) is not uniformly beneficial for large vision–LLMs (LVLMs). The authors provide a capacity- and category-aware analysis of breadth (sampling) vs. depth (reasoning) and introduce a training-free decoding controller—uncertainty-guided lookback—that detects drift in reasoning and inserts short, image-focused “lookback” phrases. The controller is model-agnostic, stream-compatible, and improves accuracy across six benchmarks while cutting token usage by roughly 35–45%. These findings directly inform how to build more compute-efficient, visually grounded LVLM applications.
Below, we list practical applications derived from the paper’s findings and methods, grouped as Immediate Applications (deployable now) and Long-Term Applications (requiring further development). Each item notes the sector, potential tools/workflows/products, and assumptions/dependencies that affect feasibility.
Immediate Applications
The following applications can be deployed with current LVLMs (e.g., Qwen3-VL and InternVL3.5 variants) by integrating the uncertainty-guided lookback controller and/or the breadth-aware sampling policies described in the paper.
- Software and ML Ops (sector: software/AI platforms)
- Application: Integrate a “Lookback Controller” into LVLM inference servers (vLLM, Text Generation Inference, LMDeploy, Hugging Face Transformers) to reduce hallucinations and token cost while improving accuracy on image-conditioned tasks (charts, diagrams, screenshots).
- Tools/Workflows:
- A plug-in SDK that does n-gram pause-phrase matching and inserts mined lookback templates during streaming generation.
- Policy knobs for breadth (Pass@k) and lookback trigger rate to meet SLA/latency targets.
- Logging/telemetry that records trigger positions, token savings, and category-level routing decisions.
- Assumptions/Dependencies:
- Model supports a reasoning/thinking mode or at least multi-turn “step-by-step” generation.
- Phrase vocabulary is mined offline and refreshed periodically for the model/domain.
- Streaming token access is available to the decoder (or batch decoding with controlled insertion).
- Document Intelligence and Enterprise Assistants (sector: enterprise software, productivity)
- Application: More accurate Q&A over charts, infographics, and technical diagrams in productivity suites and customer support portals (e.g., resolving issues from annotated screenshots).
- Tools/Workflows:
- Adaptive inference profiles: instruct mode for recognition-heavy tickets, lookback-enabled reasoning for calculation/diagram queries.
- Auto-routing by category/task metadata (MMMU-like labels or in-house taxonomy).
- Assumptions/Dependencies:
- Reliable task categorization (or lightweight heuristics) to select instruct vs. lookback mode.
- Sufficient visual token budgets for high-resolution inputs.
- Education and Tutoring (sector: education)
- Application: Math and STEM tutoring that references visual content (graphs, geometry figures, lab setups) with short, targeted lookbacks to the image rather than overlong rationales.
- Tools/Workflows:
- Diagram-aware prompts with lookback templates (“Looking back at the figure, the angle at…”) and controlled Pass@k for challenging items.
- Teacher dashboards showing when the model triggered lookbacks and why (uncertainty cues).
- Assumptions/Dependencies:
- Domain-specific lookback phrases tuned to curricula (geometry, physics, chemistry).
- Human oversight for grading and pedagogy alignment.
- Healthcare Decision Support (sector: healthcare)
- Application: Triage-level assistance for clinical workflows where visual artifacts are central (lab reports, microscopy images, annotated scans), with improved grounding and fewer “long-wrong” chains.
- Tools/Workflows:
- Controlled decoding profiles that trigger lookback in “Diagnostics and Laboratory Medicine”-type queries.
- Human-in-the-loop gating for any clinical recommendations; audit logs of lookback events.
- Assumptions/Dependencies:
- Not for autonomous diagnosis; requires clinical validation, bias assessments, and regulatory compliance (HIPAA, GDPR).
- Domain-specific lexicons and lookback phrases vetted by clinicians.
- Finance and Business Analytics (sector: finance)
- Application: Chart interpretation and visually anchored financial Q&A (candlestick charts, KPI dashboards, prospectus figures), reducing hallucinated narratives.
- Tools/Workflows:
- Adaptive routing: instruct mode for straightforward identification; lookback for quantitative reasoning across multiple visuals.
- Guardrail policies that flag overly speculative chains (pause phrases without corresponding lookback content).
- Assumptions/Dependencies:
- Access to high-quality chart images and metadata; visual token budgets for detail.
- Domain-tuned uncertainty lexicon to reduce speculative text priors.
- Energy and Engineering Operations (sector: energy, manufacturing)
- Application: Diagram-centric troubleshooting (wiring schematics, P&IDs, process flow diagrams) with short refocusing prompts to the exact region of interest before continuing reasoning.
- Tools/Workflows:
- Device-side controllers that capitalize on InternVL-style tiling/DHR features for high-res inputs.
- Integration with issue-tracking systems where lookback triggers become “evidence anchors.”
- Assumptions/Dependencies:
- Sufficient compute and memory for large images; careful permissioning for sensitive operations diagrams.
- Limited real-time constraints (batch or near-real-time OK).
- Accessibility and Assistive Tech (sector: assistive technology)
- Application: More faithful descriptions of infographics, forms, and instructions for visually impaired users by prompting explicit revisits to on-image text or key symbols.
- Tools/Workflows:
- “Describe and verify” mode: when uncertainty phrases appear, append lookback prompts and confirm specific visual details (e.g., labels, axes).
- Assumptions/Dependencies:
- Robust OCR/visual tokenization; curated lookback phrases for accessibility contexts.
- Safety and Content Moderation (sector: trust & safety)
- Application: Reduce visual hallucination in multimodal content classification and policy enforcement (misleading infographics, doctored images).
- Tools/Workflows:
- Decoding policies that trigger lookback before any sensitive label is assigned.
- Auditable “visual helpfulness” scores for escalations.
- Assumptions/Dependencies:
- Clear governance policies; model cards noting scenarios where lookback can still fail.
Long-Term Applications
These applications are promising but require further research, scaling, or ecosystem development (e.g., model training changes, richer tooling, domain certification).
- Standardized Adaptive Visual Reasoning in LVLM Ecosystems (sector: software/AI platforms)
- Application: A common, cross-model standard for uncertainty-guided lookback controllers and compute-aware routing (breadth vs. depth) across families beyond Qwen/InternVL (e.g., Gemini, LLaVA variants).
- Tools/Workflows:
- Model-agnostic “Uncertainty Lexicon” registries auto-mined per model/domain.
- Evaluation suites that report accuracy–token Pareto frontiers by category.
- Assumptions/Dependencies:
- Vendor cooperation; APIs that expose streaming tokens and allow controlled insertion.
- Training and Fine-Tuning with Lookback Signals (sector: AI research, model providers)
- Application: Use mined uncertainty/lookback events to teach models when to re-ground, penalize long-wrong trajectories, and reward visually helpful steps (RLHF/RLAIF).
- Tools/Workflows:
- Curricula that mix instruct and lookback prompts; supervised visual scratchpad data.
- RL objectives incorporating “visual helpfulness” scores computed during fine-tuning.
- Assumptions/Dependencies:
- Access to training data with aligned image–reasoning traces; compute budgets for RL.
- High-Stakes Reliability Frameworks (sector: healthcare, finance, public sector)
- Application: Formal guardrails where lookback triggers act as risk indicators (e.g., automatic human escalation when uncertainty persists after lookback).
- Tools/Workflows:
- Compliance dashboards tracking per-case lookback density, grounding metrics, and chain length.
- Third-party auditing standards for adaptive decoding in regulated domains.
- Assumptions/Dependencies:
- Regulatory acceptance of adaptive decoding logs as evidence; validated metrics linking lookback to error reduction.
- Robotics and Real-Time Systems (sector: robotics, autonomous systems)
- Application: Perception–reasoning loops where a controller triggers brief re-examination of camera frames or spatial maps, selecting grounded branches before action planning.
- Tools/Workflows:
- Latency-aware variants (micro-lookbacks with tight H and M) and multimodal extensions (audio/video).
- Integration with task routers that choose instruct vs. lookback vs. visual scratchpad per step.
- Assumptions/Dependencies:
- Faster, smaller LVLMs or distillations; careful real-time constraints; robust visual encoders.
- Visual Scratchpad Synergy (sector: education, engineering design tools)
- Application: Combine lookback with interactive visual scratchpads (drawing, annotation) so the model both re-examines the image and makes explicit, manipulable visual notes.
- Tools/Workflows:
- “Sketch-guided lookback” interfaces for geometry or circuit analysis.
- Logging of visual note references that correspond to lookback prompts.
- Assumptions/Dependencies:
- Tooling maturity; supervision for visual edits; model APIs that handle multi-modal state.
- Sustainable AI and Compute Policy (sector: policy/governance)
- Application: Policy guidelines that discourage wasteful test-time thinking and require reporting token budgets, Pass@k, and adaptive decoding in deployments (energy-aware AI).
- Tools/Workflows:
- Benchmarks that standardize compute-equivalence reporting and “token economy” audits.
- Procurement rules for public-sector AI specifying adaptive strategies over brute-force CoT.
- Assumptions/Dependencies:
- Consensus across standards bodies; measurement infrastructure in evaluations.
- Task Routing and Category-Aware Orchestration (sector: enterprise AI)
- Application: Automatic selection of instruct vs. thinking vs. lookback, and breadth (k) based on predicted category and difficulty, optimizing both accuracy and cost.
- Tools/Workflows:
- Pre-classifiers that map queries to MMMU-like categories and difficulty tiers.
- Learned policies that set token budgets and trigger thresholds per profile.
- Assumptions/Dependencies:
- Reliable routing models; continuous monitoring to avoid mode misuse (e.g., recognition-heavy tasks where concise instruct is superior).
- Edge and Mobile Assistants (sector: consumer, AR)
- Application: On-device multimodal assistants that re-ground on images with micro-lookbacks to stay within tight power and latency envelopes.
- Tools/Workflows:
- Phrase vocabularies distilled for small LVLMs; hardware-aware decoding schedules.
- Caching of lookback templates and selective visual tokenization (tiling, thumbnail + ROI).
- Assumptions/Dependencies:
- Efficient LVLMs; privacy-preserving local vision stacks; domain-specific tuning.
Cross-Cutting Assumptions and Dependencies
- Model compatibility: The reported gains are demonstrated on Qwen3-VL and InternVL3.5 families; other LVLMs may require re-mining of pause/lookback phrases and validation.
- Task heterogeneity: Recognition-heavy tasks often prefer instruct mode; adaptive routing is essential to avoid unnecessary lookbacks.
- Resource constraints: High-res images and multi-sample decoding increase memory/latency; practical deployments must set conservative token and sampling budgets.
- Data governance: Healthcare/finance use cases require rigorous compliance, bias testing, and human oversight; logs of lookback triggers should be auditable.
- Generalization: The mined phrase sets generalize across several benchmarks, but domain-specific lexicons likely yield the best results; refresh and monitor regularly.
Glossary
- Autoregressive decoding: A generation process where each token is predicted conditioned on previously generated tokens and inputs. "Because the decoder is autoregressive, we can compute per-step perplexity"
- Breadth search: Exploring multiple sampled reasoning paths during decoding to increase the chance of a correct answer. "combines an uncertainty signal with adaptive lookback prompts and breadth search"
- Cascade RL: A reinforcement learning approach applied in stages to improve model reasoning capabilities. "InternVL~3.5 reports strong reasoning results across MMMU/MathVista with cascade RL"
- Chain-of-thought (CoT) decoding: Generating explicit step-by-step reasoning tokens at test time to improve complex problem solving. "Thinking—test-time chain-of-thought decoding, self-consistency, and reflection-style prompting—has emerged as a key ingredient for complex reasoning"
- DeepStack: A multi-level Vision Transformer feature stacking/fusion module that reduces and fuses visual tokens before the LLM. "DeepStack (Qwen3-VL) denotes a multi-level ViT feature stacking/fusion module with 2×2 token merging"
- Dynamic High-Resolution (DHR) tiling: Splitting an image into high-resolution tiles to produce more detailed visual tokens for LVLMs. "InternVL3.5 uses ViT/14 features with 4× pixel unshuffle and DHR (Dynamic High-Resolution) tiling:"
- Early exit: Terminating a reasoning chain based on confidence signals before generating the full thought sequence. "early exit and confidence"
- Head-suppression strategy: An inference-time control that suppresses attention heads to mitigate visual hallucinations. "an inference-time head-suppression strategy links hallucination to low image-attending heads"
- MCTS (Monte Carlo Tree Search): A search algorithm that explores and evaluates branching reasoning trajectories using stochastic simulations. "via a collective MCTS procedure"
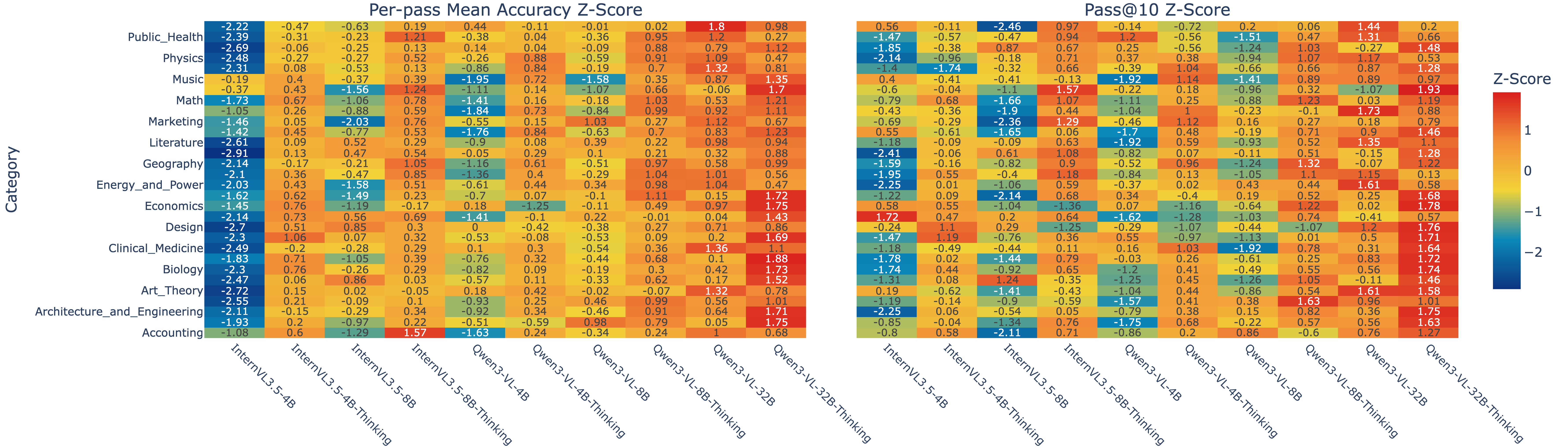
- MMMU: A diverse multimodal benchmark with many categories used to evaluate visual reasoning performance. "We adopt MMMU as our analysis benchmark"
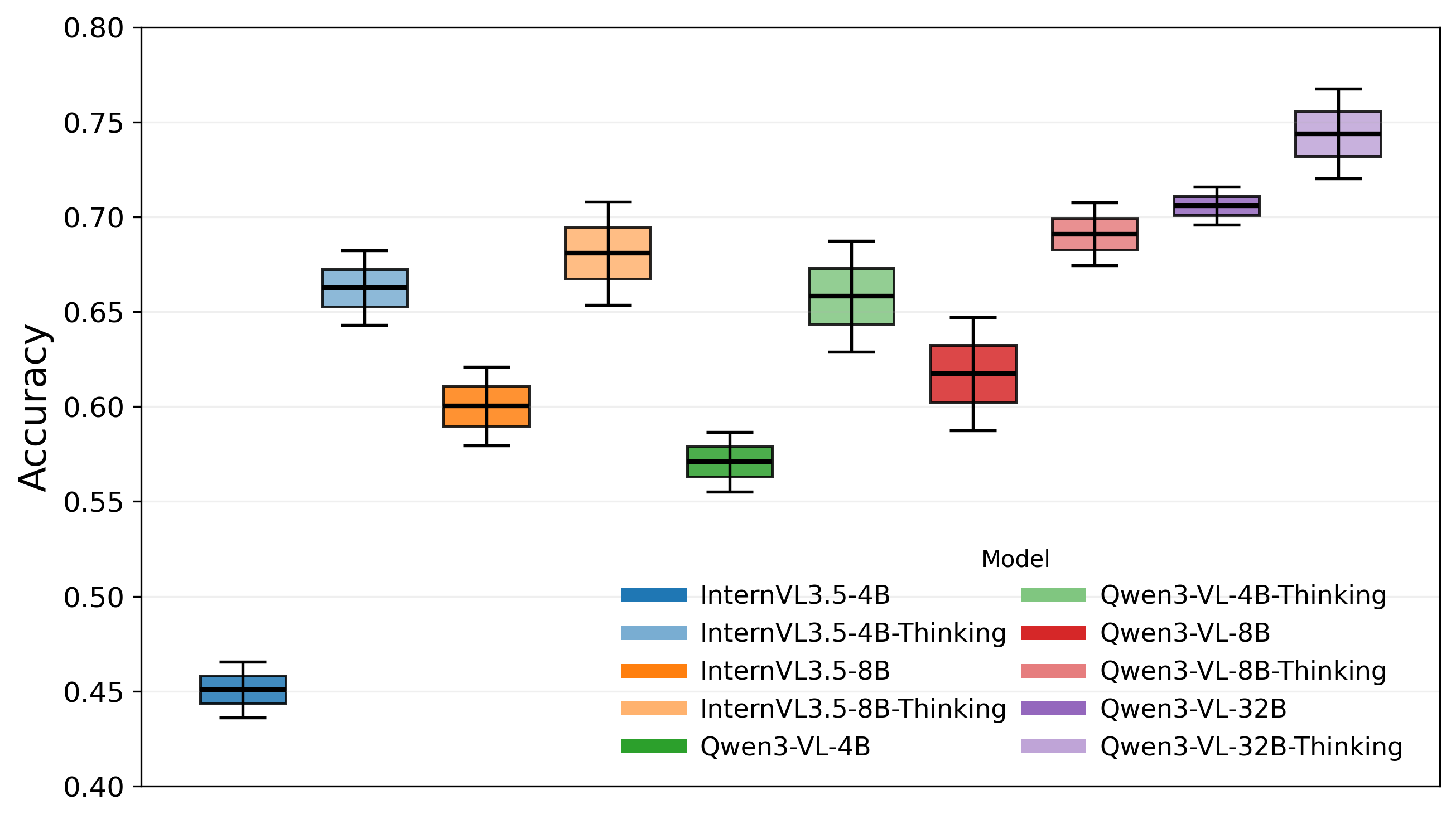
- Multiple-pass decoding: Evaluating a model by sampling several reasoning trajectories per item to improve robustness. "Multiple-pass decoding."
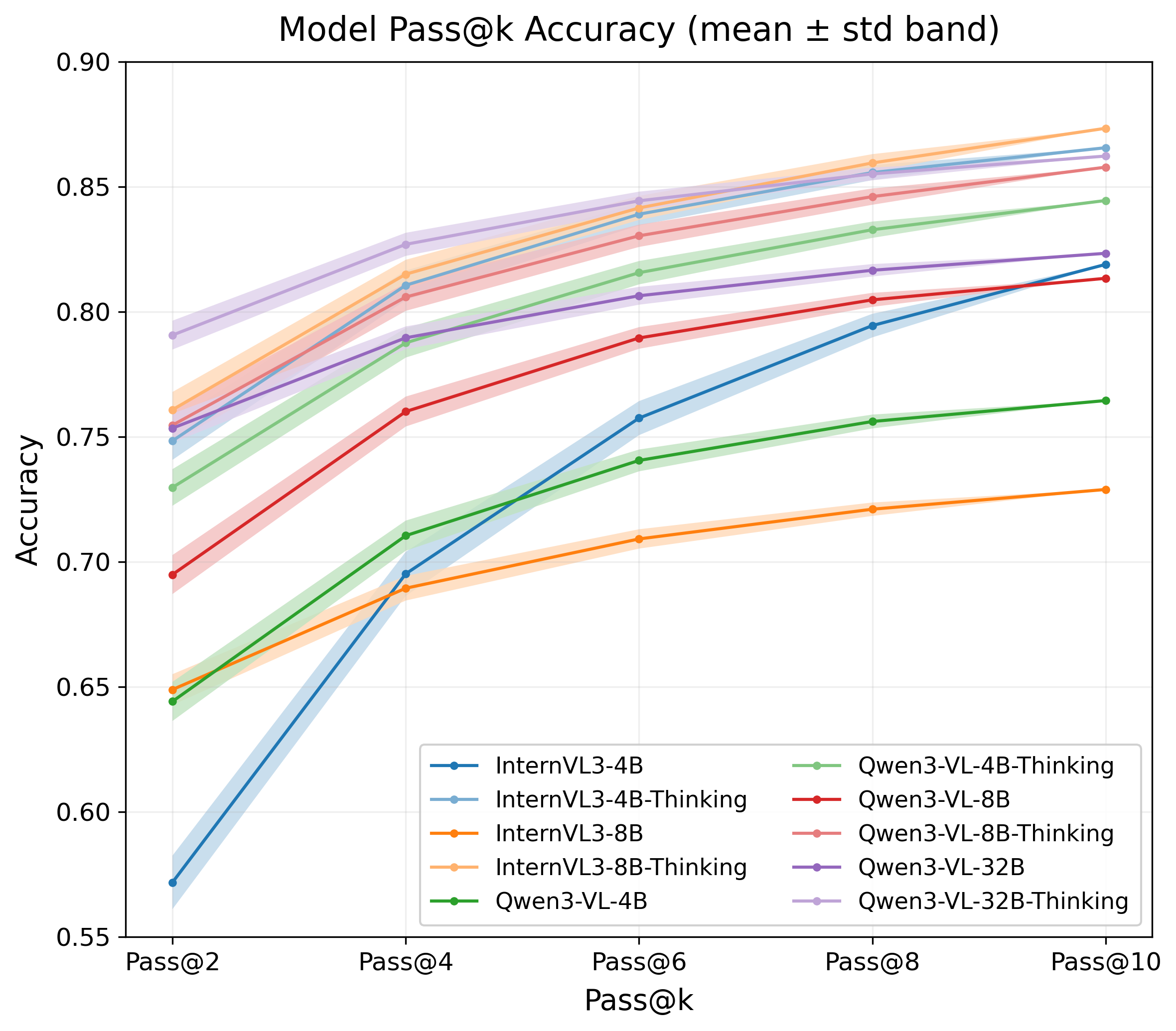
- Pass@k: The probability that at least one of k sampled outputs is correct, used to measure breadth-based improvements. "Pass@k accuracy on MMMU for 10 LVLM variants"
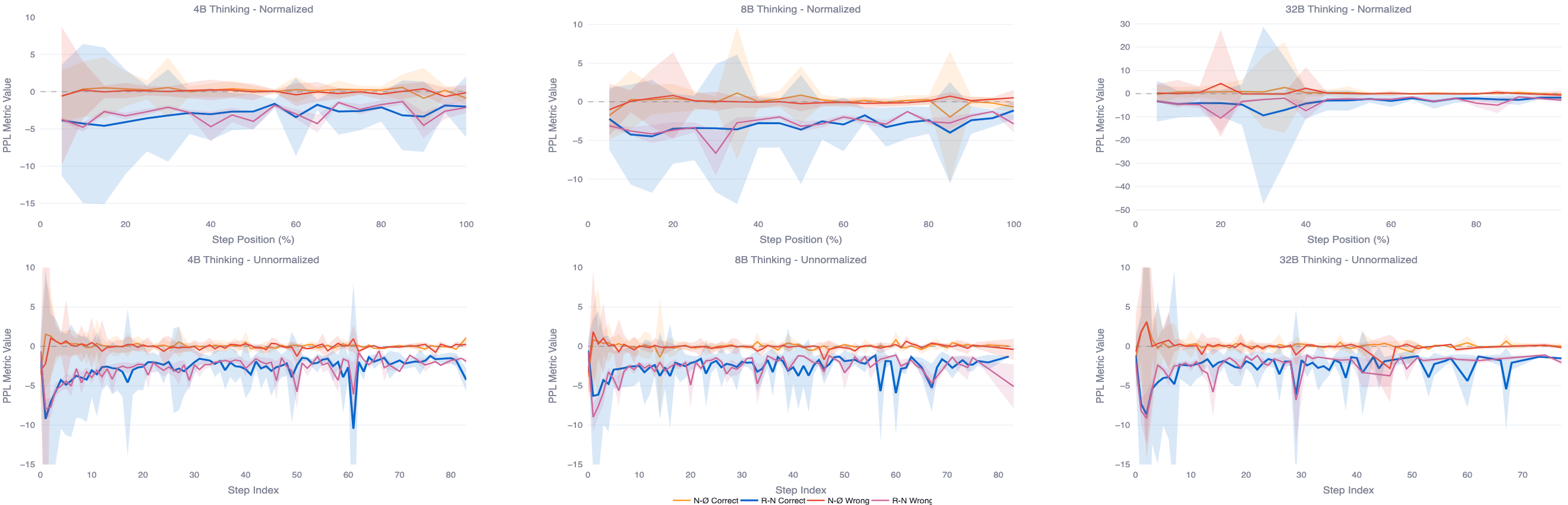
- Per-token perplexity (ΔPPL): A token-level difficulty measure; changes indicate how much visual context narrows or broadens the model’s predictions. "per-token perplexity (PPL)"
- Pixel unshuffle: A transformation that reorganizes image pixels to produce a higher-resolution feature map for the vision encoder. "4× pixel unshuffle"
- Reflection-style prompting: Prompts that encourage the model to reconsider and refine its reasoning steps during generation. "reflection-style prompting"
- Self-consistency: Sampling multiple reasoning chains and selecting answers that agree, improving reliability. "self-consistency"
- Token merging: Combining neighboring visual tokens to reduce the token grid size while preserving information. "2×2 token merging"
- Training-free decoding strategy: An inference-time control method that improves performance without retraining the model. "a training-free decoding strategy"
- Uncertainty-guided lookback: A decoding controller that inserts short prompts to re-examine the image when uncertainty or drift is detected. "uncertainty-guided lookback, a training-free decoding strategy"
- Vision Transformer (ViT): A transformer-based architecture that tokenizes images into patches for attention-based processing. "Qwen3VLVision (ViT/16)"
- Visual CoT: Chain-of-thought approaches that explicitly integrate visual intermediates (e.g., drawings) into the reasoning. "work on visual CoT has begun to explicitly incorporate visual intermediates"
- Visual grounding: Aligning the model’s reasoning and output with actual image content to avoid drifting to text priors. "correlate with better visual grounding"
- Visual hallucination: Model-generated visual claims not supported by the image, often arising from text priors. "visual hallucination"
Collections
Sign up for free to add this paper to one or more collections.