Semantic Chunking and the Entropy of Natural Language
Abstract: The entropy rate of printed English is famously estimated to be about one bit per character, a benchmark that modern LLMs have only recently approached. This entropy rate implies that English contains nearly 80 percent redundancy relative to the five bits per character expected for random text. We introduce a statistical model that attempts to capture the intricate multi-scale structure of natural language, providing a first-principles account of this redundancy level. Our model describes a procedure of self-similarly segmenting text into semantically coherent chunks down to the single-word level. The semantic structure of the text can then be hierarchically decomposed, allowing for analytical treatment. Numerical experiments with modern LLMs and open datasets suggest that our model quantitatively captures the structure of real texts at different levels of the semantic hierarchy. The entropy rate predicted by our model agrees with the estimated entropy rate of printed English. Moreover, our theory further reveals that the entropy rate of natural language is not fixed but should increase systematically with the semantic complexity of corpora, which are captured by the only free parameter in our model.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Semantic Chunking and the Entropy of Natural Language — A simple explanation
Overview: What is this paper about?
This paper asks a big question: Why is human language so predictable? Decades ago, Claude Shannon showed that printed English has a lot of redundancy—about 80% more than totally random text. In simple terms, if random text needs about 5 bits per character to describe, English needs only about 1. The authors build a simple, math-based explanation for this redundancy. They say it comes from how we naturally organize meaning in layers—like chapters, paragraphs, sentences, and words. They show that if you break a text into meaningful pieces again and again, that structure alone can explain how predictable language is.
The main questions the paper tries to answer
- Can we explain how predictable language is (its “entropy rate”) using only the way meaning is organized into chunks?
- If we split texts into a hierarchy of meaningful chunks, does that structure match a simple mathematical model?
- Do predictions from this model match what modern AI LLMs measure about how predictable text is?
- Does the predictability change across different types of writing (children’s stories, narratives, research abstracts, poetry)? If so, why?
How the researchers studied this (in everyday terms)
Think of reading as organizing a story from big ideas down to small details, like:
- Whole story → sections → paragraphs → sentences → words
The researchers turned that idea into a step-by-step process:
- They used an AI model to “chunk” each document:
- Start with the whole text.
- Split it into a few meaningful parts (at most K parts).
- Then split each part again into smaller meaningful parts.
- Keep going until you reach single words or tokens.
- This creates a “semantic tree,” like a family tree where each parent chunk splits into up to K child chunks.
- They compared these trees to a very simple random model:
- Imagine you have a long ribbon (the text).
- At each step, you randomly place up to K-1 scissors to cut the ribbon into up to K parts.
- Do that again to each piece, over and over.
- Even though the cuts are random, the overall pattern across many texts becomes very regular.
- They measured predictability in two independent ways: 1) Using an LLM: Walk through each token (word piece), ask “How surprising is the next token?” and average that surprise. This is often called perplexity or cross-entropy. 2) Using the tree model: Calculate how many different trees like this are possible for a text and convert that into an “entropy rate.” More possible trees = more uncertainty; fewer = more predictability.
- They tested across different types of writing:
- Children’s stories
- Reddit narratives
- Research abstracts (arXiv)
- Poetry
Key terms, simply explained:
- Entropy rate: Average uncertainty per token—like how hard it is to guess the next word.
- Perplexity: A model’s “how surprised am I?” score. Lower means the text is easier to predict.
- K-ary tree: A tree where each node can split into at most K parts.
- Semantic chunking: Cutting a document into pieces that each make sense on their own.
What they found and why it matters
- Real texts’ chunking patterns match the simple random-splitting model:
- When they looked at the sizes of chunks at each level (big to small), the distributions from real texts looked very similar to the model’s predictions.
- At deeper levels, chunk sizes follow a regular pattern (roughly lognormal), meaning that across many texts, the structure becomes very predictable.
- One number, K, captures how complex a corpus is:
- K is the maximum number of chunks you split into at each step.
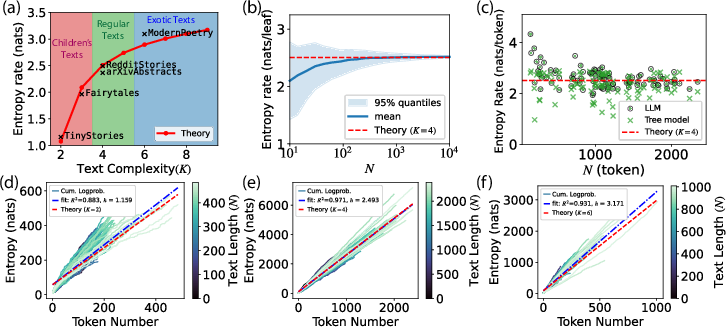
- Children’s stories fit best with smaller K (fewer ideas active at once); poetry fit best with larger K (more ideas or more complex structure).
- Larger K → higher entropy rate → harder to predict tokens.
- Their theory’s entropy rates match LLM measurements:
- The entropy rate predicted by the tree model closely matches the per-token “surprise” measured by big LLMs.
- Across corpora:
- Children’s texts: lowest entropy (most predictable).
- Narratives and research abstracts: medium.
- Poetry: highest (least predictable).
- As texts get longer, both methods give nearly the same answer; for short texts, the tree-based number tends to be a bit lower (a conservative estimate).
- A big-picture insight:
- A lot of the uncertainty in language comes from how meaning is layered and organized—not just from grammar or word choices.
- In other words, if you know the “outline” of a text (its semantic chunks), you already explain a lot of why words are predictable.
Why this is important
- It links two worlds:
- Language as a sequence of tokens (what LLMs model).
- Language as a hierarchy of meaning (how humans read and summarize).
- It offers a first-principles explanation for classic results:
- Why English seems ~80% redundant.
- Why some genres are harder to predict than others.
- It suggests a connection to human cognition:
- The K parameter may reflect how many ideas readers can juggle at once—similar to working memory limits.
- More “active ideas” → more complex texts → higher entropy.
What this could change or inspire
- Better ways to split long documents for search, retrieval, or summarization by focusing on meaningful chunks.
- New measures of text difficulty tied to semantic complexity (helpful for education or accessibility).
- Improved compression methods that use semantic structure to reduce file sizes.
- Cognitive science and education insights: estimating how demanding a text is on memory and attention.
- Evaluating datasets for AI training by their semantic complexity, not just size.
In short: The paper shows that how we organize meaning—breaking texts into nested, coherent chunks—goes a long way toward explaining how predictable language is. A simple tree model, with just one knob (K), can match both the structure of real texts and how “surprised” a strong LLM is when reading them.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, formulated to guide concrete next steps for researchers:
- Dependence on LLM-driven chunking without human validation: No comparison of LLM-induced “semantic trees” with human-annotated discourse/segmentation (e.g., RST, PDTB) or with human recall structures; inter-annotator variability and agreement with the induced trees remain unmeasured.
- Potential circularity and model dependence: Both chunking and entropy estimates rely on large LLMs; robustness to the choice of LLM (architecture, size, training data), prompts, and chunking heuristics is untested, and possible train–test contamination (e.g., TinyStories) is not ruled out.
- Tokenization confounds: Entropy is reported in nats/token, while Shannon’s classic estimate is in bits/character; there is no systematic conversion or control for tokenizer effects across corpora (token lengths, vocabulary), nor an analysis of character-level rates and their sensitivity to tokenization.
- Generality beyond English and chosen genres: All analyses focus on English corpora; cross-linguistic validation (morphologically rich languages, scripts without explicit word segmentation) and genre diversity beyond the five studied corpora are not explored.
- Assumption of a fixed corpus-level K: The model enforces a single optimal branching factor K⋆ per corpus; intra-corpus heterogeneity, document-specific K, or hierarchical levels with variable K are not modeled or estimated.
- Structural prior restrictiveness: The tree prior assumes contiguous, K-ary partitions with at most K children and uniformly placed K−1 boundaries (Beta(1, K−1) splits); alternative fragmentation processes (e.g., Dirichlet, Pitman–Yor, non-uniform boundary priors), non-contiguous/discontinuous spans, or overlapping structures common in discourse are not considered.
- Limited validation of tree statistics: Model fitting uses only chunk-size distributions across levels; other informative tree statistics (branching distributions, depth/imbalance, sibling-size correlations, ancestor–descendant dependencies) are not tested, raising identifiability concerns (different processes may match the same f_L).
- Finite-size effects and corrections: The theory largely relies on large-N scaling; finite-N corrections, their magnitude, and practical impact on short texts (where the tree-based entropy underestimates LLM cross-entropy) are not quantified or corrected.
- Deferred mathematical results: Key claims (asymptotic equipartition, general h_K characterization) and derivations are deferred to future work or SI; a complete, self-contained proof and closed-form expressions for h_K (beyond K=2 and K≫1) are missing from the paper.
- Mapping h_K to token-level entropy: The paper asserts close agreement between tree entropy and LLM cross-entropy but does not quantify confidence intervals, effect sizes, or statistical significance of the match across corpora and texts.
- Robustness across chunkers and segmentation prompts: Sensitivity of K⋆, f_L, and h_K to prompt phrasing, recursion depth criteria, stopping rules, and LLM sampling settings (e.g., temperature) is not analyzed.
- Handling of empty and multi-token leaves: The theory counts empty children and allows non-unit leaves; the empirical frequency and impact of these cases on P(T), f_L, and h_K (and on renormalization when empty nodes are removed) are not characterized.
- Universality claim versus generic lognormality: The observed lognormal scaling and collapse may arise from generic multiplicative processes, not uniquely from the proposed random K-ary partition; falsifiable signatures that distinguish this model from other multiplicative or fragmentation models are not presented.
- Linking K to cognitive constructs: The proposed interpretation of K as a working-memory capacity proxy is not validated with behavioral data (reading times, comprehension accuracy, recall structure) or individual differences; no experiments link h_K/h_LLM to processing difficulty.
- Per-character entropy and classic redundancy: The paper invokes the ~1 bit/character benchmark but does not compute per-character entropy for the studied texts or reconcile per-token results with this classic figure under a consistent tokenization-to-character mapping.
- Context window and long-range constraints: The effect of LLM context window size and truncation on h_LLM and the role of very long-range dependencies (beyond hierarchical contiguity) are not quantified.
- Genre- and formatting-specific artifacts: For poetry and other formats (e.g., code, dialogue), how line breaks, punctuation, or layout influence the induced trees and entropy estimates is not examined.
- Alternative evaluation endpoints: The predictive utility of tree-derived measures for downstream tasks (compression performance, retrieval effectiveness, summarization quality) is not evaluated, despite the compression motivation of entropy.
- Cross-model reproducibility: Agreement between tree-based and LLM-based entropy is shown for specific Llama variants; stability across multiple strong models (e.g., GPT, Mistral, Gemma) is not reported.
- Estimation and uncertainty reporting: KL fits for K⋆ and entropy-rate regressions lack uncertainty quantification (CIs, bootstrap), ablation analyses, and power considerations given relatively small sample sizes per corpus.
- Data and code transparency: Full algorithmic details, prompts, and code for chunking and entropy computation are in SI or unspecified; open availability for reproducibility is not indicated.
- Model misspecification diagnostics: There is no formal goodness-of-fit testing beyond averaged KL divergence, nor posterior predictive checks for tree features across levels; outlier texts and failure modes are not analyzed.
- Heterogeneity within corpora: Variation of K⋆ or h within a corpus (by topic, style, author) is not characterized; a hierarchical model allowing document- or section-level K would better capture heterogeneity.
- Beyond contiguous trees: Discourse phenomena involving cross-sentential anaphora, parallelism, and non-projective relations are not represented in a strictly contiguous K-ary tree; how such phenomena affect entropy and whether augmentations (e.g., DAGs, forest structures) improve fit is open.
- Practical inference of K and h without chunking: Procedures to estimate K or h_K directly from observable surface features or LLM surprisal (avoiding full tree induction) are not developed.
- Applicability to generation and editing: Whether controlling K (or estimated semantic complexity) during generation/editing can modulate text predictability or readability is untested.
Practical Applications
Immediate Applications
Below are practical uses that can be deployed with current LLMs and tooling, leveraging the paper’s semantic chunking procedure, random-tree modeling, and entropy insights.
- [Software/AI] Semantic-tree chunker for RAG and search
- What: Replace fixed-size windowing with LLM-driven, recursive semantic chunking to build a multi-level tree; index nodes (spans) at multiple scales for retrieval and long-context processing.
- Tools/workflow:
- “Semantic Tree Segmenter” library (LLM + prompts + recursion) producing spans, boundaries, and levels.
- Embed and index nodes in vector DBs (e.g., FAISS/Milvus) by level; retrieve the fewest, most-coherent nodes covering a query.
- Use higher-level nodes for context priming; refine to lower-level nodes when needed.
- Benefits: Better context coherence, fewer cross-boundary truncations, higher answer precision, less hallucination risk.
- Assumptions/dependencies: Chunk quality depends on LLM and prompt stability; compute cost grows with document size; tokenization and language differences may affect leaf-level consistency.
- [Software/AI] Multi-scale summarization and outline generation
- What: Use the semantic tree to produce outlines and summaries at each level; enable “progressive disclosure” reading and summarization.
- Tools/workflow:
- Generate node-level keypoints and summaries at each depth.
- Build UI that collapses/expands by level (document → section → paragraph → sentence).
- Benefits: Faster skimming, structured notes, better editing and review workflows.
- Assumptions: Quality of summaries depends on LLM accuracy; evaluation criteria for coherence vary across domains.
- [Education/Publishing/UX] Readability and complexity scoring with K and entropy rate
- What: Introduce “K-meter” and entropy-per-token (or per-character) as interpretable readability metrics aligned with working-memory load and semantic complexity.
- Tools/workflow:
- Compute optimal K* for a corpus or document; estimate entropy via LLM perplexity or tree likelihood.
- Integrate into LMS, CMS, or writing tools (e.g., highlight high-entropy spans; suggest simplifications).
- Benefits: Better text leveling for K–12, ESL, and general audiences; measurable targets for plain-language initiatives.
- Assumptions: Mapping from K/entropy to human comprehension needs calibration per audience; variability across genres and languages.
- [Healthcare/Patient Communication] Cognitive load gauge for patient-facing materials
- What: Apply K/entropy metrics to ensure discharge instructions, consent forms, and health portals match patients’ literacy and cognitive load.
- Tools/workflow: Batch-score documents; flag high-complexity spans; rewrite suggestions to reduce K (fewer concurrent keypoints).
- Benefits: Improved comprehension, adherence, and equity.
- Assumptions: Requires validation against patient comprehension outcomes; sensitive health contexts need expert review.
- [Finance/Legal/Compliance] Complexity-based triage for human-in-the-loop review
- What: Automatically identify high-entropy/K sections in long disclosures, contracts, or policies for prioritized human review and simplification.
- Tools/workflow:
- Run semantic chunking and compute local entropy/K per node.
- Route complex nodes for expert editing; attach justifications and plain-language rewrites.
- Benefits: Faster compliance checks, clearer consumer disclosures.
- Assumptions: Legal accuracy must not be compromised by simplification; governance and audit trails required.
- [AI Evaluation/Academia] Tree-based entropy as a diagnostic alongside perplexity
- What: Compare LLM perplexity with tree-likelihood–derived entropy to analyze where token-level uncertainty diverges from semantic structure.
- Tools/workflow:
- For each test set, compute both estimates and analyze gaps by genre or task.
- Benefits: New lens for model evaluation, dataset design, and architecture choices.
- Assumptions: Chunking pipeline must be consistent across models/experiments.
- [Data/AI Engineering] Corpus curation by complexity bands
- What: Label datasets by K*/entropy bands for balanced training and benchmarking (e.g., “child-level,” “narrative,” “technical,” “poetry-like”).
- Tools/workflow:
- Automate K* selection per corpus; publish metrics on dataset cards.
- Benefits: Better coverage of complexity regimes; targeted fine-tuning.
- Assumptions: K* depends on segmentation settings; cross-corpus comparison needs standardized pipelines.
- [Compression/Storage] Entropy-guided heuristic compression
- What: Use semantic trees to guide variable-bit-rate or structure-aware compression (e.g., stronger compression on predictable spans, references to parent summaries).
- Tools/workflow:
- Combine LLMZip-style token modeling with node-level entropy estimates; store node summaries and residuals.
- Benefits: Practical gains on long documents; more faithful meaning preservation than uniform chunking.
- Assumptions: Gains vary by genre; must maintain lossless guarantees when required; additional compute overhead.
- [Cloud/Inference Ops] Adaptive context allocation by local entropy
- What: Dynamically allocate context, attention budget, or reranking passes to high-entropy spans during long-document inference.
- Tools/workflow:
- Prepass to score nodes; route “hard” spans to larger models or multi-pass retrieval; “easy” spans to cheaper paths.
- Benefits: Lower cost with maintained quality; predictable latency.
- Assumptions: Scheduling complexity; requires robust online segmentation and monitoring.
- [Productivity/Writing] Editorial assistant for structural coherence
- What: Detect over-segmentation (very high K) or under-segmentation (very low K), suggest reorganization to match target complexity.
- Tools/workflow:
- Show per-section K and entropy; propose merging/splitting of sections; auto-generate connecting discourse glue.
- Benefits: More coherent documents; consistent style guides.
- Assumptions: Editorial preference varies by domain; avoid prescriptive homogenization for creative writing.
Long-Term Applications
These applications require further research, validation, scaling, or standardization before widespread deployment.
- [Education/EdTech] Personalized reading pathways by inferred working-memory profile
- Vision: Estimate a learner’s effective K and adapt materials in real time; scaffold texts by gradually increasing K across lessons.
- Needed advances: Validated psychometric link between K/entropy and comprehension; longitudinal studies; user modeling.
- [Healthcare/Neuropsychology] Cognitive assessment and interventions using semantic complexity
- Vision: Use reading tasks with controlled K/entropy to assess working memory and language processing (e.g., in ADHD, aphasia, aging); design targeted therapies that tune K.
- Needed advances: Clinical trials; ethical frameworks; cross-linguistic norms.
- [Policy/Government] Standards for public-facing readability based on K/entropy
- Vision: Replace or complement Flesch-like metrics with entropy/K thresholds for official documents (benefits, elections, health advisories).
- Needed advances: Regulatory consensus; validation across populations; tooling and auditability for public agencies.
- [Software/AI] Structural training objectives for LLMs (tree-likelihood regularization)
- Vision: Incorporate semantic-tree likelihoods or chunk-size distribution matching during pretraining or RLHF to bias models toward human-like discourse structure; improve long-context recall and reduce hallucinations.
- Needed advances: Differentiable approximations; scalable training integration; ablations across tasks.
- [NLP/Standards] Interoperable “Semantic Tree” annotation format
- Vision: A common schema and datasets for hierarchical semantic spans (nodes, keypoints, relations), akin to RST/PDTB but scalable with LLMs; supports benchmarking and tool ecosystems.
- Needed advances: Community consensus; multilingual corpora; annotation quality control.
- [Robotics/Agents] Hierarchical instruction parsing under K-limited planning
- Vision: Parse natural-language instructions into task trees; enforce K-compatible planning contexts to reflect agent memory limits and reduce error propagation.
- Needed advances: Integration with task planners; benchmarks relating K to performance; grounding in real environments.
- [Machine Translation/Summarization] Cross-lingual tree alignment and controllable compression
- Vision: Align source and target semantic trees for faithfulness guarantees; specify desired compression ratio via target K; ensure semantic coverage at chosen levels.
- Needed advances: Reliable alignment methods; evaluation metrics; human-in-the-loop validation.
- [Compression] Next-generation semantic-aware codecs for text and multimodal content
- Vision: Codebooks organized by semantic trees; coarse-to-fine decoding with error correction driven by node likelihoods; hybrid lossless/lossy modes.
- Needed advances: Standards; hardware acceleration; consistent gains across domains.
- [Cloud/Energy] Entropy-aware scheduling for compute efficiency
- Vision: Route high-entropy content to more powerful models or more passes; anticipate power/latency by complexity profile; reduce energy per useful token.
- Needed advances: Production telemetry linking entropy to QoS; fair scheduling in multi-tenant environments; economic models.
- [Accessibility/Daily Life] Adaptive reading interfaces tuned to user capacity
- Vision: Browsers/e-readers that auto-collapse documents into level-appropriate chunks; users control depth; interfaces track comprehension and adjust K dynamically.
- Needed advances: UX studies; privacy-preserving personalization; standards for accessible content.
- [Academia/Cognitive Science] Large-scale experiments linking K to human working memory
- Vision: Test the hypothesized relationship between K and working-memory limits across genres, languages, and modalities; refine cognitive models of discourse processing.
- Needed advances: Experimental platforms; cross-institutional collaborations; open datasets.
Cross-cutting assumptions and dependencies
- Reliability of LLM-based semantic chunking: Results depend on the prompting strategy, model size, and domain familiarity; chunk boundaries and keypoints may vary by model and language.
- Generalization beyond English and across tokenizers: Tree leaves depend on tokenization and writing systems; multilingual validation is required.
- Model-theoretic assumptions: The random K-ary ensemble approximates empirical trees at corpus level; per-document deviations can be large; AEP and closed-form h_K are still being elaborated (as noted in the paper).
- Compute and cost: Recursive segmentation and indexing add overhead; real-time deployments need efficient approximations and caching.
- Human factors: Tying K/entropy to comprehension or working memory requires careful, ethical validation across diverse populations and contexts.
Glossary
- Agentic semantic chunking: LLM-driven segmentation that actively decides chunk boundaries based on meaning rather than fixed window sizes. "embedding-based and agentic semantic chunking methods have become popular alternatives to fixed-size chunking"
- Asymptotic Equipartition Property: Information-theoretic property where, for large sequences, most realizations have per-symbol log-likelihood close to the entropy rate. "exhibits an Asymptotic Equipartition Property: namely, in the limit of large the normalized negative log-likelihood of a tree converges (in probability) to the entropy rate:"
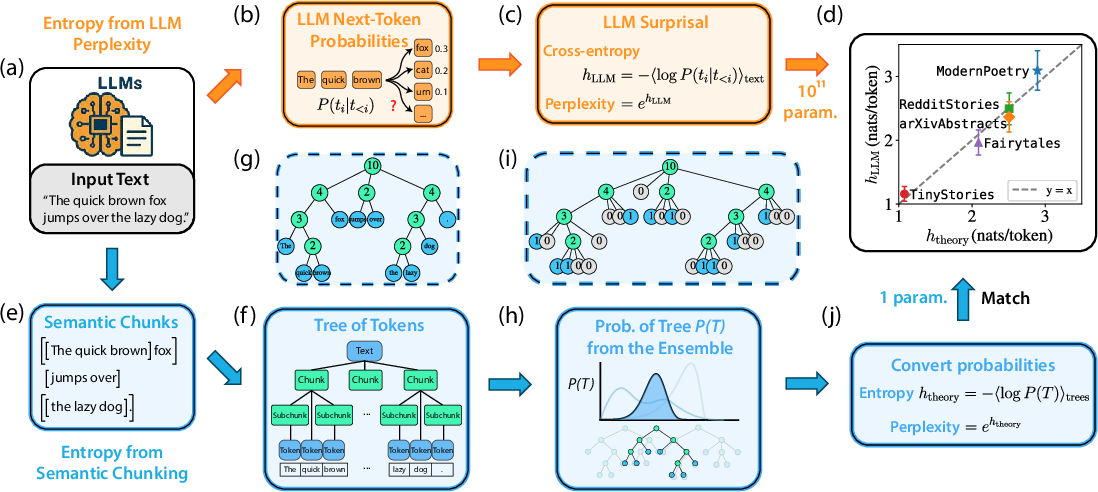
- Auto-regressive LLMs: Models that predict the next token given previous context, trained by minimizing cross-entropy on text. "Auto-regressive LLMs \cite{vaswani2017attention,radford2018improving} are trained to approximate this conditional distribution by minimizing cross-entropy loss on observed text"
- Beta distribution: A continuous probability distribution on (0,1) used here to model random split ratios between chunk sizes. "p_B(r) = (K-1)(1-r){K-2} = \text{Beta}(1,K-1)."
- Cumulative surprisal: The total negative log-probability across all tokens in a text, used to estimate entropy rate via its slope versus length. "Cumulative LLM surprisal for 100 texts from each corpus (color indicates text length )."
- Density of states: A count function over internal nodes by size at a given level, weighting entropy contributions from possible split configurations. "where is the density of states measuring the number of internal nodes of size at level ,"
- Discourse parsing: Document-level analysis of text structure and relations beyond sentence boundaries, often based on rhetorical theories. "Above the sentence level, discourse parsing can be pursued using rhetorical theories \cite{mann1988rhetorical}, but these approaches often depend on expensive manual annotation and exhibit limited scalability"
- Entropy rate: Average uncertainty per token in a sequence, defined via the conditional distribution of the next token given its context. "We define the entropy rate of language as the uncertainty associated with the next word/token given its preceding context."
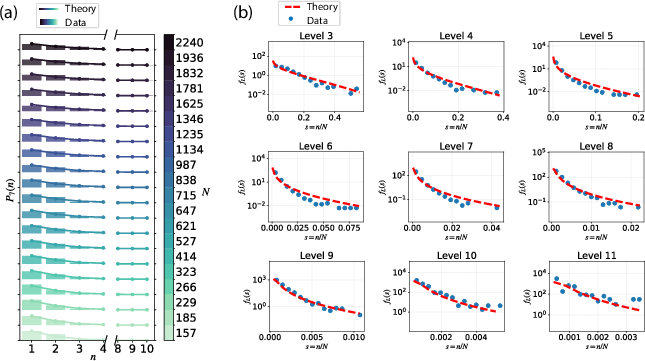
- Harmonic numbers (first and second kind): Special sums that parameterize the mean and variance of the lognormal scaling limit of chunk sizes. "where and denote the harmonic numbers of the first and second kind, respectively."
- K-ary random-tree ensemble: A probabilistic model of hierarchical text splits where each node has up to K children, enabling analytic predictions of tree statistics. "the collection of such trees forms an empirical approximation to a -ary random-tree ensemble that admits analytic treatment."
- KL divergence: A measure of discrepancy between distributions, used to compare empirical and theoretical chunk-size statistics. "we measure the discrepancy between empirical and theoretical ensembles using the KL divergence, averaged across tree levels."
- Lognormal distribution: A distribution whose logarithm is normal; here, the scaling functions for chunk sizes converge to a lognormal family at large depth. "Using renormalization-group analysis (SI), we show that for , converges to a lognormal family whose parameters are determined by and :"
- Log-perplexity: The logarithm of perplexity, equal to the per-token cross-entropy rate estimated by an LLM. "It is also referred to as the log-perplexity \cite{jelinek1977perplexity,huggingface_transformers_perplexity}, $h_{\mathrm{LLM} = \log \mathrm{PPL}$."
- Markov chain: A memoryless stochastic process; here, child chunk sizes depend only on the parent size via the splitting kernel. "which defines an Markov chain over chunk sizes (SI)."
- Multiplicative convolution: A transformation combining distributions via multiplication of random variables; used to relate scaling functions across tree levels. "successive levels are related by a multiplicative convolution with a Beta-distributed random variable ,"
- Random recursive partition: A stochastic process recursively splitting a text into shorter chunks, forming the basis of the ensemble model. "the corresponding ensemble of trees can be approximated by a random recursive partition of texts into shorter and shorter chunks."
- Renormalization-group analysis: A method to study behavior across scales; used to derive the lognormal scaling limit of chunk-size distributions. "Using renormalization-group analysis (SI), we show that for , converges to a lognormal family"
- Semantic chunking: Segmentation of text into contiguous, semantically coherent units to preserve meaning across scales. "semantic chunking seeks to segment a document into contiguous, semantically coherent units, such that each chunk is as self-contained as possible with respect to meaning and linguistic information"
- Semantic tree: A hierarchical representation of a document in which nodes are coherent spans and leaves are tokens. "thereby parsing the document into a hierarchical tree of spans whose leaves are tokens (a ``semantic tree'')."
- Surprisal (per-token): The negative log-probability of a token given its context, forming the basis of cross-entropy estimates. "The resulting per-token surprisal sequence, , averaged over tokens, yields the model's cross-entropy rate estimate."
- Weak-integer ordered-partition process: A splitting model that allows zero-sized children, uniformly distributing K-way partitions of a parent size. "We model the induced token tree as a random weak-integer ordered-partition process (Fig.~\ref{fig:schematics}(i); details in the next section)."
- Working memory capacity: A cognitive limit on the number of simultaneously maintained semantic chunks; here constrains the branching factor K. "we assumed that the splitting parameter of this ensemble, namely the maximal number of children for each node, is limited by working memory capacity."
Collections
Sign up for free to add this paper to one or more collections.