Large language models and the entropy of English
Abstract: We use LLMs to uncover long-ranged structure in English texts from a variety of sources. The conditional entropy or code length in many cases continues to decrease with context length at least to $N\sim 104$ characters, implying that there are direct dependencies or interactions across these distances. A corollary is that there are small but significant correlations between characters at these separations, as we show from the data independent of models. The distribution of code lengths reveals an emergent certainty about an increasing fraction of characters at large $N$. Over the course of model training, we observe different dynamics at long and short context lengths, suggesting that long-ranged structure is learned only gradually. Our results constrain efforts to build statistical physics models of LLMs or language itself.
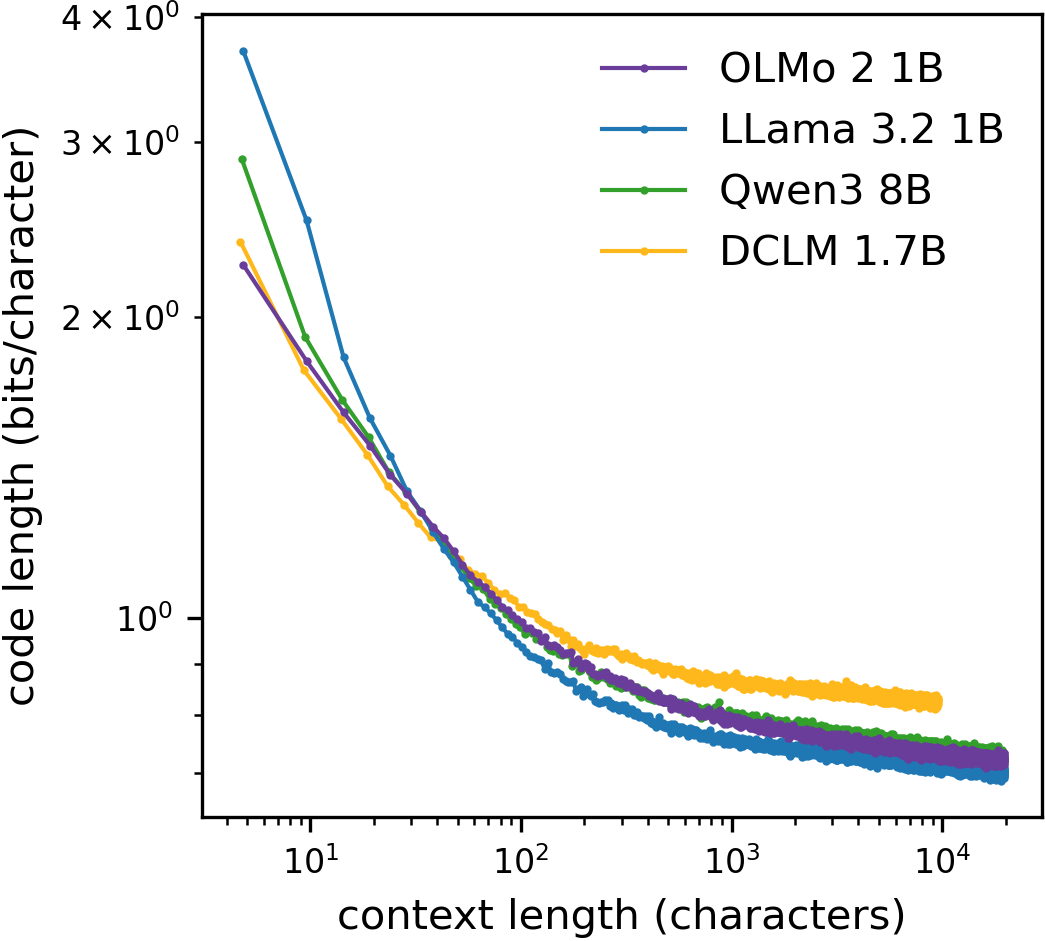
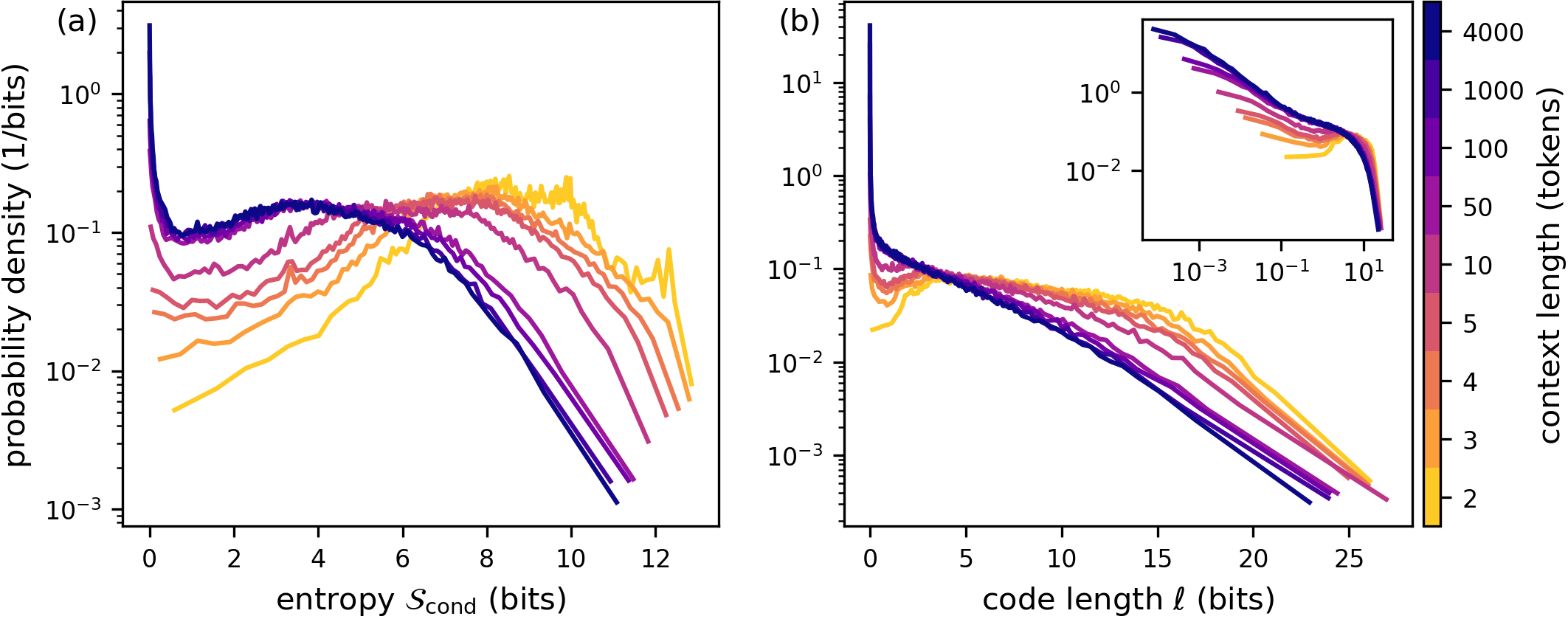
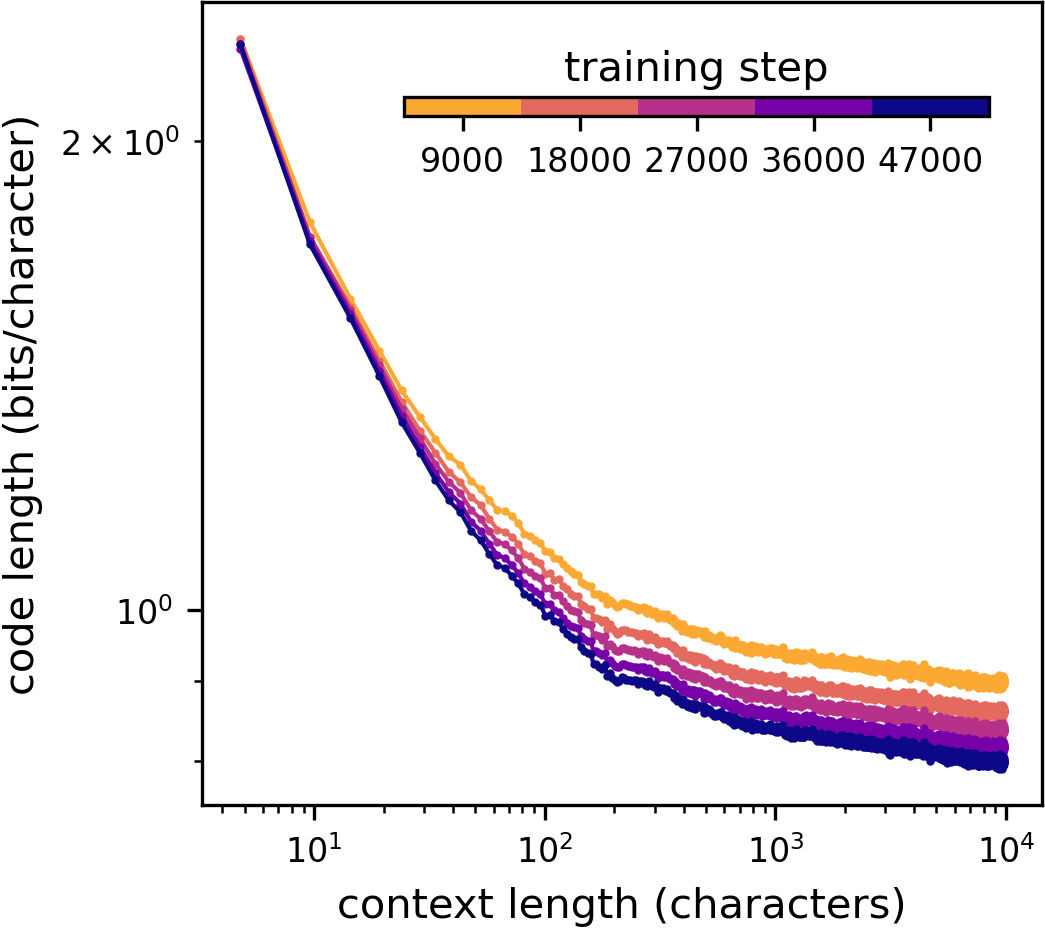

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but deep question: how predictable is English text when you read a lot of it? The authors use modern LLMs—the same kind of AI that powers chatbots—to measure how much knowing the previous part of a text helps you guess the next character. They find that even when you look thousands of characters back, the past still helps, which means English has patterns that stretch across long distances in the text.
What questions did the researchers ask?
- Does the “uncertainty” about the next character keep shrinking as you read more of the text, even across very long distances (thousands of characters)?
- Are there tiny but real connections between characters (like letters and spaces) that are far apart in a text?
- Do different kinds of writing (like poetry vs. Wikipedia) show different long-range patterns?
- How do LLMs learn these long-range patterns during training—quickly or slowly?
- What do these facts tell us about how language is structured and how we should model it?
How did they study it?
To keep things simple, here are a few key ideas they used, explained in everyday terms:
- Entropy: Think of entropy as “how surprised you are” by the next character. High entropy means it’s hard to guess; low entropy means it’s easier.
- Conditional entropy: This is how surprised you are about the next character after you’ve seen the previous N characters. If seeing more of the past makes you less surprised, that means the text has helpful patterns.
- Code length: Imagine you’re sending a message and want to use as few bits as possible. If the next character is very predictable, you can use fewer bits. Code length is a way to measure that. Lower code length means better prediction.
- Tokens vs. characters: LLMs don’t read one letter at a time; they read “tokens,” which are pieces of text (like words or word parts). For fairness across models, the authors convert everything to characters, since a character (like “a” or “!”) is the same everywhere.
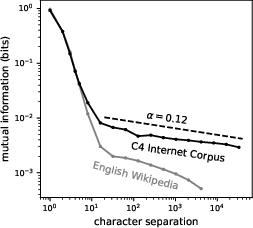
- Mutual information: This measures how much knowing one character tells you about another character far away. If it’s not zero—even after thousands of characters—that means there are long-range connections in the text.
What they did:
- They fed real text from different sources (like Wikipedia, news, internet pages, and poetry) into several open LLMs.
- For each spot in the text, they asked the model: “Given the last N characters, how likely is the next character?” From that, they computed the code length and conditional entropy.
- They repeated this for many N values, from small (dozens of characters) up to very large (around 10,000 characters).
- Separately, they measured mutual information directly from huge text datasets to see if far-apart characters really are linked.
- They also watched how a model picks up long-range patterns during training.
What did they find, and why does it matter?
Here are the main results, explained simply:
- The more of the text you’ve seen, the easier it is to predict the next character—even when “more” means thousands of characters. The average “surprise” (entropy) and code length keep decreasing with longer context, without flattening out in many kinds of text.
- This means English has long-range structure. It’s not just local spelling and grammar rules; themes, topics, styles, and repeated patterns across whole paragraphs or pages help you guess what comes next.
- There are small but real connections between characters very far apart. The authors measured mutual information (how much one character tells you about another far away) and found nonzero values even across thousands of characters. That’s strong evidence for long-range patterns.
- The distribution of predictability changes with longer context. As the model reads more of the text, a noticeable chunk of next characters become almost certain. In other words, long context creates “emergent certainty” for some tokens.
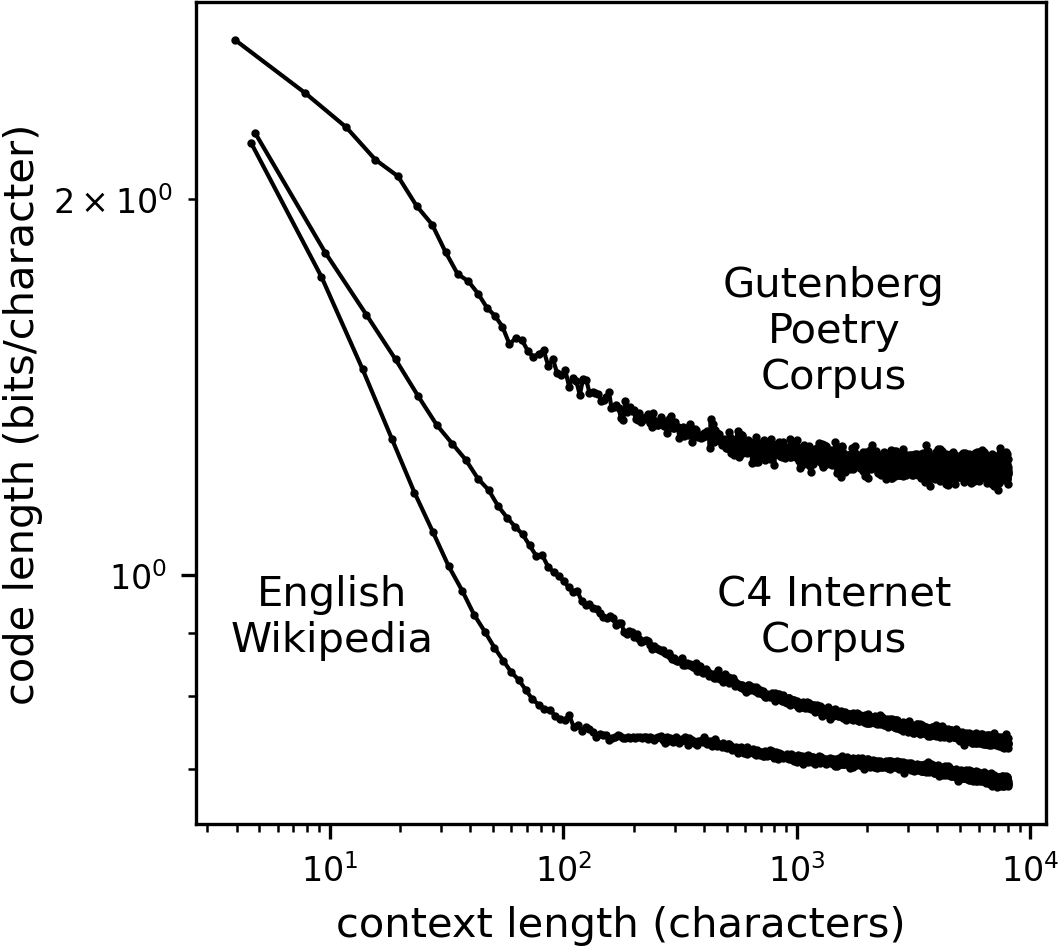
- Different genres behave differently. Poetry seems to reach a plateau sooner (it becomes less predictable and stops improving much with longer context), while Wikipedia and internet text keep getting more predictable as context grows.
- Long-range patterns are learned slowly during model training. Models quickly learn short-range rules (like spelling and punctuation), but they only gradually get better at using very long context.
Why this matters:
- It shows that language isn’t just a chain of short, local rules. There are big-picture patterns that stretch across entire sections, and LLMs can detect and use them.
- It suggests we should build models and theories of language that include long-range links, not just nearby ones.
- It helps explain why LLMs get better when you give them longer context windows: they can capture more of the long-distance structure.
What does this mean for the future?
- Better models: If long-range structure matters, future LLMs should be designed to handle and learn from very long contexts—even longer than they do now.
- New theories: People who build “physics-like” models of language will need to include long-range interactions or shared global themes, not just local grammar rules. Simple short-range models won’t be enough.
- Practical uses: Tasks like summarization, long-form writing, and tracking topics across documents can benefit from models that understand these far-reaching patterns.
- Language understanding: This work suggests that English (and likely other languages) has deep, layered structure—like topics, styles, and narrative threads—that shape predictability over long stretches of text.
In short, the paper shows that even across thousands of characters, the past still helps predict the future in English text. That discovery pushes us toward models and theories that treat language as a system with long-distance ties, not just a string of short, local rules.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved in the paper and could guide future research.
- Ground-truth entropy beyond small contexts: No direct, model-independent estimates of English’s conditional entropy at large ; compare LLM code lengths against non-LLM compressors (e.g., PPM/LZMA/CMIX) and character-level probabilistic models to bound or validate trends up to .
- Model calibration effects: The paper does not assess whether models’ probability distributions are calibrated; quantify calibration (e.g., expected calibration error, temperature scaling) and its impact on the observed gap between mean code length and mean conditional entropy (especially notable for Qwen3).
- Short- discrepancies across models: Large disagreements for are unexplained; isolate causes (tokenizer differences vs training/data differences) via controlled tests using a unified tokenizer, character-level models, and identical training corpora.
- Tokenization-to-character conversion bias: Using a global mean to convert token context lengths into characters may distort ; compute per-token character-normalized code lengths to obtain true per-character quantities and assess robustness across contexts and corpora.
- Data contamination and training overlap: The extent to which evaluation corpora overlap with each model’s pretraining/posttraining data is unclear; systematically audit contamination, leverage time-stamped datasets (e.g., LatestEval) and true held-out corpora to ensure independence.
- Corpus composition confounds: C4 likely contains boilerplate, templates, markup, and repeated fragments that can induce long-range predictability; re-run analyses on curated “clean prose” subsets (e.g., novels, essays) to separate linguistic structure from web artifacts.
- Genre differences not mechanistically explained: The apparent plateau in poetry and higher code lengths lack mechanistic interpretation; disentangle effects of line breaks, meter, rhyme, fixed forms, and punctuation by stratified analyses within poetry subgenres and by removing carriage returns.
- Emergent certainty characterization: The near power-law divergence in small code lengths at large is described but not decomposed; identify which token classes (spaces, punctuation, numerals, markup, stopwords, named entities) dominate this phenomenon and measure class-specific exponents.
- Mapping between decay and scaling: The relationship between observed code-length decay and mutual information power laws is not derived; develop a theoretical link (e.g., via Fano-type bounds or predictive-state representations) and fit exponents consistently across measures.
- Statistical bias in mutual information estimates: While a sampling floor is noted, no bias correction is applied; use standard MI bias corrections (Miller–Madow, Bayesian, permutation baselines) and confidence intervals to validate significance at large .
- Heterogeneity in long-range correlations: is aggregated at the corpus level; quantify document-level variability (distribution of across segments), identify outliers, and test whether power-law behavior is driven by a subset of highly correlated documents.
- Topic/latent-variable confounding: Long-range correlations may arise from latent topics or document-level variables; compute conditional MI given topic labels or learned topic embeddings, and assess how much of decay and the “bag-of-topics” mean-field model can explain.
- Interaction vs correlation inference: The conclusion about direct long-range “interactions” is suggestive but not formally tested; estimate conditional dependencies (e.g., conditional MI controlling for intermediate context) to distinguish direct interactions from mediated correlations.
- Training dynamics generality: Only one small model (DCLM 1.7B) is analyzed for learning trajectories; replicate training-curves across scales (1B–70B), context windows, positional encodings, optimizers, and training mixtures to test whether slow improvements at large are universal.
- Architecture effects on measured structure: The role of positional encoding (absolute vs relative), attention variants (GQA), and context window size in shaping observed trends is not isolated; conduct ablations to quantify how architectural choices alter long-range entropy decay.
- Contribution of post-training: Models differ in post-training/distillation regimes; test whether SFT/DPO/RL or strong-to-weak distillation increases near-certainty peaks or accelerates long-range compression independently of pretraining corpus size.
- Extrapolation to infinite context: Whether vanishes as (Hilberg’s conjecture) remains untested; perform rigorous model selection among plateau, logarithmic, and power-law decays, with uncertainty bands and cross-corpus comparisons.
- Word-level and n-gram analyses: The study focuses on characters; replicate MI and code-length distributions at word and subword levels to determine the scale(s) at which long-range dependencies predominantly operate.
- Cross-linguistic generality: Results are limited to English; test whether long-range entropy decay and power laws hold in languages with different morphology and syntax (e.g., agglutinative, inflectional, non-segmented scripts).
- Robustness to structural shuffles: Establish causal sources of long-range structure by shuffling at controlled scales (e.g., sentence, paragraph, document), preserving local syntax but destroying discourse-level coherence, and measuring resultant changes in and .
- Per-token vocabulary effects: Differences in token vocabulary size and segmentation strategies across models (e.g., 100k vs ~32k BPE) are not controlled; normalize with a shared tokenizer to test whether observed trends are model- or tokenizer-induced.
- Role of numbers, lists, and references: Repetitive numerical patterns, citations, and tables may drive predictability; stratify analyses to quantify their impact on emergent certainty and long-range MI.
- Segment selection biases in MI: For C4, only the first segment of long strings is used, while Wikipedia uses all segments; standardize segment selection (e.g., random, multiple, overlapping) to avoid boundary-induced biases.
- Variance reporting: Error bars are said to be smaller than point-to-point “hash,” but no detailed uncertainty quantification is provided; report confidence intervals, bootstrapped variability across documents, and sensitivity to sampling choices.
- Baselines beyond LLMs: The paper lacks comparisons to classical LLMs (n-gram with Kneser–Ney, HMMs, PCFGs); include such baselines to attribute observed long-range compression specifically to LLMs versus simpler models.
- Document structure cues: Headers, footers, HTML, code fences, and repeated page templates may inflate predictability; explicitly strip structural elements and compare entropy decay before/after cleaning.
- Training/test splits for DCLM experiments: Potential overlap between training shards and evaluation strings is not ruled out; enforce strict de-duplication and document-level holdouts when tracking training dynamics.
- Conditional entropy vs code length agreement: The near equality in three models and systematic mismatch in Qwen3 are noted but unexplained; analyze whether this stems from calibration, label smoothing, z-loss, or different objective/regularization regimes.
- Toy statistical physics models: No concrete toy model is proposed; develop and validate minimal models (finite-range interactions, hierarchical grammar, latent-topic mean-field) that replicate observed decay, scaling, and emergent certainty distributions.
- Practical ceiling of context lengths: The study is capped by model context windows and tokenization; extend to ultra-long-context models and retrieval-augmented systems to test whether the entropy keeps declining past .
- Mechanistic attribution (syntax vs semantics): The paper observes long-range structure but does not parse its sources; use controlled corpora (syntactically well-formed but semantically random vs semantically coherent but syntactically simplified) to separate contributions.
- Per-genre normalization: Differences in average characters per token and formatting across genres can bias per-character ; normalize by genre-specific tokenization and style markers to obtain fair cross-genre comparisons.
- Space and punctuation dominance: Spaces and common punctuation are frequent and predictable; explicitly quantify their contribution to low-entropy peaks and assess whether results persist after masking or reweighting these classes.
- Consistency of power-law exponents: The C4 MI exponent () is reported without uncertainty or cross-corpus fit; estimate exponents with confidence intervals and test goodness-of-fit against alternative models (stretched exponential, log-linear).
- Document boundaries in evaluation: Random start offsets and fixed-length token crops may mix intra- and inter-paragraph contexts; enforce within-document, paragraph-aware sampling to avoid boundary effects in curves.
- Time dynamics and novelty: The promise of time-stamped corpora is noted but not exploited; quantify whether post-cutoff texts (novel events) exhibit different decay and , indicating dependence on prior exposure/memorization.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient update, improving stability and generalization. "We used AdamW \cite{loshchilov2017decoupled} as our optimizer with default hyperparameters"
- Absolute positional embeddings: Fixed position-specific vectors added to token representations to encode absolute positions. "We use absolute positional embeddings, imposing a maximum context length of 2048 tokens."
- Auxiliary field: A global latent variable that mediates interactions among local variables in mean-field style models. "an auxiliary field or latent variable"
- Bag-of-words model: A text model that ignores word order and represents documents as unordered multisets of words. "the classical ``bag of words'' model"
- Code length: The number of bits needed to encode the next token under the model’s predicted distribution. "this code length bounds the conditional entropy of the real text."
- Conditional entropy: The expected uncertainty (in bits) of the next symbol given its context. "The conditional entropy or code length in many cases continues to decrease with context length"
- Context length: The number of preceding tokens/characters the model conditions on for prediction. "with a context length of 128,000 tokens."
- Cosine-decay with linear warm-up (learning rate schedule): A schedule that increases LR linearly at first, then decays it following a cosine curve. "we used a cosine-decay with linear warm-up learning rate schedule"
- Cross-entropy loss: A negative log-likelihood objective measuring how well predicted distributions match true tokens. "and a standard cross-entropy loss function with an additional z-loss hyperparameter"
- Decoder-only Transformer: A Transformer architecture using only the decoder stack for autoregressive next-token prediction. "All models consist of a decoder-only Transformer"
- Direct Preference Optimization (DPO): A post-training method that aligns models to human or synthetic preferences by optimizing a preference-based objective. "Direct Preference Optimization (DPO)"
- Emergent certainty: A phenomenon where, at long contexts, next-token predictions become nearly deterministic for a growing fraction of cases. "an emergent certainty about an increasing fraction of characters at large ."
- Entropy per character: Information content averaged per character in a text sequence. "the conditional entropy per character approached a plateau for ."
- Grouped-Query Attention (GQA): An attention variant that groups queries to share key/value projections, improving efficiency. "Grouped-Query Attention (GQA)"
- Hierarchical structures: Multi-level generative or dependency structures (e.g., grammar-like) that induce long-range interactions. "hierarchical structures inspired by grammar"
- Knowledge cutoff: The latest date of data included in training, after which the model has not been updated. "with a knowledge cutoff of December 2023"
- Latent variable: An unobserved variable that influences observed data and can explain long-range dependencies. "latent variable that is common across the whole length of the string."
- Logits: Pre-softmax scores output by the model for each token before converting to probabilities. "Additionally, logits from Llama 3.1 8B and 70B were incorporated into the pre-training stage: these logits were used as token-level targets."
- Mean conditional entropy: The average conditional entropy across samples/contexts. "the mean conditional entropy"
- Mean--field model: An approximation replacing many interactions with an average (global) field shared across variables. "mean--field like model"
- Mutual information: A measure (in bits) of statistical dependence between two variables. "The mutual information then is"
- Off-Policy Distillation: Distilling a student model from trajectories or data produced by a separate (teacher) policy/distribution. "Off-Policy Distillation"
- On-Policy Distillation: Distilling using data generated by the student’s own policy during training. "On-Policy Distillation"
- Positional encoding: Mechanisms for injecting token position information into Transformer models. "in the absence of explicit positional encoding"
- Power--law: A scaling relationship where a quantity varies as a constant times a power of another variable. "an approximately power--law divergence in the distribution"
- QK-norm: Query-Key normalization within attention layers to stabilize and improve training. "with QK-norm \cite{henry2020querykeynormalizationtransformers}"
- Rejection Sampling (RS): A sampling technique that generates samples from a target distribution via accept/reject steps. "Rejection Sampling (RS)"
- Reinforcement learning with verifiable rewards: RL-based post-training where rewards derive from criteria that can be checked or validated. "final reinforcement learning with verifiable rewards."
- Scale-invariant correlations: Statistical dependencies that exhibit the same form across scales (no characteristic scale). "scale-invariant correlations"
- Strong-to-Weak Distillation: Knowledge transfer from a stronger (larger/better) teacher model to a weaker (smaller) student. "Strong-to-Weak Distillation"
- Sub--extensive entropy: Entropy that grows slower than linearly with sequence length, implying vanishing per-character entropy. "the entropy of texts would be sub--extensive"
- Supervised Fine-Tuning (SFT): Post-training on labeled instructions or datasets to align outputs with desired behavior. "Supervised Fine-Tuning (SFT)"
- Tokenization: The process of splitting text into discrete units (tokens) for model input. "We tokenize and shuffle the data"
- Tokenizer: The algorithm/model that performs tokenization, mapping text to token IDs. "Each model uses a different tokenizer to convert text at the character level to discrete tokens."
- z-loss: An auxiliary loss term added to stabilize training by controlling the scale of logits. "z-loss hyperparameter"
Practical Applications
Immediate Applications
The following items can be deployed with current models, corpora, and infrastructure, leveraging the paper’s methods (code-length/conditional-entropy curves L(N), s(N), their distributions, and empirical mutual information I(d)).
- Long-context model evaluation and benchmarking beyond perplexity
- What: Add L(N), s(N), and the “low-entropy token fraction vs N” to model dashboards to track long-range predictability up to 104 characters.
- Sectors: Software/ML, academia, benchmarking organizations.
- Tools/Products/Workflows: Evaluation plugins for training pipelines; CI regression checks on L(N) curves; leaderboards reporting L(N) slopes at long N.
- Assumptions/Dependencies: Access to token log-probabilities; sufficiently long context windows for evaluation; representative corpora for target domains.
- Training diagnostics and curriculum design for long-range structure
- What: Monitor how L(N) improves at large N during training and reweight data/curricula to accelerate long-range dependency learning (the paper shows short-N converges early, long-N improves slowly).
- Sectors: Software/ML, model providers.
- Tools/Products/Workflows: Training hooks that compute L(N) at checkpoints; curriculum schedules that progressively increase document length and genre mix; data selection prioritizing long-range coherence.
- Assumptions/Dependencies: Control over training; compute budget for periodic long-context probes.
- MI-guided chunking and context windows for retrieval-augmented generation (RAG)
- What: Use empirical mutual information I(d) on in-domain text to set chunk sizes, overlaps, and windowing policies that preserve cross-chunk dependencies (e.g., legal, EHR notes).
- Sectors: Enterprise search, healthcare, legal, education.
- Tools/Products/Workflows: “MI-guided chunker” libraries for vector databases; heuristics that pick overlap where I(d) crosses a threshold.
- Assumptions/Dependencies: Availability of sufficient in-domain text to estimate I(d); domain drift can change optimal parameters.
- Coherence and readability feedback for authors and editors
- What: Writing assistant that visualizes entropy decay across a document and flags sections where long-range coherence is weak (e.g., flat L(N) vs baseline for the genre).
- Sectors: Publishing, education, technical writing.
- Tools/Products/Workflows: Editor plugins (e.g., VS Code/Google Docs) showing L(N) curves per section with actionable suggestions (add referents, recap context).
- Assumptions/Dependencies: Privacy-preserving local or on-prem inference; genre baselines for comparison; explainable feedback mapping statistics to edits.
- Content forensics and authorship stylometry
- What: Use L(N) slopes, low-entropy tail mass, and I(d) profiles as features for authorship attribution and detection of anomalous or synthetic documents.
- Sectors: Media integrity, security, compliance.
- Tools/Products/Workflows: Classifiers combining entropy/MI features with other stylometrics; triage alerts for documents with abnormal long-range statistics.
- Assumptions/Dependencies: Well-curated labeled datasets; sensitivity to domain and language; adversarial robustness remains a challenge.
- Dataset contamination and temporal leakage checks
- What: Evaluate models on time-stamped corpora (e.g., news) and compare long-N code-lengths across pre/post windows to detect inadvertent exposure.
- Sectors: Academia, evaluation providers, model governance.
- Tools/Products/Workflows: Time-sliced test harnesses; monitoring dashboards that flag suspicious performance shifts at long context lengths.
- Assumptions/Dependencies: Reliable timestamped datasets and documentation; results depend on similarity between training and test distributions.
- Dynamic decoding control using “emergent certainty”
- What: Exploit the growing near-zero-entropy mass at large N to implement early stopping, temperature decay, or token-level gating when confidence spikes.
- Sectors: ML inference, content generation platforms.
- Tools/Products/Workflows: Certainty-based decoding controllers; guardrails that slow generation when low-entropy runs suggest boilerplate repetition.
- Assumptions/Dependencies: Access to per-token conditional entropy at inference; careful calibration to avoid truncating necessary content.
- Compression for long texts using model probabilities
- What: Apply arithmetic coding with next-token probabilities from a local LLM to compress large documents/logs with better ratios on long contexts.
- Sectors: Storage/CDN, enterprise IT.
- Tools/Products/Workflows: “LLM-compress” utilities integrated with archival pipelines; selective use for corpora where L(N) decays strongly.
- Assumptions/Dependencies: Throughput constraints; licensing for model weights; reproducible decoding; cost–benefit vs classical compressors.
- Genre-aware routing and model selection
- What: Route tasks to models trained/tuned for genres with matching long-range structure (e.g., poetry vs encyclopedic prose) based on observed L(N) patterns.
- Sectors: Content generation, localization.
- Tools/Products/Workflows: Routers that tag documents by entropy/MI signature and select specialized models/prompts.
- Assumptions/Dependencies: Availability of specialized models; precomputed genre profiles; risk of overfitting to training distribution idiosyncrasies.
- Compliance and anomaly monitoring in long documents
- What: Continuous monitoring of reports, filings, or policies for long-range inconsistency (e.g., sections whose L(N) deviates from organizational baselines).
- Sectors: Finance, legal, regulated industries.
- Tools/Products/Workflows: Document QA pipelines that compute entropy/MI features and flag sections for human review.
- Assumptions/Dependencies: Strong internal baselines; human-in-the-loop review; sensitivity to stylistic diversity across teams.
Long-Term Applications
These rely on further research, scaling, or standardization before broad deployment.
- Architectures with explicit long-range interactions or latent global variables
- What: Models that embody the paper’s evidence for direct dependencies across ~104 characters (e.g., hierarchical, mean-field + local interactions, or power-law attention).
- Sectors: Software/ML, hardware co-design.
- Tools/Products/Workflows: New transformer variants or hybrid statistical-physics-inspired architectures; memory mechanisms aligned to measured I(d).
- Assumptions/Dependencies: Demonstrated efficiency and accuracy gains; training stability at scale; hardware support for long-range kernels.
- Standardized long-context evaluation protocol for industry
- What: Establish L(N), s(N), and I(d) reporting as required metrics for LLM releases, alongside perplexity and downstream tasks.
- Sectors: Policy/standards, ML governance.
- Tools/Products/Workflows: Public benchmarks with time-stamped corpora; certification badges for long-context robustness.
- Assumptions/Dependencies: Community consensus; reproducible datasets; API support for log-probs across providers.
- Broadly deployable next-generation text compression
- What: Production-grade compressors that consistently beat classical baselines on diverse domains by exploiting long-range predictability.
- Sectors: Storage/CDN, mobile, edge.
- Tools/Products/Workflows: Efficient quantized local models; streaming codecs that maintain long-range state.
- Assumptions/Dependencies: Orders-of-magnitude speedups vs current LLM inference; deterministic decoding; legal and IP clarity.
- Domain-specialized long-context models for safety-critical documentation
- What: Models trained to capture long-range dependencies in clinical notes, trial protocols, contracts, and standards, improving summarization and QA fidelity.
- Sectors: Healthcare, legal, engineering.
- Tools/Products/Workflows: Fine-tuning on domain corpora with long-context objectives; MI-guided data selection; evaluation via domain-specific L(N) improvements.
- Assumptions/Dependencies: Secure access to proprietary data; rigorous validation; compliance with privacy regulations.
- Misinformation and provenance detection via long-range statistics
- What: Use deviations in I(d) and long-N entropy patterns as part of ensemble methods to flag manipulated narratives or synthetic campaigns spanning documents.
- Sectors: Public policy, platforms, media.
- Tools/Products/Workflows: Cross-document statistical monitors; provenance scoring integrated with content moderation.
- Assumptions/Dependencies: Stability of signals across languages and cultures; resistance to adversarial adaptation; ethical frameworks.
- Robust watermarking using long-range statistical signatures
- What: Embed or detect subtle, distributed patterns in long-range dependencies that survive paraphrase and local edits better than short-range watermarks.
- Sectors: AI safety, IP protection.
- Tools/Products/Workflows: Encoder/decoder schemes that modulate low-entropy tail properties or I(d) slopes.
- Assumptions/Dependencies: Theoretical guarantees; negligible impact on quality; low false positives.
- Adaptive context budgeting for resource-constrained agents
- What: Predict marginal utility of longer context from observed L(N) slopes to allocate memory/attention dynamically in on-device or robotic systems.
- Sectors: Robotics, mobile AI, embedded systems.
- Tools/Products/Workflows: Controllers that extend/shrink context on the fly; cost–benefit policies based on entropy decay forecasts.
- Assumptions/Dependencies: Fast, low-overhead estimators; robust generalization across tasks.
- Learning science and pedagogy informed by long-range structure
- What: Curricula and tools that teach students to build long-range coherence in writing using entropy/MI feedback; research on reading comprehension vs L(N) profiles.
- Sectors: Education, edtech.
- Tools/Products/Workflows: Classroom analytics; student dashboards that target coherence over multi-paragraph spans.
- Assumptions/Dependencies: Teacher adoption; validation that metrics correlate with human judgments and outcomes.
- Literary analytics and cultural studies at scale
- What: Compare genres/authors via entropy distributions and I(d) decay (e.g., poetry’s earlier plateau vs prose), enabling new quantitative humanities research.
- Sectors: Academia (digital humanities).
- Tools/Products/Workflows: Open corpora+toolkits for long-range statistics; repositories of genre baselines.
- Assumptions/Dependencies: Copyright-safe corpora; careful interpretation to avoid reductive conclusions.
- Data governance and curation optimized for long-range learning
- What: Policies and pipelines that prioritize documents and mixes shown to improve long-N performance (e.g., de-duplication strategies that preserve long-range diversity).
- Sectors: Policy, ML ops.
- Tools/Products/Workflows: Data audit reports tracking contributions to L(N) at different scales; procurement guidelines.
- Assumptions/Dependencies: Transparent data documentation; measurable link from curation choices to long-context gains.
Notes on cross-cutting assumptions and dependencies
- Representativeness: The paper focuses on English; extension to other languages and modalities (source code, multilingual corpora) requires fresh measurement.
- Measurement fidelity: Code length is an upper bound on true conditional entropy and depends on model calibration and tokenization; comparisons should standardize to character-level lengths as in the paper.
- Scale of data: Accurate I(d) estimates at long distances are data-hungry; smaller domains may need transfer of shape parameters (e.g., tail exponents) from larger corpora.
- Model access: Many applications depend on access to token-level probabilities (logprobs), which some closed APIs restrict.
- Training–test contamination: Genre differences may reflect training data exposure; time-stamped evaluation sets mitigate but do not eliminate this risk.
- Compute and latency: Long-context analysis and model-based compression can be computationally expensive; practical deployments need efficient approximations or local models.
Collections
Sign up for free to add this paper to one or more collections.