LaCy: What Small Language Models Can and Should Learn is Not Just a Question of Loss
Abstract: LLMs have consistently grown to compress more world knowledge into their parameters, but the knowledge that can be pretrained into them is upper-bounded by their parameter size. Especially the capacity of Small LLMs (SLMs) is limited, leading to factually incorrect generations. This problem is often mitigated by giving the SLM access to an outside source: the ability to query a larger model, documents, or a database. Under this setting, we study the fundamental question of \emph{which tokens an SLM can and should learn} during pretraining, versus \emph{which ones it should delegate} via a \texttt{<CALL>} token. We find that this is not simply a question of loss: although the loss is predictive of whether a predicted token mismatches the ground-truth, some tokens are \emph{acceptable} in that they are truthful alternative continuations of a pretraining document, and should not trigger a \texttt{<CALL>} even if their loss is high. We find that a spaCy grammar parser can help augment the loss signal to decide which tokens the SLM should learn to delegate to prevent factual errors and which are safe to learn and predict even under high losses. We propose LaCy, a novel pretraining method based on this token selection philosophy. Our experiments demonstrate that LaCy models successfully learn which tokens to predict and where to delegate for help. This results in higher FactScores when generating in a cascade with a bigger model and outperforms Rho or LLM-judge trained SLMs, while being simpler and cheaper.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how to train small LLMs (SLMs) so they make fewer factual mistakes. The authors argue that small models shouldn’t try to remember every fact (like exact dates or names). Instead, they should learn when to “ask for help” from a bigger, smarter model. They introduce a training method called LaCy that teaches a small model to do exactly that.
What questions did the researchers ask?
They focused on two simple questions:
- Which pieces of text should a small model try to predict by itself?
- Which pieces should it “delegate” by asking a bigger model for help?
They show this isn’t just about how “wrong” a guess is. Some wrong guesses are still okay (like choosing a different but reasonable next word), while others cause factual errors (like getting a person’s birthplace wrong). LaCy tries to tell these cases apart during training.
How did they do it?
Think of text as a sequence of tiny pieces called tokens (often parts of words). At each step, the model guesses the next token.
Here’s the idea behind LaCy:
- Small models have limited memory. They can be good at general language (grammar, style), but not at storing countless facts (names, dates, locations).
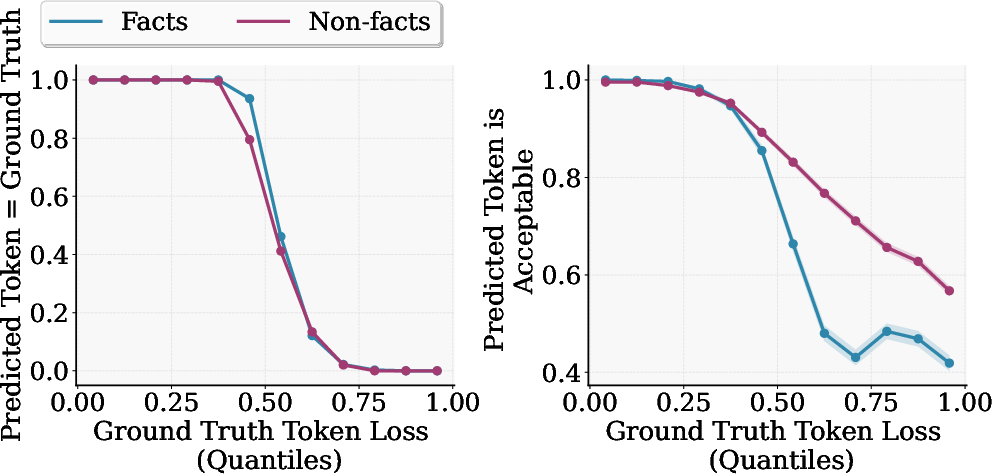
- During training, the model gets a score called “loss.” High loss means it was surprised (its guess didn’t match the training text). But high loss alone doesn’t tell you whether the guess matters for truth.
- The authors use a grammar/linguistic tool called spaCy (a program that tags words as names, places, dates, etc.) to spot tokens that are likely factual and require an exact answer (for example, “Mozart was born in Salzburg” — “Salzburg” must be correct).
- LaCy combines two signals: 1) Is this token a fact-like token (using spaCy)? 2) Is the model struggling with it (high loss)?
- If both are true, the small model is trained to output a special placeholder called a <CALL> token instead of guessing. The <CALL> means “Ask a bigger model to fill this in.”
- At inference time (when the model is actually used), if the small model outputs <CALL>, the system passes the context to a larger model, which fills in the factual token (like supplying “Salzburg”).
Analogy: Imagine writing a report. You write the sentences yourself (style, grammar), but when you reach a specific fact (a birth year), you quickly ask a more knowledgeable friend to confirm it before you write it down.
What did they find?
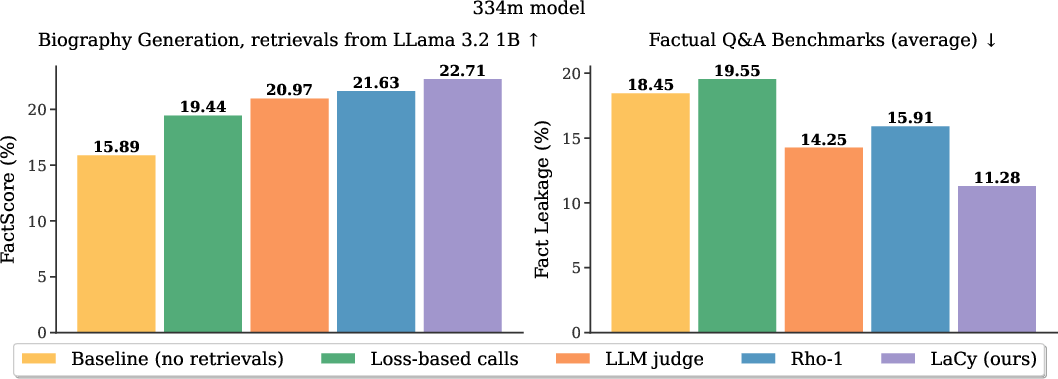
- Better factual accuracy: On a biography-writing task (using Wikipedia-style text), a small model trained with LaCy produced more correct facts when paired with a bigger model. They measured this with FactScore, a metric that checks factual statements against the real Wikipedia page.
- Smarter calling for help: LaCy learns to “call” mostly on tokens that really need precision (names, dates, places) instead of random words. This reduces hallucinations (confident but wrong statements).
- Less “fact leakage”: When they disabled calling and forced the small model to answer factual questions on its own, the LaCy model gave fewer correct answers. That’s actually good here: it shows the small model didn’t memorize lots of facts; it learned to rely on the helper when needed.
- Loss alone isn’t enough: They showed that “loss” (how wrong a guess is) doesn’t tell you whether a token is a fact that must be exact. Some high-loss tokens are harmless (like choosing between “The cat” and “The time”), while some low-loss tokens could still be wrong in a factual way. So combining loss with spaCy’s tags works better.
- Cheap and simple labeling: LaCy’s spaCy-based labeling runs on CPUs and is cheaper than methods that rely on large helper models or GPU-heavy scoring during training.
- General language skills stay intact: Offloading facts didn’t hurt the small model’s reading and reasoning skills (NLU). It still performed similarly on general understanding tasks.
Why does this matter?
LaCy shows a practical way to train small, fast models that know when to ask for help on facts. This can:
- Make small models more trustworthy by reducing factual errors.
- Keep small models efficient (they don’t waste capacity trying to memorize the world).
- Lower training and deployment costs (small model does most of the work; big model steps in only when needed).
- Fit nicely with tool use and retrieval systems (in the future, the <CALL> could trigger web search, databases, or other tools).
In short, the paper argues that small models should learn language and judgment, not memorize everything. Teaching them when to call for help leads to better, more reliable systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable follow-up work:
- Reliability of the factual-token detector: No quantitative precision/recall analysis of the spaCy-based tagging (plus heuristics) on the training domain; error types, span coverage, and boundary accuracy (especially for multi-token entities) are unreported.
- Generality of factual-token detection: It is unclear how well spaCy en_core_web_sm (and the custom heuristics) transfer to other domains (news, scientific, code), genres (dialogue, instructions), and languages; multilingual and domain-specific detectors were not evaluated.
- Formalization and validation of “acceptability”: The definition is heuristic and validated only on a tiny sample with a proprietary LLM; no large-scale, human-annotated, or reproducible protocol exists to measure acceptability reliably.
- Span-level vs token-level delegation: The method delegates at the next-token granularity, but many facts span multiple subword tokens; how to detect, initiate, and terminate span-level calls (entity/date ranges, multiword names) is unaddressed.
- Tokenization mismatches: The SLM uses SentencePiece while the cascade model does not; multi-token returns are noted but not systematically handled or evaluated for their impact on coherence and downstream metrics.
- Numeric/date handling: Numbers and dates are high-risk factual tokens with bounded loss; no targeted rules or detectors were developed to prioritize or tailor delegation for numeric content.
- Call-budget selection and scheduling: The 15% training and 22% inference budgets are fixed and partly chosen for comparability; the optimal fraction, adaptive scheduling over training, and coverage–risk trade-offs remain unexplored.
- Calibration of call thresholds: The running-quantile thresholding at inference is heuristic; robustness under distribution shift, per-domain calibration, and principled selective prediction calibration (e.g., risk-coverage curves) are unstudied.
- Training–inference mismatch: During pretraining, the model never conditions on cascade outputs; the effect of this exposure bias on downstream calling behavior and factuality is unknown, and no methods (e.g., mixed-in teacher forcing with returned spans) were tested.
- Dependency on cascade partner quality: Only two partners (Llama 3.2 1B; one Qwen 32B+RAG ablation) are tried; systematic variation of partner size/quality, RAG configurations, grounding sources, and cost–quality trade-offs is missing.
- End-to-end latency and cost: The paper does not measure inference-time latency, throughput, or cost per token considering call frequency and cascade overhead; practical deployment implications remain unclear.
- Utility vs. redundancy of calls: No detailed error analysis of unnecessary calls (overcalling) versus missed calls (undercalling) and their contribution to factual errors, fluency degradations, or cost.
- Alternative token-type signals: No ablation with other linguistic signals (e.g., constituency/dep parsing, POS tags), stronger NERs, learned factuality classifiers, or ensembles combining multiple detectors.
- Robustness to label noise: Sensitivity of LaCy to mislabeling in spaCy/heuristics is not quantified; no simulations of noise injection or ablations to estimate performance degradation under imperfect labels.
- Scaling behavior: Results center on 334M (main) and 1.3B (appendix) SLMs over ~50B tokens from Wikipedia; scaling trends for larger SLMs, longer training, and heterogeneous corpora remain unknown.
- Decoding effects: Only greedy decoding is used; interactions between sampling-based decoding (temperature/top-p) and the timing/frequency/quality of calls were not analyzed.
- Breadth of evaluation: NLU is limited to a few multiple-choice sets; no assessments on instruction-following, long-context reasoning, code, math, or dialogue to test whether fact offloading helps or hurts broader capabilities.
- Human evaluation: No human judgments of coherence, fluency, style consistency, or perceived factual soundness in cascaded generations, especially with frequent token-level calls.
- Factuality metrics coverage: Results rely on FactScore (biographies); benchmarks like FEVER, TruthfulQA, HoVer, attribution-based QA, and contradiction detection were not tested.
- Objective alignment: While loss is shown to misalign with factuality, no alternative training objective is proposed that directly optimizes factuality/abstention (e.g., selective likelihood, risk-aware losses).
- Privacy and safety: Calling may expose user/contextual data to external models/tools; the paper does not address redaction, privacy constraints, call governance, or post-call safety filtering.
- Verification of cascade outputs: There is no mechanism to validate or reject incorrect cascade returns; strategies for post-hoc verification, cross-checking, or self-consistency are not explored.
- Consecutive/nested calls and long-span retrieval: Handling of back-to-back calls, multi-token retrieval windows, or structured tool outputs (tables, API returns) is out of scope but crucial for practical systems.
- Interaction with instruction tuning/RLHF: Whether the learned calling behavior persists or is overwritten during downstream alignment/finetuning is unknown.
- Stronger uncertainty baselines: Comparisons lack modern selective prediction baselines (e.g., entropy/margin, temperature scaling, conformal prediction, mutual information from ensembles/MC dropout).
- Catastrophic interference and calibration: The effect of introducing <CALL> on probability calibration, long-horizon language modeling quality, and interference with non-factual tokens is not measured.
- Adaptive or curriculum strategies: No investigation into curricula that phase in/out delegation, progressively refine factual detectors, or anneal budgets during training.
- Online/teacher-assisted variants: Combining LaCy with online teacher signals (reference model/RAG) without full two-stage training (e.g., distillation, pseudo-labeling) is an open design question.
- Reproducibility of labeling: The custom spaCy heuristics and exact rule set for fact detection are not fully specified; lack of released code or detailed schemas hinders replication and fair comparison.
- Data contamination checks: The paper does not report contamination analysis between pretraining and evaluation pages in Wikipedia, which could inflate absolute scores.
- Multilingual/code settings: No experiments on multilingual corpora or code-switching; coverage and accuracy of factual detectors and calling behavior in such settings are unknown.
- Downstream cost–quality optimization: There is no principled framework to jointly optimize factuality gains against monetary/latency costs of cascading under production constraints.
Practical Applications
Immediate Applications
The following use cases can be deployed with current tooling, leveraging LaCy’s training recipe (spaCy-based factual token identification + loss-based selection) and standard cascade/RAG stacks.
- Cost‑efficient LLM cascades for enterprise knowledge assistants
- Sector: software, enterprise IT
- What: Train small on‑prem SLMs to handle fluency and “safe-to-guess” tokens, emitting <CALL> only for high‑loss factual tokens; route those to a larger cloud model or RAG stack.
- Tools/products/workflows: spaCy (NER/POS), SentencePiece, vector DB (FAISS/Elasticsearch), cascade partner (e.g., Llama 3.2 1B, Qwen 3 32B), FactScore-based evaluation; deploy as a microservice with a call‑ratio gate.
- Assumptions/dependencies: Larger model or RAG is more factual than the SLM; acceptable cloud latency; security model allows contextual snippets to be sent on <CALL>; tuning of call thresholds to meet cost and quality targets.
- On‑device assistants with selective cloud escalation
- Sector: consumer software, mobile, IoT
- What: Run an SLM locally for conversational flow and grammar; only send to cloud on <CALL> (names, dates, entities) to improve accuracy and reduce data usage.
- Tools/products/workflows: Mobile/edge runtime for SLM, lightweight telemetry to monitor call budget, privacy filters on context before escalation.
- Assumptions/dependencies: Network availability for escalations; privacy constraints on sending context; smaller vocabulary/tokenization alignment between on‑device and cloud models.
- Factual content generation with editorial workflows (bios, product pages, briefs)
- Sector: media, e‑commerce, marketing
- What: Authoring pipelines where the SLM writes prose and defers only for factual spans; editors review retrieved facts explicitly marked as “called”.
- Tools/products/workflows: CMS integration; audit trail that tags called tokens; FactScore monitoring to QA campaigns.
- Assumptions/dependencies: High‑quality cascade partner or RAG corpus (e.g., product catalog, Wikipedia); latency budget compatible with batch generation.
- Retrieval‑Augmented Generation (RAG) trigger gating
- Sector: software, search, enterprise knowledge
- What: Use <CALL> as a learned gate to trigger retrieval only when facts are likely needed; reduce unnecessary retrievals and hallucinations.
- Tools/products/workflows: Retrieval middleware keyed by <CALL> events; hybrid pipelines (SLM → RAG → rewrite).
- Assumptions/dependencies: Accurate entity detection in the domain; RAG index freshness; minimal domain shift relative to training data or updated spaCy rules.
- Customer support chatbots with targeted deferral
- Sector: customer service, telecom, SaaS
- What: SLM handles general conversation; <CALL> triggers a KB lookup or hands off to a larger model for policy, pricing, or account‑specific facts.
- Tools/products/workflows: Integration with ticketing/CRM; dynamic call budgets (risk‑aware gating for account‑critical questions); explainable escalation messages.
- Assumptions/dependencies: Access to up‑to‑date KBs; ability to redact PII before deferral; clear fallback when larger model fails.
- Report and narrative generation with verified numbers/dates
- Sector: finance, operations, analytics
- What: SLM drafts narratives while <CALL> retrieves exact figures (KPIs, dates) from warehouse/ERP via function calls.
- Tools/products/workflows: Tool/function calling instead of LLM cascade (e.g., SQL connectors, API wrappers); typed <CALL> schemas.
- Assumptions/dependencies: Stable APIs/metadata; governance ensuring retrieved values are authoritative; audit trails.
- Safer non‑diagnostic medical knowledge assistants
- Sector: healthcare (informational use only)
- What: SLM manages conversational flow; <CALL> fetches medical facts (drug interactions, guidelines) from vetted sources.
- Tools/products/workflows: UMLS/SNOMED/DailyMed integrations; explicit disclaimers; human‑in‑the‑loop for high‑risk queries.
- Assumptions/dependencies: Strict compliance (HIPAA/GDPR); domain‑tuned fact detectors (beyond general spaCy); regulatory approval for deployment scope.
- Developer assistants that defer on API facts
- Sector: software engineering
- What: SLM suggests code or explanations; <CALL> triggers docs search/static analysis when encountering API names/versions.
- Tools/products/workflows: IDE plugins; docsearch over MDN/StackOverflow/internal docs; call logs for debugging.
- Assumptions/dependencies: Fresh documentation index; appropriate parsing for code tokens (domain‑specific NER).
- Legal/Policy summarization with fact deferral
- Sector: legal, public sector
- What: SLM summarizes prose; <CALL> inserts citations/statutes/precedents with links to verified sources.
- Tools/products/workflows: Legal RAG (case law databases); citation validators; redlining workflows highlighting called spans.
- Assumptions/dependencies: Licensed legal corpora; tolerance for added latency; jurisdiction awareness.
- Data labeling at scale without GPUs for call training
- Sector: ML infrastructure, academia
- What: CPU‑only spaCy annotation integrated into the dataloader to flag factual tokens during pretraining; avoids GPU labeling (LLM judge) or two‑stage Rho pipelines.
- Tools/products/workflows: spaCy pipelines, CPU workers in data loaders, reproducible masks per batch.
- Assumptions/dependencies: spaCy coverage for target languages; maintainable heuristics for domain entities.
- Privacy‑aware selective disclosure
- Sector: security, compliance
- What: Reduce exposure by deferring less often and only on factual spans; combine with redaction so only minimal context is sent when <CALL> triggers.
- Tools/products/workflows: Context windows scrubbers; call‑time PII filters; DLP policies keyed off <CALL>.
- Assumptions/dependencies: Effective redaction without breaking factual retrieval; organizational approval for selective disclosure.
- Better evaluation and model selection for cascades
- Sector: academia, ML ops
- What: Replace validation‑loss as a single KPI with downstream factuality metrics (e.g., FactScore) when tuning cascade policies (as loss did not correlate with factuality in the paper).
- Tools/products/workflows: Continuous evaluation harness with FactScore; offline call‑ratio sweeps; A/B tests of cascade partners.
- Assumptions/dependencies: Availability of task‑aligned factuality metrics; representative evaluation data.
Long‑Term Applications
These use cases may require additional research, tooling, or standardization (e.g., domain‑specific parsers, span‑level deferral, security/legal frameworks).
- Open standard for <CALL> protocols and tool schemas
- Sector: software, interoperability
- What: Define typed deferral APIs (entity, date, citation, numeric) so SLMs can interoperate with multiple tools/LLMs/KBs.
- Dependencies: Community/spec governance; alignment across tokenizers and vendors; security model for call payloads.
- Span‑level and structured deferral (beyond single tokens)
- Sector: NLP research, enterprise apps
- What: Train models to emit boundaries and types for factual spans and invoke specific tools (e.g., “<CALL:WIKIDATA>[entity span]”).
- Dependencies: Training data with span annotations; decoding/beam support for structured calls; evaluation on span‑level factuality.
- Domain‑specific fact detectors beyond general spaCy
- Sector: healthcare, law, finance, scientific publishing
- What: Replace/augment spaCy with domain NER (e.g., UMLS entities, legal citations, financial instruments) to improve deferral accuracy.
- Dependencies: High‑quality domain parsers; licensing; labeled corpora for adaptation.
- Verified knowledge integration and function‑first deferral
- Sector: data platforms, enterprise IT
- What: Prefer direct function calls (SQL, API) over LLM cascades for facts; unify governance and auditability.
- Dependencies: Stable data contracts; provenance tracking; monitoring for stale sources.
- Risk‑aware orchestration and dynamic call budgeting
- Sector: finance, healthcare, government
- What: Adjust call thresholds based on risk class of a task/user/context (e.g., stricter in regulated workflows).
- Dependencies: Reliable risk classifiers; policy engines; explainability requirements.
- Human‑in‑the‑loop deferral for high‑stakes decisions
- Sector: healthcare, legal, safety‑critical operations
- What: Elevate <CALL> to route specific factual spans to human experts (editor review queues).
- Dependencies: Triage UIs; SLAs; auditability and attribution of changes.
- Multilingual and cross‑domain LaCy variants
- Sector: global software, education
- What: Extend parsing/heuristics to other languages and scripts; ensure entity/date detection works across locales.
- Dependencies: Multilingual NER/POS resources; tokenization harmonization; culturally specific formats.
- Edge/robotics planning with selective knowledge offload
- Sector: robotics, IoT
- What: On‑device SLM for instruction following; <CALL> to remote knowledge/services when exact world facts are needed (maps, part specs).
- Dependencies: Connectivity management; caching of frequent facts; safety gating in low‑connectivity scenarios.
- Hardware/software co‑design for deferral gating
- Sector: semiconductors, mobile
- What: Accelerators that cheaply compute confidence/loss proxies and spaCy‑like features to trigger calls with minimal overhead.
- Dependencies: Efficient token‑type detectors; frameworks exposing gating signals.
- Continual learning with externalized facts (reduced obsolescence)
- Sector: MLOps, enterprise AI
- What: Keep SLM stable while updating external knowledge sources; avoid frequent retraining for fact drift.
- Dependencies: Up‑to‑date KBs; monitoring for drift; retriever maintenance.
- Policy and compliance standards for deferral and auditing
- Sector: regulators, compliance
- What: Mandate deferral on high‑risk factual tokens in sensitive domains; require call logs and provenance in AI‑assisted content.
- Dependencies: Consensus on risk taxonomies; certification schemes; privacy regulations for call payloads.
- New evaluation metrics and datasets centered on acceptability
- Sector: academia, benchmarking
- What: Develop acceptability‑based benchmarks and metrics that reflect factual correctness over exact-token matching.
- Dependencies: Human/system annotations for acceptable continuations; community adoption.
- Education/tutoring with source‑grounded answers
- Sector: education
- What: Tutors that defer to textbooks/journals for factual claims, citing sources automatically on <CALL>.
- Dependencies: Licensed curricular materials; citation engines; classroom acceptance policies.
Cross‑cutting assumptions and caveats
- Cascade partner quality matters: Gains depend on the larger model/RAG being more factual than the SLM; poor partners limit benefits.
- Domain shift requires re‑tuning: spaCy rules and loss thresholds tuned on Wikipedia may not transfer without adaptation.
- Privacy and governance: Any deferral sends context; organizations must implement redaction and auditing.
- Tokenization/tool alignment: Mismatched tokenization between SLM and cascade must be handled (e.g., multi‑token numeric returns).
- Latency budgets: Workflows must tolerate added latency on <CALL>; prefetching/caching may be needed.
- Evaluation: Rely on downstream factuality metrics (e.g., FactScore) rather than validation loss alone when optimizing cascades.
Glossary
- Acceptability: A criterion for whether a predicted next token maintains factual and logical consistency with the ground truth continuation. "we propose the concept of acceptability as a relaxation of accuracy"
- Autoregressive LLMs: Models that predict the next token given previous tokens to approximate the data distribution. "Autoregressive LLMs approximate the data distribution by next-token prediction"
- Bayesian active learning: A framework that selects informative data points for training using Bayesian principles. "has recently resurfaced in Bayesian active learning \citet{rho_loss}"
- CALL token: A special placeholder token indicating the model should delegate prediction to an external source. "This is implemented by predicting some form of a <CALL> placeholder for the next token."
- Cross-entropy loss: A standard training objective that measures the divergence between predicted and true token distributions. "the cross-entropy loss is blind to the type of error"
- Domain adaptation: Techniques for improving model performance when training and test data come from different distributions. "It has roots in domain adaptation \citep{moore-lewis-2010-intelligent,xie_doremi}"
- Distributionally robust optimization: Methods that optimize performance under worst-case distributional shifts. "distributionally robust optimization \citep{oren2019distributionallyrobustlanguagemodeling}"
- Fact leakage: The unintended storage of factual knowledge in a small model’s parameters, measured by its ability to answer facts without calling. "Without calling, LaCy has lowest fact leakage, meaning the least facts were trained into the limited parametric SLM memory."
- FactScore: An evaluation metric that measures the proportion of atomic facts in generated text supported by ground-truth sources. "Factual accuracy is measured by FactScore \citep{min-etal-2023-factscore}."
- Greedy decoding: A generation strategy that selects the highest-probability token at each step without search. "We use greedy decoding."
- Grokking: A phenomenon where models transition from memorization to generalized patterns after extended training. "models seem to start ``grokking'', that is, they transition from nearly lossless to lossy predictions"
- Learnability theory: The study of which data points or tokens a model can reliably learn given its capacity and training signals. "From a learnability theory standpoint, the loss on the true token during pretraining indicates both whether the SLM predicts the true token correctly and whether it will reliably predict it after training."
- LLM judge: An approach that uses a larger LLM to annotate or classify tokens (e.g., as factual) for training smaller models. "LLM judge-based factual annotations \citep{zhao2025lmlm}"
- Model cascade: A system where a smaller model defers to a larger, more capable model when needed. "assume a bigger model to step in when the SLM calls, forming a model cascade \citep{varshney-baral-2022-model-cascading,gupta2024language}"
- Named Entity Recognition: A technique to identify entities such as names, dates, and locations in text. "spaCy's small English web model ... for Named Entity Recognition and linguistic annotation"
- Parametric knowledge: Information stored in the model’s parameters rather than accessed externally. "they transition from nearly lossless to lossy predictions by overwriting and compressing parametric knowledge \citep{ghosal2025memorization}"
- Retrieval-Augmented Generation (RAG): A method that augments generation by retrieving external knowledge based on the context. "enhanced with a RAG prompt."
- Rho-1: A loss-based token selection method that uses a reference model’s loss to decide which tokens to train or delegate. "Rho-1 \citep{rho_1}"
- Rho-loss: A learnability-based metric guiding token selection by comparing losses across models or training stages. "Rho-loss and Rho-1 \citep{rho_loss,rho_1} use this to decide which tokens to pretrain into the SLM's parameters and which to skip"
- SentencePiece tokenizer: A subword tokenization algorithm that builds a vocabulary from data without language-specific rules. "We pretrain GPT-2 architectures from scratch with the SentencePiece tokenizer \citep{Kudo2018SentencePieceAS}."
- Small LLMs (SLMs): Compact LLMs (around or below 1B parameters) designed to predict easy tokens and delegate hard factual ones. "Small LLMs (SLMs, \citeauthor{belcak2025small}, \citeyear{belcak2025small})."
- spaCy: An NLP library used here for grammar parsing and entity detection to augment loss signals for token delegation. "We find that a spaCy grammar parser can help augment the loss signal to decide which tokens the SLM should learn to delegate"
- Token logits: The pre-softmax scores over the vocabulary that reflect the model’s preference for each next token. "while being simpler and cheaper.} ... or token logits."
- Validation loss: The loss measured on held-out data used to monitor training progress and generalization. "Models' abilities, especially during pretraining, are often assessed by their validation loss."
Collections
Sign up for free to add this paper to one or more collections.