Beyond Tokens: Concept-Level Training Objectives for LLMs
Abstract: The next-token prediction (NTP) objective has been foundational in the development of modern LLMs, driving advances in fluency and generalization. However, NTP operates at the \textit{token} level, treating deviations from a single reference continuation as errors even when alternative continuations are equally plausible or semantically equivalent (e.g., mom'' vs.mother''). As a result, token-level loss can penalize valid abstractions, paraphrases, or conceptually correct reasoning paths, biasing models toward surface form rather than underlying meaning. This mismatch between the training signal and semantic correctness motivates learning objectives that operate over higher-level representations. We propose a shift from token-level to concept-level prediction, where concepts group multiple surface forms of the same idea (e.g., mom,''mommy,'' ``mother'' $\rightarrow$ \textit{MOTHER}). We introduce various methods for integrating conceptual supervision into LLM training and show that concept-aware models achieve lower perplexity, improved robustness under domain shift, and stronger performance than NTP-based models on diverse NLP benchmarks. This suggests \textit{concept-level supervision} as an improved training signal that better aligns LLMs with human semantic abstractions.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple question: What if we trained AI LLMs to understand ideas, not just exact words? Today’s big LLMs are taught to guess the next token (a word or piece of a word). That makes them very good at sounding fluent, but it can also push them to copy specific wordings instead of focusing on meaning. The authors propose training models to predict the next concept—an idea that can be expressed in different ways, like “mom,” “mommy,” or “mother.”
What questions did the researchers ask?
They explored three main questions, in plain terms:
- Can a model trained to recognize concepts (not just exact words) still perform well on regular language tasks?
- Is a concept-trained model more robust when it reads different kinds of text (like comments, news, or science)?
- Will focusing on meaning help the model do better on common language tests (like detecting spam or finding contradictions)?
How did they do it?
Think of language in two layers: surface words and deeper ideas. The team tried to inject “idea awareness” into training.
Building the concept lists
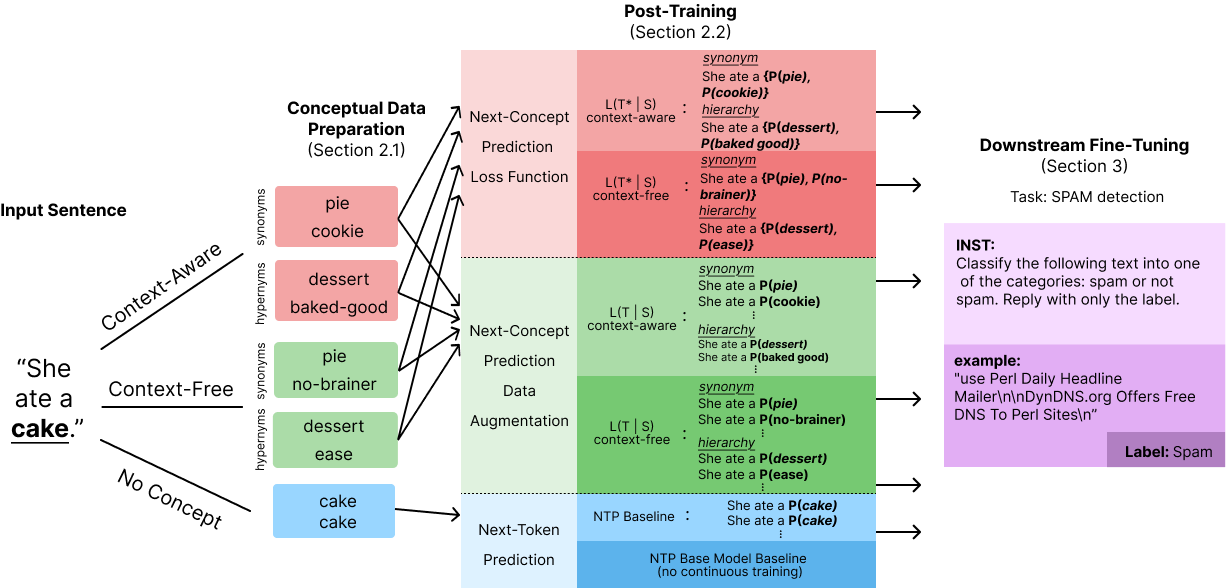
They focused on nouns (the things in sentences, like “cake” or “mother”) and gathered:
- Synonyms: different words with the same meaning in context (cake → “pie,” “cookie,” depending on usage).
- Hypernyms: more general categories (cake → “dessert,” “baked goods”).
They got these in two ways:
- Context-free: using a dictionary-like resource called WordNet.
- Context-aware: asking an LLM to suggest alternatives that fit the sentence’s meaning.
They collected fresh text from three places to avoid overlap with the model’s original training:
- YouTube comments (casual language)
- arXiv abstracts (scientific writing)
- New York Times abstracts (journalistic writing)
Two ways to train with concepts
They tried two training strategies to make the model treat multiple wordings as equally valid when they express the same idea:
- Data augmentation: Duplicate a sentence several times, each time swapping the target noun with a synonym or a hypernym. The model is still trained normally, but now it sees many correct ways to express the idea.
- Concept-aware loss: Change the model’s “mistake counter” so it counts any correct synonym or hypernym as right. In other words, if the true answer is “mother,” predicting “mom” also earns full credit.
An analogy: Imagine grading an essay for ideas rather than exact phrases. With concept-aware training, if the student writes “mom” instead of “mother,” they still get the point—because the idea is correct.
How they tested the models
They ran three types of checks:
- Perplexity: A score for how “surprised” the model is by normal text; lower is better. Even though the new models were trained with concepts, they were evaluated on regular text to see if they still handled everyday language well.
- Cross-domain robustness: Train on one type of text (e.g., YouTube) and test on another (e.g., news) to see how well the model adapts.
- Downstream tasks: Fine-tune the models on seven common benchmarks, including:
- GLUE (general language understanding)
- SNLI (does one sentence follow from another?)
- Empathetic Dialogs (emotional understanding)
- Hate speech detection
- Spam detection
- Fake news classification
- Logical fallacy detection
What did they find?
- Better or comparable language modeling: Concept-aware models achieved lower or competitive perplexity compared to standard next-token models. In some cases, the best perplexity came from a concept-augmented model.
- More robust across domains: Models trained with concepts handled domain shifts better—for example, training on science text and doing well on news or comments.
- Stronger performance on benchmarks: Across a variety of tasks, concept-trained models usually outperformed the standard baselines. A model trained with hypernyms (more general concepts) often did especially well across several tests.
- More flexible word choices: When completing a sentence, concept-aware models spread their guesses across meaning-related words (like “articles,” “episodes,” “cases”), not just tiny variations of the same word (“article” vs. “articles”).
Why this matters: It suggests that when models learn the idea behind the words, they generalize better and become less rigid about exact phrasing—more like how people understand language.
Why does this matter?
Training on concepts shifts the model’s focus from matching strings to matching meaning. This can help with:
- Paraphrasing and rewording without losing the idea
- Understanding new topics or writing styles
- Being more robust to small wording changes and domain shifts
- Performing better on real-world tasks like moderation, fact-checking, or reasoning
Caveats and next steps
There are some limits:
- They only worked with nouns this time; verbs and adjectives matter too.
- Some concept lists were generated by another LLM or by a dictionary—both can make mistakes or miss context.
- Most tests were classification tasks; future work should include more open-ended reasoning and generation.
What’s next:
- Try concept-aware training from the very start (pretraining), not just after
- Use hierarchical concepts (ideas within bigger ideas)
- Expand to multiple languages
Bottom line
Teaching models to aim for meaning—by rewarding any correct way to express the same idea—makes them more flexible, more robust, and often more accurate. It’s a step toward LLMs that think less like autocomplete and more like humans who understand concepts.
Knowledge Gaps
The paper leaves the following concrete gaps, limitations, and open questions that future work could address:
- Concept definition and formalization: No rigorous, operational definition of “concept” beyond synonym/hypernym sets; unclear how to model context-sensitive, overlapping, and hierarchical concept boundaries in a principled way.
- Set-based objective clarity: The NCP loss is under-specified (e.g., summation index and treatment of multi-token completions); a formal derivation of a set-aware cross-entropy or likelihood objective is missing.
- Weighting of concept members: All synonyms/hypernyms are weighted equally in the loss; methods to weight by contextual appropriateness or corpus frequency are unexplored.
- Multi-token concepts and phrases: Handling of multiword expressions (e.g., “baked goods”), multi-token nouns, idioms, named entities, and paraphrases at the phrase/sentence level is not addressed.
- Part-of-speech coverage: The approach only targets nouns; extending to verbs, adjectives, and compositional constructions (verb–object pairs, clauses) remains unexplored.
- Context quality and validity: No evaluation of the correctness and appropriateness of LLM-generated context-aware synonyms/hypernyms (precision/recall of substitutions, semantic fidelity, and meaning preservation in context).
- Concept induction at scale: Scalable, domain-adaptive pipelines to induce concepts (beyond WordNet and single LLM prompts) are untested; coverage, noise rates, and maintenance of evolving concepts remain open.
- Bias and safety: No systematic fairness/safety audit—how concept clustering affects biased generalizations (e.g., demographic terms), stereotypes, or disparate error rates across groups; need fairness metrics and targeted stress tests.
- Calibration and uncertainty: The claim that concept-aware training “flattens” distributions is not backed by calibration metrics (ECE, Brier score) or uncertainty evaluation.
- Trade-offs in specificity: Encouraging hypernyms may induce genericity and loss of specificity; effects on tasks requiring precise word choice or factual detail are not evaluated.
- Generative and reasoning tasks: Evaluation is limited to classification; effects on generation, summarization, QA, reasoning (deductive/abductive), and chain-of-thought quality remain unknown.
- Concept-level evaluation metrics: Reliance on token-level perplexity and accuracy; metrics that credit semantically equivalent outputs (multi-reference, semantic similarity, entailment-based scoring) are absent.
- Decoding strategies: Interaction between NCP and decoding (greedy, top-k, nucleus, contrastive decoding) is unexamined; whether concept-aware training benefits or requires different decoding is unclear.
- Baseline breadth: Comparisons lack stronger multi-reference or semantic-target baselines (e.g., label smoothing to paraphrase sets, MR-NLL, SenseBERT-/supersense-style losses, contrastive semantic objectives).
- Statistical rigor: No significance testing, confidence intervals, or variance over multiple seeds; many reported improvements may be within noise given small fine-tuning budgets.
- Training budget and scale: Post-training and fine-tuning use small datasets (~8k/train per domain) and only 100 LoRA steps; the effect of larger-scale NCP pretraining and different optimization regimes is unknown.
- Model generality: Results are limited to Llama-3-8B; cross-architecture and cross-parameter-scale generalization of NCP is not demonstrated.
- Domain coverage: Only three text domains (YouTube, arXiv abstracts, NYT abstracts) are used; generalization to technical (code, legal, medical), multilingual, and low-resource domains is untested.
- Negative transfer analysis: Combined-domain post-training underperforms domain-specific training; mechanisms of interference and methods to mitigate (e.g., domain-aware sampling, adapters) are not explored.
- Tokenization alignment: How BPE segmentation interacts with concept units (words split into subword tokens) and how to aggregate over multi-token targets is not specified.
- Concept hierarchy learning: The paper suggests hypernyms but does not learn or evaluate hierarchical (graph/tree) concept structures, nor methods to exploit them in training and inference.
- Internal representations: No probing or representational analysis to show that models form concept-level abstractions (e.g., clustering in embedding space, neuron-level interpretability, causal tracing).
- Robustness to adversarial paraphrases: No stress tests for adversarial rewordings, paraphrase invariance, or semantic perturbations; GLUE paraphrase tasks are not sufficient as targeted robustness checks.
- Data contamination and confounds: Using the same LLM family to generate context-aware concepts could inject model-specific biases; disentangling improvement from self-generated supervision is not addressed.
- Quality control of substitutions: No automatic or human evaluation of whether substituted synonyms/hypernyms preserve sentence acceptability, truthfulness, and pragmatics (e.g., grammaticality, register).
- Cost/efficiency: Compute overhead of NCP (data augmentation, set-based loss) vs. NTP is not quantified; memory and throughput implications for pretraining-scale experiments are unknown.
- Safety/hallucinations: The paper flags risks but does not empirically test hallucination rates, factuality, or safety under NCP compared to NTP.
- Concept drift and dynamics: How concept clusters evolve over time and across domains—and how to update them without catastrophic forgetting—is left open.
- Integration with alignment methods: Interaction with RLHF/RLAIF/DPO/KTO and preference-based objectives is not studied; whether concept-aware supervision complements or conflicts with alignment is unknown.
- Reproducibility details: Some tables contain formatting issues; full post-training hyperparameters, seeds, and ablation protocols (e.g., effect of upsampling vs. concept loss) are incomplete for robust replication.
Practical Applications
Immediate Applications
The following applications can be deployed now by adapting the paper’s training procedures (concept-level data augmentation and/or concept-aware loss) to existing LLMs and NLP classifiers.
- Content moderation robust to paraphrase (industry, policy, social platforms)
- What: Improve hate speech, harassment, and policy-violation detection so it’s less brittle to lexical variation (e.g., euphemisms, leetspeak, synonyms).
- How: Fine-tune moderation models with NCP data augmentation (synonyms/hypernyms from WordNet + context-aware expansions) or swap in the concept-aware loss for classification heads.
- Tools/workflow: The paper’s open-source repo; LoRA-based fine-tuning recipe; concept mining pipeline as a preprocessor; integration with Trust & Safety dashboards.
- Dependencies/assumptions: High-quality concept clusters; careful handling of sensitive categories to avoid overgeneralization; human-in-the-loop review.
- Spam/phishing detection that resists wording changes (industry, cybersecurity)
- What: Increase robustness of email/SMS spam filters against rephrasing tactics.
- How: Retrain filters using NCP augmentation and concept-aware loss on historical corpora (e.g., SpamAssassin-like datasets plus recent enterprise mail).
- Tools/workflow: Batch augmentation of labeled data with contextual synonyms; LoRA updates to existing filters.
- Dependencies/assumptions: Up-to-date corpora; false-positive tolerance tuning; data governance for enterprise emails.
- Misinformation and fallacy detection for newsrooms and civic tech (industry, policy, media)
- What: Strengthen fake-news and logical-fallacy detectors against lexical camouflage.
- How: Fine-tune on fact-check and fallacy datasets with NCP; deploy as pre-publication or post-publication scanners.
- Tools/workflow: Editorial plugins for CMS (pre-publish alerts); API services for civil society monitors; benchmarking against PolitiFact-like datasets.
- Dependencies/assumptions: Regular refresh with new narratives; human fact-check oversight; audit for political bias.
- Customer support intent classification and empathetic responses (industry, CX)
- What: Better route tickets and interpret paraphrased intents; improve empathetic tone stability across phrasing.
- How: Train intent classifiers and response suggestion models with concept-augmented data; use empathetic-dialog datasets as in the paper.
- Tools/workflow: Helpdesk integrations (Zendesk/ServiceNow); concept-aware fine-tuning kits; evaluation on paraphrase-heavy test sets.
- Dependencies/assumptions: Domain-specific lexicons (product names, categories); guardrails for tone and compliance.
- Search and ads matching via concept expansion (industry, advertising, search)
- What: Boost recall by expanding queries and documents to concept clusters (synonyms, hypernyms).
- How: Add a concept-expansion middleware that rewrites queries/index terms; maintain concept thesauri per domain.
- Tools/workflow: Retrieval pipelines with concept rewrites; vector store re-indexing using concept embeddings.
- Dependencies/assumptions: Precision controls to avoid drift; domain ontologies; A/B testing for CTR/CVR impact.
- Enterprise document auto-tagging and taxonomy alignment (industry, knowledge management)
- What: Assign consistent tags despite wording differences; map documents to hierarchical categories.
- How: Use NCP-trained classifiers for tag prediction; leverage hypernym-based expansions to align with taxonomies.
- Tools/workflow: DMS integrations (SharePoint/Confluence); concept dictionaries linked to enterprise taxonomies.
- Dependencies/assumptions: Curated taxonomies; periodic concept updates; access controls for sensitive docs.
- Compliance monitoring of communications (finance, regulated industries)
- What: Detect restricted-topic communications even when employees paraphrase.
- How: Fine-tune NCP models on historical compliance incidents and policy lexicons expanded to concepts.
- Tools/workflow: Surveillance connectors for email/chat/CRM; risk scoring dashboards; alert triage assistants.
- Dependencies/assumptions: Legal review; strict data security; explicit definitions of concepts to prevent overreach.
- Healthcare back-office coding and categorization (healthcare, revenue cycle)
- What: More robust mapping of clinical notes to codes/categories despite synonyms and abbreviations.
- How: Pair NCP augmentation with medical ontologies (UMLS/SNOMED) as concept sources; limit scope to coding support (not clinical decision-making).
- Tools/workflow: EHR add-ons for code suggestions; concept matching with domain ontologies; coder review loops.
- Dependencies/assumptions: Regulatory compliance (HIPAA); rigorous validation; domain ontologies as concept backbone; current approach covers nouns best.
- Education: short-answer grading tolerant of paraphrases (education, edtech)
- What: Grade for concept coverage rather than specific phrasing; flag logical fallacies in essays.
- How: Fine-tune grading rubrics with concept-level expansions; add fallacy detection models in writing tools.
- Tools/workflow: LMS plugins; rubric authoring UI with concept lists; educator override interface.
- Dependencies/assumptions: Transparent rubrics; bias checks across demographics; human review for high-stakes grading.
- Retrieval-augmented generation (RAG) with concept-aware queries (software, data)
- What: Improve recall in RAG by expanding user queries to concept-level variants.
- How: Insert a pre-RAG query expander using contextual synonyms/hypernyms; optionally re-rank by concept overlap.
- Tools/workflow: Middleware for LLM apps; concept-aware re-ranker; evaluation on domain-shifted corpora.
- Dependencies/assumptions: Balance recall vs. precision; latency budgets; concept drift monitoring.
- Low-resource model improvement via data augmentation (academia, startups)
- What: Boost small models on NLU tasks using NCP augmentation where labeled data is scarce.
- How: Generate context-aware lexical variants to multiply training samples; apply concept-aware loss when feasible.
- Tools/workflow: The paper’s pipeline, WordNet + LLM generators; HF Trainer adapter for concept-loss.
- Dependencies/assumptions: Quality control for synthetic data; coverage of domain terminology.
- Benchmarking and robustness evaluation suites (academia, MLOps)
- What: Add concept-robustness tests to model evals (paraphrase, hypernym swaps).
- How: Create “concept shift” eval sets and perplexity/accuracy comparisons across domain shifts as in the paper.
- Tools/workflow: Eval harness integrating concept transformations; CI gates for robustness criteria.
- Dependencies/assumptions: Representativeness of transformations; clear acceptance thresholds.
Long-Term Applications
These applications require further research, scaling, or development (e.g., extending beyond nouns, hierarchical concepts, multilingual support, or full pretraining).
- Concept-first foundation model pretraining (software, AI platforms)
- Vision: Train foundation models with NCP from scratch, including verbs/adjectives and hierarchical concepts, to improve reasoning and transfer.
- Value: Reduce surface-form bias; more stable planning and abstraction.
- Dependencies: Scalable, high-quality concept graphs; efficient loss implementations; compute at pretraining scale.
- Multilingual concept alignment for cross-lingual transfer (global platforms, policy)
- Vision: Shared concept space across languages for moderation, search, and translation.
- Value: Consistent policy enforcement and retrieval despite language-specific phrasing.
- Dependencies: Cross-lingual ontologies; multilingual concept mining; bias and fairness audits.
- Concept-aware reasoning and planning (software, agents, autonomy)
- Vision: Chain-of-thought and tool-use that operate on concept graphs (not just tokens), enabling more robust multi-step reasoning.
- Value: Greater interpretability at the idea level; fewer surface-form traps.
- Dependencies: Stable concept hierarchies; interfaces between symbolic concept graphs and neural models.
- Concept-level alignment and preference learning (academia, alignment research)
- Vision: Preference optimization (DPO/KTO/RLHF) that rewards concept coverage and penalizes conceptual errors.
- Value: Stronger semantic alignment to human intent; reduced reward hacking via wording.
- Dependencies: Concept-aware reward models; annotation schemes for concept correctness.
- Robotics and embodied agents with semantic invariance (robotics)
- Vision: Instruction-following robust to synonyms and categories (e.g., “cup → mug → container”).
- Value: Better generalization to new environments and utterances.
- Dependencies: Grounded concept mappings (vision–language–action); safety validation; latency constraints.
- Legal and contract analytics via concept lattices (legaltech)
- Vision: Clause detection and normalization using concept hierarchies (e.g., “termination → cancellation → dissolution”).
- Value: Improved e-discovery recall; better risk extraction across drafting variants.
- Dependencies: Legal ontologies; explainability requirements; jurisdictional variation.
- Clinical decision support with concept reasoning (healthcare)
- Vision: Diagnostic reasoning and guideline application based on conceptual equivalence and hierarchies (e.g., symptom clusters).
- Value: Reduced brittleness to phrasing; improved generalization across notes and specialties.
- Dependencies: Clinical validation; robust safety/QA; integration with medical knowledge graphs; regulatory approval.
- Personalized tutoring by concept mastery (education)
- Vision: Track and teach “concept coverage” rather than exact wording; adaptive remediation across concept hierarchies.
- Value: Fairer assessment; better feedback; transfer across paraphrases.
- Dependencies: Curricular concept maps; psychometric validation; educator oversight.
- Concept-indexed search and analytics (enterprise, BI)
- Vision: Index corpora by concept graphs; trend analysis resilient to phrasing shifts (e.g., product renames).
- Value: Stable KPIs; better topic tracking across time and domains.
- Dependencies: Continual concept updating; governance for taxonomy changes; scalability.
- Concept-aware tokenization/embeddings (software, infra)
- Vision: Hybrid token–concept vocabularies or adapters that encode conceptual invariances.
- Value: More compact and semantically stable representations; improved compression vs. meaning trade-offs.
- Dependencies: Efficient runtime; backward compatibility with existing toolchains.
- Safety against surface-form adversarial attacks (policy, safety)
- Vision: Moderation and safety systems robust to adversarial paraphrase/euphemism attacks.
- Value: Reduced evasion; consistent enforcement.
- Dependencies: Adversarial evaluation frameworks; calibrated thresholds to limit over-blocking.
- Open concept-graph induction from large corpora (academia, open knowledge)
- Vision: Continuously induced, audited concept graphs spanning domains to fuel NCP training and evaluation.
- Value: Public infrastructure for concept-aware NLP research and products.
- Dependencies: Community curation; debiasing; versioning and provenance.
Cross-cutting assumptions and risks (affecting feasibility across applications)
- Concept quality: Overgeneralization can raise false positives; undergeneralization reduces gains. Domain ontologies (e.g., UMLS, SNOMED, product taxonomies) materially improve quality.
- Coverage limits: Current paper targets nouns; extending to verbs/adjectives and context disambiguation is needed for many long-term uses.
- Bias and safety: Concept clustering may encode or amplify societal biases; sensitive categories require stricter governance and audits.
- Evaluation gaps: Most evidence is from classification; generative/reasoning improvements need broader validation.
- Compute and data: Post-training is relatively light (LoRA), but large-scale pretraining or multilingual alignment will require significant resources and high-quality, up-to-date corpora.
- Compliance: Regulated sectors (healthcare, finance, legal) require rigorous validation, monitoring, and documentation before deployment.
Glossary
- 4-bit quantization: A model compression technique that represents weights with 4 bits to reduce memory and compute. "Models were trained using 4-bit quantization with the AdamW 8-bit optimizer"
- AdamW: An optimizer that decouples weight decay from the gradient-based update for better training stability. "with the AdamW 8-bit optimizer"
- Alpaca instruction format: A standardized prompt template used to format inputs for instruction tuning. "employing the Alpaca instruction format for consistent prompt structuring across tasks."
- concept-level prediction: Training models to predict abstract concepts rather than exact tokens to better capture meaning. "We propose a shift from token-level to concept-level prediction"
- concept resolution: The process of defining at what level concepts are grouped, such as synonyms or hypernyms. "Concept Resolution"
- conceptual supervision: Training signals that annotate or group text by underlying concepts rather than surface tokens. "integrating conceptual supervision into LLM training"
- context-aware: Methods that generate or select alternatives using the full sentence context. "Context-Aware, which extracts contextual synonyms and hypernyms"
- context-free: Methods that rely on context-independent resources (e.g., dictionaries) without sentence context. "Context-Free extracts context-independent, dictionary-based synonyms and hypernyms from WordNet"
- cross-domain robustness: The ability of a model to maintain performance when evaluated on data from different domains. "NCP models show superior cross domain robustness."
- cross-domain transfer: Generalizing knowledge learned in one domain to another domain effectively. "we explore cross-domain transfer abilities"
- cross-lingual mappings: Alignments between concepts or representations across different languages. "cross-lingual mappings, or integration with generative objectives"
- data augmentation: Expanding training data by generating semantically equivalent variants to improve robustness. "We augmented the training data using the extracted synonyms and hypernyms."
- data contamination: Overlap between training and evaluation data that can inflate performance metrics. "To avoid data contamination, we gathered new data"
- domain shift: Differences between training and test data distributions that can hurt performance. "improved robustness under domain shift"
- downsampling: Reducing data size to balance datasets or ensure consistency across splits. "downsampling where necessary for consistency across splits."
- downstream NLP tasks: Tasks models are fine-tuned on after pretraining, used to assess practical utility. "improves performance on various downstream NLP tasks."
- fine-tuning: Additional training on specific tasks or datasets to adapt a pretrained model. "we fine-tuned them on seven diverse benchmarks"
- gradient accumulation: Accumulating gradients over multiple steps before an update to emulate larger batch sizes. "and gradient accumulation over four steps."
- hallucinations: Confident but incorrect or fabricated model outputs not grounded in input data. "NCP might lead to hallucinations and other types of undesired model behaviors."
- hierarchical concepts: Concept representations organized in levels (e.g., specific to general) reflecting semantic hierarchies. "hierarchical concepts, cross-lingual mappings"
- hypernym: A more general term that subsumes a more specific one (e.g., dessert is a hypernym of cake). "the hypernyms would include
dessert'' andbaked goods.''" - interpretability: How understandable a model’s reasoning or outputs are to humans. "may shift the interpretability of model outputs"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that injects small low-rank matrices. "we fine-tuned all models using LoRA"
- loss function: The objective optimized during training that quantifies prediction errors. "modify the NTP loss function itself"
- match accuracy: An evaluation metric that compares predicted labels to ground truth after normalization. "We computed match accuracy by comparing lowercased, stripped predictions against ground truth labels."
- multilingual extensions: Expanding methods or models to support multiple languages. "hierarchical concept representations, and multilingual extensions."
- Next-Concept-Prediction (NCP): An objective where models predict sets of conceptually equivalent continuations rather than exact tokens. "Next-Concept-Prediction (NCP) implementations"
- Next Token Prediction (NTP): The standard language modeling objective of predicting the next token in a sequence. "The next-token prediction (NTP) objective"
- perplexity: A measure of how well a probabilistic model predicts a sample; lower is better. "We computed NTP perplexity scores"
- post-training: Additional training after initial pretraining, often on new objectives or data. "We post-trained Llama-3-8B"
- probability mass: The distribution of probability across possible outputs in a model’s predictions. "distribute the probability mass across semantically related completions"
- semantic abstractions: Higher-level meanings that group different expressions under shared concepts. "aligns LLMs with human semantic abstractions."
- semantic coherence: The degree to which outputs maintain consistent and meaningful relationships. "can improve semantic coherence"
- semantic units: Meaningful elements that capture concepts beyond surface words or tokens. "semantic units that unify different linguistic expressions"
- spurious associations: Unreliable correlations that do not reflect true causal or meaningful relationships. "amplifying spurious associations or stereotypes."
- surface form: The exact string or tokenization of text, as opposed to underlying meaning. "biasing models toward surface form rather than underlying meaning."
- train-validation-test split: Dividing data into training, validation, and test sets for model development and evaluation. "approximately 8K-1K-1K sentences for the train-validation-test split"
- upsample: Increasing the frequency of certain data points to balance or emphasize them during training. "We upsample the original data for the NTP baselines."
- WordNet: A large lexical database that organizes words into synsets and semantic relations. "from WordNet"
Collections
Sign up for free to add this paper to one or more collections.