Short-Context Dominance: How Much Local Context Natural Language Actually Needs? (2512.08082v1)
Abstract: We investigate the short-context dominance hypothesis: that for most sequences, a small local prefix suffices to predict their next tokens. Using LLMs as statistical oracles, we measure the minimum context length (MCL) needed to reproduce accurate full-context predictions across datasets with sequences of varying lengths. For sequences with 1-7k tokens from long-context documents, we consistently find that 75-80% require only the last 96 tokens at most. Given the dominance of short-context tokens, we then ask whether it is possible to detect challenging long-context sequences for which a short local prefix does not suffice for prediction. We introduce a practical proxy to MCL, called Distributionally Aware MCL (DaMCL), that does not require knowledge of the actual next-token and is compatible with sampling strategies beyond greedy decoding. Our experiments validate that simple thresholding of the metric defining DaMCL achieves high performance in detecting long vs. short context sequences. Finally, to counter the bias that short-context dominance induces in LLM output distributions, we develop an intuitive decoding algorithm that leverages our detector to identify and boost tokens that are long-range-relevant. Across Q&A tasks and model architectures, we confirm that mitigating the bias improves performance.
Sponsor

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Clear, simple explanation of “Short-Context Dominance: How Much Local Context Natural Language Actually Needs?”
Overview
This paper asks a simple question: When a LLM (like the ones behind chatbots) tries to guess the next word in a sentence, how much of the text does it really need to look at? The authors find that, most of the time, only a small chunk of the most recent text is enough. They call this idea the “short-context dominance” hypothesis.
Objectives
The paper focuses on three main questions, explained in everyday terms:
- How far back does a model need to look to correctly guess the next word?
- Can we spot the special cases where the model truly needs to remember information from much earlier in the text?
- If short context dominates, can we improve the way models write by correcting for this bias—especially in tasks that require long-distance understanding, like answering questions about a long story or document?
Methods and Approach
Think of a LLM as a “smart guesser” that looks at previous text and predicts the next word (or “token,” which is a word or piece of a word).
The authors use three ideas:
- Minimal Context Length (MCL):
- What it is: The smallest number of recent tokens the model needs to correctly and confidently predict the actual next token.
- How it’s measured: Start with just the last 32 tokens, then 48, 64, and so on, until the model’s top guess is the true next token with enough confidence. This tells you how “local” the prediction is.
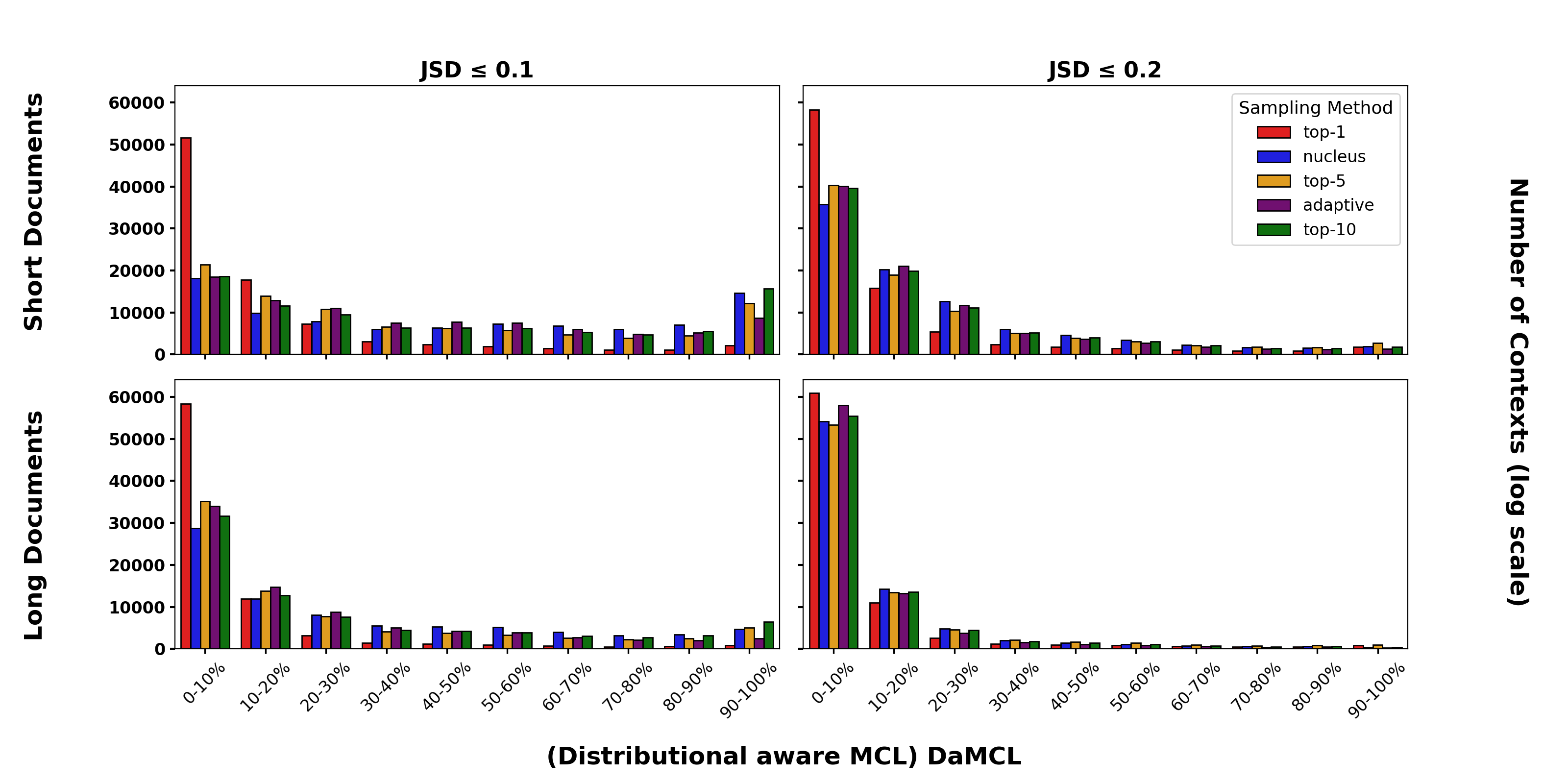
- Distributionally Aware MCL (DaMCL):
- Why it’s needed: Sometimes there’s more than one good next word, and the model may not pick the exact word from the dataset even if its overall “guess distribution” is similar.
- What it is: Instead of checking one correct word, compare the model’s whole “probability list” of next-word guesses using a similarity score (like checking how close two playlists are). If the guess list using a short prefix looks very similar to the list using the full context, the short prefix is good enough.
- Long-Context Detection (LSDS) and Long-Context Tokens (LSPS):
- LSDS (Long-Short Distribution Shift): Measures how much the model’s guess list changes when using just the last 32 tokens versus the full document. Big change = you probably need long context; small change = short context is fine.
- LSPS (Long-Short Probability Shift): For each token, measure how much its probability increases when the model sees the whole text instead of just the short prefix. Tokens that “light up” only with full context are likely important for long-range reasoning.
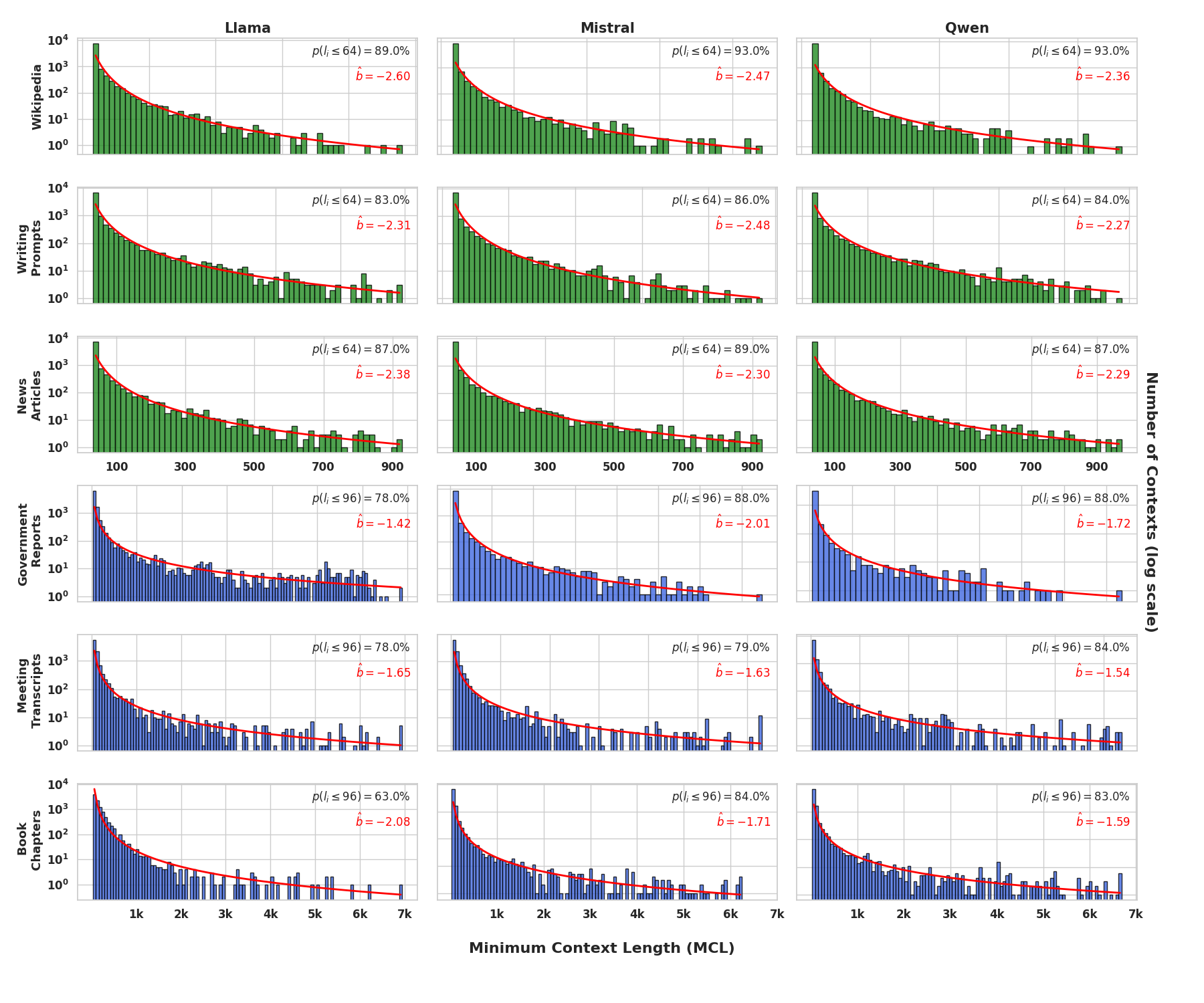
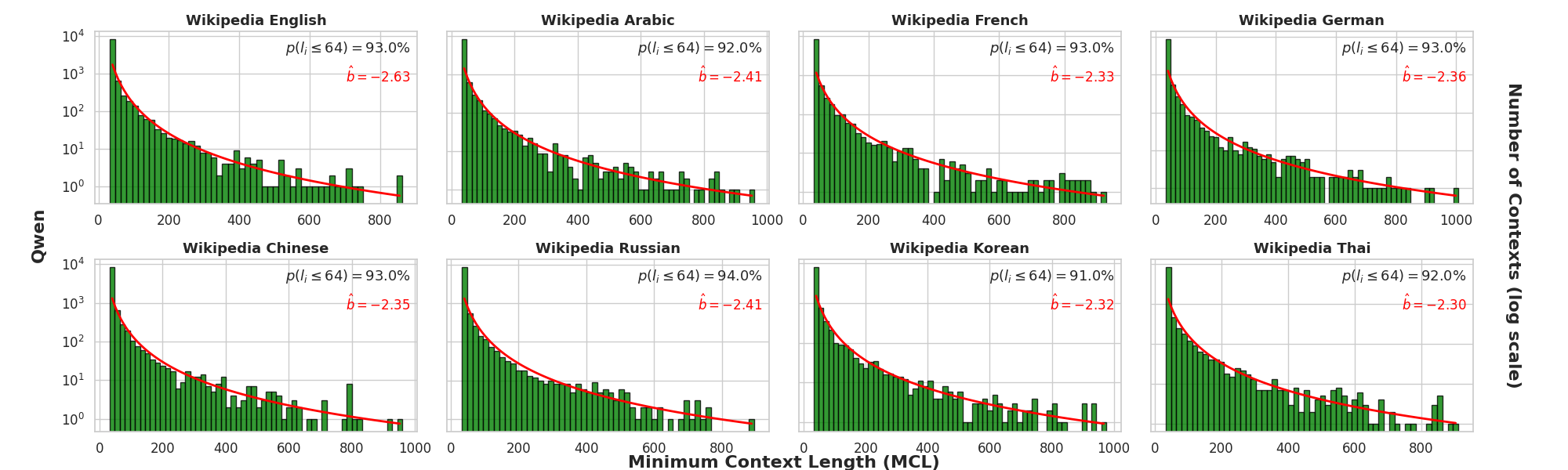
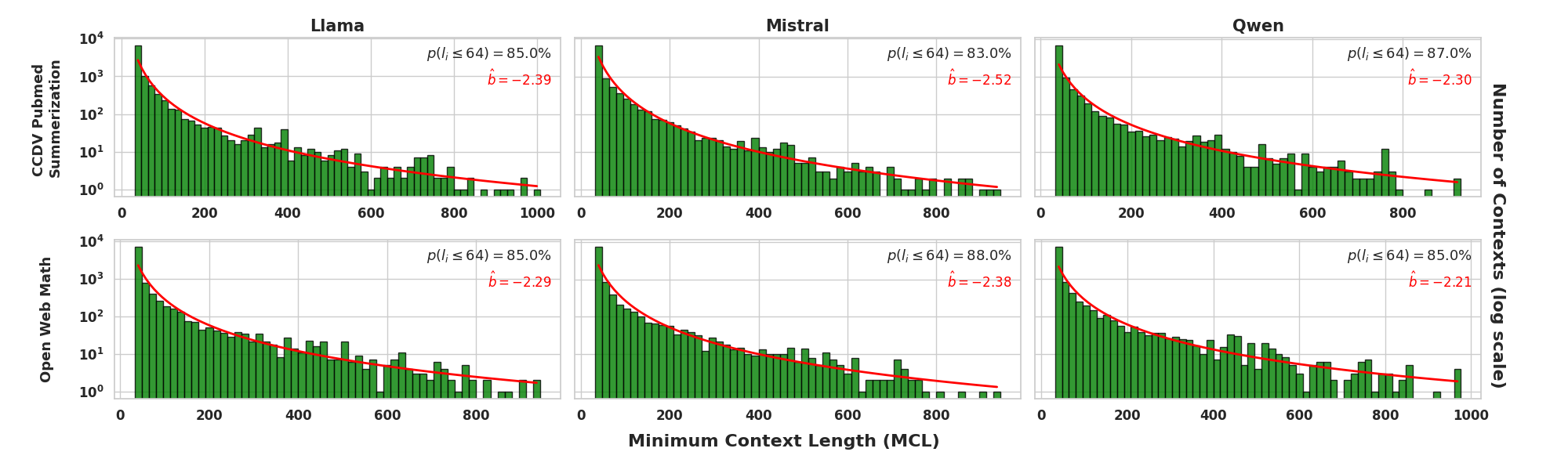
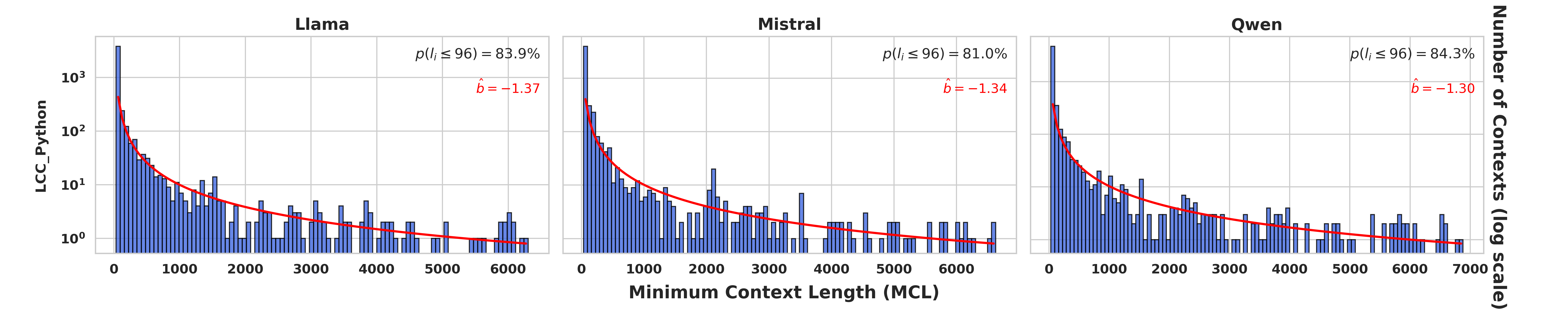
They test these ideas on different datasets (like news articles, government reports, meeting transcripts, and book chapters) and with several open models (LLaMA-3-8B, Mistral-7B, Qwen2-7B).
Main Findings and Why They Matter
- Short-context dominance is real:
- Across many datasets with texts from 100 to 7,000 tokens, about 75–80% of next-token predictions only need the last 32–96 tokens. In simple terms: models mostly rely on recent text, not the entire document.
- DaMCL supports the same story:
- Even when comparing full probability distributions (not just the top word), short context often does the job. Stricter similarity rules make the effect less dramatic, but the pattern still holds.
- Detecting long-context needs works well:
- A simple threshold on LSDS can reliably tell whether a sequence needs long context. This doesn’t require knowing the true next word, so it’s practical during generation.
- Fixing the short-context bias boosts performance:
- The paper introduces a decoding method called TaBoo (Targeted Boosting). It:
- 1. Detects when the model needs long context,
- 2. Identifies tokens that are more likely with the full context (using LSPS),
- 3. Gently boosts those token probabilities before sampling the next word.
- On question-answering tasks that involve long documents (like NarrativeQA, HotpotQA, and MultiFieldQA), TaBoo consistently improves results compared to standard sampling and a strong existing method called CAD (Context Aware Decoding).
Why it’s important:
- It shows that most everyday language predictions depend on local context. This explains why simpler models or methods that focus on short spans can perform surprisingly well.
- It also highlights that traditional metrics (like perplexity that scores token-by-token prediction) may over-reward short-range patterns and undercount true long-range reasoning.
Implications and Impact
- Better evaluation: Since most tokens only need short context, measuring performance purely by token prediction may hide whether a model can use far-away information. New metrics and tests should focus on the rare—but important—long-context cases.
- Smarter generation: During writing or answering questions, the model can quickly check if a short prefix is enough. If not, it can adjust how it picks words (like TaBoo) to favor tokens that depend on the full document.
- Training and design: Future models might use training strategies that pay special attention to long-range dependencies, balancing the natural “short-context bias” in data.
- Real-world use: Tasks like long document QA, summarization, and research assistants benefit the most—places where the answer might depend on something mentioned far earlier in the text.
In short: Most of the time, LLMs only need the last few lines to guess the next word. But when they do need long context, we can detect it and help the model focus on the right long-range information, improving performance on tasks that truly require understanding the whole story.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following concrete gaps, limitations, and unanswered questions that future work could address:
- Selection bias in MCL estimation: quantify the fraction and characteristics of sequences excluded by the “correct-and-confident” filter; report denominators and analyze how inclusion of less-confident or incorrect predictions changes the MCL distribution.
- Model generality: validate short-context dominance on larger and more capable LLMs (e.g., ≥30B, ≥70B, closed models), instruction-tuned variants, and long-context specialist architectures (e.g., FlashAttention-2/Longformer/state-space models), to rule out capacity or architecture-specific effects.
- Context window scaling: test whether short-context dominance persists at very long input lengths (e.g., 32K–128K tokens) and across different positional encoding schemes (absolute, relative, rotary); quantify sensitivity of MCL/DaMCL/LSDS to these choices.
- Domain and language coverage: systematically extend evaluation to low-resource languages, morphologically rich languages, code, legal, and scientific corpora, and report cross-domain differences in MCL/DaMCL distributions and LSDS detection performance.
- Reporting of heavy-tail parameters: provide confidence intervals and goodness-of-fit diagnostics for the reported power-law exponents, and assess whether alternative distributions (log-normal, stretched exponential) better explain the empirical MCL tails.
- Step-size granularity: analyze how the choice of prefix increment (16 or 64 tokens) affects MCL estimates; adopt finer-grained or adaptive search (e.g., binary search) and report sensitivity curves.
- Alternative MCL definitions: compare MCL under different correctness/confidence criteria (e.g., top-k accuracy, margin schedules, temperature scaling, calibration-aware thresholds) and decoding regimes (beam, diverse beam, temperature sampling).
- Distributional metric choice: benchmark DaMCL and LSDS with additional distance measures (total variation, Wasserstein, symmetric KL), and assess robustness to distribution smoothing, tail truncation, and support mismatches introduced by decoding filters.
- Threshold calibration: replace ad-hoc LSDS/DaMCL thresholds with principled calibration (e.g., ROC-optimized τ via validation sets, risk minimization, or unsupervised knee-point detection over prefix-length JSD curves).
- Ground-truth dependency annotation: build or leverage datasets with labeled long-range dependency spans (coreference chains, entity links, multi-hop evidence) to validate LSDS against human-annotated “long-context required” cases beyond token-level surrogates.
- Middle-of-context dependencies: explicitly evaluate sequences whose decisive evidence lies in the middle (Lost-in-the-Middle) and test whether LSDS still separates short vs. long-context cases when the relevant span is neither very recent nor near the beginning.
- Impact of positional masking: quantify whether masking-based truncation (to preserve positional embeddings) introduces confounds versus true truncation; compare both approaches and report any systematic offsets.
- Tokenization effects: examine sensitivity of MCL/DaMCL/LSDS and LSPS to different vocabularies and tokenization schemes (BPE/Unigram/Byte-level), including cross-model vocabulary mismatches.
- From next-token to task-level dependency: extend beyond single-token prediction to multi-token horizons (e.g., next 10–50 tokens), and measure how short-context sufficiency composes over longer generation spans.
- LSDS prefix length: test adaptive short-prefix sizes (e.g., proportional to , content-aware segmenters) rather than fixed 32 tokens, and report trade-offs in detection precision/recall and computational cost.
- Decoding hyperparameter sensitivity: characterize how LSDS and LSPS vary under temperature, top-k, nucleus , adaptive sampling parameters; provide calibration curves and recommended defaults per model/dataset.
- False-positive/negative analysis: publish confusion matrices (precision/recall/F1/AUPRC) for LSDS vs. both oracles across datasets and models; identify failure modes (e.g., entity disambiguation, numeric references).
- Token-level taxonomy: categorize which token types exhibit high LSPS (entities, pronouns, dates, citations, numbers, rare terms) and which do not; connect to linguistic phenomena (coreference, ellipsis, topic shifts).
- TaBoo hyperparameter selection: provide principled methods to set , , and (e.g., validation-based optimization, constrained risk minimization to cap divergence or calibration error) instead of fixed heuristics.
- Side-effects of boosting: measure impacts on fluency, coherence, repetition, toxicity/safety, and calibration (ECE); include human evaluation and long-form quality metrics to ensure gains do not come at the cost of degraded generation quality.
- Baseline breadth: compare TaBoo against a broader set of inference-time baselines (DExperts, Contrastive Decoding variants, Mutual Information decoding, CoherenceBoosting/CAD with tuned , logit lens methods) and report statistically significant differences.
- Statistical rigor: include statistical significance tests, bootstrapped confidence intervals, and effect sizes for QA improvements; clarify whether “best-of-5” gains reflect diversity or true accuracy improvements under fair sampling budgets.
- Efficiency gains: demonstrate end-to-end compute savings by using LSDS to adapt attention span or memory (e.g., selective long-range attention, dynamic retrieval) and quantify throughput/latency trade-offs on long inputs and long generations.
- RAG interactions: test whether short-context dominance persists under retrieval-augmented generation; evaluate whether LSDS can trigger retrieval or re-ranking decisions and whether TaBoo complements or interferes with RAG.
- Training-time implications: empirically measure the proportion of long-range-dependent tokens in pretraining corpora, and explore training modifications (curriculum, contrastive objectives, long-dependency upweighting) that reduce short-context bias; report effects on MCL/DaMCL.
- Theoretical grounding: develop generative or information-theoretic models explaining why MCL follows heavy tails and links to Zipf’s/Heaps’ laws; derive conditions under which short-context dominance emerges and when it should break.
- Reproducibility and artifacts: address LaTeX errors/placeholders and ensure all appendices, code, and datasets (including LSDS/LSPS labels) are released with exact preprocessing, sampling protocols, and seeds for full reproducibility.
Glossary
- Adaptive sampling: A decoding method that adjusts sampling dynamically based on a target criterion. "and adaptive sampling with \citep{zhu2024adaptive}."
- Attention masking: A technique to restrict which tokens can attend to others, simulating truncated context without changing positions. "In practice, we provide the full input to preserve positional encoding and simulate truncated contexts via attention masking."
- Context Aware Decoding (CAD): A contrastive decoding method that reweights token probabilities using long vs. short context. "CAD \citep{CADBoost} is most closely related to our TaBoo algorithm, but differs fundamentally in both motivation and implementation."
- Contrastive decoding: An approach that improves generation by contrasting model outputs under different conditions or contexts. "Contrastive decoding."
- Distribution-aware Minimal Context Length (DaMCL): The shortest prefix length for which a chosen decoding’s next-token distribution is sufficiently similar to the full-context distribution. "We introduce a practical proxy to MCL, called Distributionally Aware MCL (DaMCL), that does not require knowledge of the actual next-token and is compatible with sampling strategies beyond greedy decoding."
- Entropy-based selection: A selection strategy that uses entropy to guide contrastive decoding or token choice. "\citet{vanderpoel2022mutual} apply entropy-based selection for contrastive decoding, but their method differs again in both theoretical motivation and technical implementation."
- Greedy decoding: A decoding strategy that picks the highest-probability token at each step without sampling. "Definition~\ref{def:MCL} is also limited to greedy decoding, while popular natural language generation methods often rely on sampling strategies that draw from multiple probable tokens."
- Heavy-tailed distribution: A distribution where large values occur with non-negligible probability, producing a long tail. "we observe that MCL follows a heavy-tailed distribution where sequence frequency is proportional to "
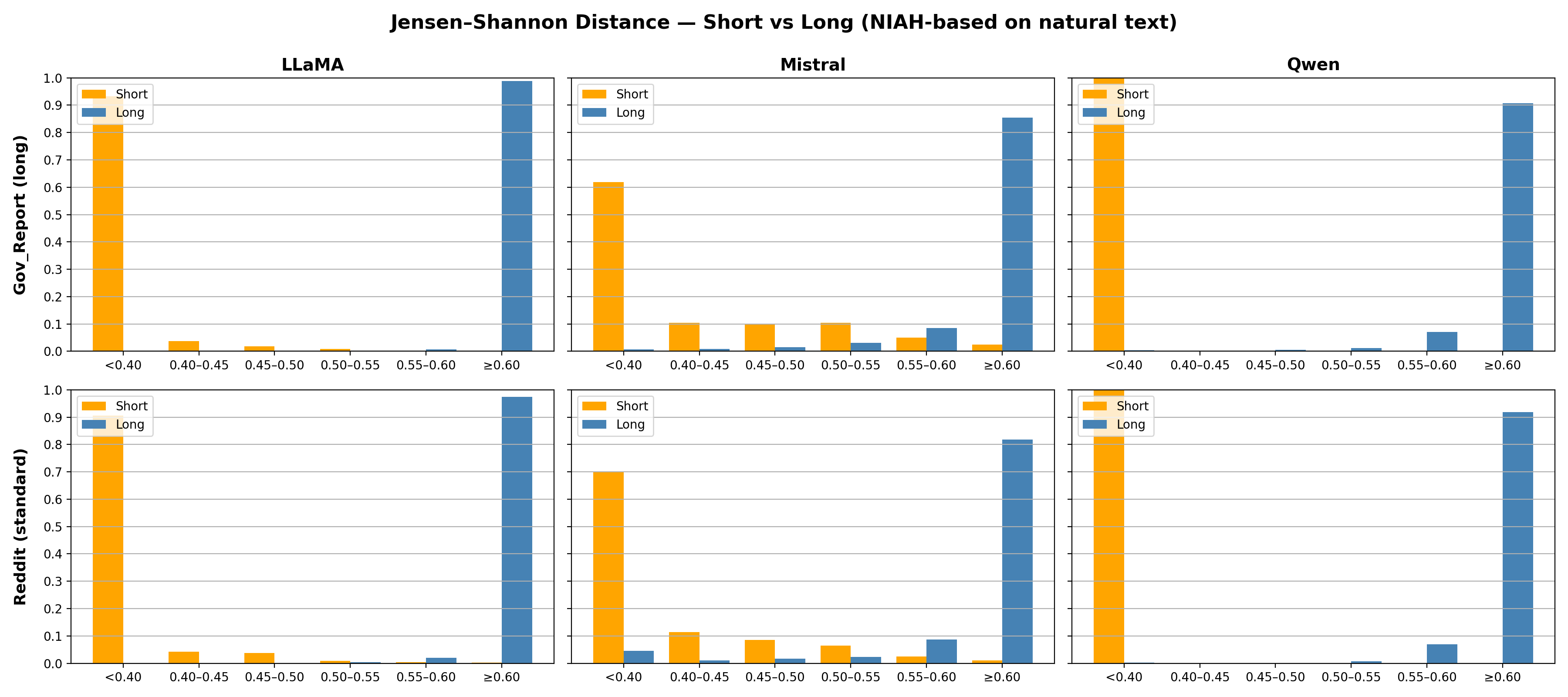
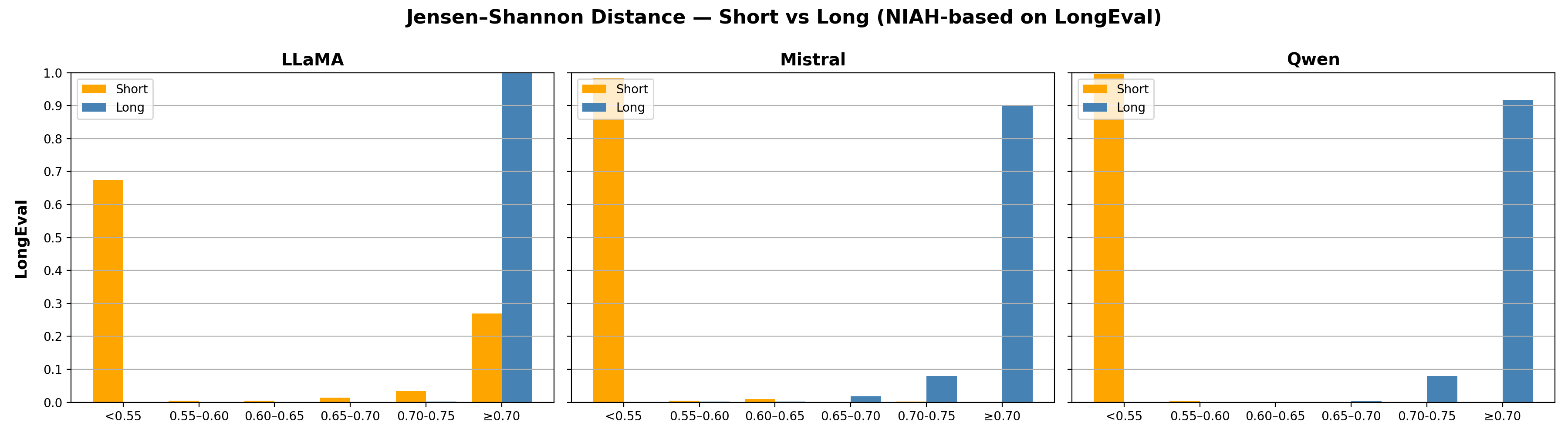
- Jensen-Shannon Distance (JSD): A symmetric, bounded distance between probability distributions, derived from KL divergence. "we specifically use the {Jensen-Shannon Distance (JSD)} throughout our experiments."
- Kullback-Leibler divergence: A measure of how one probability distribution diverges from another. "and $\mathrm{KL}(\mathbf{p}_1 \| \mathbf{p}_2) := \sum_{t \in \mathcal{V} [\mathbf{p}_1]_t \log \frac{[\mathbf{p}_1]_t}{[\mathbf{p}_2]_t}$ is the Kullback-Leibler divergence."
- Logit-adjustment methods: Techniques that modify logits to counter biases or improve generation quality. "and competitive logit-adjustment methods across model architectures."
- Long-Context Likelihood (LCL): An oracle metric indicating whether the next token is favored under long context. "Following \citet{PerplexityLongCtx}, we classify as long-context iff {paper_content} "
- Long-Short Difference (LSD): An oracle measure comparing likelihoods under long vs. short contexts to flag long-context dependence. "Following \citet{PerplexityLongCtx}, we classify as long-context iff "
- Long-Short Distribution Shift (LSDS): The JSD between next-token distributions using a short prefix vs. the full context. "The Long-Short Distribution Shift (LSDS) of sequence is the JSD between the next-token distributions obtained with decoding strategy when given a short prefix of length $32$ versus the full context."
- Long-Short Probability Shift (LSPS): The change in a token’s probability when moving from short to full context. "The Long-Short Probability Shift (LSPS) of a vocabulary token given sequence is defined as the change in the assigned probability moving from short to full context under decoding :"
- Minimal Context Length (MCL): The shortest prefix length that enables a model to confidently predict the ground-truth next token. "We introduce Minimal Context Length (MCL), which quantifies how much local context suffices for a LLM, used as oracle, to confidently and correctly predict the ground-truth next token of a sequence."
- Needle-in-a-haystack experiment: A controlled setup where a relevant item is hidden in a large context to test retrieval or detection. "a controlled needle-in-a-haystack experiment adapted from \citet{KamradtNIAH2023}."
- Nucleus sampling: A decoding method that samples from the smallest set of tokens whose cumulative probability exceeds a threshold p. "For example, nucleus sampling \citep{holtzman2020curious} selects a subset of tokens whose cumulative probability mass reaches threshold (e.g. ), then produces a renormalized distribution with support on this subset and zero probability to tokens otherwise."
- Positional encoding: A mechanism that encodes token positions so transformers can use order information. "In practice, we provide the full input to preserve positional encoding and simulate truncated contexts via attention masking."
- Power-law exponent: The parameter b characterizing how a quantity scales as a power law. "we examine the power-law exponent by fitting in log-log space."
- Probability simplex: The set of all discrete probability vectors whose components are nonnegative and sum to one. "For distributions in the -dimensional simplex, JSD is defined as"
- Renormalized distribution: A probability distribution rescaled to sum to one after restricting its support. "then produces a renormalized distribution with support on this subset and zero probability to tokens otherwise."
- Statistical oracle: A model or procedure treated as providing reliable ground-truth-like evaluations. "Using LLMs as statistical oracles, we measure the minimum context length (MCL) needed to reproduce accurate full-context predictions"
- Top-1 sampling: Selecting only the highest-probability token (i.e., greedy choice) at each step. "While top-1 sampling continues to exhibit standard decay across settings, broader sampling methods such as nucleus, top-5, top-10, and adaptive sampling increasingly lead to flatter distribution."
- Top-K sampling: Sampling from the highest-K probability tokens at each step. "Top- sampling ( for greedy) with \citep{radford2019language, fan-etal-2018-hierarchical}"
- Triangle inequality: A property of a distance metric stating the distance between two points is no greater than via a third point. "We choose JSD because it is a proper distance metric satisfying the triangle inequality"
Practical Applications
Immediate Applications
Below are concrete, deployable applications that directly leverage the paper’s findings (short-context dominance), measurements (MCL/DaMCL), and methods (LSDS detector, LSPS token scoring, TaBoo decoding).
- Inference-time decoding plugin to improve long-context QA and generation
- Sectors: software, legal, finance, healthcare, media
- What: Integrate LSDS (long-context detector) and TaBoo (Targeted Boosting) into serving stacks to automatically detect when long-range context matters and boost long-range-relevant tokens (via LSPS) only in those cases.
- Tools/products/workflows:
- A Hugging Face-compatible sampler that wraps nucleus sampling with LSDS+TaBoo
- A “Context-Aware Decoding” toggle in enterprise LLM gateways
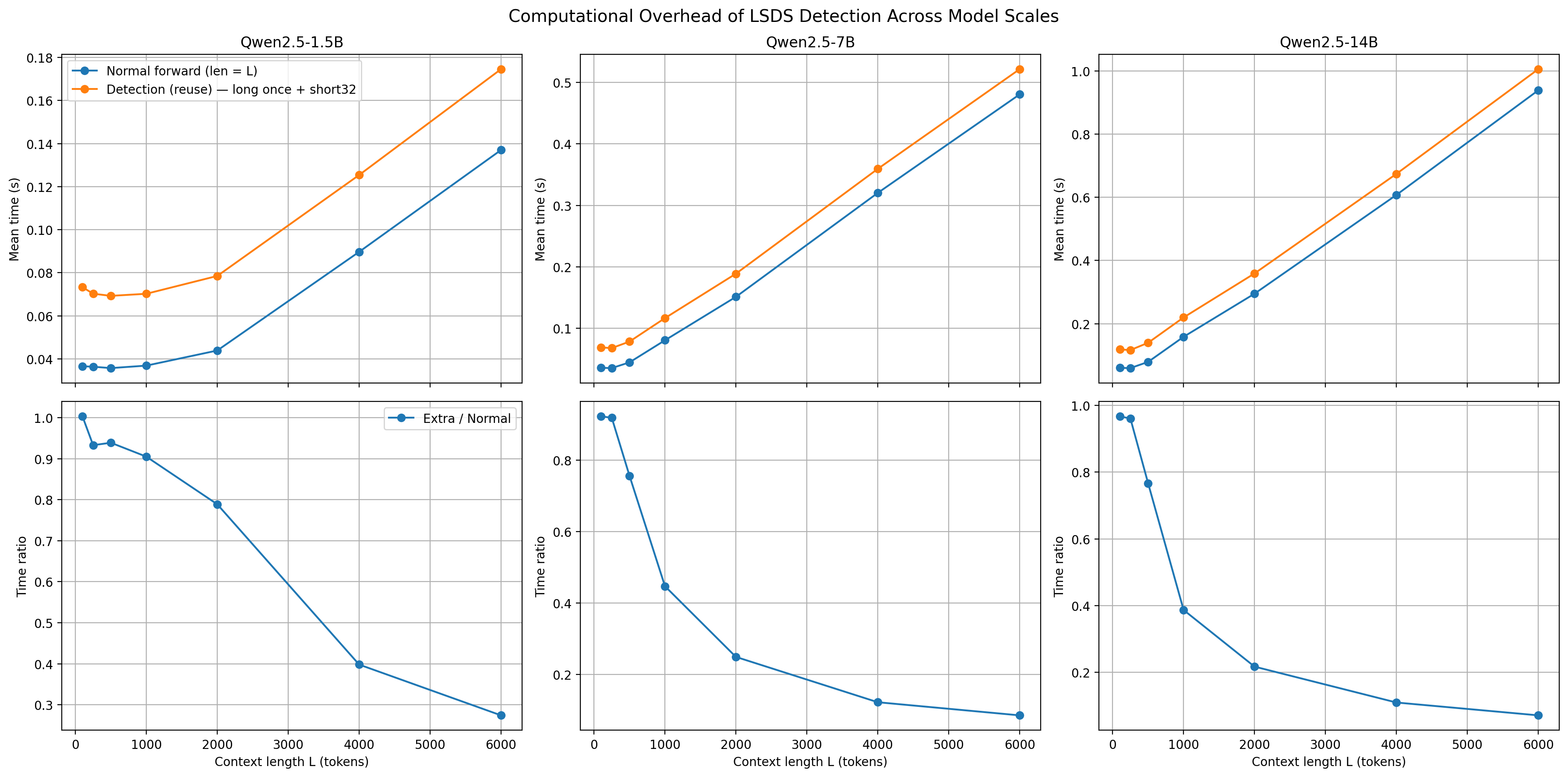
- Assumptions/dependencies: Access to token probabilities/logits; threshold tuning per model/task; small added latency (an extra short-context forward pass), negligible for long inputs.
- Context-adaptive compute to cut inference cost and latency
- Sectors: software, cloud/ML platforms
- What: Default to short attention windows (e.g., last 32–96 tokens) and expand only when LSDS indicates long-context is needed.
- Tools/products/workflows:
- Dynamic KV cache and attention-masking policies
- Scheduling policies in serving systems that allocate long-context kernels only on LSDS>τ
- Assumptions/dependencies: Model supports attention masking; careful calibration to avoid missing true long-context cases.
- RAG policy control (adaptive retrieval depth)
- Sectors: legal, finance, customer support, healthcare
- What: Use LSDS on the current prompt to decide retrieval depth, chunk count, or reranking intensity—shallow retrieval for short-context cases; deeper retrieval for long-context cases.
- Tools/products/workflows:
- “Context Budgeter” in RAG pipelines (retrieval top-k and window size governed by LSDS)
- Assumptions/dependencies: RAG system exposes retrieval knobs; thresholds tuned to content domain.
- Model routing based on context need
- Sectors: software, cloud/ML platforms
- What: Route short-context requests to cheaper/short-window models; route LSDS-flagged requests to long-context models.
- Tools/products/workflows:
- API gateways with LSDS-based routing policies
- Assumptions/dependencies: Multiple model backends available; routing thresholds validated on representative traffic.
- Dataset labeling and curation for long-context evaluation and training
- Sectors: academia, industry ML teams
- What: Use MCL/DaMCL/LSDS to label tokens/sequences as short- vs long-context dependent for targeted evaluation sets and rebalanced fine-tuning.
- Tools/products/workflows:
- Benchmark subsets focusing on high-MCL/DaMCL items
- Curriculum or reweighting that up-samples long-context cases
- Assumptions/dependencies: Compute budget to run labeling passes; labels mildly model-dependent.
- Replacement/augmentation of perplexity in long-context evaluation
- Sectors: academia, policy (procurement), industry evaluation
- What: Report LSDS/DaMCL distributions alongside perplexity to reflect whether models actually utilize distant context.
- Tools/products/workflows:
- Evaluation dashboards that chart LSDS histograms and DaMCL curves
- Assumptions/dependencies: Agreement on thresholds; community adoption.
- Hallucination mitigation in long documents
- Sectors: healthcare (clinical summaries), legal (contracts), finance (10-Ks), media (long-form)
- What: Apply LSDS+TaBoo to downplay locally overconfident fillers and boost tokens whose probabilities increase with access to the full document.
- Tools/products/workflows:
- Risk-reduction modes for long-document summarizers and assistive drafting tools
- Assumptions/dependencies: Gains demonstrated on QA; verify for each generation task.
- Developer/prompting assistant for context awareness
- Sectors: software, education (instructional design), documentation tooling
- What: Expose LSDS/LSPS in IDEs and prompt design tools to show when and where long-range references drive predictions.
- Tools/products/workflows:
- Prompt linting: flags that suggest adding citations or reintroducing entities when LSDS is high
- Assumptions/dependencies: Access to logits; UX integration.
- Customer-support and email thread assistants that adapt to conversation length
- Sectors: customer support, daily life
- What: Detect whether recent messages suffice; when LSDS is high, expand window to include earlier thread turns.
- Tools/products/workflows:
- Smart threading policies in helpdesk/chat products
- Assumptions/dependencies: Privacy controls for pulling longer histories.
- On-device and edge inference with default-short context
- Sectors: mobile, embedded AI
- What: Default to short windows for efficiency; expand selectively based on LSDS to stay within memory/compute limits.
- Tools/products/workflows:
- Edge runtimes with LSDS-triggered “burst” long-context mode
- Assumptions/dependencies: Efficient attention-masking and caching; modest quality trade-offs acceptable.
- Code assistance with long-range dependency detection
- Sectors: software engineering
- What: Use LSDS on code tokens to detect when earlier files or distant symbols matter (imports, global state), and boost identifiers via LSPS in completion.
- Tools/products/workflows:
- IDE extensions for context-aware completion and navigation
- Assumptions/dependencies: Empirical thresholds differ from natural language; verification on code corpora recommended.
- Governance and procurement checklists for “long-context readiness”
- Sectors: policy, enterprise IT procurement
- What: Require vendors to report LSDS/DaMCL metrics on standard long-document suites (e.g., GovReport).
- Tools/products/workflows:
- RFP templates with long-context utilization criteria
- Assumptions/dependencies: Standardized datasets and reporting formats.
Long-Term Applications
These applications likely require additional research, scaling, integration, or standardization beyond what’s provided in the paper.
- Training-time debiasing toward long-context dependencies
- Sectors: academia, industry ML labs
- What: Incorporate MCL/DaMCL/LSDS-driven sampling or auxiliary losses to counter short-context dominance during pretraining/fine-tuning.
- Tools/products/workflows:
- Data schedulers that upweight high-MCL sequences
- Loss terms that encourage agreement between short- and long-context distributions only where appropriate
- Assumptions/dependencies: Stable training objectives; compute to re-train; careful avoidance of overfitting rare long-context cases.
- Architectures with dynamic context allocation
- Sectors: software, cloud/ML platforms
- What: Models that natively select a minimal useful window per step (guided by DaMCL-like criteria), invoking memory modules or retrieval only when needed.
- Tools/products/workflows:
- Mixture-of-attention or selective attention layers gated by LSDS-like signals
- Assumptions/dependencies: Differentiable proxies for LSDS in training; robust memory mechanisms; hardware support.
- Standardized long-context benchmarks and metrics for policy and regulation
- Sectors: policy, standards bodies, academia
- What: Establish LSDS/DaMCL/LSD-based scorecards for procurement, safety evaluation, and certification of long-document systems (e.g., medical or legal).
- Tools/products/workflows:
- Shared leaderboards with LSDS distributions and task-level performance under long-context constraints
- Assumptions/dependencies: Community consensus; domain-specific validation (e.g., clinical accuracy standards).
- Retrieval policies learned end-to-end with LSDS guidance
- Sectors: enterprise knowledge management, search
- What: Train controllers that map LSDS signals to retrieval depth, chunking, and re-ranking policies to minimize cost while preserving accuracy.
- Tools/products/workflows:
- RL or bandit-driven retrieval controllers
- Assumptions/dependencies: Reliable online feedback; guardrails to avoid missing critical evidence.
- Safety and security: prompt-injection and position-bias defenses
- Sectors: cybersecurity, platform safety
- What: Use LSDS to identify when early-context content disproportionately influences predictions; trigger countermeasures or isolations of untrusted spans.
- Tools/products/workflows:
- “Influence monitors” that gate or annotate suspicious long-range effects
- Assumptions/dependencies: Calibrated thresholds; integration with existing safety policies.
- Domain-specific long-context guarantees (healthcare, legal, finance)
- Sectors: healthcare, legal, finance
- What: Task designs and contracts that guarantee earlier clauses/evidence are considered when LSDS indicates long-range relevance; audit trails showing LSDS shifts across drafts.
- Tools/products/workflows:
- “Context coverage” reports attached to generated outputs (e.g., which sections influenced the answer)
- Assumptions/dependencies: Regulatory acceptance; privacy and auditability infrastructure.
- Cognitive and educational research using LSDS as a proxy for human context use
- Sectors: academia, education
- What: Study how often local vs distant context is needed in reading comprehension, using LSDS-like measures as model-based analogues; design curricula to train long-context reasoning.
- Tools/products/workflows:
- Classroom tools that highlight when a question depends on prior chapters; adaptive reading assignments
- Assumptions/dependencies: Validity of LSDS as a proxy for human processing; IRB considerations for studies.
- Multimodal long-context control (audio/video transcripts, meetings)
- Sectors: productivity, enterprise collaboration
- What: Extend LSDS/LSPS ideas to transcripts and multimodal inputs; meeting assistants that highlight when earlier agenda items or speakers’ notes matter.
- Tools/products/workflows:
- Meeting summarizers with LSDS-aware turn selection and targeted boosting
- Assumptions/dependencies: Robust multimodal tokenization; empirically validated thresholds per modality.
- Energy-aware scheduling at datacenter scale
- Sectors: energy, cloud providers
- What: Use population LSDS statistics to schedule long-context kernels to times/locations with lower carbon intensity; throttle long-context usage when negligible benefits expected.
- Tools/products/workflows:
- “Green context” schedulers and SLAs that include context-efficiency targets
- Assumptions/dependencies: Accurate forecasting of LSDS distribution; alignment with performance SLAs.
- Tokenization/vocabulary and memory design optimized for long-context signals
- Sectors: academia, industry ML labs
- What: Design vocabularies or memory layouts that preserve and surface long-range-relevant tokens (high-LSPS) more effectively.
- Tools/products/workflows:
- Vocabulary reallocation or subword merges guided by LSPS statistics
- Assumptions/dependencies: Re-training required; risk of regressing short-context performance.
Notes on feasibility and transfer
- Thresholds and gains are model- and task-dependent; adopt per-domain validation loops.
- Closed APIs that don’t expose logits limit immediate adoption; best suited for open-weight or enterprise deployments.
- Evidence is strongest for QA and long-document tasks; creative writing, code, and math may require domain-specific calibration and further validation.
- Extra forward passes for LSDS are modest overhead on long inputs but proportionally higher for short ones; use heuristics to skip LSDS for short contexts.
Collections
Sign up for free to add this paper to one or more collections.