- The paper introduces ReNoV, a diffusion-based framework that leverages multi-view geometric and semantic representations for high-fidelity novel view synthesis.
- It uses projected representation conditioning to align 3D geometric features with target views, achieving superior reconstruction metrics (PSNR, SSIM, LPIPS) in diverse settings.
- The study shows robust generalization to sparse, unposed inputs, eliminating explicit 3D reconstruction with efficient, transformer-based feature aggregation.
Projected Representation Conditioning for High-Fidelity Novel View Synthesis: An In-Depth Analysis
Introduction
The paper "Projected Representation Conditioning for High-fidelity Novel View Synthesis" (2602.12003) proposes ReNoV, a diffusion-based framework that leverages geometric and semantic correspondence properties of visual foundation models for novel view synthesis (NVS). The approach addresses core limitations in existing generative and feedforward paradigms by integrating multi-view feature representations—specifically those with strong geometric consistency—into the conditional denoising process of diffusion models. The methodology targets both faithful reconstruction of visible regions and plausible inpainting of occluded or unobserved regions during synthesis, with an emphasis on generalizability to sparse, unposed, and diverse image collections.
Motivation and Representation Analysis
The authors begin by recognizing that the quality of NVS depends critically on the ability to establish robust geometric and semantic correspondences across viewpoints. Noting that recent visual foundation models (e.g., VGGT, DepthAnythingV3) possess emergent multi-view consistency in their attention mechanisms, the study systematically characterizes these properties using extensive probing experiments.
The cross-view attention analysis (Figure 1) demonstrates that regions requiring inpainting induce broad, semantically driven attention across references, whereas visible regions prompt sharp, geometrically aligned attention—highlighting the dual requirements for effective NVS:

Figure 1: Cross-view attention maps of the denoising network reveal semantic-driven and geometric-driven correspondences depending on the region targeted for inpainting or reconstruction.
Subsequent probing quantifies geometric and semantic correspondence of intermediate features in DINOv2, VGGT, and DA3. Figure 2 provides evidence that the deeper layers of VGGT and DA3 capture geometric structure with high fidelity, outperforming purely semantic encoders such as DINOv2 when localizing geometric correspondences in challenging, texture-less scenes:

Figure 2: Deep VGGT and DA3-L layers correctly identify geometric correspondences even in regions lacking semantic detail, unlike DINOv2.
Quantitative experiments using shallow MAE decoders on warped features reveal that the geometric alignment capability of representations is highly correlated with reconstruction performance, as shown by superior PSNR, SSIM, and LPIPS achieved by VGGT features.
ReNoV Architecture and Projected Representation Conditioning
The ReNoV pipeline is composed of two U-Nets: a reference network and a denoising network. Reference images are processed by external representation models (VGGT, DA3, or DINOv2), which provide:
- Dense pointmaps and camera pose estimates (geometry priors).
- High-dimensional semantic-geometric representations extracted from multiple transformer layers.
These conditioned features are subjected to "projected representation conditioning": geometric features are unprojected into 3D using predicted pointmaps and then reprojected to the target camera frustum, directly aligning reference features with the target view (Figure 3):
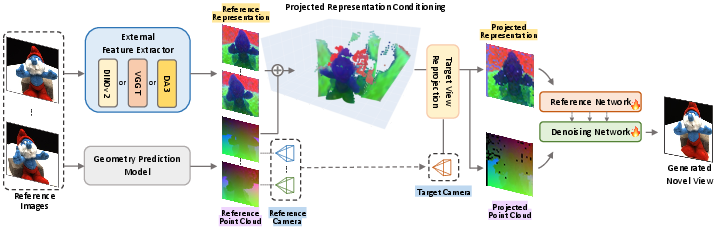
Figure 3: ReNoV's architecture aggregates multi-view features and geometry, reprojected into the target view for spatially aligned conditioning.
This conditioning is concatenated, Fourier-encoded, and channeled through shallow networks before being injected at several stages in the denoising U-Net, thus providing both precise geometric priors for observed regions and rich semantic priors for occluded or ambiguous areas.
Experimental Results
In-Domain and Generalization Performance
ReNoV displays strong quantitative performance across standard NVS benchmarks (RealEstate10K, DTU, Co3D), outperforming previous feedforward and generative baselines in both interpolation and extrapolation regimes. Notably, in far-view (extrapolation) settings—where large scene regions are unobserved—diffusion-based models with projected conditioning demonstrate substantial improvements in LPIPS and SSIM (Table 1 in the paper). Qualitative comparisons support these findings, with ReNoV achieving coherent geometric reconstructions and plausible inpainting:

Figure 4: Far-view synthesis results on DTU—ReNoV extrapolates realistically beyond references and preserves scene geometry.
Representation and Architecture Ablations
Ablations highlight the superiority of implicit geometric-semantic conditioning through VGGT features compared to explicit pointmaps only or semantic aggregation alone (Table 2 in the paper). Qualitative results (Figure 5) further illustrate this:

Figure 5: Only the full configuration with projected VGGT features preserves semantic consistency and structural alignment in difficult settings.
Projection-based conditioning enables robust inpainting in the presence of noisy or incomplete geometry, as shown by minimal degradation in metrics when the point cloud is randomly subsampled. These results confirm the resilience of the approach to imperfect geometric priors.
Theoretical and Practical Implications
The principal theoretical insight is that conditioning diffusion models with external representations that exhibit multi-view geometric consistency unlocks higher-fidelity generative behavior in both observed and unobserved regions. Projected representation conditioning unifies explicit 3D warping with generative inpainting, leveraging the locality and multi-view coherence of foundation model features for spatially accurate synthesis.
From a practical perspective, this paradigm eliminates the need for explicit 3D reconstruction or optimization at inference, while achieving strong generalization even with sparse and unposed input imagery. The system is extensible to various backbone representations and robust to geometric noise—making it highly attractive for applications in scene digitization, content creation, telepresence, and robotics.
Further, the demonstrated benefit of intermediate, multi-layer feature aggregation prompts further investigation into representation learning for geometry-aware synthetic generation and the development of improved architectures that balance semantic and geometric information across transformer depths.
Future Directions
Future research may expand ReNoV’s approach to handle dynamic scene changes, interactive scene editing, and real-time synthesis. The conditioning mechanism could be extended to leverage video or temporally-aware representations, facilitate joint appearance-geometry synthesis for relighting or simulation, and integrate with foundation models trained explicitly for correspondence alignment across spatiotemporal domains.
Emerging large-scale, self-supervised pretraining regimes designed to fuse both appearance and geometry are likely to further improve the conditioning signals and thus the synthesis quality in this and related frameworks.
Conclusion
ReNoV advances the field of novel view synthesis by explicitly combining projected, multi-view-consistent foundation model features with diffusion-based conditional generation. Through systematic representation analysis and comprehensive empirical validation, the framework demonstrates improved geometric consistency, inpainting fidelity, and resilience to input sparsity and geometric noise. The results underscore the value of multi-layer, geometry-grounded feature representations and projected conditioning for robust NVS and related vision-generation tasks.