- The paper presents 3DiM, a pose-conditional diffusion model that overcomes limitations of prior NeRF and SRN methods in producing high-fidelity 3D views.
- It employs a novel stochastic conditioning sampler and a modified X-UNet architecture to ensure consistent 3D view generation during the image-to-image translation process.
- Experiments on the SRN ShapeNet dataset show that 3DiM generates visually coherent outputs with superior FID scores and a new 3D consistency metric.
Novel View Synthesis with Diffusion Models
Introduction
The paper presents 3DiM, a diffusion model for generating novel 3D views using pose-conditional image-to-image diffusion models. This novel approach leverages diffusion probabilistic models (DPM) to generate multiple views of 3D objects, maintaining high fidelity across these views via stochastic conditioning. The limitations of prior NeRF and SRN models—such as blurriness, regression-based limitations, and constraints on data scaling—are addressed by this geometry-free framework that allows diffusion models to extend to large-scale datasets without requiring one model per scene.
Methodology
3DiM's core is a pose-conditional diffusion model for image-to-image translation, using a novel stochastic conditioning sampling algorithm to enhance 3D consistency. Unlike traditional NeRFs, which require 3D-aware representations, 3DiM generates views autoregressively by conditioning each denoising step on random previous views, thereby ensuring 3D consistency and avoiding the fixed-view limitations of naive samplers.
Image-to-Image Diffusion Models with Pose Conditioning
Figure 1 illustrates the training process where noise is added to one of two frames from a common scene, and the model learns to predict and remove this noise, thus completing the image generation task.
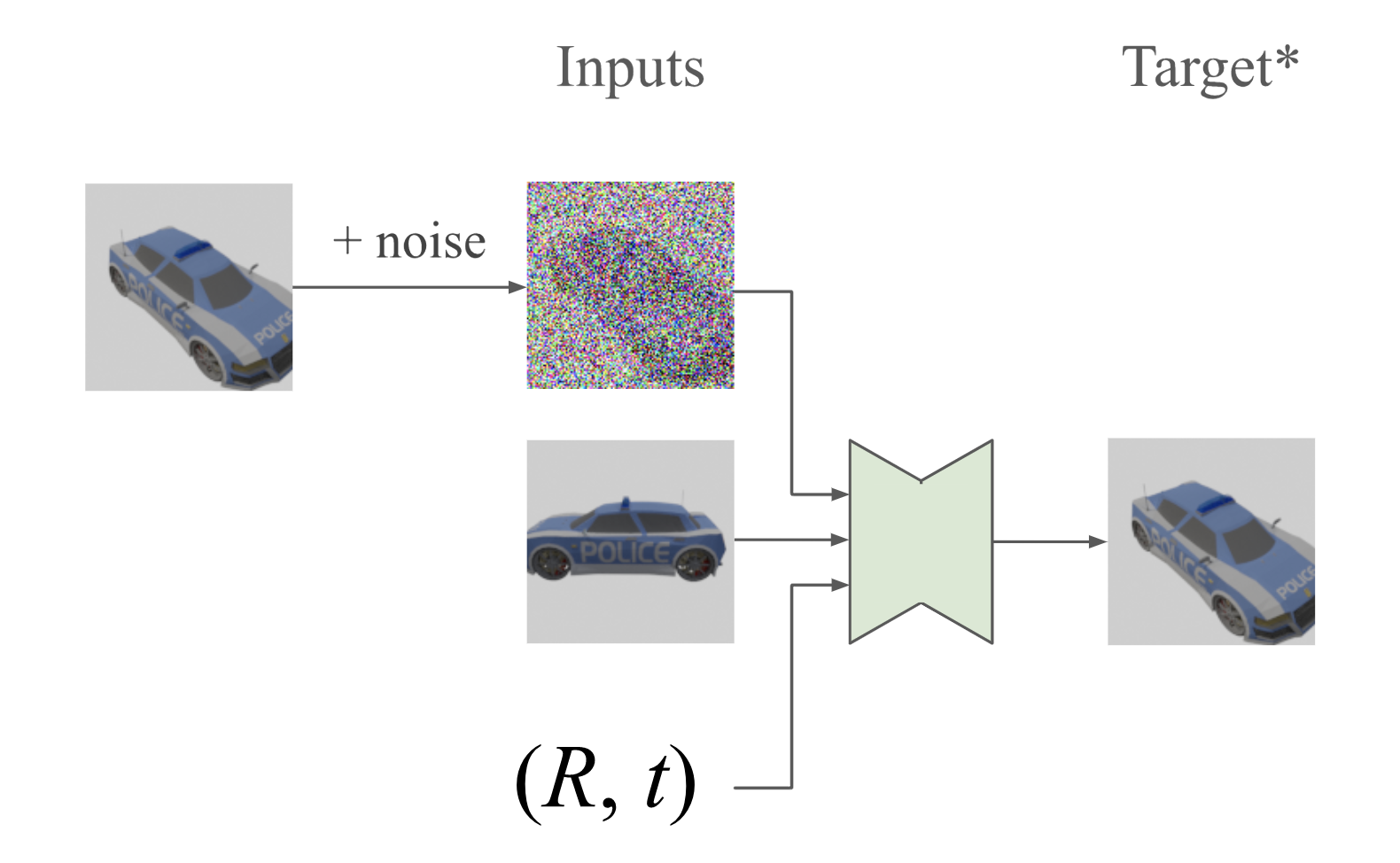
Figure 1: Pose-conditional image-to-image training -- Example training inputs and outputs for pose-conditional image-to-image diffusion models.
Stochastic Conditioning for 3D Consistency
To achieve 3D consistency, each denoising step of the sampling process randomly selects a conditioning frame. This stochastic selection enables the diffusion model to generate frames that are coherent and likely to maintain high fidelity to the input view, as shown in Figure 2.
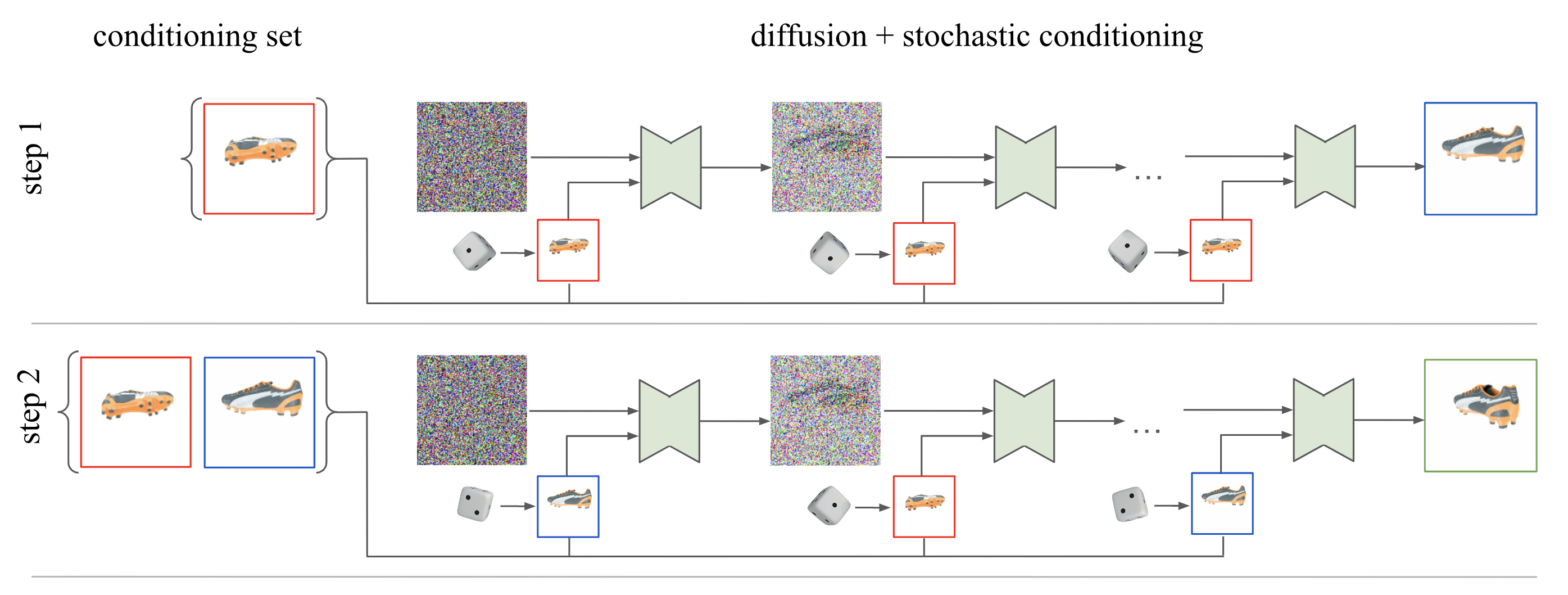
Figure 2: Stochastic conditioning sampler -- The autoregressive generation and denoising processes where random conditioning frames are selected at each denoising step.
X-UNet Architecture
A significant contribution is the modification of the UNet architecture, creating X-UNet, optimized for 3D novel view synthesis through shared weights and cross-attention layers, which bolster its 3D synthesis capabilities, as depicted in Figure 3.
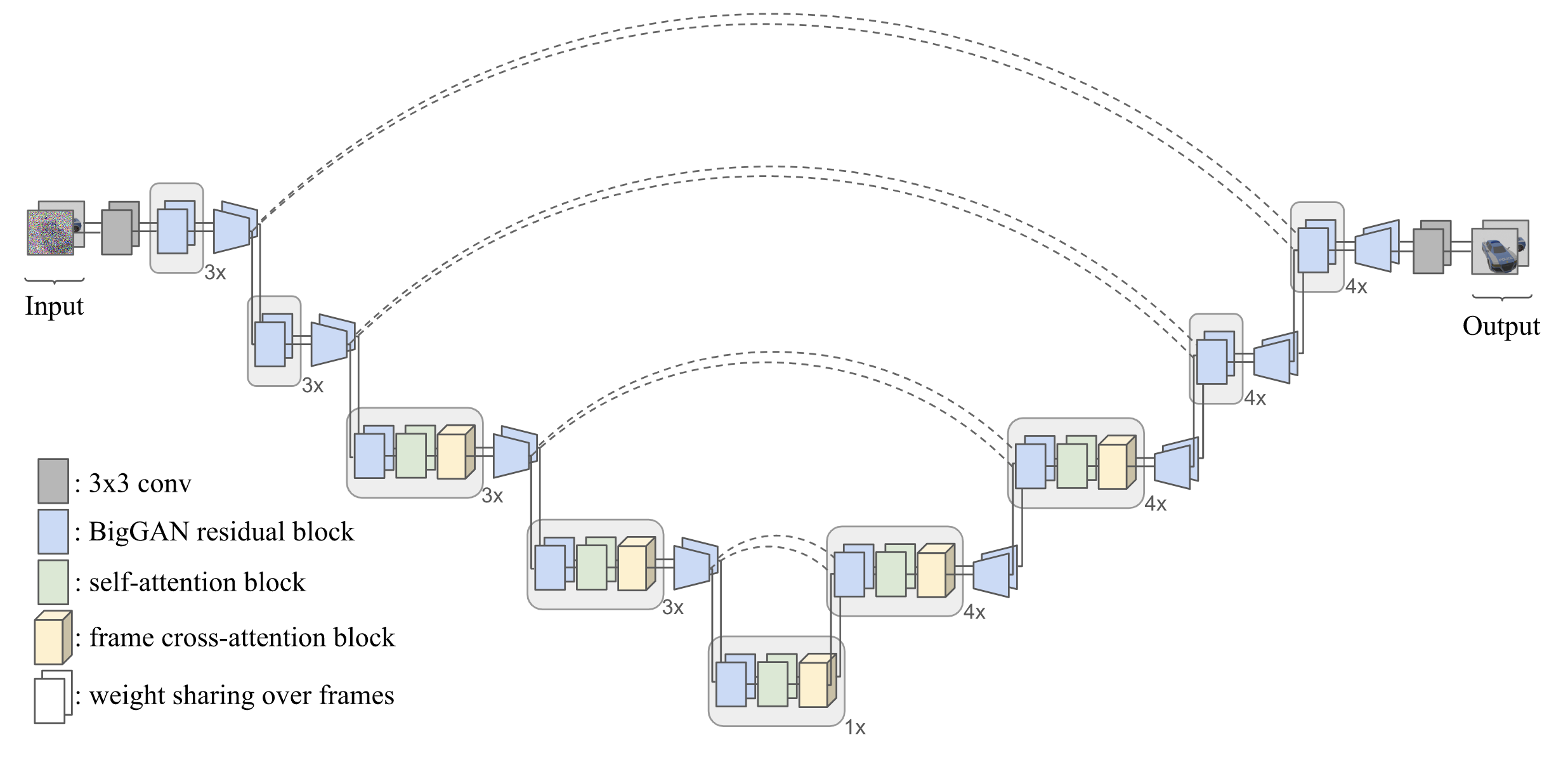
Figure 3: X-UNet Architecture -- Modified UNet for accommodating 3D novel view synthesis with shared weights and cross-attention layers.
Experiments and Results
Empirical validation is conducted using the SRN ShapeNet dataset, comparing the performance of 3DiM against existing methods, like PixelNeRF and VisionNeRF. The evaluation reveals that though 3DiM does not excel in traditional metrics like PSNR and SSIM, it surpasses other methods in generating sharp, visually coherent samples, reflected by superior FID scores in comparisons, as shown in Figure 4.

Figure 4: Visual results from 3DiM producing high-fidelity views from a single input image.
A new evaluation metric, "3D consistency scoring," verifies the method's consistency by training a neural field on output views. This metric confirms 3DiM’s proficiency in maintaining 3D alignment across generated views.
Conclusion
3DiM represents an advancement in 3D view synthesis using diffusion models, advancing the fidelity and consistency of generated views. Its architecture supports scalable, geometry-free modeling across extensive datasets, hinting at applications extending to large 3D datasets and real-world scenarios. The development of end-to-end models that ensure 3D consistency by design remains a promising research frontier, potentially applicable in text-to-3D media generation.
This work underscores the capability of diffusion models in maintaining view consistency without explicit geometry representation, relying on innovative stochastic sampling methods and architecture enhancements to achieve results that challenge existing state-of-the-art techniques.

