Abstract: Synthesizing novel views from a single input image is a challenging task. It requires extrapolating the 3D structure of a scene while inferring details in occluded regions, and maintaining geometric consistency across viewpoints. Many existing methods must fine-tune large diffusion backbones using multiple views or train a diffusion model from scratch, which is extremely expensive. Additionally, they suffer from blurry reconstruction and poor generalization. This gap presents the opportunity to explore an explicit lightweight view translation framework that can directly utilize the high-fidelity generative capabilities of a pretrained diffusion model while reconstructing a scene from a novel view. Given the DDIM-inverted latent of a single input image, we employ a camera pose-conditioned translation U-Net, TUNet, to predict the inverted latent corresponding to the desired target view. However, the image sampled using the predicted latent may result in a blurry reconstruction. To this end, we propose a novel fusion strategy that exploits the inherent noise correlation structure observed in DDIM inversion. The proposed fusion strategy helps preserve the texture and fine-grained details. To synthesize the novel view, we use the fused latent as the initial condition for DDIM sampling, leveraging the generative prior of the pretrained diffusion model. Extensive experiments on MVImgNet demonstrate that our method outperforms existing methods.
The paper introduces a novel method using DDIM inversion and a camera pose-conditioned TUNet to generate high-fidelity novel views from a single image.
It leverages a fusion strategy that integrates high-frequency details with low-frequency components, achieving improved LPIPS, PSNR, SSIM, and FID metrics.
Experimental results on the MVImgNet dataset demonstrate superior performance over state-of-the-art models such as GIBR and NViST.
Novel View Synthesis using DDIM Inversion
The paper "Novel View Synthesis using DDIM Inversion" introduces an innovative methodology for generating novel views from a single input image using Deterministic Denoising Diffusion Implicit Models (DDIM). This work aims to address existing challenges in novel view synthesis by employing a lightweight view translation framework based on a pretrained diffusion model. The key contributions of the literature are the introduction of a camera pose-conditioned Translation U-Net (TUNet) and a novel fusion strategy that leverages the noise correlation innate to DDIM inversion. This methodology ultimately enhances the textural and fine-grained details in the generated images and demonstrates superior performance over existing methods, specifically in terms of LPIPS, PSNR, SSIM, and FID metrics.
Figure 1: (a) High-resolution (512×512) novel-view synthesis on the MVImgNet test set from a single input image and camera parameters, (b) Zero-shot synthesis on out-of-domain images.
Methodology
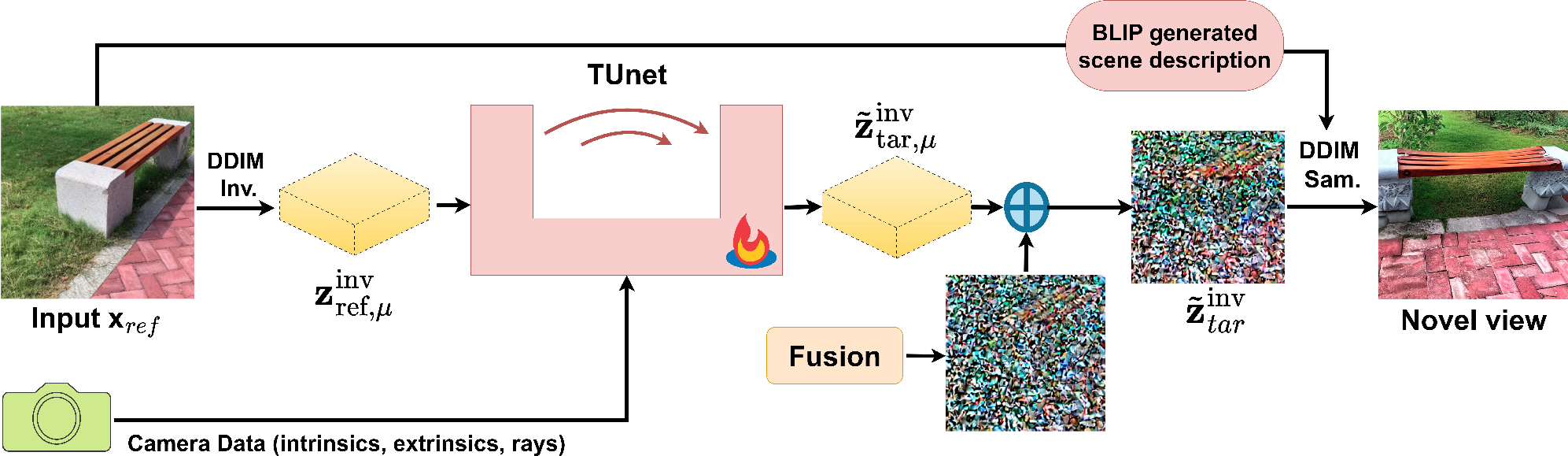
At the core of this work is the application of deterministic DDIM inversion in the latent space for novel view synthesis. The proposed method is illustrated below:
Figure 1: Overview: Given a single reference image $\mathbf{x_{\text{ref}$, we first apply DDIM inversion up to t=600 to obtain the mean latent $\mathbf{z}_{\text{ref},\mu}^{\text{inv}$. This, together with camera intrinsics/extrinsics, class embeddings, and ray information, is fed into our translation network TUNet. TUNet predicts the target-view mean latent $\tilde{\mathbf{z}_{\text{tar},\mu}^{\text{inv}}$, which is combined with a noise component to form the initial DDIM latent $\tilde{\mathbf{z}_{tar}^{\text{inv}$, ultimately used in DDIM sampling to synthesize the novel view.
Methodology
Spectral Behavior of Diffusion
The paper leverages the spectral bias property of diffusion models, which prefer lower frequency components (capturing coarse features) and degrade high-frequency details initially in the forward diffusion process. In the DDIM inversion approach, the representation is not manipulated with additional noise. Instead, the DDIM inversion relies on preserving a signal/noise balance: at an intermediate timestep, t=600, where low-frequency components remain, the model generates a coarse-grained version of the target view. This constraint is used by the translation U-Net (TUNet) to map this latent to the target novel view.
xt=signalαtx0+noise1−αtϵ,ϵ∼N(0,I)
Figure 2: Qualitative results with our 167-class trained model.
TUNet Architecture
The TUNet is central to this approach, leveraging U-Net's encoder-decoder architecture for view transformation within the DDIM-inverted latent space. The input image is mapped to a latent space through a VAE encoder followed by DDIM inversion. TUNet is designed with a cross-attention mechanism enabling effective feature transfer between the input and target views by conditioning on camera and class embeddings.
Two types of embeddings are utilized as inputs for TUNet at varying stages: a Camera Embedding, vectorizing camera intrinsics and extrinsics through a learnable linear layer, and a Class Embedding that corresponds to the scene category. As shown in Equation (\ref{eq:ddpm_pixel_reparam}) and discussed in \citet{choi2022perception}, diffusion models tend to have a spectral bias favoring low-frequency component modeling, negatively impacting high-frequency details necessary for high-quality images. Therefore, an additional fusion strategy was developed to inject these details into the novel view reconstruction.
Figure 4: Left: Mean of the DDIM inverted latent at t=600. Latent is decoded using VAE for visualization. Right: Original 512×512 image.
Fusion Strategy
The fusion strategy addresses the inherent spectral bias of diffusion models, which tend to retain lower frequencies while higher frequency information may be lost during the forward diffusion process. The proposed fusion approach involves two different strategies for combining the TUNet's prediction (the mean latent) with a noise component that reintegrates the high-frequency details. This compensated latent serves as the input for the final step of the DDIM sampling with a pretrained diffusion model, ultimately attaining high-quality novel view reconstructions.
Experimental Results
The performance of the proposed approach is verified using the MvImgNet dataset, which provides access to diverse real-world scenes across various categories. The dataset was resized and normalized, with DDIM inversion applied to obtain the DDIM-inverted latent space representation for processing through TUNet.
Figure 2: Qualitative results with our 167-class trained model.
Quantitative Performance
The proposed method was benchmarked against state-of-the-art models such as GIBR and NViST in different conditions. The experimental results reveal that the presented model outperforms existing methods, yielding superior LPIPS, PSNR, SSIM, and FID metrics. Specifically, our method demonstrated better performance in LPIPS compared to GIBR and achieved better results than NViST across all measurable metrics.
Figure 5: We resize our results to 90×90 to show comparison with NViST on unseen test scenes from 5 classes.
Limitations and Future Work
While the methodology proves effective in synthesis, limitations include handling occluded regions. Despite leveraging a pre-trained diffusion model, the current framework may face challenges with significantly unseen regions due to the constraints of existing data.
Implications and Future Directions
The implications of this research are significant, especially for domains requiring high-fidelity novel view synthesis from limited viewpoints, such as virtual reality and augmented reality content creation, robotics, and autonomous vehicles. Future work could further optimize the fusion strategy, explore hybrid methodologies for enhancing high-frequency detail retention, and study the impact of different noise schedules on synthesis quality to enhance generalizability and efficiency.
In conclusion, this paper presents a promising method for novel view synthesis by leveraging DDIM inversion and introduces efficient processing in the latent space with a trained TUNet network. Future explorations could focus on extending this approach to even more complex scenes, improving the understanding of the noise distribution, and optimizing fusion strategies for more precise high-frequency detail reconstruction.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.